






[Ollama+Cherry Studio]三步骤搭建本地化训练模型
好久没有写CSDN了,一直在写公众号。结果发现大伙用的最多的还是CSDN
1.Ollama安装
1.1进去Ollama官网:https://ollama.com/。点击Download下载

1.1.1下载完,直接双击 OllamaSetup.exe安装,不存在选择安装位置。默认安装C盘。安装好之后我们迁移位置。
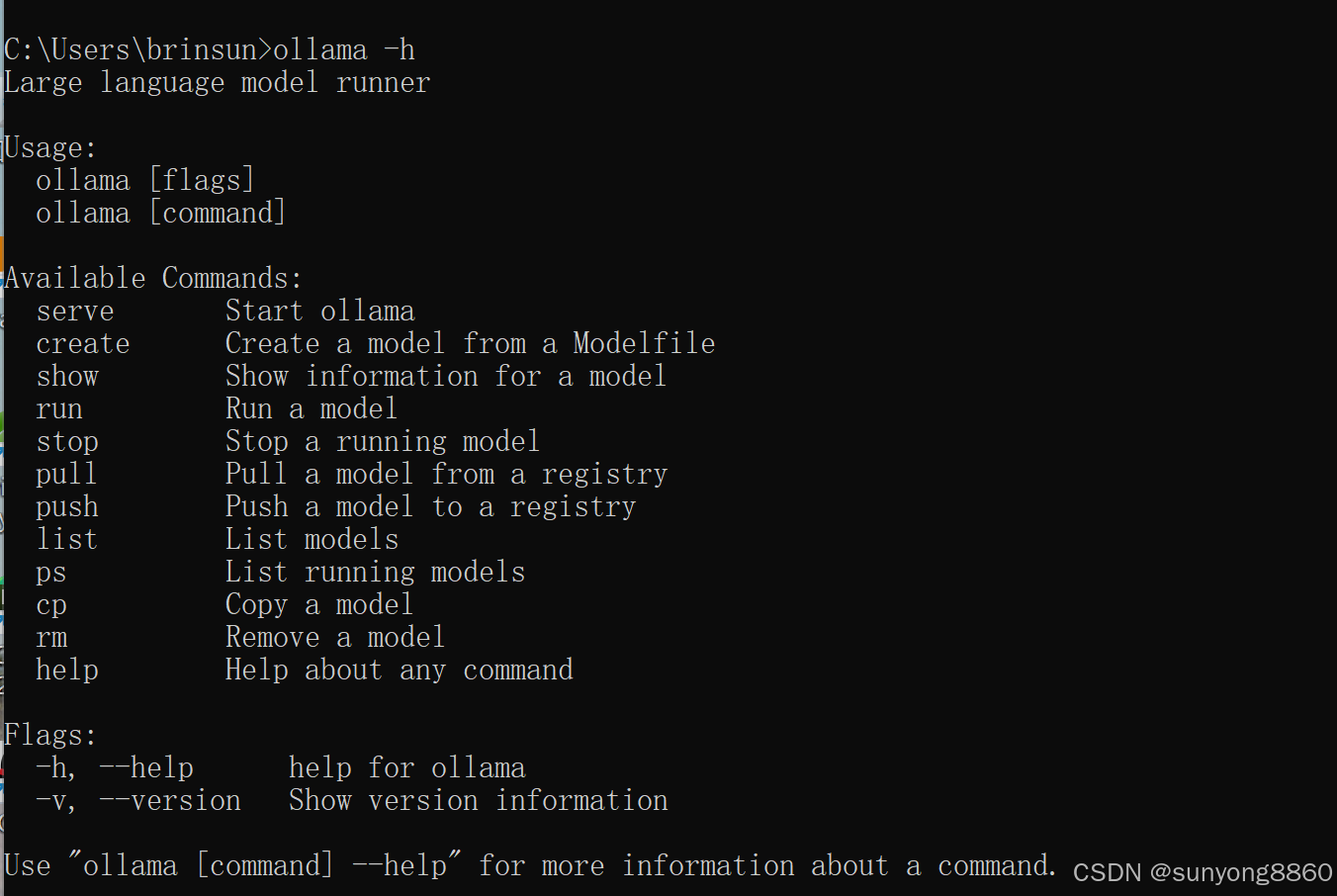
1.1.2安装完成验证:cmd输入:ollama -h。出现如下图说明安装成功。
1.2修改安装位置。
1.2.1首先在任务管理器中关闭 Ollama 和 ollama.exe
1.2.2右击我的电脑属性:进入环境变量配置。系统变量下新建。如下图
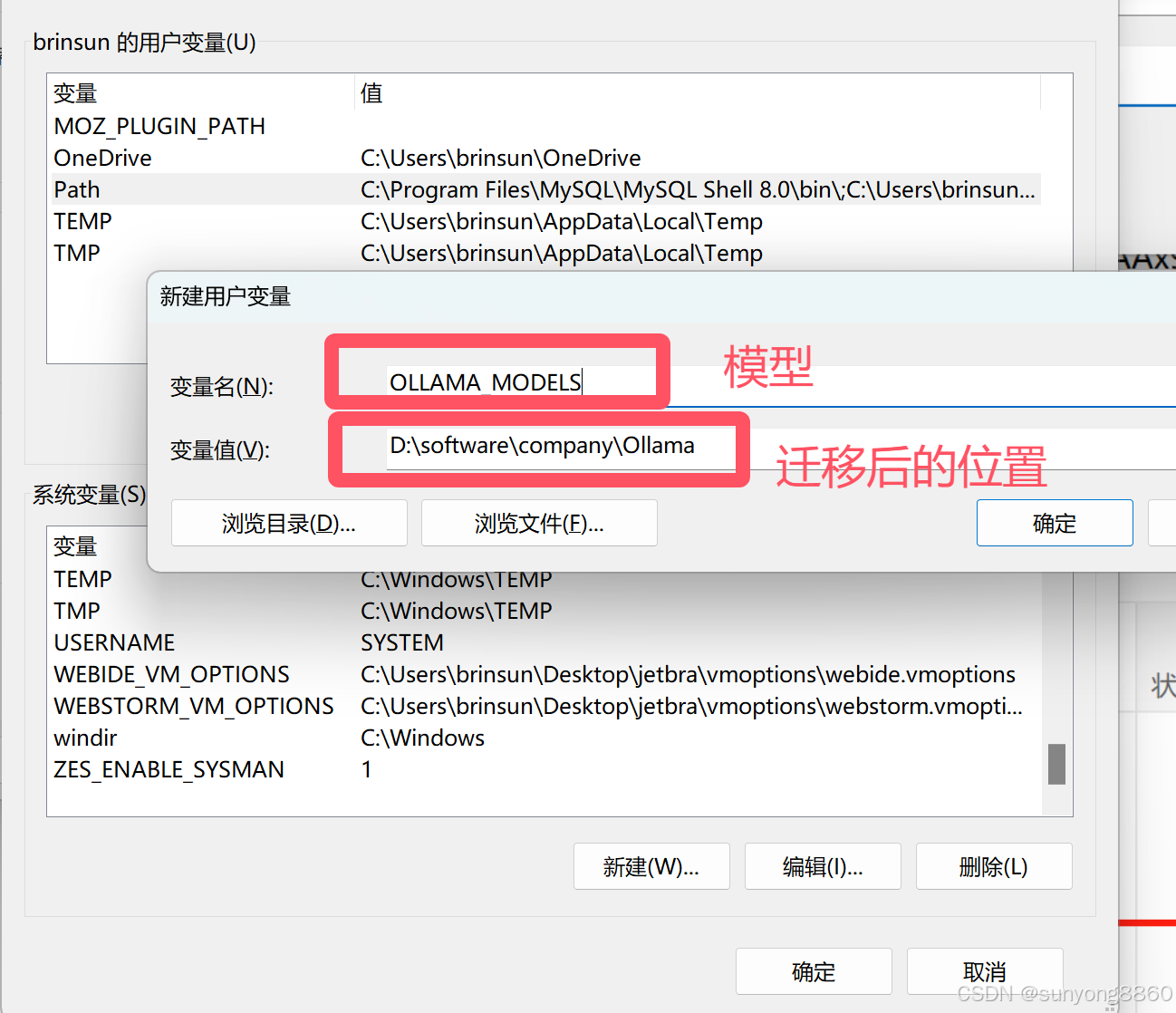
把C盘下Ollama位置找到(C:\Users%username%\AppData\Local\Programs\Ollama),并复制到环境变量配置的对应位置(D:\software\company\Ollama),迁移任务完成。
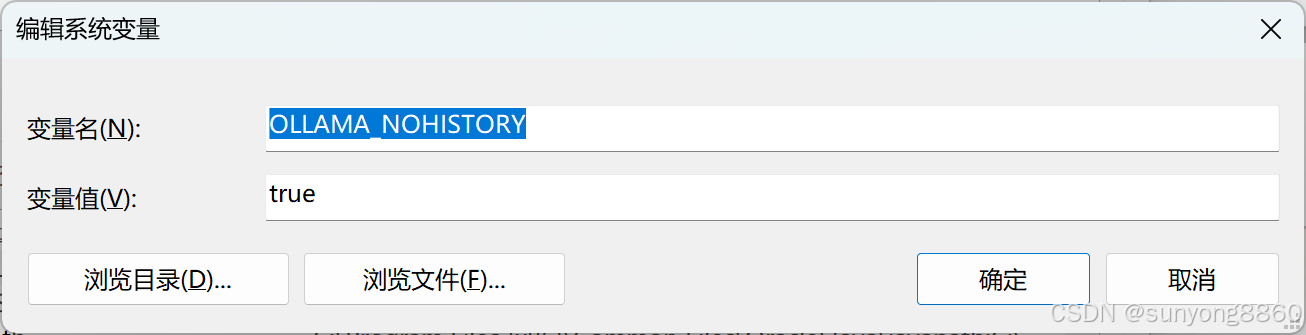
1.2.3设置记住上一次会话。
系统变量里面新建**OLLAMA_NOHISTORY**属性,指为**true**。
其他参数列举
OLLAMA_DEBUG: 显示额外的调试信息(例如:OLLAMA_DEBUG=1)。
OLLAMA_HOST: Ollama 服务器的 IP 地址(默认值:127.0.0.1:11434)。
OLLAMA_KEEP_ALIVE: 模型在内存中保持加载的时长(默认值:“5m”)。
OLLAMA_MAX_LOADED_MODELS: 每个 GPU 上最大加载模型数量。
OLLAMA_MAX_QUEUE: 请求队列的最大长度。
OLLAMA_MODELS: 模型目录的路径。
OLLAMA_NUM_PARALLEL: 最大并行请求数。
OLLAMA_NOPRUNE: 启动时不修剪模型 blob。
OLLAMA_ORIGINS: 允许的源列表,使用逗号分隔。
OLLAMA_SCHED_SPREAD: 始终跨所有 GPU 调度模型。
OLLAMA_TMPDIR: 临时文件的位置。
OLLAMA_FLASH_ATTENTION: 启用 Flash Attention。
OLLAMA_LLM_LIBRARY: 设置 LLM 库以绕过自动检测。
2.安装DeepSeek模型。
DeepSeek模型参数有:“1.5b”、“7b”、“8b”、“14b”、“32b”、“70b” 和 “671b”
b代表的是“billion(十亿)”,如8b指的是8个十亿个参数。以此类推其他参数。
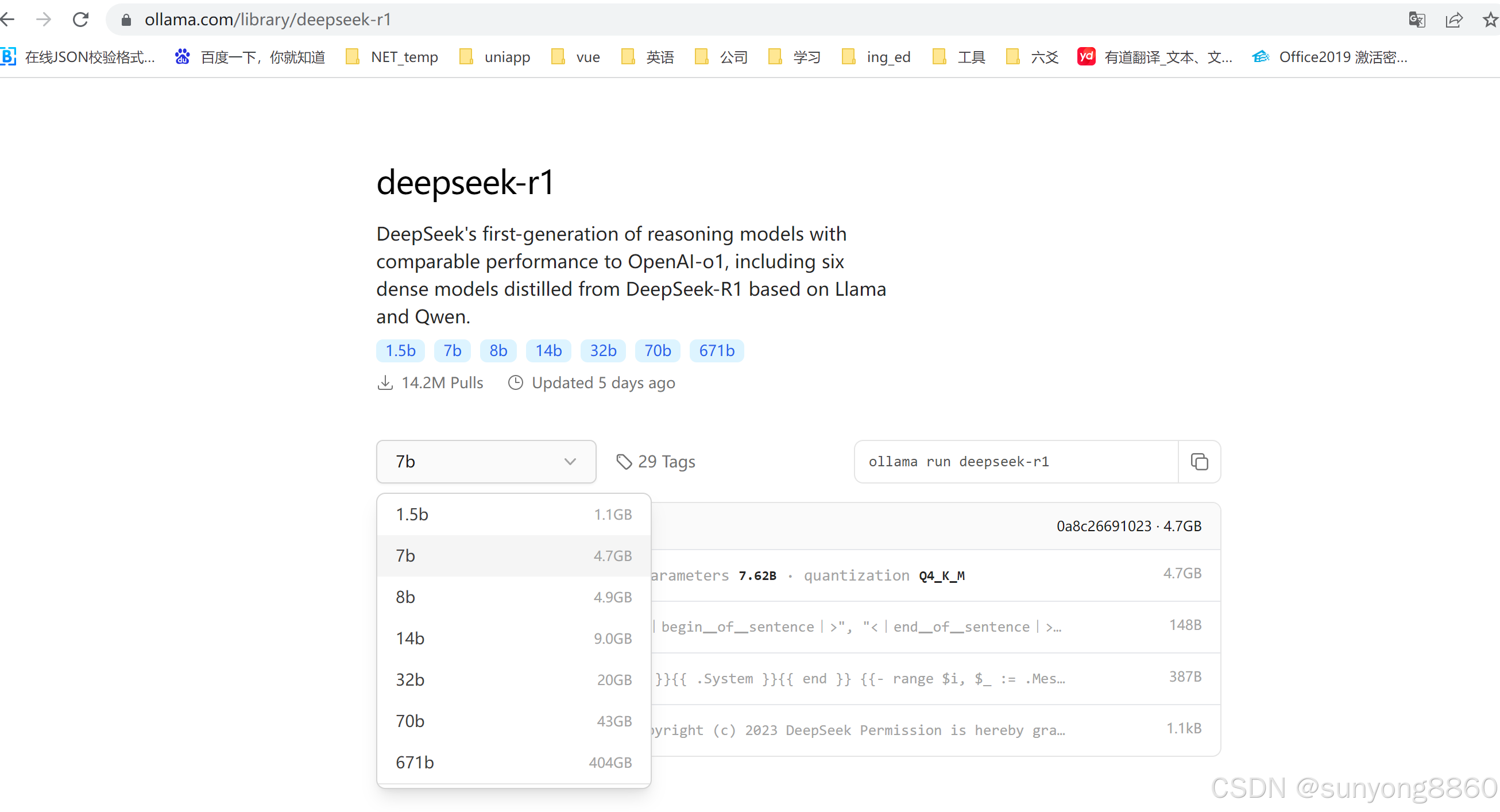
2.1在Ollama命令行中按照。
博主本机电脑按照了两个模型,一个是8b一个14b。具体安装那个模型需要根据自己电脑性能。
初步参考
1.5B 参数模型
GPU: 1-2 个 NVIDIA RTX 3090 或等效显卡
内存: 8-16 GB RAM
存储: SSD,最好 100 GB 可用空间
7B 参数模型
GPU: 2-4 个 NVIDIA RTX 3090 或 RTX A6000,或相当于 16GB VRAM 的其他显卡
内存: 8-16 GB RAM
存储: SSD,最好 400 GB 可用空间
8B 参数模型
GPU: 2-4 个 NVIDIA A100 或 RTX 3090
内存: 32 GB RAM
存储: SSD,最好 400 GB 可用空间(博主安装)
14B 参数模型
GPU: 4-8 个 NVIDIA A100 或 RTX 3090
内存: 32 GB RAM
存储: SSD,至少 500 GB 可用空间(博主安装)
32B 参数模型
GPU: 8 个 NVIDIA A100 或更高规格显卡
内存: 64 GB RAM
存储: SSD,至少 1 TB 可用空间(预估,博主尚未安装)
70B 参数模型
GPU: 8-16 个 NVIDIA A100 或 H100
内存: 128 GB RAM 或更多
存储: SSD,至少 2 TB 可用空间(预估,博主尚未安装)
671B 参数模型
GPU: 多个 NVIDIA H100 或 TPU 集群
内存: 512 GB RAM 或更多
存储: 大容量 SSD 或分布式存储,至少 5 TB 或更多(预估,博主尚未安装)
2.2.1开始安装DeepSeek模型。
继续Ollama窗口输入命令:Ollama DeepSeek-r1:14b
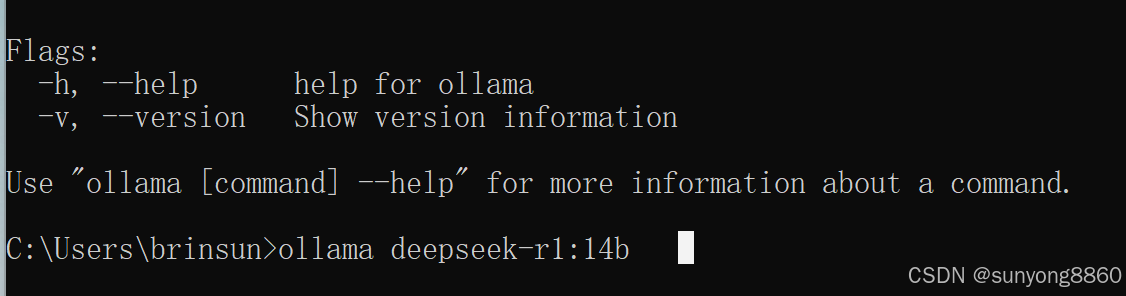
此过程时间较长,8b模型4.9G。14b模型9G。博主一不小心两个都装了。
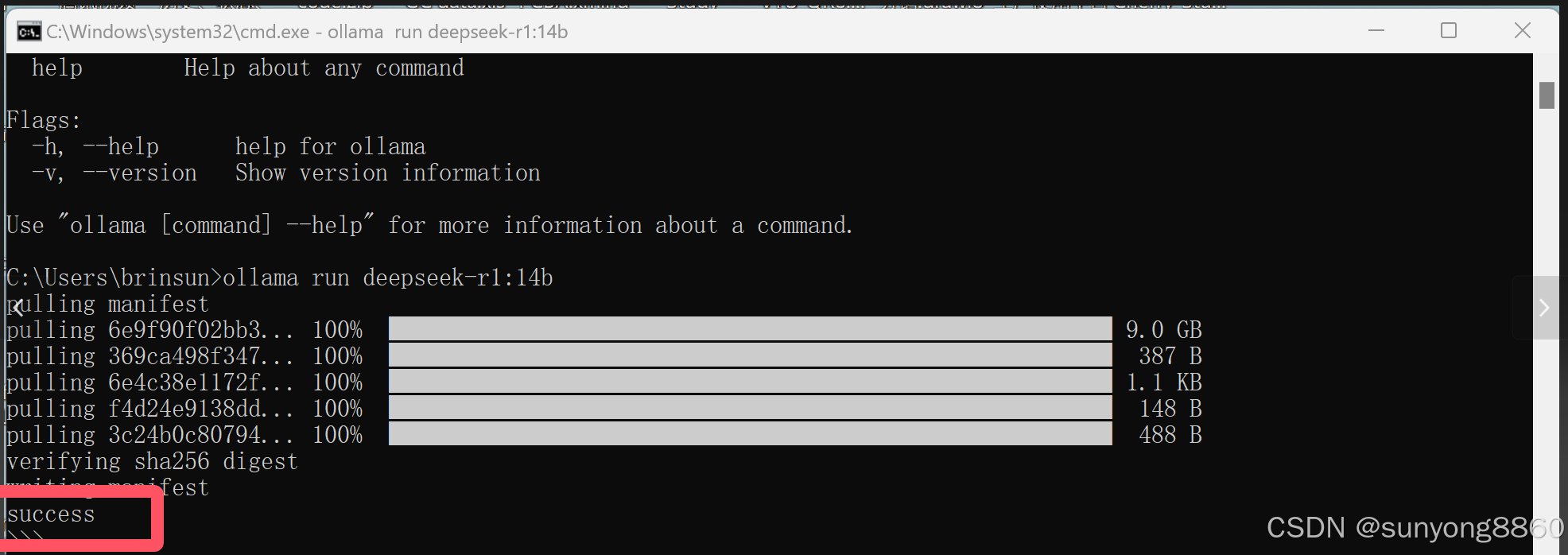
好了,以上都安装成功了。接下来就可以用了。

使用命令:
// 启动命令 deepseek-r1启动的模型名称 14b上述安装的14b模型
ollama run deepseek-r1:14b
// 结束命令 可以直接关闭窗口
/bye

每次用命令行好像也不太方便。博主找了个图形化界面操作的。
3.安装Cherry Studio工具。下载地址:https://cherrystudio.com.cn/
下载安装完成后,配置使用本地化模型。
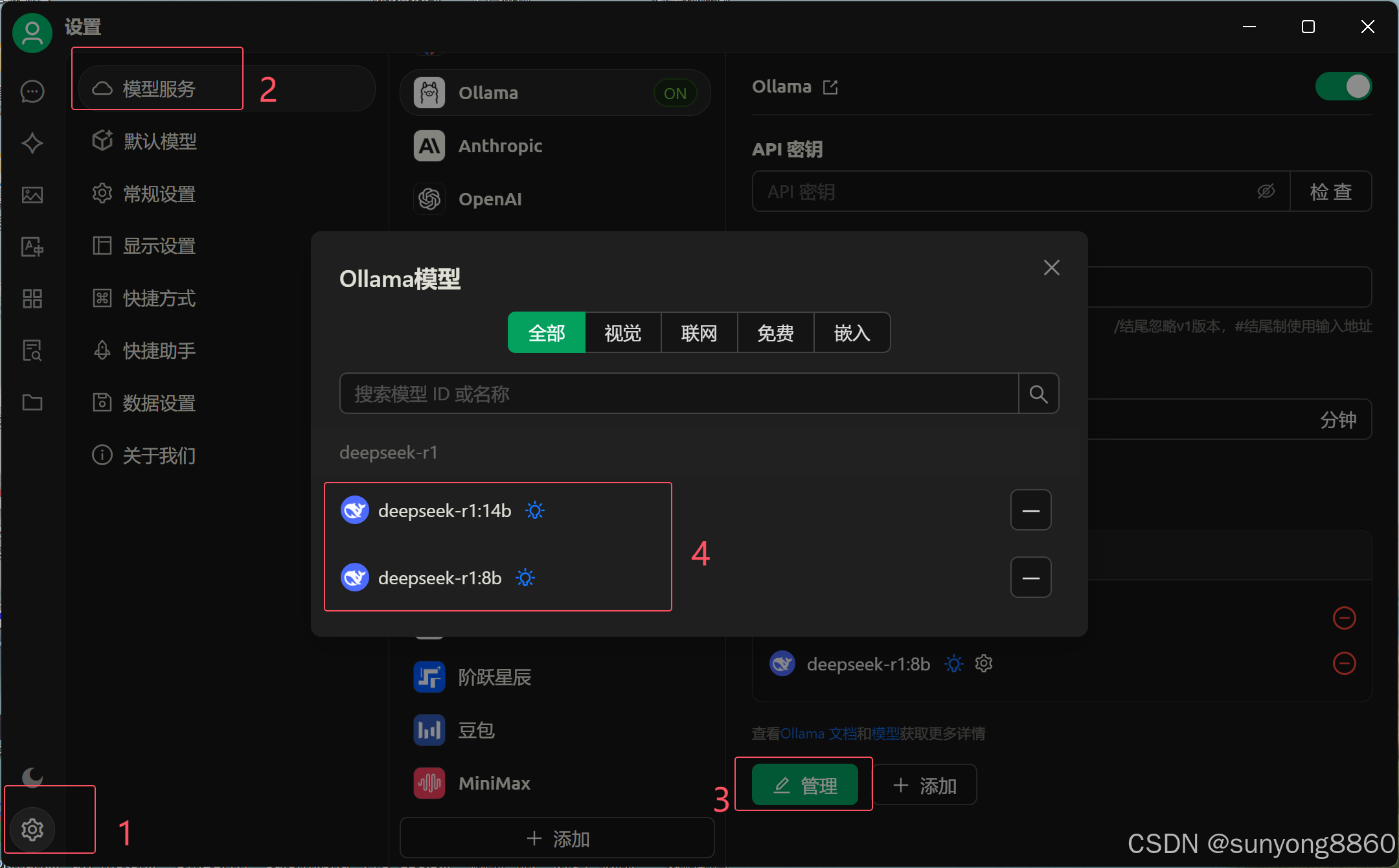
3.1点击左下角设置按钮,进入模型服务页面。找到ollama,有个管理。在管理里面选择本地模型使用。
3.2模型服务里面"硅基流动"获取API秘钥。点击下面蓝色字体(点击这里获取秘钥),跳转页面。创建API秘钥
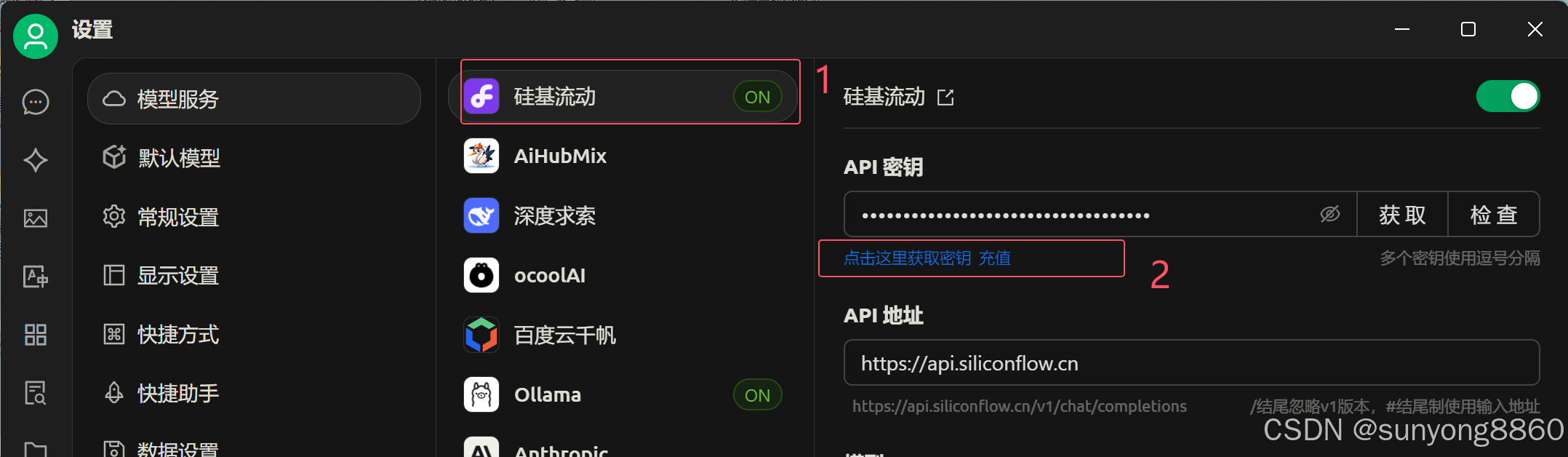
输入完成。就可以开始使用了。
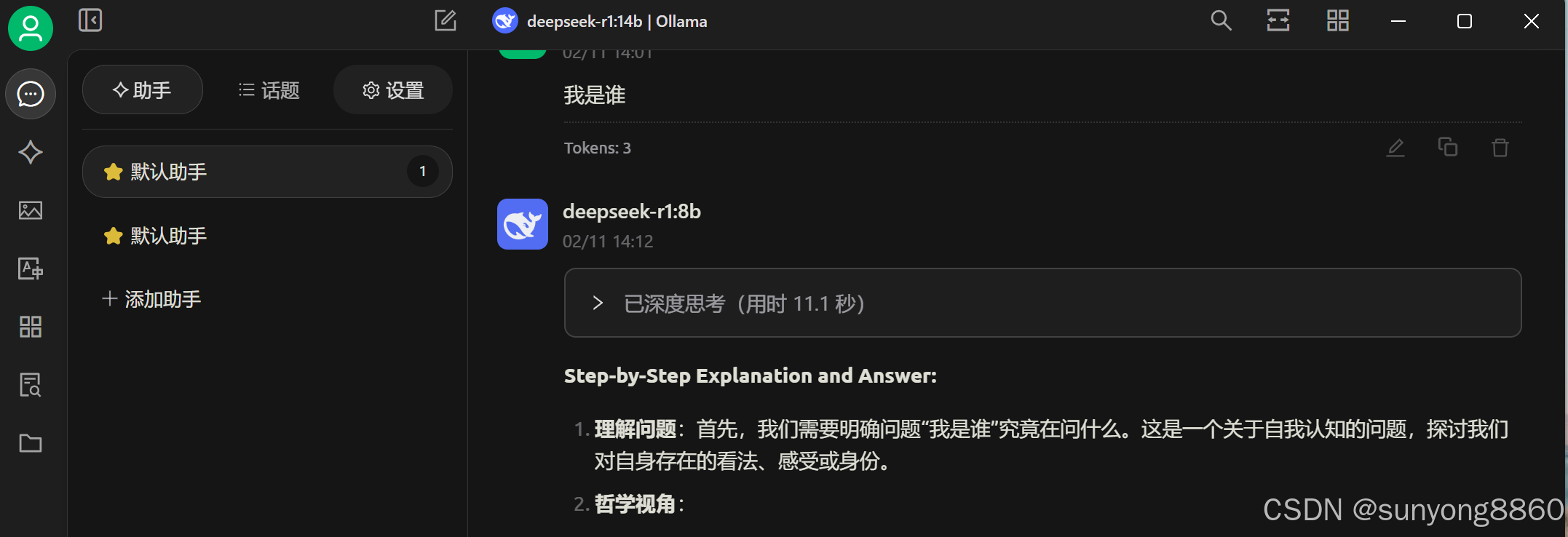
注意:默认助手,每次新建一个需要重新第3步骤,选择模型。在知识库里面,可以来投喂资料训练本地化模型。
公众号:sy157715743

















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









