







目录
〇、写在前面
前文链接:读取ICM20602(一)STM32通过SPI读取ICM20602
虽然副标题格式和前一篇文章一模一样,但我保证这篇真不是水货!
在这篇文章里,我会着重讲述我将ICM20602库移植至梁山派(主控GD32F470ZGT6)的过程与要点,以及过程中的各种坑,供有意进行驱动移植或更深入地理解SPI通讯协议的各位进行参考。
一、GD32F4系列的SPI总线简述
1.结构框图

2.相关标志位
GD32F4系列的UserManual在21.6节中对SPI相关标志位描述如下:
21.6.1.状态标志位· 发送缓冲区空标志位( TBE )当发送缓冲区为空时, TBE 置位。软件可以通过写 SPI_DATA 寄存器将下一个待发送数据写入发送缓冲区。· 接收缓冲区非空标志位(RBNE )当接收缓冲区非空时, RBNE 置位,表示此时接收到一个数据,并已存入到接收缓冲区中,软 件可以通过读 SPI_DATA 寄存器来读取此数据。· SPI通信进行中标志位( TRANS )TRANS 位是用来指示当前传输是否正在进行或结束的状态标志位,它由内部硬件置位和清除, 无法通过软件控制。该标志位不会产生任何中断。21.6.2.错误标志· 配置错误标志(CONFERR )在主机模式中, CONFERR 位是一个错误标志位。在硬件 NSS 模式中,如果 NSSDRV 没有使能,当 NSS 被拉低时, CONFERR 位被置 1 。在软件 NSS 模式中,当 SWNSS 位为 0 时, CONFERR 位置 1 。当 CONFERR 位置 1 时, SPIEN 位和 MSTMOD 位由硬件清除, SPI 关 闭,设备强制进入从机模式。在 CONFERR 位清零之前, SPIEN 位和 MSTMOD 位保持写保护,从机的 CONFERR 位不能 置 1 。在多主机配置中,设备可以在 CONFERR 位置 1 时进入从机模式,这意味着发生了系统控制的多主冲突。· 接收过载错误(RXORERR )在 RBNE 位为 1 时,如果再有数据被接收, RXORERR 位将会置 1 。这说明,上一帧数据还未被读出而新的数据已经接收了。接收缓冲区的内容不会被新接收的数据覆盖,所以新接收的数据丢失。· 帧错误(FERR )在 TI 从机模式下,从机也要监视 NSS 信号,如果检测到错误的 NSS 信号,将会置位 FERR标志位。例如, NSS 信号在一个字节的中间位发生翻转。· CRC错误( CRCERR )当 CRCEN 位置 1 时, SPI_RCRC 寄存器中接收到的 CRC 值将会和紧随着最后一帧数据接收到的 CRC 值进行比较。当两者不同时, CRCERR 位将会置 1 。
可以发现,在GD32F4系列的SPI共有三个状态标志位,分别用于标志发送缓冲区是否有数据、接收缓冲区是否有数据、SPI是否在通讯中。关于这三个标志位的置位与复位条件,会在下一节中详细描述。
3.工作流程
发送流程在完成初始化过程之后, SPI 模块使能并保持在空闲状态。在主机模式下,当软件写一个数据 到发送缓冲区时,发送过程开始。在从机模式下,当 SCK 引脚上的 SCK 信号开始翻转,且 NSS 引脚电平为低,发送过程开始。所以,在从机模式下,应用程序必须确保在数据发送开始 前,数据已经写入发送缓冲区中。 当 SPI 开始发送一个数据帧时,首先将这个数据帧从数据缓冲区加载到移位寄存器中,然后开始发送加载的数据。在数据帧的第一位发送之后,TBE (发送缓冲区空)位置 1 。 TBE 标志位置 1 ,说明发送缓冲区为空,此时如果需要发送更多数据,软件应该继续写 SPI_DATA 寄存器。 在主机模式下,若想要实现连续发送功能,那么在当前数据帧发送完成前,软件应该将下一个 数据写入 SPI_DATA 寄存器中。接收流程在最后一个采样时钟边沿之后,接收到的数据将从移位寄存器存入到接收缓冲区,且 RBNE (接收缓冲区非空)位置 1 。软件通过读 SPI_DATA 寄存器获得接收的数据,此操作会自动清除 RBNE 标志位。在 MRU 和 MRB 模式中,为了接收下一个数据帧,硬件需要连续发送时钟信号,而在全双工主机模式(MFD )中,当发送缓冲区非空时,硬件才接收下一个数据帧。
以上内容节选自GD32F4系列的UserManual。由此我们可以得知,在全双工常规连接的SPI主机模式下,其工作流程为:
1.初始化完成后,SPI处于空闲状态,此时NSS引脚为高电平,TBE标志位为1,RBNE标志位为0;
2.当软件写一个数据到发送缓冲区时,发送过程开始,TBE置0;
3.将发送缓冲区的数据存入移位寄存器并开始发送,当数据的第一位发送后,TBE置1,此时可继续往缓冲区中写入数据,但在当前帧发送完成前缓冲区的数据不会发送;
4.在最后一个采样时钟沿后,将移位寄存器中的数据存入接收缓冲区,RBNE置1;
5.当软件读取接收缓冲区的数据后,RBNE置0,本帧通讯结束。
图示如下:

这里为什么没讲 TRANS 标志位的置位和复位条件呢?因为原文里真没有……原文里关于 TRANS标志位的置位和复位条件只有标志位介绍的一句话,因此我们只知道,TRANS 标志位会在通讯开始时置1,通讯完成后置0。
为什么要着重说这个呢?因为和HAL库不同,GD32的库是没有TransmitReceive这么好使的函数的,因此每次SPI数据交换时都需要我们去留意标志位的情况,并以此判断是否可以发送或接收数据。
4.相关函数
实现与ICM20602的SPI通讯,仅需spi_init、spi_i2s_flag_get、spi_i2s_data_transmit、spi_i2s_data_receive 四个函数即可。
4.1 spi_init
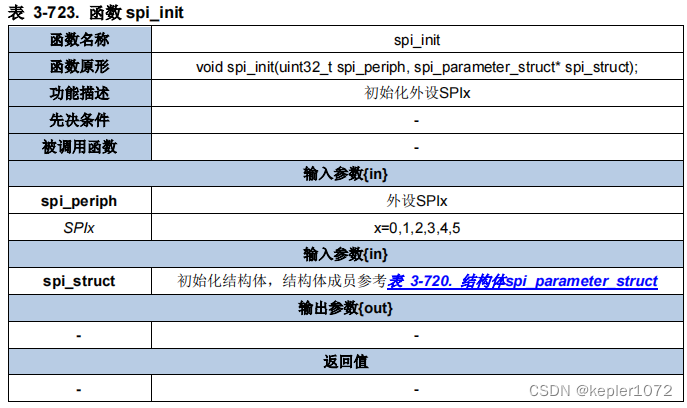
其中结构体spi_parameter_struct成员参数如下:

因为和STM32的配置相似,所以没啥好说的,按照前一篇文章所说进行配置即可。
4.2 spi_i2s_flag_get
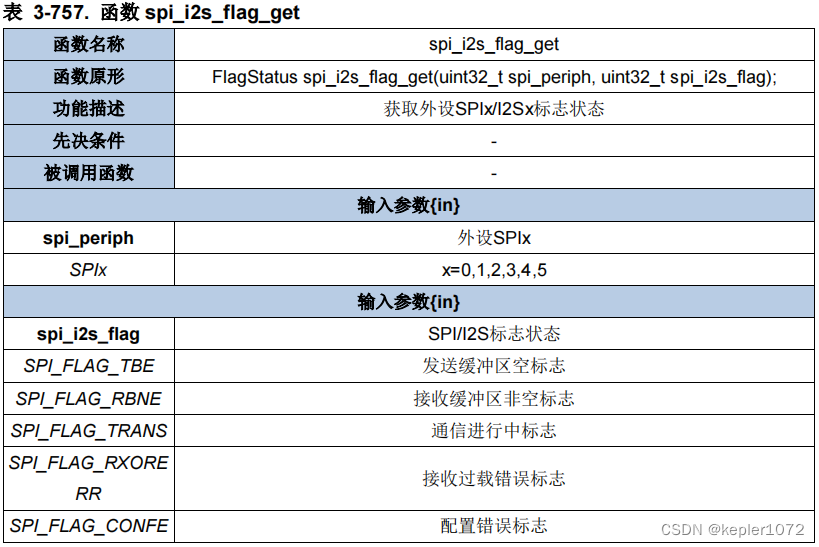
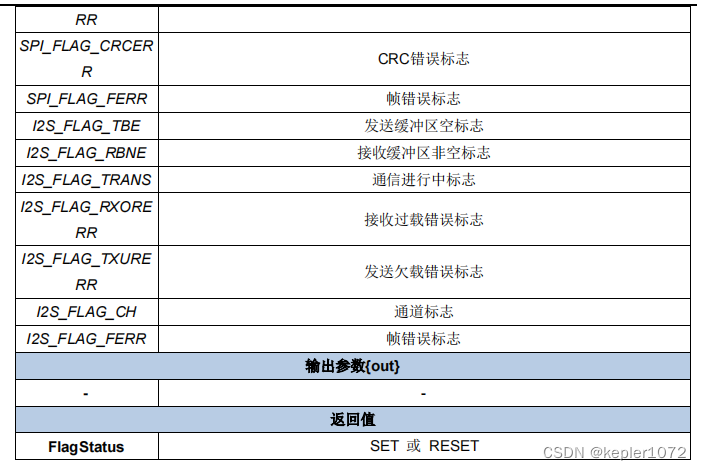
该函数的功能为获取对应SPI寄存器标志位状态,返回值为SET或RESET,其中SET为1,RESET为0。在SPI通讯过程中,我们需要重点关注的三个标志位分别为SPI_FLAG_TBE、SPI_FLAG_RBNE、SPI_FLAG_TRANS。
4.3 spi_i2s_data_transmit

值得注意的是,该函数源码实现如下:
/*!
\brief SPI transmit data
\param[in] spi_periph: SPIx(x=0,1,2,3,4,5)
\param[in] data: 16-bit data
\param[out] none
\retval none
*/
void spi_i2s_data_transmit(uint32_t spi_periph, uint16_t data)
{
SPI_DATA(spi_periph) = (uint32_t)data;
}因此,该函数的功能仅仅是将传入的数据写进SPI的发送缓冲区中,发送缓冲区是否为空、后续发送是否成功之类的问题是一概不管的,所以我们需要结合spi_i2s_flag_get函数来确定发送时机。
4.4 spi_i2s_data_receive

该函数源码实现如下:
/*!
\brief SPI receive data
\param[in] spi_periph: SPIx(x=0,1,2,3,4,5)
\param[out] none
\retval 16-bit data
*/
uint16_t spi_i2s_data_receive(uint32_t spi_periph)
{
return ((uint16_t)SPI_DATA(spi_periph));
}同样的,该函数的功能仅仅是将SPI接收缓冲区中的数据读出,接收缓冲区是否有数据、缓冲区中的数据是否完整之类的问题同样是不管的。此外,GD32F4的UserManual中特别提到,“……而在全双工主机模式(MFD)中,当发送缓冲区非空时,硬件才接收下一个数据帧。”因此,该函数的使用不仅得结合spi_i2s_flag_get函数来确定时机,还得保证在读取之前数据已经传输完成。
二、代码实现
本库构成思路如下:

其中,SPI驱动层即各厂商的SPI函数库,不同单片机系列与设计厂商的SPI驱动层也各不相同;
寄存器操作层则负责通过各厂商的SPI函数库实现对ICM20602的单寄存器读取、单寄存器写入及多寄存器读取函数,也是将驱动移植至其它单片机平台时唯一需要实现的部分;
功能函数层则由寄存器操作实现对ICM20602的配置、读取等操作,本层建立在寄存器操作层上,仅由ICM20602的硬件决定,与寄存器操作层的实现方式无关。
1.寄存器操作层的实现思路
注:按照ICM20602时序图,在NSS引脚拉低后需要有一个持续时间不小于2ns的延时,因此在寄存器操作开始前会有读/写命令与地址的或运算充当延时。
1.1 单寄存器写入
由于不需要进行接收,寄存器写入的过程中仅考虑SPI_FLAG_TBE和SPI_FLAG_TRANS即可,基本流程如下:

1.2 单寄存器读取
在执行寄存器读取操作时,需要保证寄存器读取到的数据是本周期传输过来的数据,因此地址和读指令写入完成后需要复位RBNE标志位,保证其中的数据不会被误读。图示如下:

1.3 多寄存器读取
与单寄存器读取相似(其实可以直接使用多次单寄存器读取操作取代,只是速度会慢一点),图示如下:

2.寄存器操作层代码
2.1 单寄存器写入
/*
* 功能 ICM20602写寄存器
* 参数 addr 寄存器地址
* dat 需要写入的数据
* 返回 无
*/
static void icm20602_writeReg(uint8_t addr, uint8_t dat)
{
uint8_t cmd;
ICM_NSS_SELECT;
cmd = addr | REGISTER_WRITE; /* 注:此处的运算实质上起到了NSS引脚拉低后的2ns延时作用,因此不可移除 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_RBNE))
spi_i2s_data_receive(ICM_SPI);/* 读取读SPI_DATA寄存器中的数据以复位RBNE标志位 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE))
spi_i2s_data_transmit(ICM_SPI, cmd);/* 发送地址与写指令 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE))
spi_i2s_data_transmit(ICM_SPI, dat);/* 发送需要写入寄存器的值 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TRANS))/* 等待数据传输完毕 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_RBNE))
spi_i2s_data_receive(ICM_SPI);/* 读取读SPI_DATA寄存器中的数据以复位RBNE标志位 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
ICM_NSS_RELEASE;
}2.2 单寄存器读取
/*
* 功能 ICM20602读寄存器
* 参数 addr 寄存器地址
* dat 读取得到的数据
* 返回 无
*/
static void icm20602_readReg(uint8_t addr, uint8_t *dat)
{
uint8_t cmd;
uint8_t res;
ICM_NSS_SELECT;
cmd = addr | REGISTER_READ; /* 注:此处的运算实质上起到了NSS引脚拉低后的2ns延时作用,因此不可移除 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_RBNE))
res = spi_i2s_data_receive(ICM_SPI);/* 读取读SPI_DATA寄存器中的数据以复位RBNE标志位 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE))
spi_i2s_data_transmit(ICM_SPI, cmd);/* 发送地址与读指令 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TRANS));/* 等待数据传输完毕 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_RBNE))
spi_i2s_data_receive(ICM_SPI);/* 本周期(以缓冲区内数据发送完成为结束)内收到的数据不能使用 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE))
spi_i2s_data_transmit(ICM_SPI, 0x00);/* 传输数据以进行接收 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TRANS));/* 等待数据传输完毕 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_RBNE))
res = spi_i2s_data_receive(ICM_SPI);/* 这个周期收到的才是传感器返回的数据 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
ICM_NSS_RELEASE;
*dat = res;
}2.3 多寄存器读取
/*
* 功能 ICM20602读取多字节数据
* 参数 addr 寄存器地址
* dat 读取得到的数据
* len 需要读取的数据长度
* 返回 无
*/
static void icm20602_readBytes(uint8_t addr, uint8_t *dat_array, uint8_t len)
{
uint8_t cmd;
uint8_t *dat_ptr = dat_array;
uint8_t i;
ICM_NSS_SELECT;
cmd = addr | REGISTER_READ; /* 注:此处的运算实质上起到了NSS引脚拉低后的2ns延时作用,因此不可移除 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_RBNE))
spi_i2s_data_receive(ICM_SPI);/* 读取读SPI_DATA寄存器中的数据以复位RBNE标志位 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE))
spi_i2s_data_transmit(ICM_SPI, cmd);/* 发送地址与读指令 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TRANS));/* 等待数据传输完毕 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_RBNE))
spi_i2s_data_receive(ICM_SPI);/* 本周期(以缓冲区内数据发送完成为结束)内收到的数据不能使用 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
for(i = 0; i < len; i++)
{
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE))
spi_i2s_data_transmit(ICM_SPI, *dat_ptr);/* 传输数据以进行接收 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TRANS));/* 等待数据传输完毕 */
while(SET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_RBNE))
*dat_ptr = spi_i2s_data_receive(ICM_SPI);/* 这个周期收到的才是传感器返回的数据 */
while(RESET == spi_i2s_flag_get(ICM_SPI, SPI_FLAG_TBE));/* 等待发送缓冲区清空 */
dat_ptr++;
}
ICM_NSS_RELEASE;
}至此,寄存器操作层已全部实现,然后就可以根据芯片手册的描述配置传感器的各项参数了。为避免本期文章太过冗长,完整版的代码我会在下一篇文章中开源。















 1210
1210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









