








连续对打10回合,成功率达80%的机器狗长这样……
在机器狗运动控制领域,实现上下肢的协调配合一直是一项长期挑战,尤其是在高速、动态的真实交互环境中更是难上加难。
上周,ETH苏黎世联邦理工的研究团队在机器人顶刊 Science Robotics 上发布了重磅成果——《Learning coordinated badminton skills for legged manipulators》。他们提出了一套端到端的强化学习控制策略,使得四足移动操作机器狗不仅能自主完成感知、导航、挥拍等复杂动作,还能和人类选手进行真实羽毛球对打。
这项工作首次在全自主感知与控制框架下展示了机器狗应对高动态竞技任务的能力。论文所展现的系统融合了高频运动控制、多模态视觉感知与机械臂精细操作,展示了机器狗在运动学协调、主动感知行为以及部署鲁棒性等方面的一次系统性突破。

▲图1|Demo演示。机器人自信又熟练的挥拍,能够连续的接回高速飞来的羽毛球。仔细观察,机器人不仅仅是简单的把球打回去,从接球前的移动,对于球落点的预测,击球的飞行轨迹、弧度、高度可见整体系统协调性十分出色©️【深蓝具身智能】编译
从Demo和作者发布的视频来看,机器狗已经具备基本的实战能力,不仅能追球、挥拍、打回,还能完成连续多回合的对战交锋。具体是如何实现的?
本文将深入解析这项研究背后的方法路径、控制机制、训练设计以及关键实验结果,看看这个“羽毛球搭子”到底强在哪里。
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

要让机器人“像人一样打羽毛球”,并不是把腿、眼、手凑到一块就行了。问题的复杂性远超我们在实验室里调个关节、摆个pose的范畴。
首先,机器人要在极短时间内完成“看到球—预测轨迹—快速移动—精确挥拍”这一整套闭环流程,任何一个环节的延迟、误差或不协调都可能导致击球失败。
其次,感知系统受到相机视野、延迟与噪声的限制,控制系统又必须在不超电流、不失稳定的前提下高速响应,这对策略的协调性、实时性和鲁棒性都提出了极高要求。
为解决上述挑战,该项工作从感知、控制到部署全过程进行了系统设计:
基于强化学习的整身控制策略;
贴近真实的感知误差模型;
具备目标引导与物理约束的训练机制;
在真实环境中完成了高动态动作与连续击球的验证。
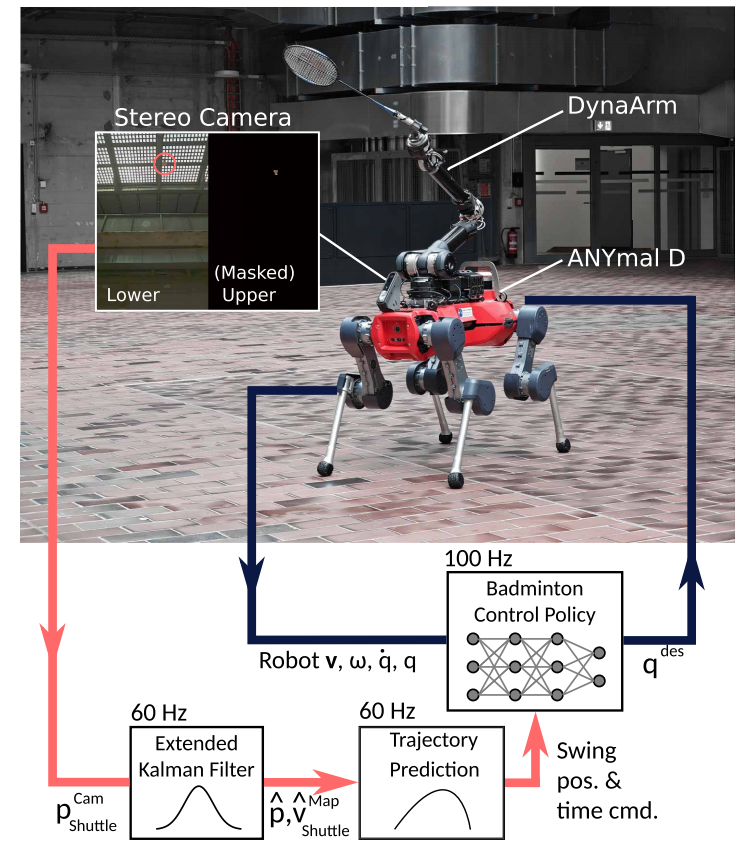
▲图2|系统结构总览。机器人由四足底盘+机械臂+立体相机组成,系统通过摄像感知、轨迹预测与整身控制策略实现对羽毛球的精准拦截与挥拍操作©️【深蓝具身智能】编译
接下来,我们将逐步拆解这些关键技术。

整身控制策略:统一关节调度的策略优化与奖励设计
论文中所提出的控制策略是一种基于强化学习的整身控制框架,其核心是利用PPO(Proximal Policy Optimization)算法,训练一个联合控制机器人 18 个关节的策略网络,使其能够在面对复杂羽毛球轨迹时自主完成走位与挥拍任务。
策略结构采用了非对称 Actor-Critic 架构:
-
Critic 能访问“特权信息”(privileged information),如球的真实位置和速度、未来轨迹等,从而获得更稳定的训练反馈;
-
Actor 则仅基于机器人部署时可获得的感知信息(如本体状态、预测击球点)进行动作输出。这种设计有助于提升训练效率,同时保持策略的实际可部署性。
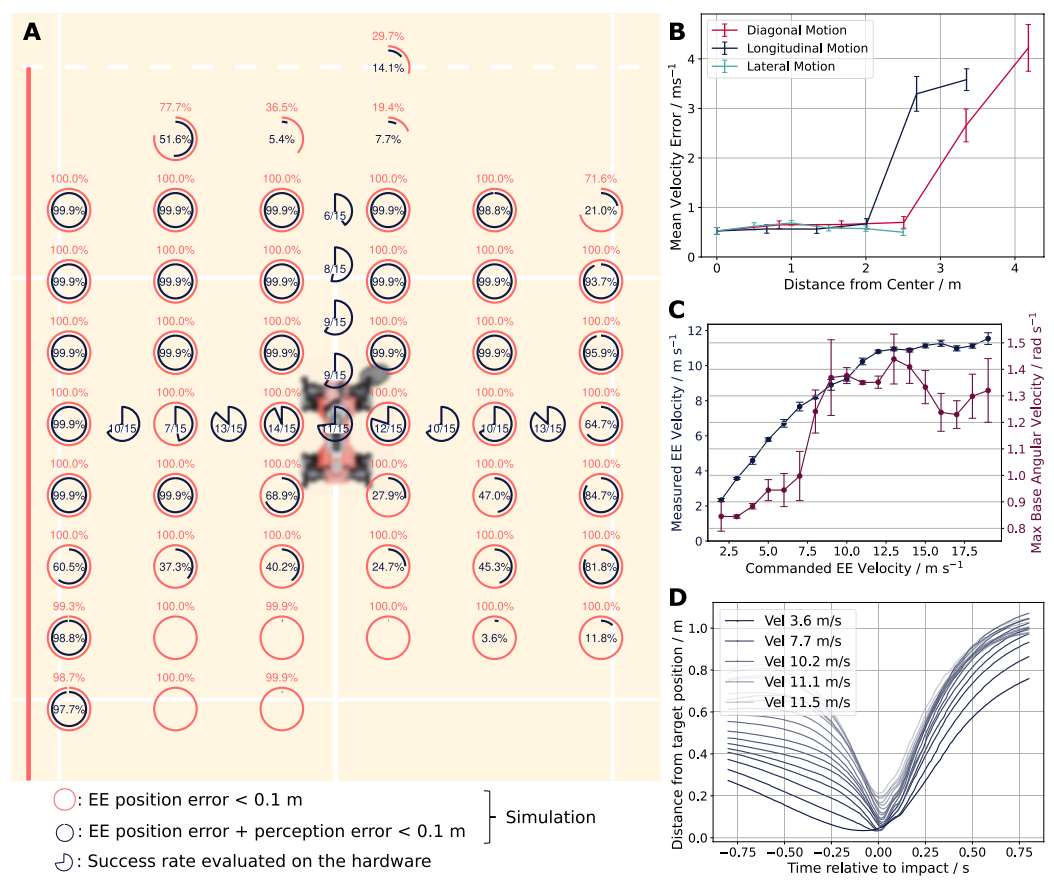
▲图3|机器人在球场不同位置的击球精度(A)、末端执行器速度跟踪误差(B)、实际挥拍速度与底盘角速度关系(C)以及拍面命中精准性(D)共同验证了强化学习策略对整身18自由度的高效调度能力,支持在动态目标下实现高精度、高速度、稳定的连续击球。©️【深蓝具身智能】
值得注意的是,奖励函数的设计在策略收敛中起到了关键作用。除了击中球的核心奖励外,还设计了多个辅助项,用于鼓励策略:
-
提前接近预测击球点;
-
控制步态稳定性,避免跌倒;
-
控制挥拍速度与角度以匹配球速;
-
在连续击球任务中维持身体状态稳定。
最终,策略能够在仿真中生成自然涌现的击球前移步、稳定挥拍、回正准备等行为,体现出良好的策略协调性与多回合适应性 。
感知建模:从视觉噪声到策略适应的主动感知机制
机器人配备的是前置的双目立体相机,具备30Hz图像采样频率。但由于羽毛球速度极快(可达每秒10-20米),即便微小的感知误差也会导致击球失败。
为增强策略对现实感知条件的鲁棒性,在训练中引入了一个基于实测数据回归的感知误差模型,该模型考虑了观测角度、距离、球速对测量误差的影响,并在仿真中为每次观测引入高斯噪声扰动。

▲图4|机器人感知演示。通过算法机器人可以在双目系统中稳定的追踪飞过来的羽毛球,并清除其它无关物体的干扰,从而实现对于高速运动的羽毛球的“注视”效果。©️【深蓝具身智能】编译
更重要的是,这一机制驱动策略在训练中自然发展出主动视觉行为(active visual behavior)——
机器人学会通过躯干姿态调整保持球在视野中央,甚至在击球前进行微调站位,以减少预测误差。
这实际上是一种机器人对人类行为的模仿学习。众所周知,在接球之前要“架拍”,随后在球飞行的过程中自身就要开始往最佳接球点进行移动,同时保持对球的注视观察,这个过程也被机器人完美的学习和掌握。

▲图5|接球前的微调。注意看机器人在接球前的瞬间对自身位置进行了微调,移动到最恰当的位置以保证用最佳的姿态和角度对羽毛球进行击打©️【深蓝具身智能】编译
此外,感知模块还包括:
-
轨迹估计器:将历史观测拟合为三次多项式轨迹;
-
拦截点预测器:以时域方式预测未来击球最佳位置;
-
估计器融合:使用低延迟观测估算当前状态,并补偿感知与控制之间的时间差。
这一设计保证了即便感知存在延迟与误差,策略依然能基于“信得过”的信息做出高精度决策。
多目标击球机制:学习击球节奏与连续动作生成
单次击球的成功不足以支撑一个真正具备实战能力的机器人。
为此,提出了一个多目标摆动训练范式(multi-target swing training paradigm)——
每个训练回合中机器人需连续完成多次击球,模拟真实对战中的回合场景。这也是小编在引言中提到的,该机器人在连续回合战也能够表现出色的原因。


▲图6|多目标击球条件下的步态适应与时序协调能力。面对不同距离和紧急程度的连续击球任务,机器人根据目标位置自适应调整步态策略。在中短距离下采用稳定步态完成快速击球(B/C),而在较远距离下(A)则采用高频奔跑并协调躯干与臂部姿态完成目标覆盖。在时间窗口极短的条件下,尽管击球失败(E),策略仍能保持躯干稳定性,展示了对身体极限的自适知觉与鲁棒控制能力。这一序列验证了多目标训练机制下策略在“走-打-回”全过程中的连贯性与实用性。©️【深蓝具身智能】编译
在具体实现中,每次击球后将新的羽毛球目标“重置”到新的轨迹上,要求机器人快速完成上一动作后的回位、重新感知并进入下一轮挥拍状态。这使得策略不得不学习:
-
击球后的姿态收敛;
-
过渡动作的快速调度;
-
下一球的预测与身体重新定位。
通过这一机制训练出的策略,在真实部署中能完成 10 拍以上的连续对打,展现出近似人类球员的节奏控制能力与连续决策能力。
此外,策略还优化了挥拍时间窗口和挥拍轨迹,使得击球速度高达每秒12米,击球成功率在挑战条件下仍保持在 80% 以上 。
Sim-to-Real机制与部署工程化:全链条感知—控制闭环实现
前面我们说了许多细节技术上的内容,相信大家一定发现了,这些都是Learning-based方法。
那么机器人是如何进行训练,又是如何从仿真走向实物部署的呢?
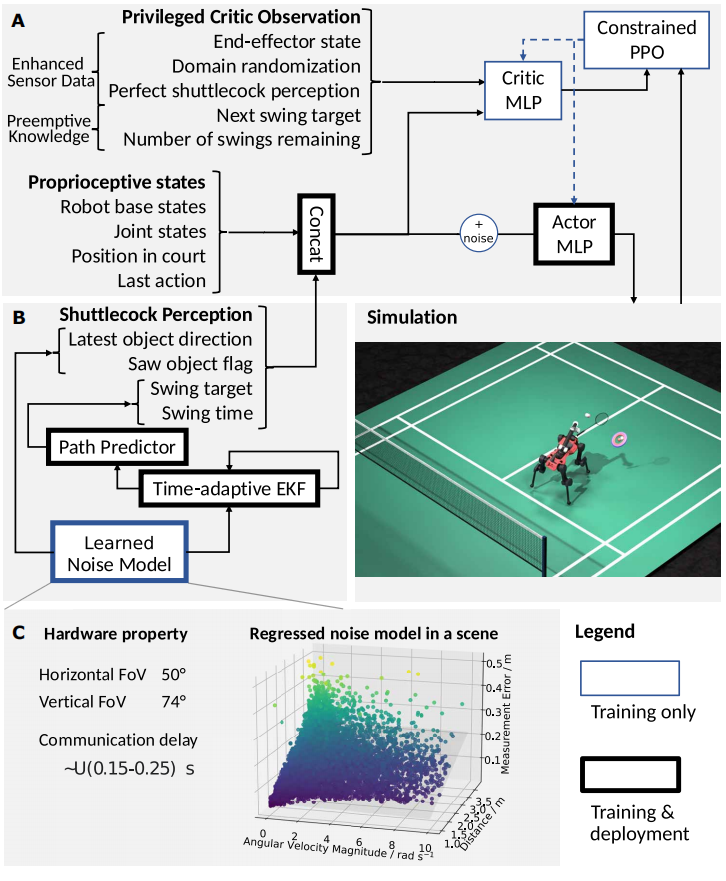
▲图7|训练方法总览。训练中采用非对称 Actor-Critic 架构,策略接收带噪本体状态与感知输入,Critic访问特权信息以提升估值准确性(A)。仿真感知模块基于真实相机数据构建噪声模型,并在训练与部署中统一使用EKF与轨迹预测器,确保感知—控制闭环在仿真与实物之间的一致性(B)©️【深蓝具身智能】编译
我们先看上图。实际上,从sim到real,最关键的是确保感知估计与控制策略之间的信息一致性。
论文在Sim-to-Real转移方面采用了多项工程设计:
-
使用扩展卡尔曼滤波器(EKF)对球的状态进行估计,将轨迹估计与机器人本体状态同步;
-
所有感知预测模块(含轨迹回归器、击球点预测器)与部署中使用的版本保持完全一致,策略训练时使用的感知输入即为部署中生成的估计值,确保zero-shot迁移;
-
控制策略引入了电流限制、最大角速度限制等真实硬件约束,避免策略生成过于激进的动作;

▲图8|虚拟环境训练演示。在虚拟环境中机器人进行成千上万次的击球模拟,获得一个初步的击球综合能力的先验。©️【深蓝具身智能】编译
整个系统运行在Jetson AGX Orin上,感知模块60Hz更新,控制策略以100Hz频率运行,实现高动态下的低延迟响应 。

▲图9|显示环境训练演示。完成在虚拟环境中的训练之后,掌握了初步技能的机器人再来到真实的物理世界进行大量的学习,逐步提升自身的技术水平,从而实现对于羽毛球技能从sim到real的泛化©️【深蓝具身智能】编译
这一整套部署机制有效解决了感知延迟、估计误差与策略不一致带来的稳定性问题,使得机器人能在标准球场上与人类完成实战对打。
实验结果
在一系列仿真与真实环境下的实验中,全面评估了所提出整身控制框架在复杂羽毛球任务中的表现。
机器人不仅能够连续完成多轮与人类选手的真实对打,展现出节奏稳定、姿态协调的击球能力,还在不同目标位置下保持了较高的拦截成功率和出色的速度控制性能。
实测数据显示,机器人可实现最高12.06 m/s的挥拍速度,拍面在命中瞬间与目标位置的误差控制在厘米级,时间偏差低于11毫秒,体现出策略在高速动态下的高精度调度能力。

▲图10|室外场景与人类对练©️【深蓝具身智能】编译
更关键的是,通过在训练中引入基于真实相机数据拟合的感知噪声模型,策略学会了主动调整姿态以优化感知质量,从而有效缩小了感知与控制之间的时延误差。
此外,机器人还能根据不同目标距离和时间约束,自主选择步态模式,从原地微调到高速奔跑,表现出良好的动作自适应性。
整套系统在部署中展现出高稳定性与硬件约束下的鲁棒控制,室内室外各种场景都能和人类选手打的“有来有回”,除了不能跳起来扣球(可能也不远了),已经是一个比较合格的“羽毛球搭子”了。
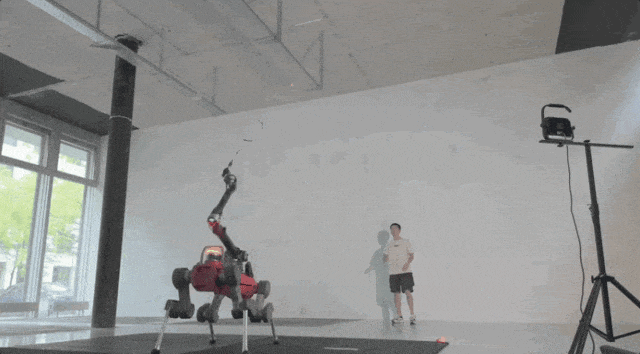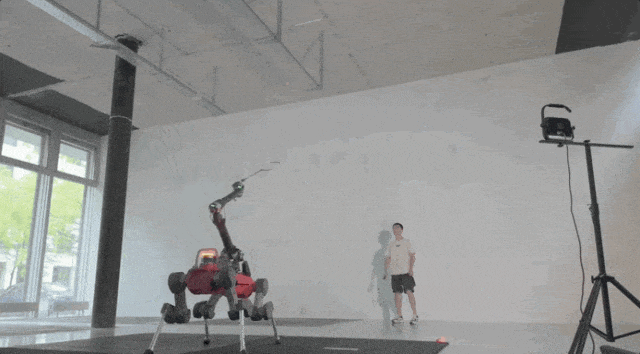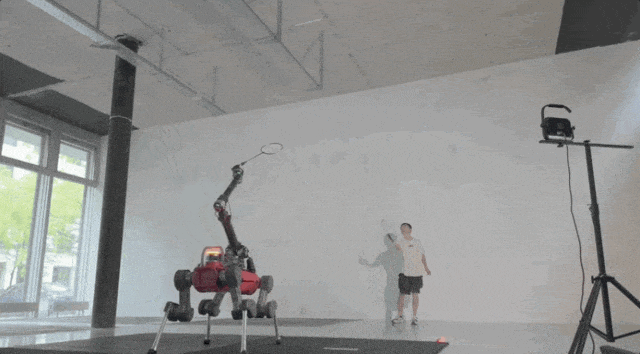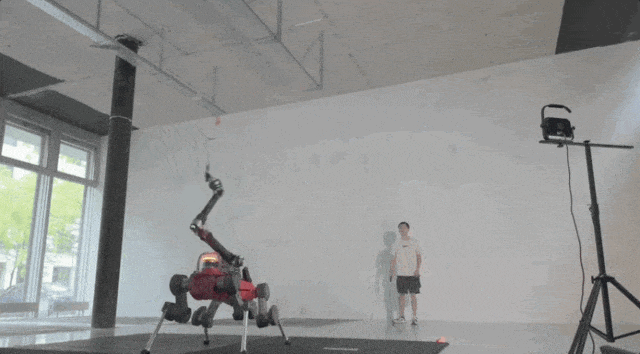
▲图11|室内场景与人类对练©️【深蓝具身智能】编译

从感知延迟到姿态控制,从整身协调到连续击球,这项研究系统性地解决了“机器人如何打好羽毛球”这一看似离谱却技术门槛极高的问题。
该项工作展示的并不仅仅是一套能动起来的控制策略,更是一种真正具备时序规划、感知自适应与实战部署能力的整身智能系统。机器人不仅能准确预判来球、快速移动定位,还能完成高速、高精度的挥拍回击。
而话又说回来,狗都会打羽毛球了,那人形机器人还会远吗?未来的人形伙伴,或许不仅能陪你做饭、干活,还能在你下班后随时来一场酣畅淋漓的对打。
比起总找不到球搭子的烦恼,你会愿意选择这样一位永不爽约、不带情绪波动、不会动不动就跳起来把你杀的人仰马翻的“AI球友”吗?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









