







我也是做RAG相关工作的。周末抽了一些时间,来看看开源的RAG技术能够做到什么程度。
其实我重点关注的是以下几点(以下几个点是RAG提升的关键点):
- 这些开源技术他们是怎么做文档解析的(有哪些我们可以借鉴的,哪些是我不知道的)
- 如何做切分的
- 不同的场景数据又是如何制定不同的策略的
- 还有如何做召回的,召回策略是什么?
- 以及如何选用embedding模型,rerank模型
- 效果怎么样,本地快速部署效果是否方便?
一、开源的RAG
1.1 网易开源的 QAnything
当前github 7.7K star
https://github.com/netease-youdao/QAnything/blob/master/README_zh.md
先试试效果
1.2 ragFlow
也是很快在github上获取1000+的star,当前4.3K star
https://github.com/infiniflow/ragflow/blob/main/README_zh.md
先试试效果
RAGFlow 与其他 RAG 产品有何不同?看看官方的描述
尽管法学硕士在自然语言处理(NLP)方面取得了显着的进步,但“垃圾进垃圾出”的现状仍然没有改变。为此,RAGFlow 引入了与其他检索增强生成 (RAG) 产品相比的两个独特功能。
- 细粒度文档解析:文档解析涉及图片和表格,您可以根据需要灵活干预。
- 可追踪的答案,减少幻觉:您可以信任 RAGFlow 的答案,因为您可以查看支持它们的引文和参考文献。
二、最关心的技术点揭秘
2.1 文档解析
文档解释是RAG走先成功的第一步。就像经常所说的 “Quality in, quality out”。
但是由于文件的复杂多样性,往往都是文件解析不对,导致丢数据,在召回阶段无法被召回。最后没有成功回答问题。
2.1.1 RAGFlow 的文档解析
这里是PDF 解析的细节
使用到的OCR识别技术。然后又做的版面分析的技术。我测试了上传论文,来测试解析的效果。我并不是很认可这个解析最终的效果。
这里简单说一下它的解析过程:先进行ORC识别,然后再做的版面分析。详细见下文。
https://www.cnblogs.com/xiaoqi/p/18123888/ragflow
RAGFlow 有一个做的好的地方
在解析前,它可以提前配置好,文档是什么类型,它针对不同的类型去解析。
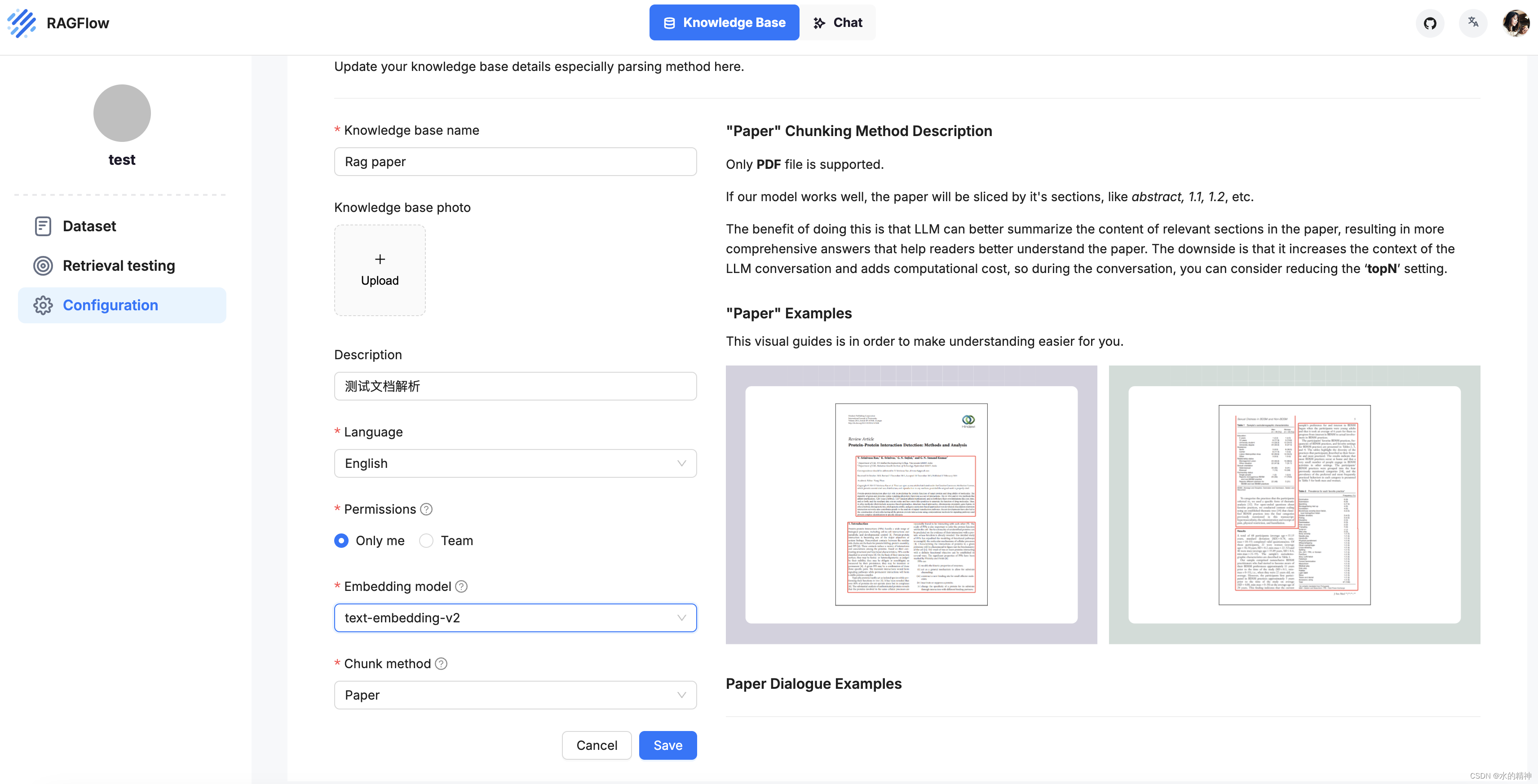
第二个好的地方是,把解析的结果返显了。用户可以来修改纠正解析后的结果,还可以调整chunck的大小。
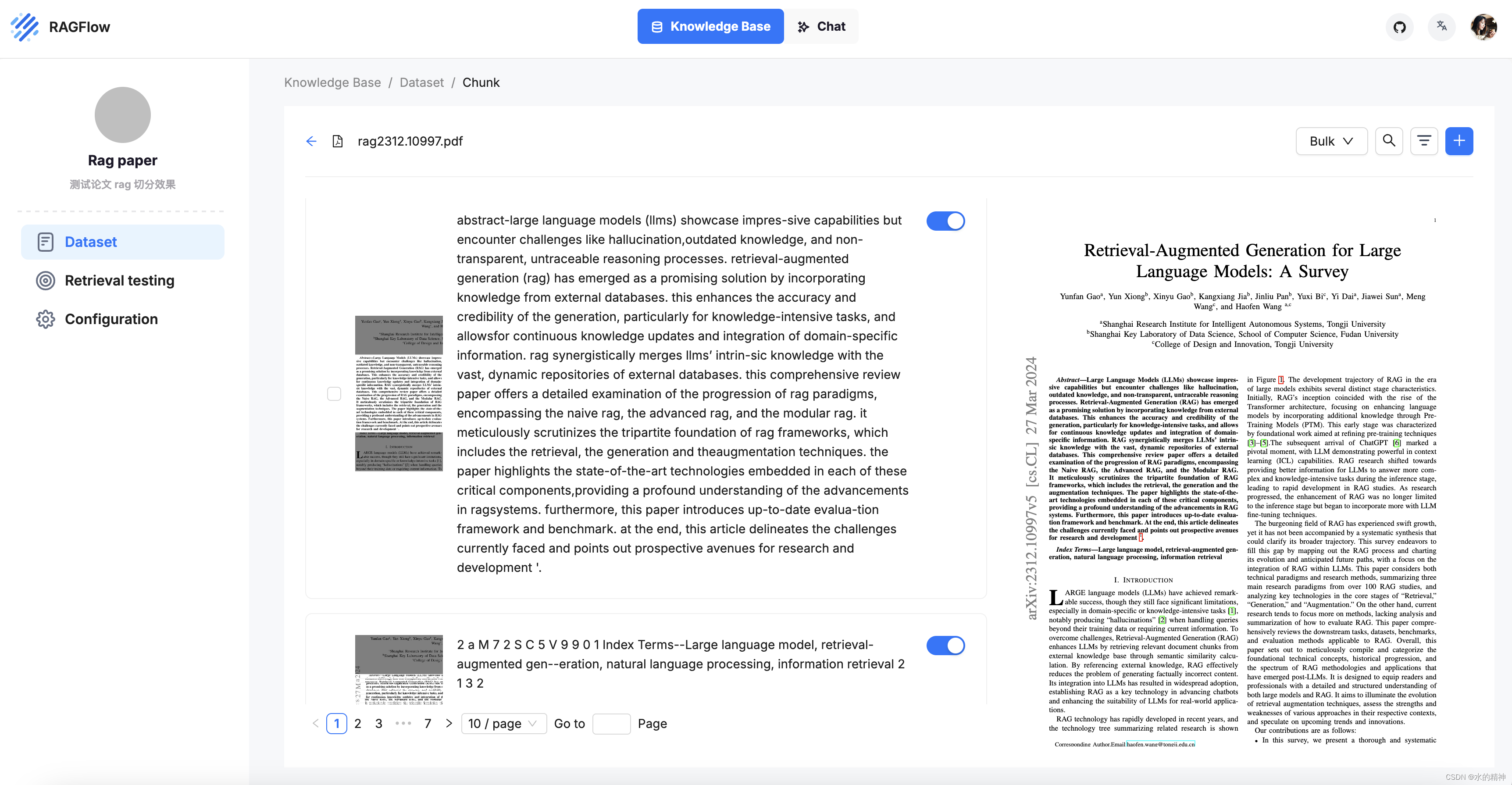
2.1.2 QAnything的 文档解析
QAnything的文档解析远嘛在这里,也是用模型来解析文档的,用到的是UnstructuredPaddle。
也是走的OCR识别的路线。
https://github.com/netease-youdao/QAnything/blob/master/qanything_kernel/utils/loader/pdf_loader.py
2.2 UnstructuredPaddleOCR 介绍
UnstructuredPaddle并不是一个单一的模型,而是一个基于PaddlePaddle框架的OCR(光学字符识别)工具包,它由Unstructured-IO组织开发。这个工具包旨在从非结构化的文档中提取文本,支持多种语言和多种格式的文档,包括PDF和Word文档等。UnstructuredPaddleOCR特别强调其轻量级和实用性,支持超过80种语言的文本识别6。
使用UnstructuredPaddleOCR时,用户可以通过简单的API调用来实现文本的提取。例如,用户可以上传一个PDF文件,然后UnstructuredPaddleOCR会利用OCR技术从文件中识别并提取出文本内容。这个过程通常包括图像预处理、文本识别、版面分析等步骤,以确保提取的文本尽可能准确和完整。
此外,UnstructuredPaddleOCR也提供了一些高级功能,比如支持自定义的版面分析策略,允许用户根据具体的文档类型和需求来调整文本提取的过程。这样的灵活性使得UnstructuredPaddleOCR可以应用于多种不同的场景,如文档数字化、数据录入、内容分析等。

















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









