









前言:
研究项目课题是对自动驾驶环境下视频中的行人做位置预测。本人对时空序列预测数据的制作不太了解,写这篇文章的目的是记录下数据制作的过程,以防以后要制作类似的东西,也为有需要的人提供些帮助。
因为参考文献PredRNN++用到的数据是MovingMnist,相对容易复现,于是思考将相机拍摄的视频制作成类似于MovingMnist格式的数据。
本文主要介绍的是MovingMnist数据的保存方法,MovingMnist的封装很简单,只需一个Numpy就够了。
文章目录
0. 工作流程介绍
- 将视频数据通过Alpha pose读取人体骨架。
1.5 对数据清洗,并存入列表。- 提取视频帧同时裁剪到目标大小,并保存成图片。
- 将图片封装成训练数据和测试数据并打包。
效果如下所示:

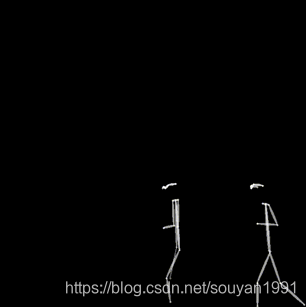
1. 将视频通过Alphapose人体姿态识别人体骨架
这一步的思路就是将含有复杂背景信息的视频转为只含有行人信息的视频。
具体实现参见我的另一篇:【AlphaPose姿态估计 只输出骨架 源码修改 相关记录】文1
- 这里我写了一个批量处理的代码参考:
视频文件都存储在input_dir中,直接在输出路径生成处理好的视频文件。
alphapose指令如果有不懂的地方请仔细阅读官方GitHub中的demo,里面写的很详细。
import os
input_dir = ''
if not os.path.exists():
os.mkdir('')
for file in data_list:
file = input_dir + file
os.system('python 你的Alpapose路径/scripts/demo_inference.py '
'--cfg Alphapose配置文件.yaml '
'--checkpoint Alphapose模型文件.pth '
'--video %s '
'--outdir 输出路径/ '
'--save_video '
%file
)
1.5 数据清洗
对数据的清洗做的主要有两部分:
1. Alphapose的主动data cleaning, 和2. 手动对处理结果cleaning。
- AlphaPose部分通过修改对骨骼关键点的results的confidence(置信度/阈值),达到去除误检测,以及冗余的检测点和连线(需要根据自己的数据进行测试)。具体例子还是看文1
- 手动主要剔除一些检测效果很差的视频,比如行人小又多又密集导致Alphapose误检测点多到一定程度的数据,再比如一些原因导致的背景全黑或者正确识别帧数占比太小的数据我都会剔除。这个操作比较主观,概括来讲,你想得到什么样结果就喂给网络什么样的数据。
2. 提取视频帧同时裁剪并保存为图片
- 这部分没什么好说的,直接上代码:
A.裁剪和截取目标时间段的video
import os
import ffmpeg
input_dir = '输入路径'
save_path = '保存路径'
def crop(stream): # 以(640,320)为矩形框左上方顶点坐标裁剪成640*640大小
stream = ffmpeg.crop(stream, x=640, y=320, width=640, height=640)
return stream
def trim(stream, duration, length=2.0): # 处理视频中间开始后2秒的视频
start = float(duration) // 2
end = start + length
stream = ffmpeg.trim(stream, start=start, end=end)
return stream
video_list = os.listdir(input_dir)
i = 0
for file in video_list:
i += 1
file = input_dir + file
duration = ffmpeg.probe(file)['format'].get('duration')
stream = ffmpeg.input(file)
stream = crop(stream)
stream = trim(stream, duration)
stream.output(save_path + 'train_%0.4d.mp4' % i).run()
B. 视频转图片
import os
import cv2
input_dir = '输入路径'
out_dir = '保存路径'
# 将视频转换成每帧图片
def video2img(input_dir, out_dir, size=(64, 64)):
video_num = out_dir[-5:-1]
print(video_num)
vc = cv2.VideoCapture(input_dir + 'train_%s.mp4' % video_num) # 读入视频文件
# if vc.isOpened(): # 判断是否正常打开
# rval, frame = vc.read()
# else:
# rval = False
timeF = 1 # 视频帧计数间隔频率,数字代表每几帧保存一次。
num = 0
while True: # 循环读取视频帧
rval, frame = vc.read()
if not rval:
break
# if (n % timeF == 0): # 每隔timeF帧进行存储操作
num += 1
frame = cv2.resize(frame, size, interpolation=cv2.INTER_AREA) # resize
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imwrite(out_dir + '{}.png'.format(num), frame) # 存储为图像
vc.release()
if not os.path.exists(out_dir):
os.mkdir(out_dir)
data_list = os.listdir(input_dir)
folder_name = 0
for file in data_list:
folder_name += 1
opt_dir = out_dir + '%04d/' % folder_name
if not os.path.exists(opt_dir):
os.mkdir(opt_dir)
video2img(input_dir, opt_dir)
print('video clip %d is processed.' % folder_name)
处理后效果:

3. 将图片封装成训练数据和测试数据
MovingMnist数据格式在之前的文章也有介绍:【基于Movingmnist结构制作predrnn++的训练数据过程记录文2】
-
moving_nmist_example.zip
-
-
moving_mnist_train.npz
- clips.npy
- dims.npy
- raw_data.npy
-
-
moving_mnist_valid.npz
- …
-
-
moving_mnist_test.npz
- …
其中:
clips.npy
type = numpy.ndarray
shape = (2, 10000, 2)
[[0,10],[20,10]...[199980,10](1w)], [[10,10],[30,10]...[199990,10](1w)]]
dims.npy
type = numpy.ndarray
shape = (1, 3)
[1, 64, 64]
input_raw_data.npy
type = numpy.ndarray
shape = (200000, 1, 64, 64)
[ [ [ [pixel*64] *64] ]*200000 ]
我们依次来制作:
首先如果不熟悉数据格式想看一下原始数据可以存入txt然后用文本文档打开查看:
import numpy as np
input_data = np.load("dims.npy")
print(input_data.shape)
data = input_data.reshape(1, -1)
print(data.shape)
print(data.dtype)
np.savetxt(".txt/dims.txt", data, delimiter=',')
另外定义几个全局变量和函数先:
import cv2
import os
import numpy as np
npy_save_path = './mydata_npy/'
valid_dir = './val/'
train_dir = './train/'
frame_size = 64
mode = 'train'
def countFile(dir): #读取data的总帧数
tmp = 0
for item in os.listdir(dir):
if os.path.isfile(os.path.join(dir, item)):
tmp += 1
else:
tmp += countFile(os.path.join(dir, item))
return tmp
train_frame_nums = countFile(train_dir)
val_frame_nums = countFile(valid_dir)
3.1 clips.npy
直接上代码:
def gen_npy_clips(frame_nums, save_path):
dim2 = frame_nums // 20 # 每20帧为一组,包含10帧的input和10帧gt
clips = np.ndarray(shape=(2, dim2, 2), dtype=np.int32) # dtype对应不能改
for i in range(clips.shape[0]):
x = 0 if i == 0 else 10
for j in range(clips.shape[1]):
clips[i][j][0] = x
clips[i][j][1] = 10
x += 20
np.save(save_path + 'clips.npy', clips)
print('clips.npy is saved in path:%s' % save_path) # 输出一些信息
print('shape:', clips.shape)
print('type:', type(clips[0][0][0]))
3.2 dims.npy
def gen_npy_dims(frame_size, save_path):
dims = np.array([[1, frame_size, frame_size]], dtype=np.int32) # 注意dtype
np.save(save_path + 'dims.npy', dims)
print('dims.npy is saved in path:%s' % save_path)# 输出信息
print('shape:', dims.shape)
print('type:', type(dims[0][0]))
3.3 input_raw_data.npy
def gen_raw_data(img_path, img_size, save_path):
size = img_size
nums = countFile(img_path)
data = np.ndarray(shape=(nums, 1, size, size), dtype=np.float32)
folder_list = os.listdir(img_path)
itr = 0
for folders in folder_list:
img_list = os.listdir(img_path + folders)
contents = []
for numbers in img_list: # 遍历图片文件名
contents.append(int(numbers[:-4])) # 保存图片文件编号
start = min(contents) # 记录起始文件编号
for i in range(start, len(img_list) + start): # 起始编号为start的图片开始向后操作图片数量个循环
img = cv2.imread(img_path + folders + '/%d.png' % i)
img = cv2.resize(img, (size, size), interpolation=cv2.INTER_AREA)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 三通道转单通道
img = np.float32(img)
dst = np.zeros(img.shape, dtype=np.float32) # dtype注意
img = cv2.normalize(img, dst, alpha=0, beta=1.0, norm_type=cv2.NORM_MINMAX) # 归一化
data[itr] = img
itr += 1
print('clip %s ' % folders + 'is processed.')
np.save(save_path + 'input_raw_data.npy', data)
print('input_raw_data.npy is saved in path:%s' % save_path)
print('shape:', data.shape)
print('type:', type(data[0][0][0][0]))
最后是输出信息:
clip 0084 is processed.
clip 0085 is processed.
input_raw_data.npy is saved in path:C:/Users/Abali/Projects/AlphaPose_n/AP/test/mydata_npy/
shape: (3900, 1, 640, 640)
type: <class 'numpy.float32'>
3.4 将以上三个文件打包mydata.npz
def gen_npz_data(path):
data_list = os.listdir(path)
print('reading data...')
for file in data_list:
if file[0] == 'c':
clips = np.load(path + 'clips.npy')
if file[0] == 'd':
dims = np.load(path + 'dims.npy')
if file[0] == 'i':
input_raw_data = np.load(path + file)
le = len(clips[0])
if le == train_frame_nums // 20:
np.savez(path + 'mydata_train.npz', clips=clips, dims=dims, input_raw_data=input_raw_data)
print('{}, {}, {} have been saved in {}'.format('clips.npy', 'dims.npy',
'input_raw_data.npy', 'mydata_train.npz'))
elif le == val_frame_nums // 20:
np.savez(path + 'mydata_valid.npz', clips=clips, dims=dims, input_raw_data=input_raw_data)
print('{}, {}, {} have been saved in {}'.format('clips.npy', 'dims.npy',
'input_raw_data.npy', 'mydata_valid.npz'))
最后写了一个判断train还是val的,方便选择:
if mode == 'train':
gen_npy_clips(train_frame_nums, save_path=npy_save_path)
gen_npy_dims(frame_size, save_path=npy_save_path)
gen_raw_data(img_path=train_dir, img_size=frame_size, save_path=npy_save_path)
gen_npz_data(npy_save_path)
if mode == 'valid':
gen_npy_clips(val_frame_nums, save_path=npy_save_path)
gen_npy_dims(frame_size, save_path=npy_save_path)
gen_raw_data(img_path=valid_dir, img_size=frame_size, save_path=npy_save_path)
gen_npz_data(npy_save_path)
else:
print('Error occurs, process finished.')
最后的输出,打包完成:
reading data...
clips.npy, dims.npy, input_raw_data.npy have been saved in mydata_train.npz
数据生成成功!

本文代码详见我的GitHub库:github.com/Abalizzw/MovingMnist_DataMaker
最后更新日期20210509














 4651
4651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









