







 文章介绍了使用大模型自动生成RAG问答数据集的过程,通过BM25检索器进行评估,并发现关键词检索优于向量检索。作者详细展示了数据加载、模型加载、数据生成以及评估指标的计算方法。
文章介绍了使用大模型自动生成RAG问答数据集的过程,通过BM25检索器进行评估,并发现关键词检索优于向量检索。作者详细展示了数据加载、模型加载、数据生成以及评估指标的计算方法。
背景
最近在做RAG评估的实验,需要一个RAG问答对的评估数据集。在网上没有找到好用的,于是便打算自己构建一个数据集。
简介
本文使用大模型自动生成RAG 问答数据集。使用BM25关键词作为检索器,然后在问答数据集上评估该检索器的效果。
输入是一篇文本,使用llamaindex加载该文本,使用prompt让大模型针对输入的文本生成提问。
步骤如下:
- llamaindex 加载数据;
- 利用 chatglm3-6B 构建CustomLLM;
- 使用prompt和chatglm,结合文本生成对应的问题,构建RAG问答数据集;
- 使用
BM25Retriever,构建基于关键词的检索器; - 评估
BM25Retriever在数据集上的hite_rate和mrr结果;
由于在构建问答对时,让大模型结合文本生成对应的问题。笔者在测试时,发现关键词检索比向量检索效果要好
代码实现
导入包
from typing import List, Any
from llama_index.core import SimpleDirectoryReader
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.legacy.llms import (
CustomLLM, CompletionResponse, CompletionResponseGen, LLMMetadata)
from llama_index.legacy.schema import NodeWithScore, QueryBundle, Node
from llama_index.core.base.base_retriever import BaseRetriever
from llama_index.legacy.retrievers import BM25Retriever
from llama_index.core.evaluation import RetrieverEvaluator
from llama_index.core.evaluation import (
generate_question_context_pairs,
EmbeddingQAFinetuneDataset,
)
加载数据,使用llamaindex网站的paul_graham_essay.txt
# Load data
documents = SimpleDirectoryReader(
input_files=["data/paul_graham_essay.txt"]
).load_data()
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
# Extract nodes from documents
nodes = node_parser.get_nodes_from_documents(documents)
# by default, the node ids are set to random uuids. To ensure same id's per run, we manually set them.
for idx, node in enumerate(nodes):
node.id_ = f"node_{idx}"
大模型加载
chatglm3-6B 使用half,显存占用12G
from modelscope import snapshot_download
from modelscope import AutoTokenizer, AutoModel
model_name = "chatglm3-6b"
model_path = snapshot_download('ZhipuAI/chatglm3-6b')
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
model = model.eval()
本地自定义大模型
# set context window size
context_window = 2048
# set number of output tokens
num_output = 256
class ChatGML(CustomLLM):
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
context_window=context_window,
num_output=num_output,
model_name=model_name,
)
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
prompt_length = len(prompt)
# only return newly generated tokens
text, _ = model.chat(tokenizer, prompt, history=[])
return CompletionResponse(text=text)
def stream_complete(
self, prompt: str, **kwargs: Any
) -> CompletionResponseGen:
raise NotImplementedError()
llm_model = ChatGML()
生成RAG测试数据集
# Prompt to generate questions
qa_generate_prompt_tmpl = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge.
generate only questions based on the below query.
You are a Professor. Your task is to setup \
{num_questions_per_chunk} questions for an upcoming \
quiz/examination. The questions should be diverse in nature \
across the document. The questions should not contain options, not start with Q1/ Q2. \
Restrict the questions to the context information provided.\
"""
# The questions should be solely based on the provided context information, and please pose them in Chinese.\
qa_dataset = generate_question_context_pairs(
nodes,
llm=llm_model,
num_questions_per_chunk=2,
qa_generate_prompt_tmpl=qa_generate_prompt_tmpl
)
qa_dataset.save_json("pg_eval_dataset.json")
# qa_dataset = EmbeddingQAFinetuneDataset.from_json("pg_eval_dataset.json")
import pandas as pd
def display_results(eval_results):
"""
计算hit_rate和mrr的平均值
"""
metric_dicts = []
for eval_result in eval_results:
metric_dict = eval_result.metric_vals_dict
metric_dicts.append(metric_dict)
full_df = pd.DataFrame(metric_dicts)
hit_rate = full_df["hit_rate"].mean()
mrr = full_df["mrr"].mean()
metric_df = pd.DataFrame(
{"hit_rate": [hit_rate], "mrr": [mrr]}
)
return metric_df
class JieRetriever(BM25Retriever, BaseRetriever):
def _get_scored_nodes(self, query: str):
tokenized_query = self._tokenizer(query)
doc_scores = self.bm25.get_scores(tokenized_query)
nodes = []
for i, node in enumerate(self._nodes):
node_new = Node.from_dict(node.to_dict())
node_with_score = NodeWithScore(node=node_new, score=doc_scores[i])
nodes.append(node_with_score)
return nodes
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
if query_bundle.custom_embedding_strs or query_bundle.embedding:
logger.warning("BM25Retriever does not support embeddings, skipping...")
scored_nodes = self._get_scored_nodes(query_bundle.query_str)
# Sort and get top_k nodes, score range => 0..1, closer to 1 means more relevant
nodes = sorted(scored_nodes, key=lambda x: x.score or 0.0, reverse=True)
return nodes[:self._similarity_top_k]
retriever = JieRetriever.from_defaults(
# retriever = BM25Retrieve r.from_defaults(
nodes=nodes,
similarity_top_k=10
)
现在llamaindex在使用BM25Retrieve会报错,故笔者创建了JieRetriever,具体请点击查看链接
from llama_index.core.base.base_retriever import BaseRetriever
retriever_evaluator = RetrieverEvaluator.from_metric_names(
["mrr", "hit_rate"], retriever=retriever
)
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
for idx, item in enumerate(eval_results):
if idx == 15:
break
d = item.metric_vals_dict
mrr, hit_rate = d['mrr'], d['hit_rate']
if mrr != 1 or hit_rate != 1:
print(mrr, hit_rate, item.expected_ids, item.retrieved_ids)
下图展示了hit_rate 和 mrr 的计算:
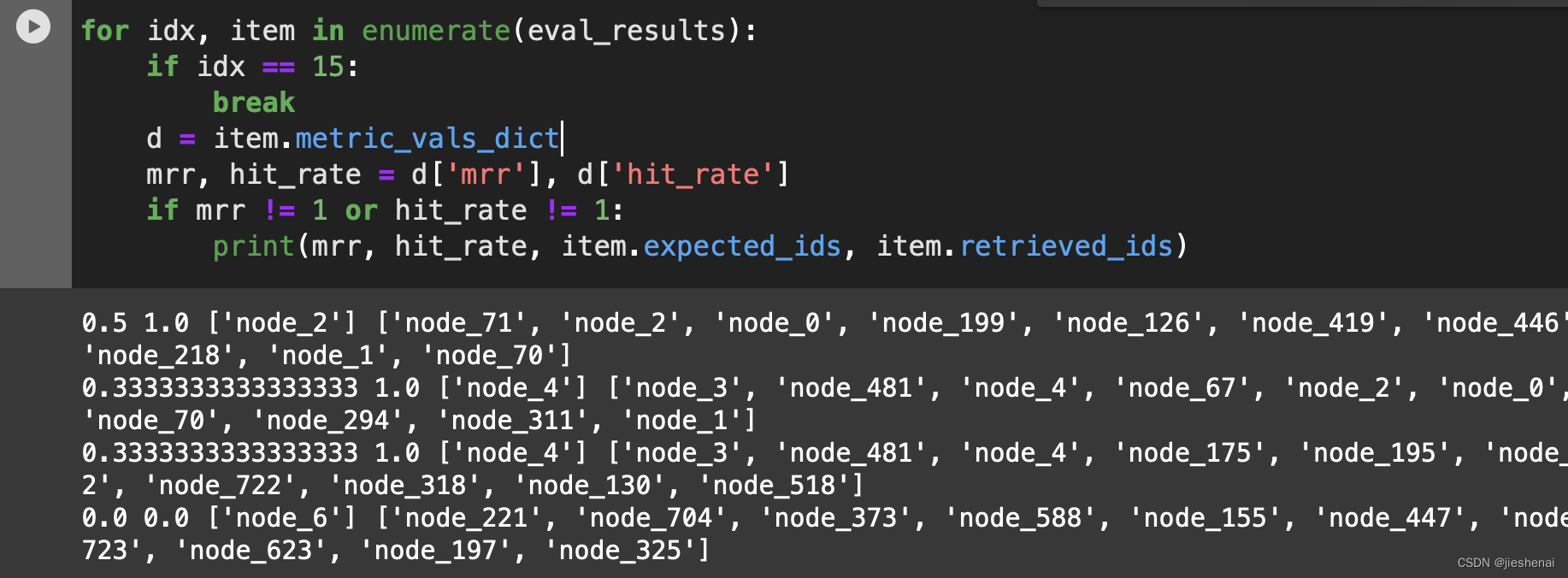
结合下述结果,分析一下 hit_rate 和 mrr:
0.5 1.0 ['node_2'] ['node_71', 'node_2', 'node_0', 'node_199', 'node_126', 'node_419', 'node_446', 'node_218', 'node_1', 'node_70']
['node_2']是 label['node_71', 'node_2', 'node_0', 'node_199', 'node_126', 'node_419', 'node_446', 'node_218', 'node_1', 'node_70']是检索器召回的候选列表;- mrr : 0.5;
'node_2'在候选列表的第二个位置,故mrr为 二分之一。在第几位就是几分之一;- hit_rate:代表label是否在候选集中,在就是1,不在就是0;
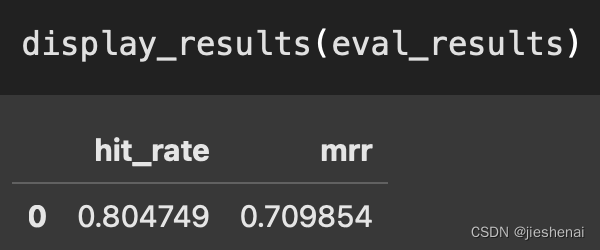
def display_results(eval_results):
"""
计算平均 hit_rate 和 mrr
"""
metric_dicts = []
for eval_result in eval_results:
metric_dict = eval_result.metric_vals_dict
metric_dicts.append(metric_dict)
full_df = pd.DataFrame(metric_dicts)
hit_rate = full_df["hit_rate"].mean()
mrr = full_df["mrr"].mean()
metric_df = pd.DataFrame(
{"hit_rate": [hit_rate], "mrr": [mrr]}
)
return metric_df
display_results(eval_results)
公开
生成的评估数据集和相应示例代码,已上传到modelscope平台;
https://www.modelscope.cn/datasets/jieshenai/paul_graham_essay_rag/files
下一步阅读
在同样的数据集上,下一篇文章,展示了如何使用向量检索和rerank模型;


















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











