







幸存者偏差(英语:survivorship bias),另译为“生存者偏差”,是一种认知偏差。其逻辑谬误表现为过分关注于目前人或物“幸存了某些经历”然而往往忽略了不在视界内或无法幸存这些事件的人或物。
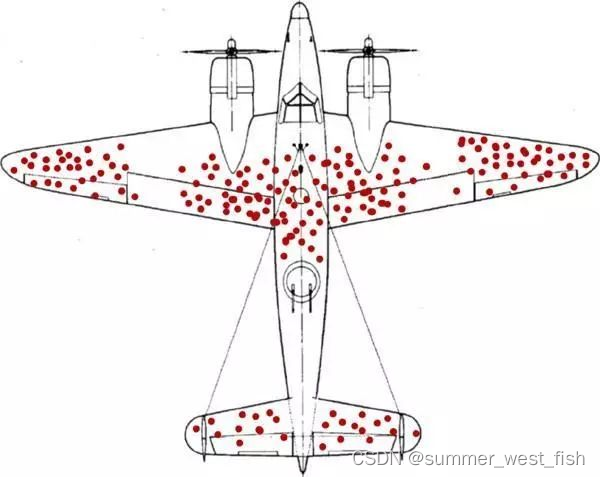
幸存者偏差最早来源于第二次世界大战期间,美国哥伦比亚大学统计学亚伯拉罕·沃德教授接受美国海军要求,运用他在统计方面的专业知识给出关于“飞机应该如何加强防护,才能降低被炮火击落的几率”的建议。
通过统计发现主要受损部位集中在机翼,所以结论是应当减少机腹的装甲加强机翼的装甲?这个结论显然是可笑的,造成这种偏差的原因是机腹中弹的灰机大多数都坠毁了,统计结论产生了偏差,这个偏差被命名为“幸存者偏差”。
再举一个非常简单的例子:
一名记者来到火车站台上,随机询问:“请问你买到火车票了吗?”
一位大妈微微一愣,回答:“买到了”
记者又转向一位精瘦精瘦的年轻人,问:“请问你买到火车票了吗?”
年轻人回答:“买到了”
随后记者又问了5个人,大家都回答:“买到了”
最后记者对着镜头说:“今年虽然火车票难买,但是通过采访我们发现,大家都买到了火车票,现在正满怀希望地赶回家乡,过个团圆年!”幸存者偏差,就是忽略了筛选条件,把经过筛选的结果当成随机结果。
生活中我们大多数人所认为的事情,其实都是错的,举两个例子。
随着参加高考的人数越来越多,高考的录取率也越来越高,2018年的参加高考的人数是975万,前六年的录取率都在74%以上,也就意味着每年100个人参加高考就会有74个同学可以考上大学,如果算上一些民营或者专科类高校,可以说只要参加高考了就可以上大学。
大家现在身边经常会流行这么一句:现在满大街都是大学生了。但其实根据统计本科生占据总人口的比例是3.69%,换句话说,只要你是本科生,你的学历就碾压了97%的中国人!
但其实2018年,国家统计局公布了中国人可支配收入的中位数:2028元/月。这个数据是不是超出大多数人的预期?
-
可支配收入的定义,可以理解为在缴纳税/险/金之后的到手收入;
-
中位数的定义,可以理解为一半的人在此收入之上,一半的人在此收入之下,在统计学里被认为比平均数要更加客观。
如果我说中国有些地方的年轻人,竟然听不懂普通话,一辈子没有走出过他们县城,大家是不是觉得很夸张。
2018年我国农村还有5000万贫困人口。如何定义为贫困人口呢?2016年的标准是年收入少于3026元,请注意这里是年收入而不是月收入。
我们常常都喜欢把自己身边人的情况,当成了世界的普世情况,比如我老婆总说美国很美好,其实她也只是认识一个美国的姑姑而已,认识一个人移民美国的人并不能代表美国很美好。
不要认为马云成功了就去模仿马云,可能淘宝也是幸存者偏差的一种现象。存活下来的企业往往被视为“传奇”,它们的做法被争相效仿,而其实有些也许只是因为偶然原因幸存下来了而已。。
普通人都喜欢基于自己所熟悉的情况做出判断,那么这个判断难免会具有很大的误差,有时候明明有科学的数据放在那里,大家不去参考借鉴,偏偏却喜欢问身边一个半拉子不懂的人。

















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









