







说明:
1. 这个谷歌在udacity上开设的一门deeplearning免费课程,可以通过这个链接访问,笔记中所有的文字和图片都来自这门课,在此感谢这些大牛们的免费分享
2. 这是我自己的学习笔记,错误和遗漏之处肯定很多,还有一些细节没有解释。另外,有些地方直接把英文复制过来是因为理解很简单或者我自己理解不了。
3. 笔记目录:
- L1 Mechine Learning to DeepLearning
- L2 DEEP NEURAL NETWORK
- L3 CONVOLUTIONAL NEURAL NETWORKS
- L4 TEXT AND SEQUENCE MODEL
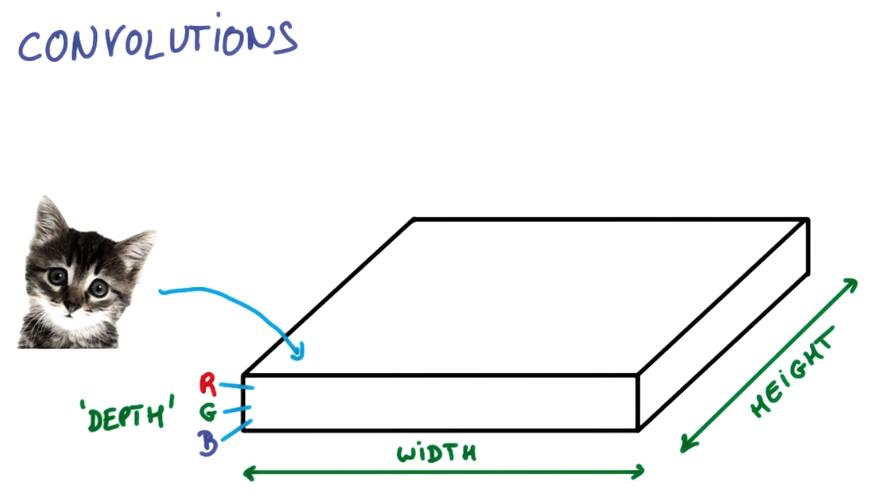
Color
彩色的就不赘述了
对于颜色无关的分类才说,一般采用灰度值,灰度值的计算就是mean(R+B+G)
平移不变性Translation invariance
Explicitly, that objects and images are largely the sanme whether they are on the left or on the right of the picture. That’s what’s called translation invariance
If you’re trying to network on text, maybe you want the part of the network that learns what a kitten is to be reused every time you see the word “kitten”, and not have to relearn it everytime.
The way you achieve this in your own network is using what’s called “weight sharing”. When you know that two inputs can contain the same kind of information, the you share the weights and train the weight jointly for these inputs.
Statistical invariants things that don’t change on average across time or space are everwere.
统计不变性司空见惯:事物的平均值不会随时间和空间改变。
CONVOLUTIONAL NETWORK
Convnets are neural networks that share their parameters across space.
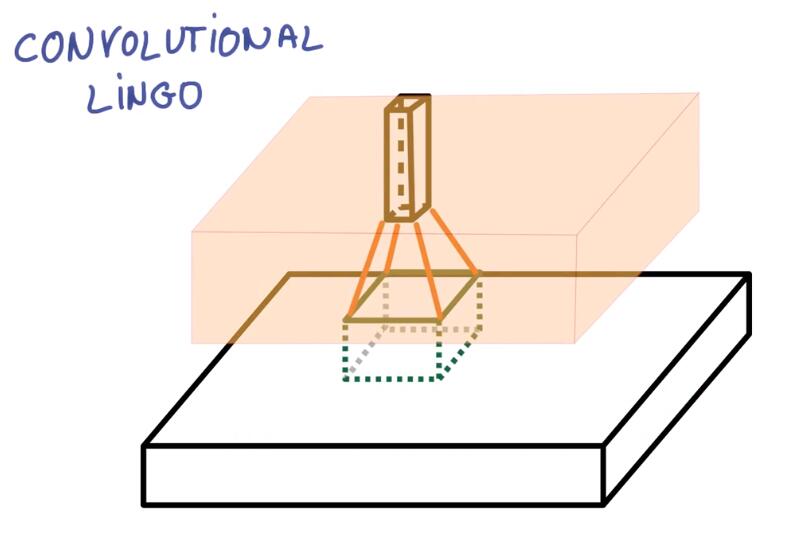
Now imagine taking a small patch of this image and running a tiny neural networks on it, with say, K outputs.
卷积核是一个具有K个输出的小神经网络
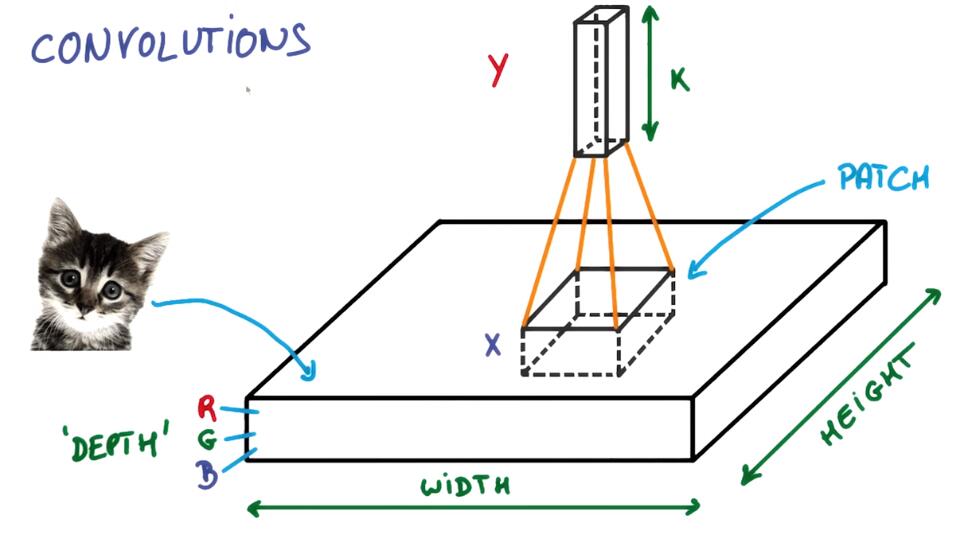
Let’s represent those outputs vertically, in a tiny column like this.
像这样把输出表示为垂直的一列
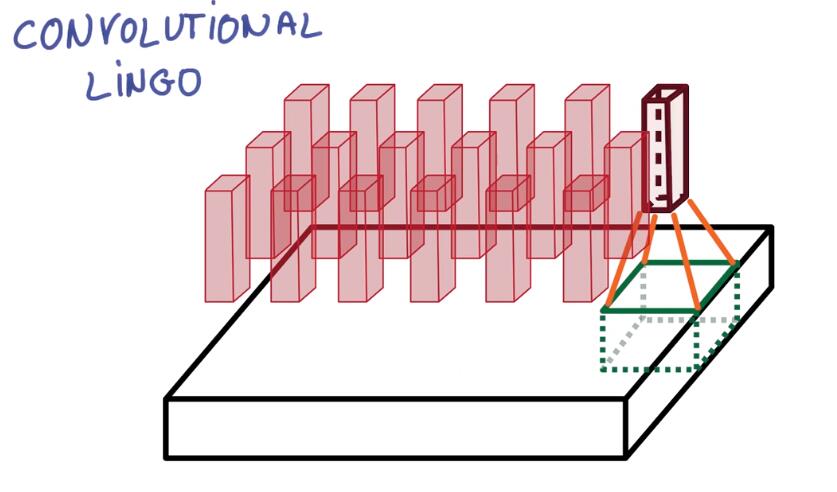
Let’s slide that little neural network across the image without changing the weights. Just slide across and vertically like we’re painting it with a brush.
通过权重共享遍历整张图片,过程参考下面的动图
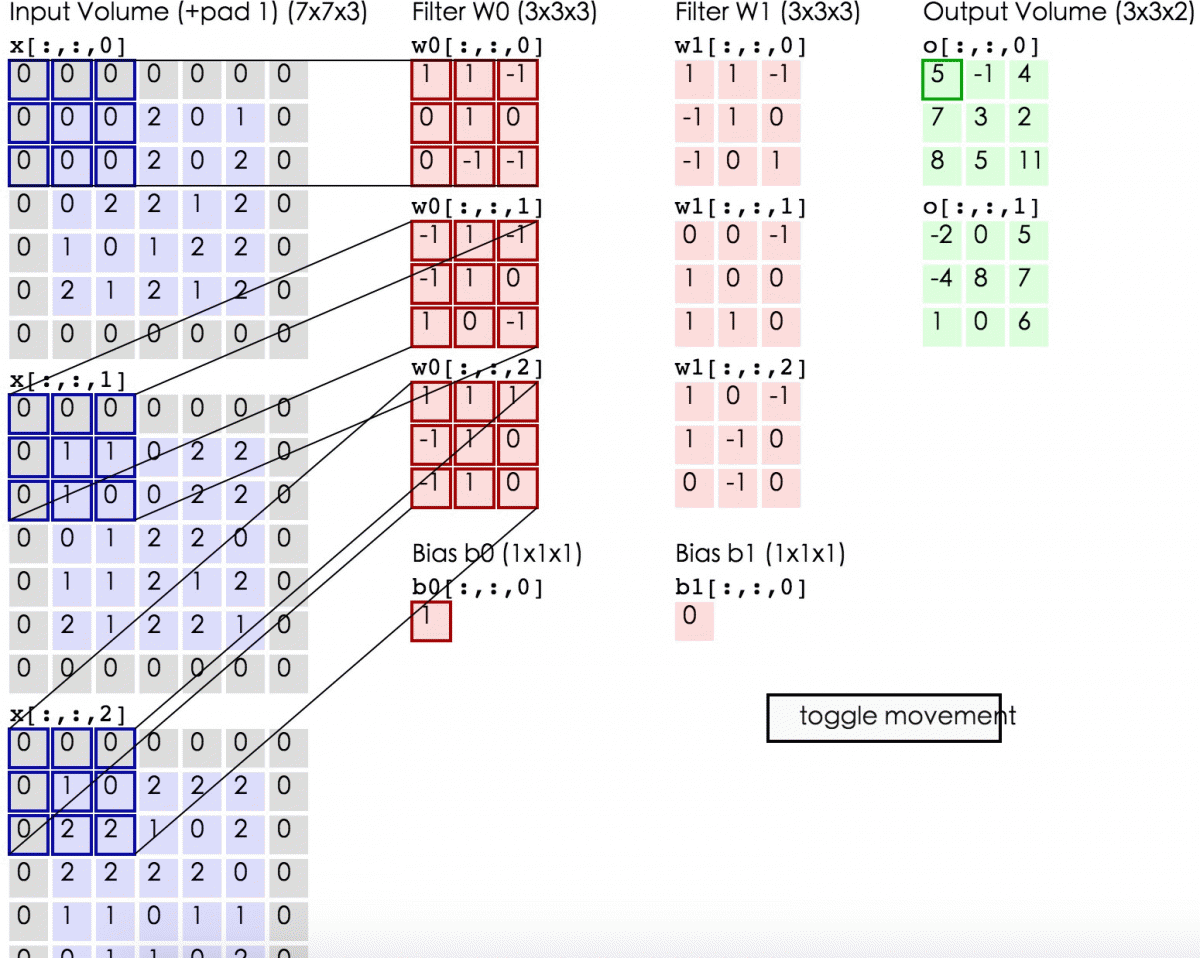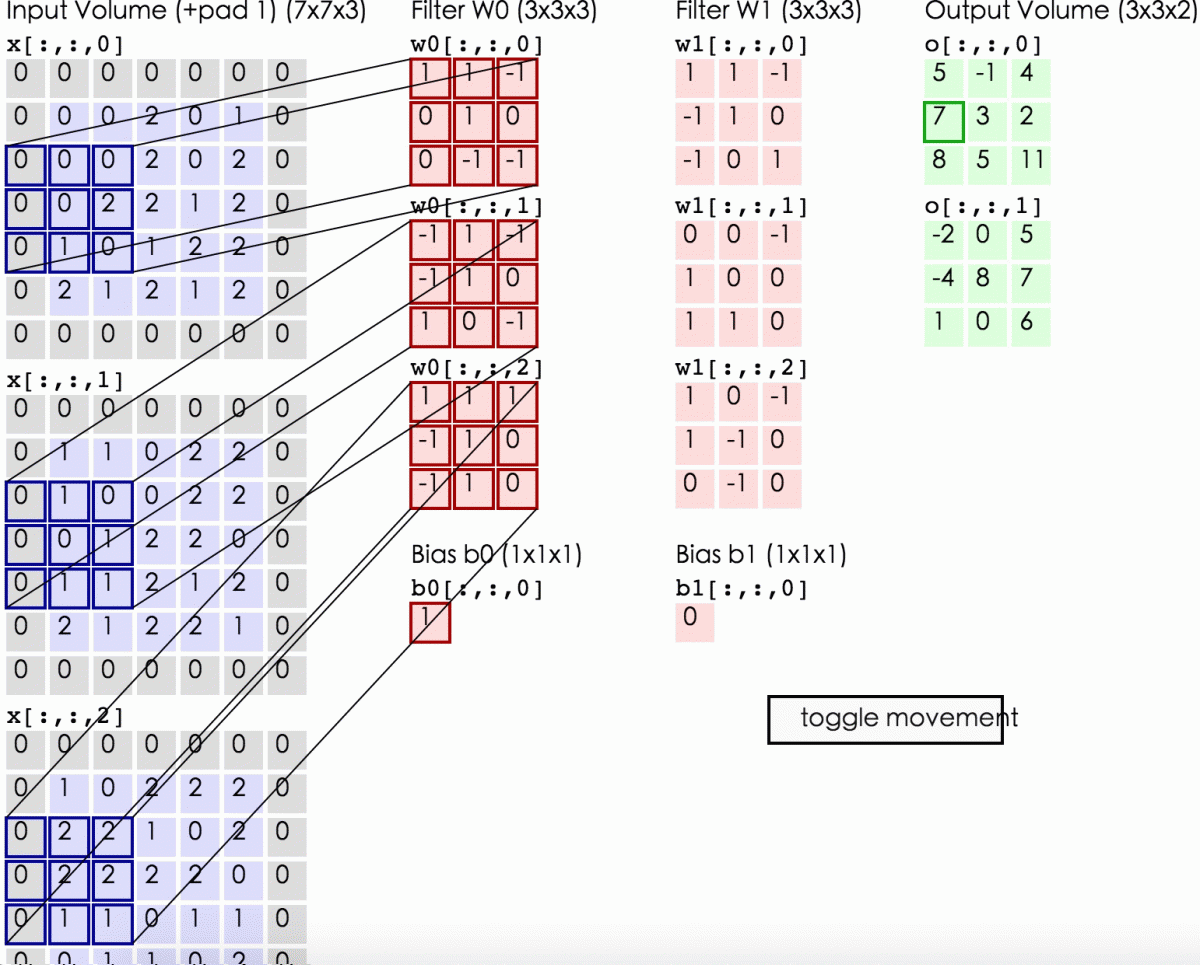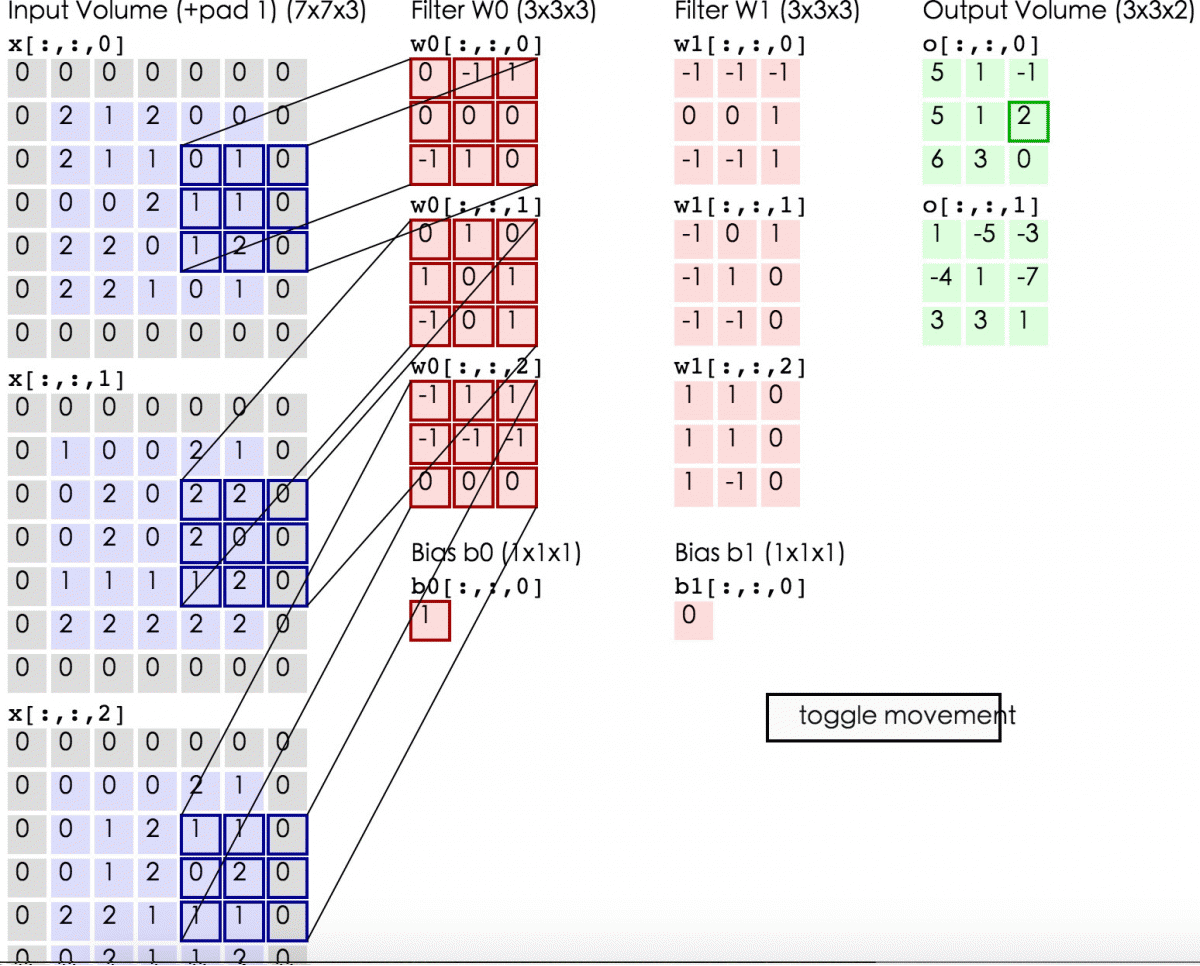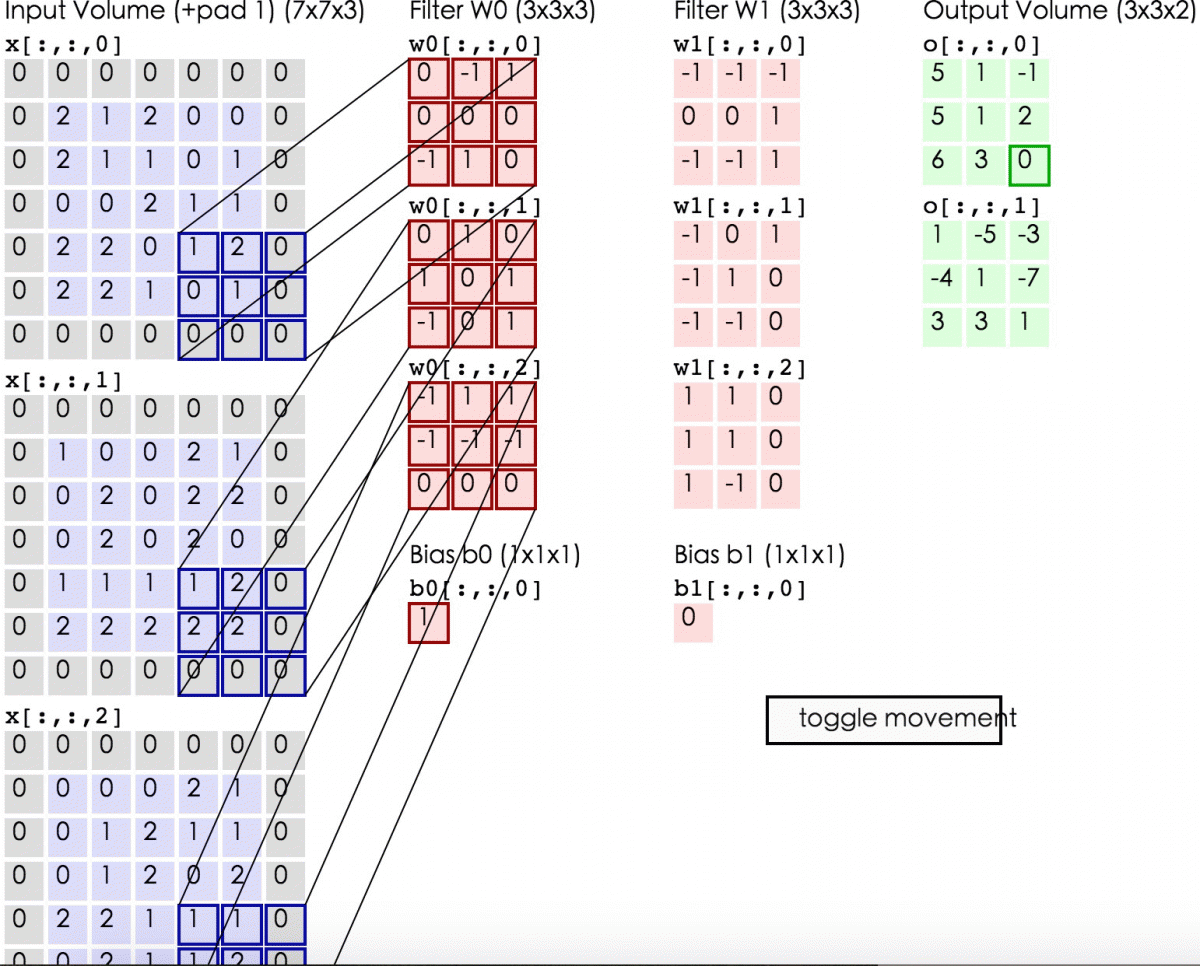
On the output, we’ve drawn another image. It’s got a different width, a different height, and more importantly, it’s got a different depth. Instead of just R, G and B, now you have an output that’s got many color channels, K of them.
我们得到了一个不同宽高,最重要的是不同深度的image。
This operation is called a convolution.
Because we have this small patch instead, we have many fewer weights and they are shared across space.
使用共享权重的卷积核是我们有更少的参数。
A convnet is going to basically be a deep network where instead of having stacks of matrix multiply layers, we’re going to have stacks of convolutions.
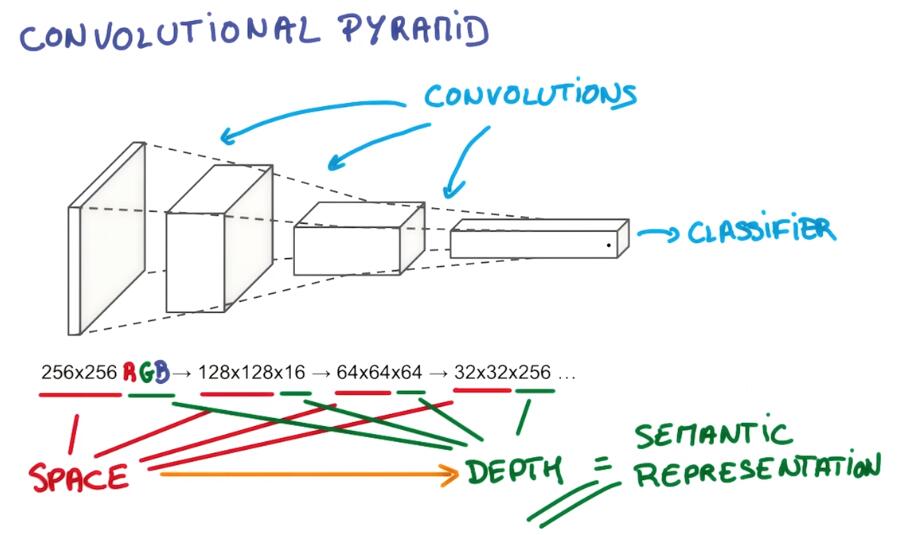
In Convnet, You’re going to apply convolutions that are going to progressively squeeze the spatial dimensions while increasing the depth, which corresponds roughly to the semantic complexity of your representation. At the top you can put your classifier. You have a representation where all the spatial information has been squeezed out and only parameters that map to contents of the image remain.
在卷积网络中,通过卷积逐步挤压空间的维度,同时不断增加深度,使深层信息基本上可以表示出复杂的语义。在最顶端的分类器中,所有的空间信息被压缩成一个标识,只有图片映射到不同类的信息得以保留。
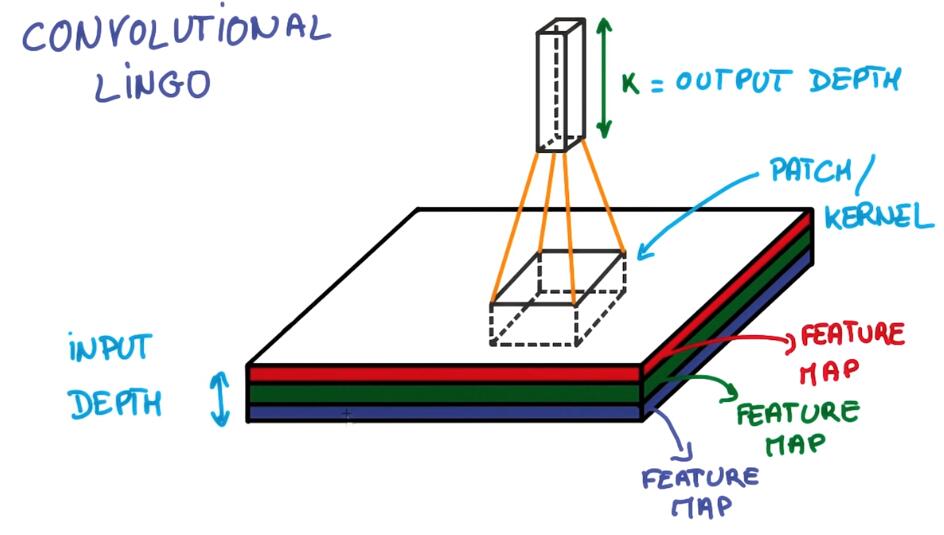
kernels、feature map就不再多做解释了
在卷积网络中需要注意的参数:
Stride :It’s the number of pixels that you’re shifting each time you move your filter.
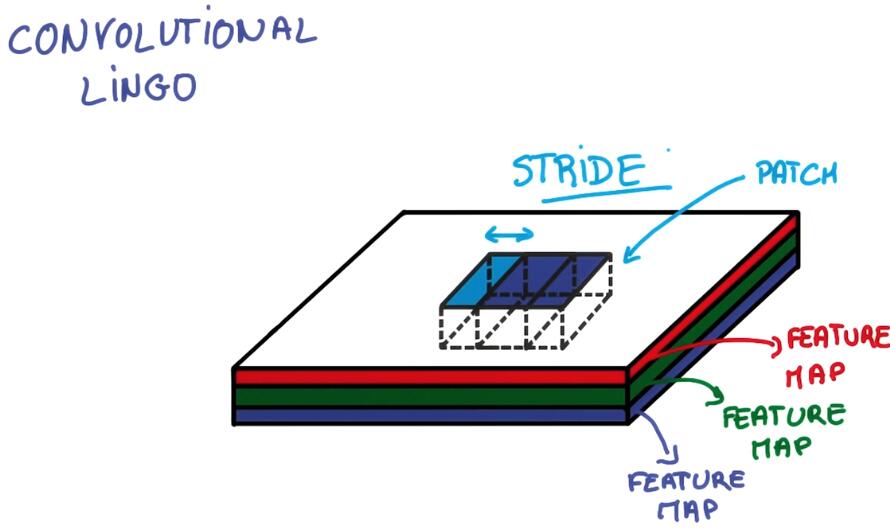
Stride = 1 基本和输入相同
Stride = 2 尺度变为输入的一半
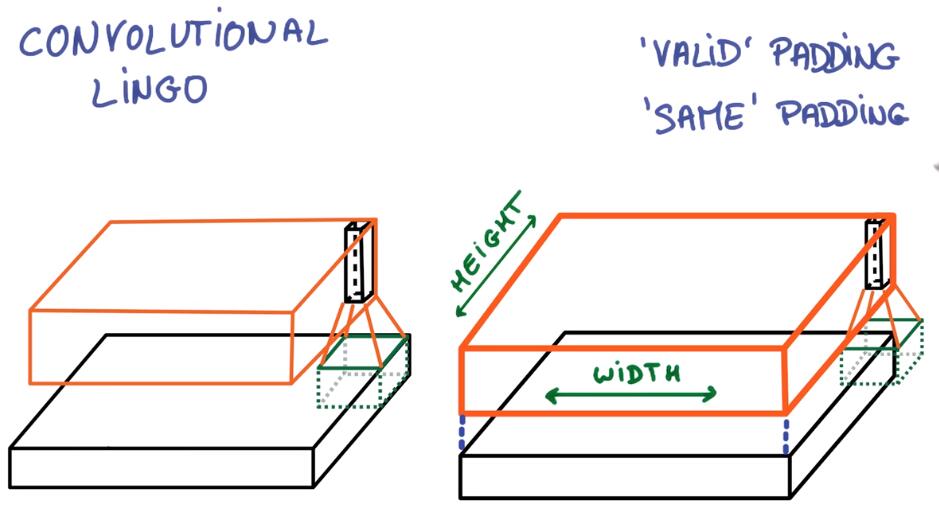
Padding
VALID PADDING : don’t go past the edge 不超过边界
SAME PADDING : go off the edge and pad with zeo 超过边界的用0填充,输出和输入大小一致
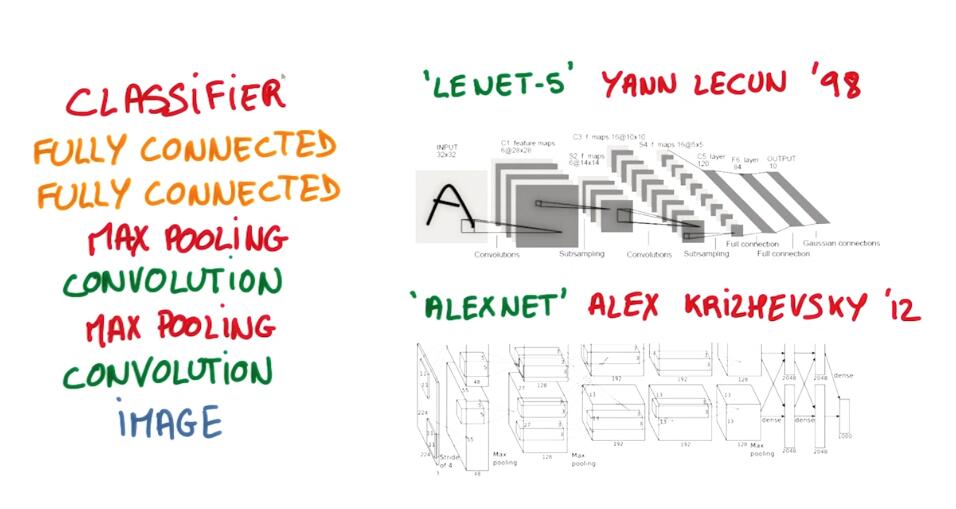
A classical CNNs
Stack up you convulsions, then use trieds to to reduce the dimensional ID and increase the depth of your network, layer after layer. And once you have a deep and
narrow representation, connect the whole thing to a few regular fully connected layers and you’re ready to train your classifier.
卷积网络的结构:叠加卷积层,进行将为,提高网络深度,然后链接到全连接层,这样就可以训练分类器的。
Explore The Design Space提升网络性能的方法
主要介绍三种方法:
Pooling
1 x 1 convolutions
Inception architecture
Pooling
The most common is max pooling.
max pooling: At every point in the future map, look at a small neighborhood around that point and compute the maximum of all the responses around it.
优点:
PARAMETER-FREE: 没有增加参数数量,不用担心过拟合
OFTEN MORE ACCURATE:简单地产生了更精确的模型
缺点:
MORE EXPENSIVE : 更多计算量
MORE HYPER PARAMETERS 更多超参数需要tune,比如pooling size, pooling stride
A very typical architecture for a covenant is a few layers alternating convolutions and max pooling, followed by a few fully connected layers at the top.
还有一种方法就是mean pooling ,这个更类似与降低分辨率
1 X 1 convolution
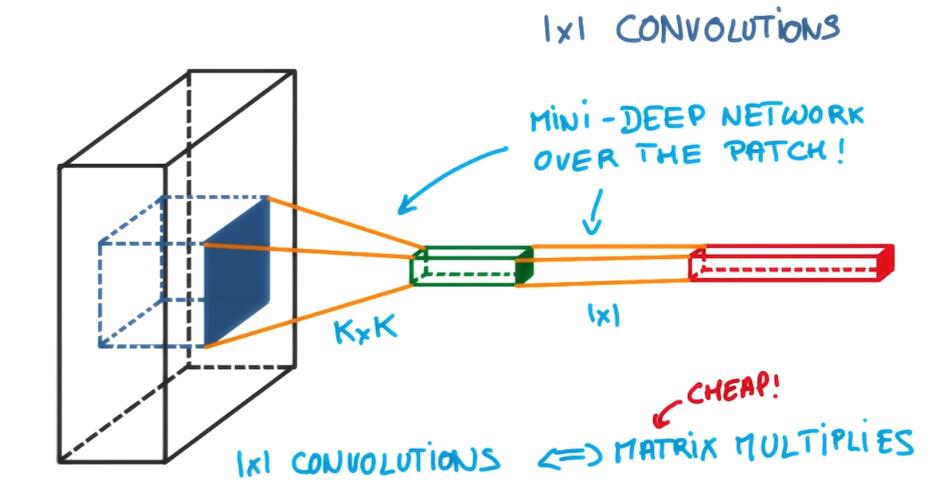
At the classic convolution setting, It’s basically a small classifier for a patch of the image, but it’s only a linear classifier. But if you add a one by one convolution in the middle, suddenly you have a mini neural network running over the patch instead of a linear classifier.
传统的卷积网络中的卷积核操作仅仅是一个线性分类,但是加上一个1X1卷积后,变成了一个小神经网络。
Interspersing your convolutions with one by one convolutions is a very inexpensive way to make your models deeper and have more parameters without completely changing their structure. They’re really just matrix multiplies, and they have relatively few parameters.
这是一种高效低耗的方式,网络的层数更深,参数更多,却没有改变网络的结构。
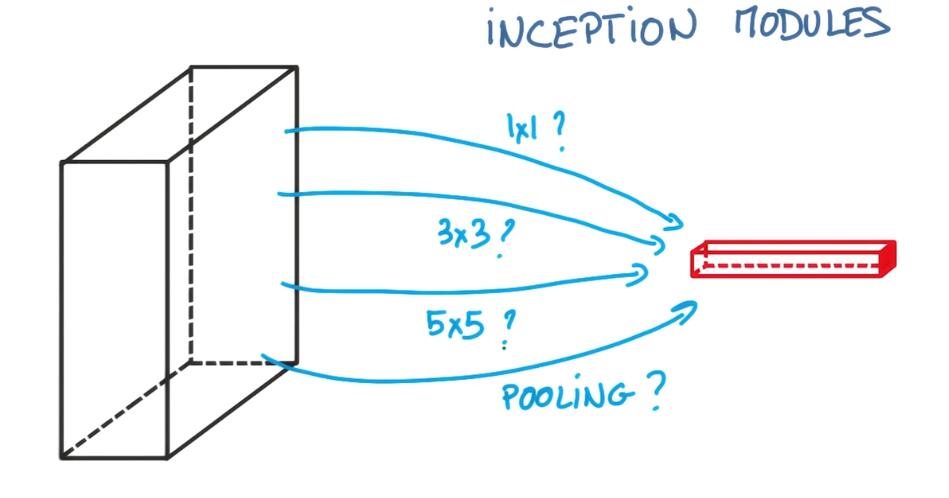
Inception module
The idea is that at each layer of your cognate you can make a choice. Have a pooling operation, have a convolution. Then you need to decide is it a 1 by 1 convolution, or a 3 by 3, or a 5 by 5? All of these are actually beneficial to the modeling power of your network.
这种方法就是让你决定在网络中选择什么样的结构,卷积?或者pooling,或者不同形式的卷积,pooling。
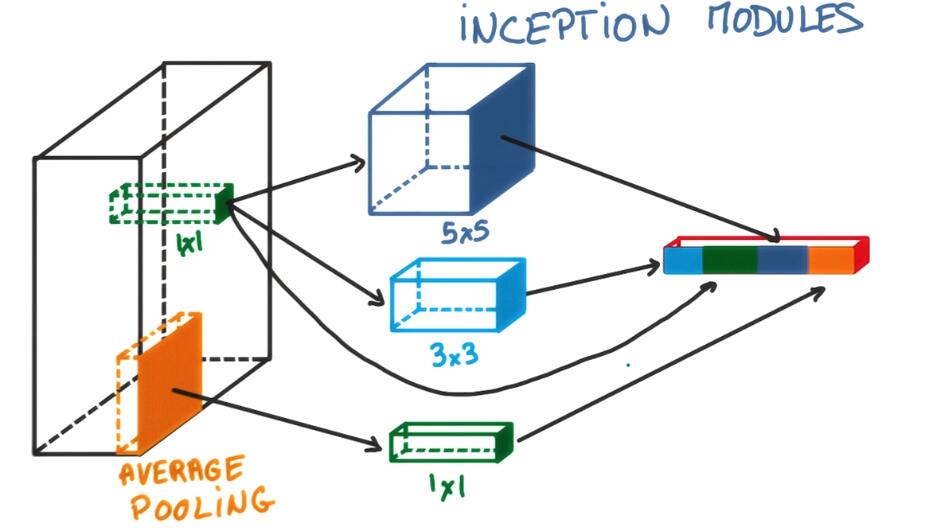
It looks complicated, but what’s interesting is that you can choose these parameters in such a way that the total number of parameters in your model is very small. Yet the model performs better than if you had a simple convolution.















 1360
1360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









