









Cherry Studio介绍
Cherry Studio 是一个支持多模型服务的桌面客户端,为专业用户而打造,内置 30 多个行业的智能助手,帮助用户在多种场景下提升工作效率。
Cherry Studio支持多种场景应用,不过还是有一些限制,比如画图只能调用硅基流动的服务。
特色功能:多模型对话,可以选中多个模型,对同一个问题就行回答。
Cherry Studio安装
首先下载Cherry:
点击“下载客户端”,下载适合自己操作系统的客户端。
比如Windows下非常简单方便,下载后直接安装即可。
Ollama安装
Ollama可以直接安装,在Ubuntu下使用apt进行安装,在Windows下可以直接下载安装包进行安装。
Ollama的安装参考:
在Windows下安装Ollama并体验DeepSeek r1大模型_ollama-windows-amd64 下载-CSDN博客
使用Ollama 在Ubuntu运行deepseek大模型:以deepseek-r1为例_ubuntu deepseek-CSDN博客
Cherry配置模型
在模型服务中配置Ollama
启动Cherry后,先配置大模型。 配置模型需要点左下角的“设置”按钮,然后在“模型服务”里进行设置,比如设置Ollama本地模型。

因为是本地部署的Ollama,所以不需要api秘钥,但是需要设置一个api秘钥,随便输入字符串即可。选好模型,自动保存浩即可。
设置默认模型
然后设置默认模型,都选择deepseek-r1:1.5b

使用chat测试助手
点最左上角的“助手”图标,创建一个新助手,或者使用默认的助手,第一行能力选择模型,选已经安装好的Ollama deepseek-r1:1.5b模型,然后测试一下:

测试通过,这样一个简单的助手就配置好了!
CherryStudio中使用nomic-embed-text配置本地知识库
使用文档:知识库教程 | CherryStudio
CherryStudio中添加nomic-embed-text
CherryStudio 的模型服务,在Ollama模型设置中,加入nomic-embed-text 模型
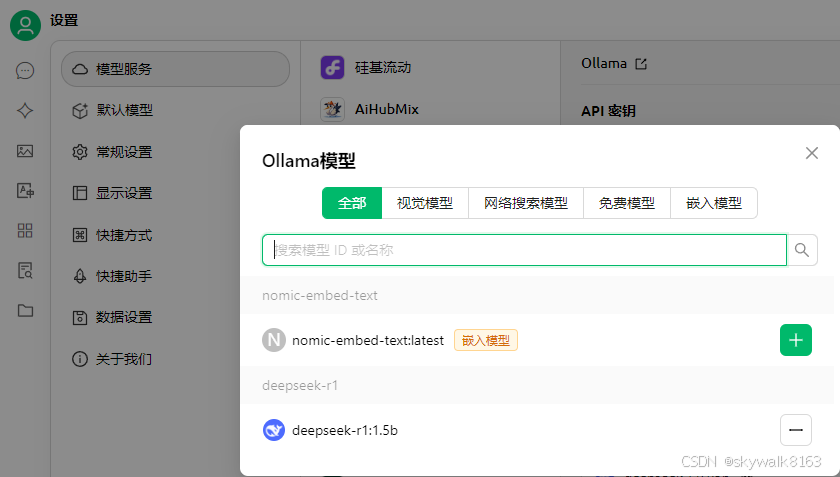
创建知识库
CherryStudio知识库中使用,在创建知识库的时候,嵌入模型选nomic-embed-text
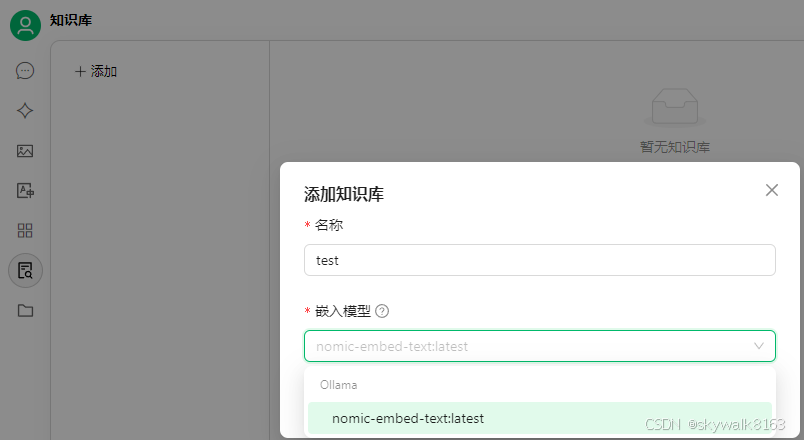
然后,进行知识库内容的建立。
比如直接添加文件、添加目录、添加网址、添加网站、添加笔记等。
比如把水浒传上传进行embedding,整个文件较大,embedding需要等待一些时间。
在chat中使用知识库
embedding后,在chat对话中,就可以使用创建好的知识库了。
问它一下:水浒传第一个出场的人是谁?
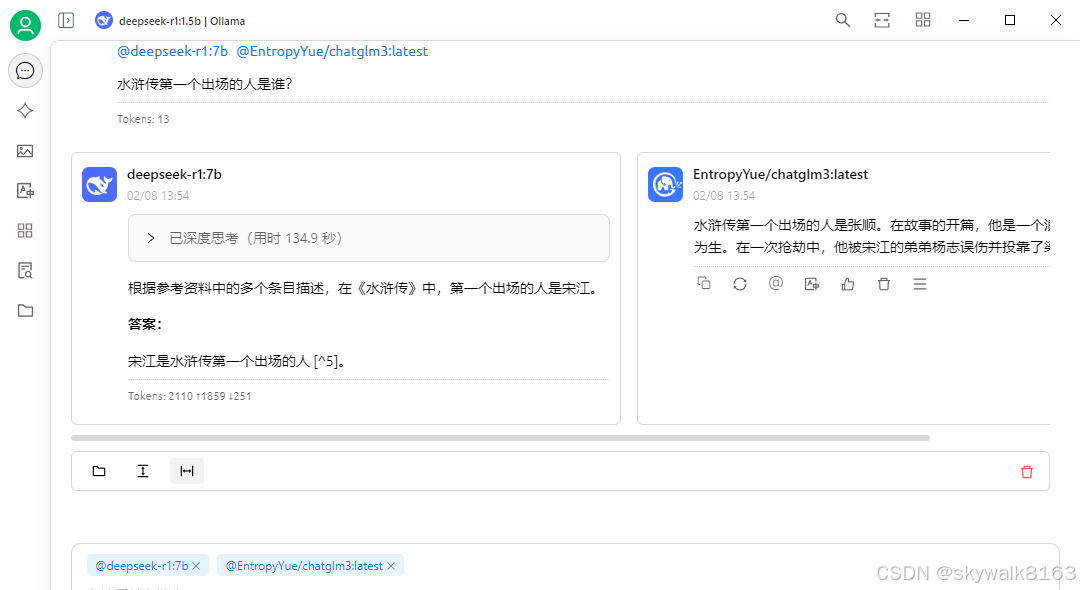
答案并不正确。
看来还需要继续调试。

















 2202
2202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









