







大模型(Qwen2.5_Coder_3B) GRPO训练教程
本教程主要目的是完成 在 AutoDL 的GPU服务器 4090 上,对 大模型(Qwen2.5_Coder_3B)进行GRPO训练,所使用的数据集是 “gms8k”。
当然,也可以使用其他类型的GPU,实现训练过程中 24G的显存也会用到了7G, 模型可以完美切换到其他Qwen模型进行微调,我这里只是为了演示选择了较少的3B模型。
教程内容
本教程将介绍以下内容:
- AutoDL配置 - 如何启动相应配置的GPU实例
- 安装依赖库 - 如何安装python依赖包
- 模型准备 - 如何下载和初始化模型
- 数据准备 - 如何准备和处理训练数据
- 模型训练 - 如何训练和优化模型
- 模型保存 - 如何保存训练结果
- 模型推理 - 如何使用训练好的模型进行推理
【本教程代码 】: https://github.com/songxia928/LLM/blob/main/02_%E5%A4%A7%E6%A8%A1%E5%9E%8BQwen2.5_GRPO%E8%AE%AD%E7%BB%83.ipynb
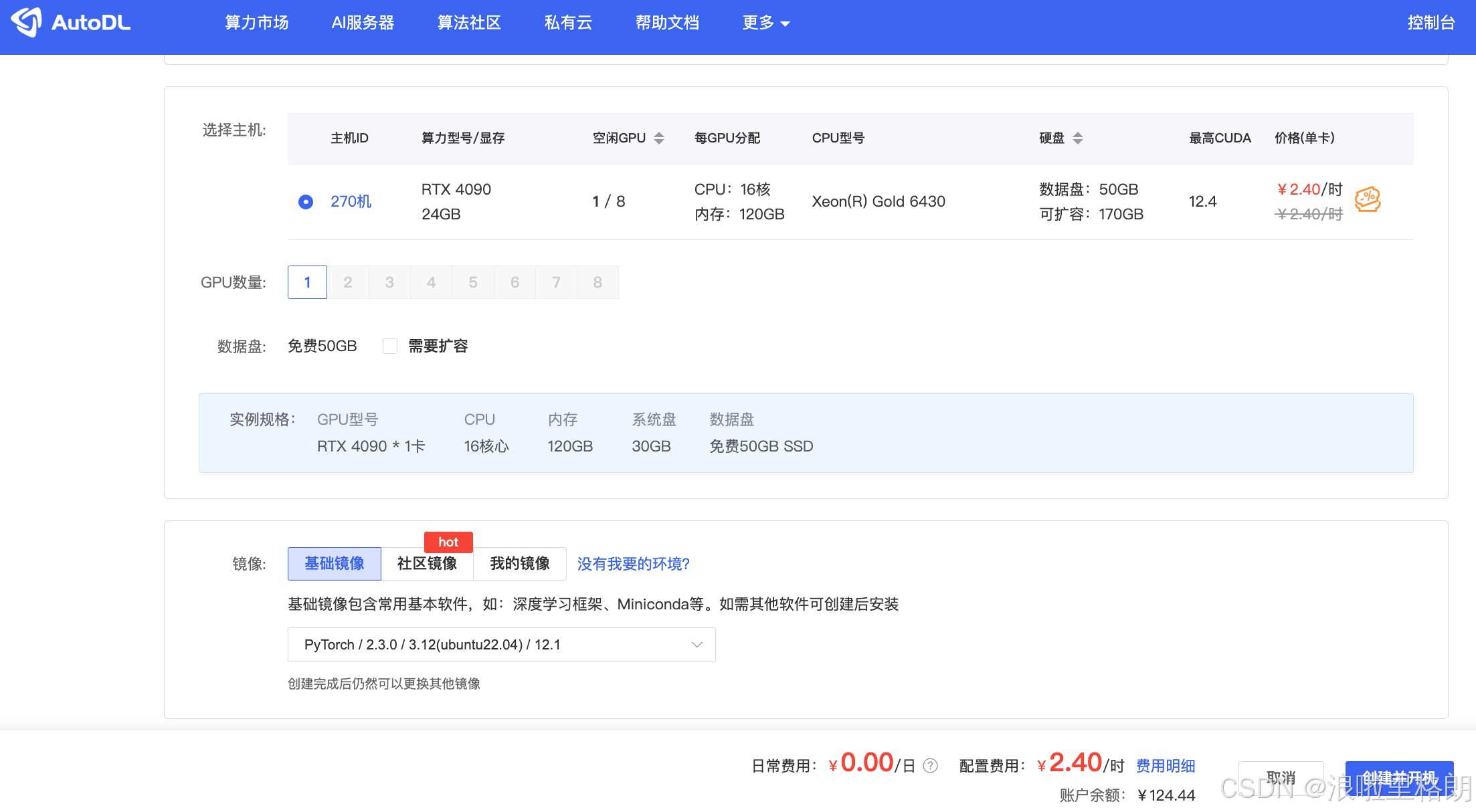
0.AutoDL配置
- 为什么选择 AutoDL?: 相对于其他云服务器厂商,AutoDL卡相对便宜很多,而且操作相对简单,上手成本很低。
- 如何配置?:
- GPU: RTX 4090(24GB) * 1。
- 镜像: PyTorch 2.3.0 --> Python 3.12(ubuntu22.04) --> CUDA 12.1
1.安装依赖库
!pip install unsloth vllm modelscope datasets
!pip install --upgrade packaging # 新增依赖升级
!pip install peft
2.模型准备
下面代码是直接从模型文件中读取,模型文件下载的部分可以参考上一篇文章 “大模型(Qwen2.5_Coder_3B) 指令微调教程” 的 “2.1下载模型”。
2.1 模型加载
from unsloth import FastLanguageModel
PatchFastRL("GRPO", FastLanguageModel)
# 基础配置参数
max_seq_length = 2048 # 最大序列长度
dtype = None # 自动检测数据类型
load_in_4bit = True # 使用4位量化以减少内存使用
lora_rank = 64 # 选择任何大于 0 的数, 建议 8, 16, 32, 64, 128
# 加载预训练模型和分词器
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = local_dir, # "unsloth/Qwen2.5-Coder-32B-Instruct", # 选择Qwen2.5 3B指令模型
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank, # LoRA秩,控制可训练参数数量
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",], # 需要训练的目标模块
lora_alpha = lora_rank, # LoRA缩放因子
lora_dropout = 0, # LoRA dropout率
bias = "none", # 是否训练偏置项
use_gradient_checkpointing = "unsloth", # 使用梯度检查点节省显存
random_state = 3407, # 随机数种子
use_rslora = False, # 是否使用稳定版LoRA
loftq_config = None, # LoftQ配置
)
hugging face 也有对应的模型,但是AutoDL不能直接访问 hugging face,可以在本地PC下载,再上传到AutoDL,如下面的方式。但是这种方式比较复杂,不推荐。
2.2 未经过 GRPO 训练的模型推理
import torch
from transformers import GenerationConfig
# 应用聊天模板
text = tokenizer.apply_chat_template([
{"role": "user", "content": "How many r's are in strawberry?"}
], tokenize=False, add_generation_prompt=True)
# 配置生成参数
generation_config = GenerationConfig(
temperature=0.8,
top_p=0.95,
max_new_tokens=1024,
)
# 将文本转换为输入张量
input_ids = tokenizer(text, return_tensors="pt").input_ids.to(model.device)
# 使用标准的 generate 方法生成输出
with torch.no_grad():
output = model.generate(
input_ids=input_ids,
generation_config=generation_config
)
# 解码输出
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
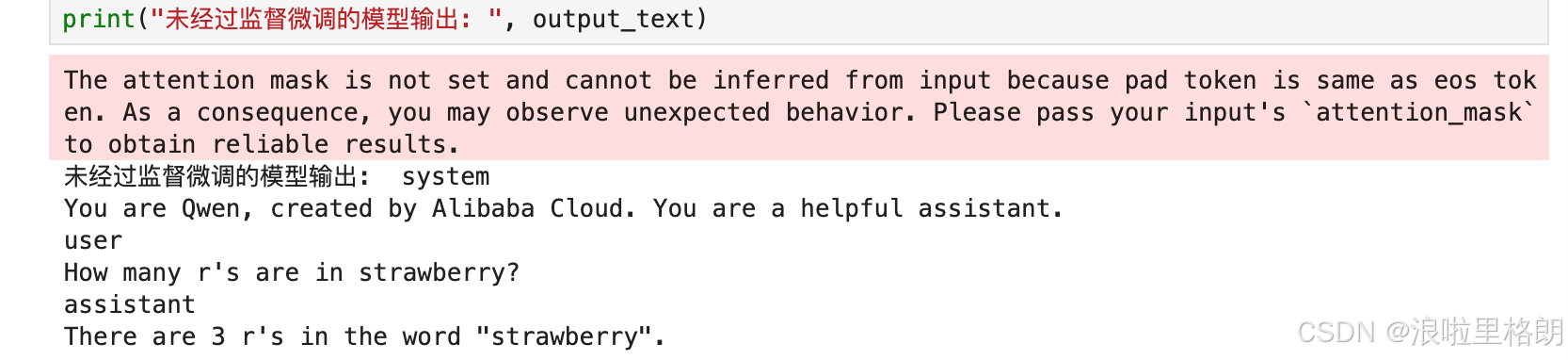
print("未经过监督微调的模型输出: ", output_text)
3. 数据准备
3.1 本地PC准备步骤
datasets 是 Hugging Face 提供的用于加载和处理各种数据集的库。AutoDL上无法直接访问 Hugging Face。 因此数据集 “mlabonne/FineTome-100k” 需要在本地PC下载后,从AutoDL的“文件存储”上传到你所使用的实例存储位置。
本地可以科学上网后,安装 pip install datasets 后,然后运行下面代码。
from datasets import load_dataset
import json
# 下载 gsm8k 数据集的训练集
dataset = load_dataset('openai/gsm8k', 'main', split='train')
# 保存为 JSON 文件
with open('./datasets/gsm8k/gsm8k_train.json', 'w', encoding='utf-8') as f:
for example in dataset:
json.dump(example, f, ensure_ascii=False)
f.write('\n')
如果不能科学上网,无法下载对应数据集,我这里也提供了依据下载好的。链接: https://pan.baidu.com/s/1ftrbEn7FHZaYG3CjXEkqzA?pwd=sakn 提取码: sakn 。
随后需要将下载的数据上传到AutoDL 对应的位子 “./datasets/gsm8k”。
3.2 数据加载
# 本地数据集路径(请提前上传到AutoDL的 /auto-fs/datasets目录)
import re
import json
from datasets import Dataset
# 加载并准备数据集
SYSTEM_PROMPT = """
响应格式如下:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""
def extract_xml_answer(text: str) -> str:
"""从文本中提取 XML 格式的答案"""
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
def extract_hash_answer(text: str) -> str | None:
"""从文本中提取带有哈希的答案"""
if "####" not in text:
return None
return text.split("####")[1].strip()
'''
def load_local_gsm8k(file_path="./datasets/gsm8k/gsm8k_train.json"):
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
return Dataset.from_list(data)
'''
def load_local_gsm8k(file_path="./datasets/gsm8k/gsm8k_train.json"):
data = []
with open(file_path, "r", encoding="utf-8") as f:
for line in f:
data.append(json.loads(line.strip())) # 逐行加载
return Dataset.from_list(data)
# 加载本地数据集
dataset = load_local_gsm8k()
# 处理数据集
def process_dataset(data):
data = data.map(lambda x: {
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
})
return data
dataset = process_dataset(dataset)
# 奖励函数
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
"""正确性奖励函数"""
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
def int_reward_func(completions, **kwargs) -> list[float]:
"""整数奖励函数"""
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""严格格式奖励函数"""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""软格式奖励函数"""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def count_xml(text) -> float:
"""计算 XML 格式的得分"""
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1]) * 0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1) * 0.001
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
"""XML计数奖励函数"""
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]

4. 模型GRPO训练
4.1 数据模型验证
/models/
└── gsm8k/Qwen2.5-Coder-3B-Instruct # 模型
/datasets/
└── gsm8k/
└── gsm8k_train.json # 数据集
/outputs/
└── 02_outputs/
├── grpo_saved_lora/ # LoRA适配器
└── qwen-grpo-model/ # ModelScope格式模型
# 验证模型加载
from modelscope import Model
import pprint
loaded_model = Model.from_pretrained("/outputs/qwen-grpo-model")
assert loaded_model is not None, "模型加载失败"
# 验证数据集
assert len(dataset) > 0, "数据集加载失败"
pprint.pprint(dataset[0]) # 验证数据格式
4.2 训练
from trl import GRPOConfig, GRPOTrainer
from unsloth import is_bfloat16_supported
save_path = "./outputs/02_outputs"
training_args = GRPOConfig(
use_vllm=False, # 使用 vLLM 进行快速推理!
learning_rate=5e-6,
adam_beta1=0.9,
adam_beta2=0.99,
weight_decay=0.1,
warmup_ratio=0.1,
lr_scheduler_type="cosine",
optim="adamw_8bit",
logging_steps=1,
bf16=is_bfloat16_supported(), # 是否支持 bfloat16
fp16=not is_bfloat16_supported(), # 是否使用 fp16
per_device_train_batch_size=1,
gradient_accumulation_steps=1, # 增加到 4 以获得更平滑的训练
num_generations=8, # 如果内存不足,请减少
max_prompt_length=256,
max_completion_length=200,
# num_train_epochs=1, # 设置为 1 进行完整的训练
max_steps=250,
save_steps=250,
max_grad_norm=0.1,
report_to="none", # 可以使用 Weights & Biases
output_dir=save_path, # AutoDL推荐输出路径
)
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=[
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func,
],
args=training_args,
train_dataset=dataset,
)
trainer.train()
# 启动训练
train_result = trainer.train()
# 指定路径保存训练好的模型
trainer.save_model(save_path)
# 打印训练结果
print("训练结果:", train_result)
💡 提示:首次运行会下载ModelScope模型(~3GB),请确保有足够存储空间。训练时间约1小时(250 steps),建议使用
screen或nohup保持会话。
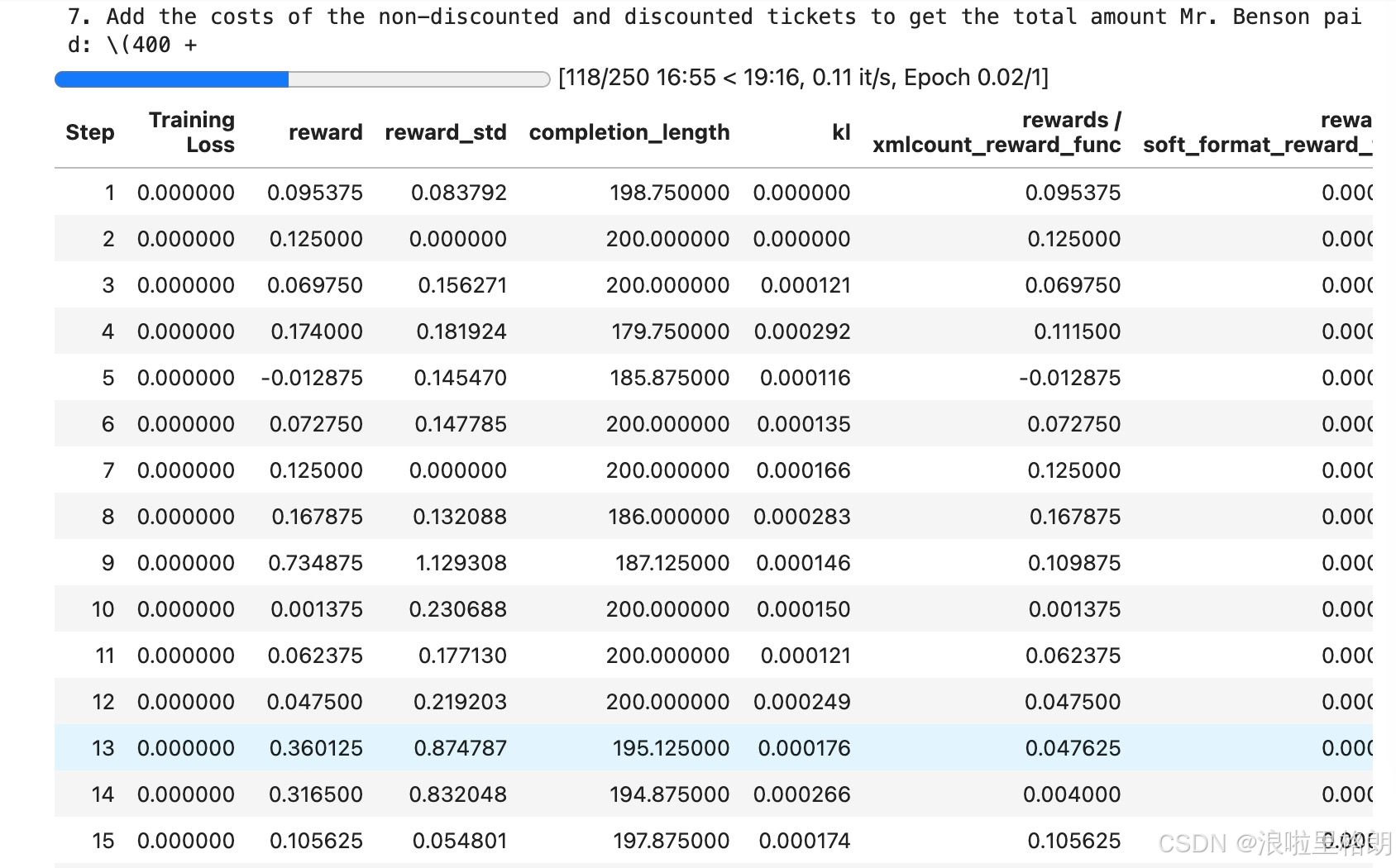
5. 模型保存
# 保存LoRA适配器
save_path = "./outputs/02_outputs"
model.save_lora(save_path+'/grpo_saved_lora')
# 保存为ModelScope格式(可选)
model.save_pretrained(
save_path+"/qwen-grpo-model",
save_function=Model.save,
tokenizer=tokenizer
)
6.模型推理
6.1 使用 GRPO 训练的 LoRA 进行推理
import torch
import warnings
from peft import PeftModel
from transformers import GenerationConfig
# 禁用 peft 的 UserWarning(关键修改)
warnings.filterwarnings("ignore", category=UserWarning, module="peft")
# 定义 SYSTEM_PROMPT
SYSTEM_PROMPT = "你是一个知识渊博、友好的助手,能准确回答各种问题。"
# 加载 LoRA 权重
model = PeftModel.from_pretrained(model, save_path+"/grpo_saved_lora")
# 应用聊天模板
text = tokenizer.apply_chat_template([
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": "How many r's are in strawberry?"}
], tokenize=False, add_generation_prompt=True)
# 配置生成参数
generation_config = GenerationConfig(
temperature=0.8,
top_p=0.95,
max_new_tokens=1024,
)
# 将文本转换为输入张量
input_ids = tokenizer(text, return_tensors="pt").input_ids.to(model.device)
# 使用标准的 generate 方法生成输出
with torch.no_grad():
output = model.generate(
input_ids=input_ids,
generation_config=generation_config
)
# 解码输出
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("使用监督微调的 LoRA 模型输出: ", output_text)

引用
[1]. https://github.com/LFF8888/FF-Studio-Resources
[2]. https://www.autodl.com/docs/
[3]. https://huggingface.co/unsloth/Qwen2.5-Coder-3B-Instruct

















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









