










Alpha pose数据准备部分可以看我之前的【文1】:
AlphaPose姿态估计 只输出骨架 源码修改 相关记录
关于PredRNN++的内容见【文2】:
predRNN++代码实战 tensorflow版本
本文代码详见我的GitHub库:Abalizzw/MovingMnist_DataMaker
1. Moving mnist数据集
因为用自己的数据训练PredRNN++需要制作自己的数据集,数据结构类似于Movingmnist,还不了解的同学可以看一下。
Moving_mnist data中的train.npz包含了三个部分。
它们的结构如下:
-
clips.npy
- type = numpy.ndarray
- shape = (2, 10000, 2)
-
[[0,10],[20,10]...[199980,10](1w)], [[10,10],[30,10]...[199990,10](1w)]]
dims.npy
- type = numpy.ndarray
- shape = (1, 3)
-
[1, 64, 64]
input_raw_data.npy
- type = numpy.ndarray
- shape = (200000, 1, 64, 64)
-
[ [ [ [pixel*64] *64] ]*200000 ]
解释一下
- 第一个文件clips表示输入帧和gt帧所在的图片位置,1w个视频每个被分为10帧,图片总数就是20w。
- clips[0]的[0,10]表示0开始数10张,20开始往后的10张一直到第199980和往后的10张代表输入帧。同理剩下的图片被分为gt label。
- dims表示了输入data的size,很好理解。
- input_raw_data包含了1w个视频每一帧的图片,存储类型为np.ndarray,可以直接用opencv或matplotlib等python库可视化,64*64是一张图片,一共20w张,也很好理解。下面放一个可视化的例子和代码。
查看第100张图片:
import cv2
import numpy as np
data = np.load('./input_raw_data.npy')
pixel = data[100][0]
cv2.imshow('1', pixel)
cv2.waitKey(0)
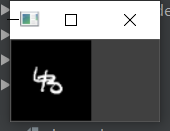
下面我们只要仿照他的格式制作我们的数据就行了。
2. 数据的准备
数据的准备先由AlphaPose输出黑底的检测框,见【文1】,得到一系列的视频数据,我们需要使用ffmpeg或者opencv将视频切割成图片。
我使用的是opencv,代码入下:
#将视频转换成每帧图片
def video2img(input_dir, out_dir):
vc = cv2.VideoCapture(input_dir+'train_0004.mp4') # 读入视频文件
n = 1 # 计数
if vc.isOpened(): # 判断是否正常打开
rval, frame = vc.read()
else:
rval = False
timeF = 1 # 视频帧计数间隔频率
i = 0
while rval: # 循环读取视频帧
rval, frame = vc.read()
if (n % timeF == 0): # 每隔timeF帧进行存储操作
i += 1
print(i)
# frame = cv2.resize(frame, (64, 64)) # resize
cv2.imwrite(out_dir+'{}.png'.format(i), frame) # 存储为图像
n = n + 1
cv2.waitKey(1)
vc.release()
然后我们得到每帧的图片在一个文件夹下:

3. 数据的处理
将处理好的数据进行如下操作:
- 三通道转单通道
- 将像素转换为numpy.float32。
- 归一化
附上代码:
import cv2
img = cv2.imread(r'Your path\img.png')
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # 三通道-->单通道
img = np.float32(img) # 像素格式化
dst = np.zeros(img.shape, dtype=np.float32)
img = cv2.normalize(img, dst, alpha=0, beta=1.0, norm_type=cv2.NORM_MINMAX) #图像归一化
print(img.shape)
cv2.imwrite(r'Your path\img_gray.png', img)
cv2.imshow('1', img)
cv2.waitKey(0)
输出如下:
(640, 640)

4. 数据的保存
我们需要将图片数据转换成numpy格式并封装保存在.npy文件中,然后打包成npz文件。这里建议将每个视频分成相同数量的单帧,并且保证总数可以被10整除。其中每个数据文件的结构,维度,参数量,参数格式等有明确的要求。
如果您没有丰富的处理numpy数据经验,或是不想动源代码的data读取部分,或者和我一样初次接触这类numpy数据的制作,请看下我的另一篇文章,这将节省您的时间。
关于详细的数据保存方法和代码请移步这篇文章:
模仿制作自己的MovingMnist数据集【封装篇】
最后更新20210504















 2348
2348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









