










Looking Ahead: Anticipating Pedestrians Crossing with Future Frames Prediction
1.Intro: contribute
1.我们提出了未来的视频帧预测编码器/解码器网络,该网络以自监督的方式运行,以使用N个初始帧来预测视频的N个未来帧。
2.我们提出了一种端到端模型,该模型可以预测未来的视频帧,并将预测的帧用作监督动作识别网络的输入,以预测行人何时会走在车辆前。
3.我们在未来帧预测和对JAAD数据集的行人未来穿越行动的预测上均达到了最新的性能。
4.我们进行了彻底的消融研究,结果表明模型组件在多种天气条件,位置和其他变量下均十分可靠,高效。
2.Method
2.1.Architecture:
我们的端到端模型包括两个阶段:第一阶段是一个自我监督的编码器/解码器网络,该网络生成预测的未来视频帧。 第二阶段是深度的时空行为识别网络,该网络利用生成的视频帧来预测行人的行为,特别是行人是否会在车辆前方越过。
2.2.prediction component预测组件
2.2.1 N个连续的视频帧被输入到模型中,并且该模型预测了将来的N个帧。
2.2.2 图A是编码器/解码器架构的视觉表示。 编码器将帧的输入序列映射到具有不同分辨率的低维特征空间中。 解码器将输入帧的低维表示空间映射到输出图像空间。
图B是4种convLSTMs层和残差操作结构示意图。
编码器:编码器是由三维卷积层组成的时空神经网络。
3D卷积建模跨帧的时间连接的空间关系和顺序关系。 N个RGB帧是编码器输入。 输入的大小为3×N×H×W。输出的特征图的时间长度与输入图像匹配。前两个图像下采样,最后一个是时分滤波器,捕获了输入序列的时间依赖性。
解码器:解码器由convLSTMs层和上采样层组成。
编码器/解码器连接:横向跳过连接从编码器中相同尺寸的部分到解码器(图2中的绿线)交叉。 横向连接增加了可用输入帧的细节水平,从而有助于预测帧中的细节。

A-在我们的方法中使用前N个视频帧(过去)作为输入来预测下N个视频帧(未来)的编码器/解码器网络的建议概述。
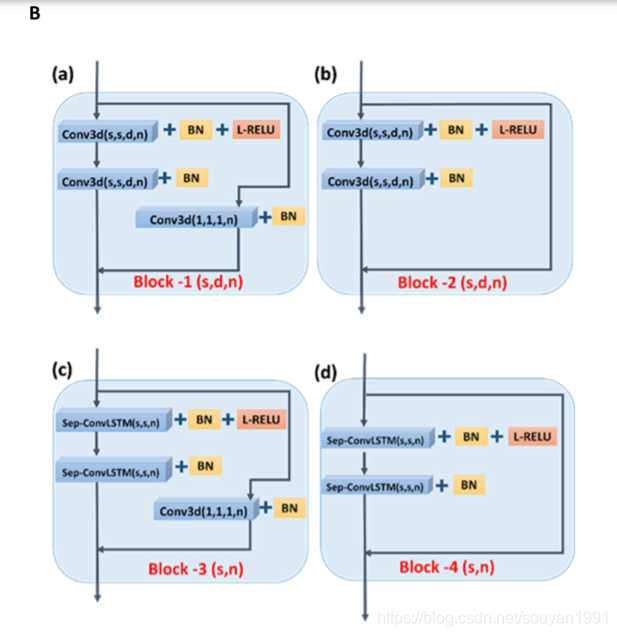
B-在A中的体系结构中使用的4个不同的残差块。(a)和(b)是在编码器中使用的残差块。 (c)和(d)用于解码器。
3. Pedestrian Action Prediction Component 行人行动预测组件
该模型的第二阶段包括一个经过微调的早期动作识别网络,即“时间3D虚拟网络”(T3D)。
该阶段预测行人是否会在场景中过马路。 从编码器/解码器产生的N个预测帧被输入到网络中。
T3D网络的最后一个分类层被完全连接的层替换,该层产生一个输出,然后进行S型激活。 对组件进行二进制交叉熵损失训练。
4.Loss-Function
L[recog] = λ*L[pred] + L[ce](Y, ˆY)
Lce是交叉行动分类的交叉熵损失,ˆY和Y是high-level预测和对应的groundtruth。
Lpred是未来帧预测损失,即N个预测帧和N个ground truth帧的像素之间的逐像素损失。
Lpred定义如下:
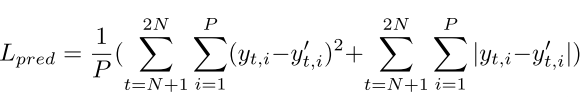
这里的P = H×W,为每帧像素数。 为了规范化,将l1和l2范数损失结合使用。
5. Experiments 实验
5.1 Data: JAAD
5.2 model:
5.2.1 架构设计:对主要的编码器/解码器组件进行了实验操作,以测试多种架构设计。 层的数量,层的顺序以及层中的通道数量都不同。
在所有变化中,编码器输出保持不变,这是因为输入的空间尺寸始终被8降采样。在解码器中,始终使用convLSTM块-反卷积模式。
5.2.2 超参数选择:(表1)对于每个选定的体系结构,随机采样了38个超参数设置。 每个参数设置都使用其在验证集上的平均像素方向预测误差来评估。
| Calibration parameters | search space |
|---|---|
| Spatial filter size of 3D Convs | [3,5,7,11] |
| Temporal dilation rate | [1,2,3,4] |
| Spatial filter size of sep-ConvLSTMs | [3,5,7] |
| Temporal filter size of 3D Convs | [2,3,4] |
| Temporal filter size of sep-ConvLSTMs | [2,3,4] |
表1.编码器/解码器网络超参数和搜索空间。 注意:时间扩散率仅在编码器的最后一个块中实现
5.3训练
我们使用了[14]中介绍的相同的训练,验证和测试片段,这使我们可以直接比较我们的性能。
60%的数据用于培训,10%的数据用于验证,30%的数据用于测试。 将剪辑分为2N帧视频,时间跨度为1。
将帧的大小调整为128×208,N =16。因此,模型输入为3×16×128×208。
lr=1e-4
6. Results
JAAD 数据集上达到了SOTA,平均精度(AP)为86.7,比以前的最新技术[14]81.14AP有所提高。
参考文献
[14]P. Gujjar and R. Vaughan. Classifying pedestrian actions in advance using predicted video of urban driving scenes. In 2019 International Conference on Robotics and Automation (ICRA), pages 2097–2103. IEEE, 2019.
Fin.














 6589
6589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









