







在计算机视觉领域中,目标检测(Object Detection)是一个具有挑战性且重要的新兴研究方向。目标检测不仅要预测图片中是否包含待检测的目标,还需要在图片中指出它们的位置。2015 年,Joseph Redmon, Santosh Divvala 等人提出第一个 YOLO 模型,该模型具有实时性高、支持多物体检测的特点,已成为目标检测领域热门的研究算法。本文主要介绍 YOLO 算法及其基本原理。
目录
1 YOLO 算法介绍
在目标检测算法的发展过程中,人们一开始采用 Proposal + 图像分类的思路,Proposal 用于预测目标位置,分类用于识别目标的类别。这类算法被称为 Two-stage 算法,例如 R-CNN,Faster R-CNN 算法。
2015 年,Joseph Redmon, Santosh Divvala 等人在《You Only Look Once: Unified, Real-Time Object Detection》论文中提出 YOLO 模型,开启了 YOLO 算法的研究热潮。经过后来人们的不断改进,YOLO 算法已经发展成为一个庞大的家族,后来人们把第一个 YOLO 模型称为 YOLO v1 模型。

YOLO 检测算法的大致处理步骤:
(1)调整输入图像的大小为 448 x 448;
(2)使用卷积网络对输入图像执行一次预测;
(3)对预测结果进行非极大值抑制。

YOLO 模型使用单个卷积网络同时预测多个边界框,以及对应框的类别概率。与传统的目标检测方法相比,这种统一的模型有以下优点:
(1)YOLO 的预测速度快,由于模型将检测框转化为回归问题,因此只用一个网络同时输出目标的位置与分类信息;
(2)YOLO 模型在进行预测时对图像进行全局推理。与基于滑动窗口和区域建议的技术不同,YOLO 在训练和测试期间看到整个图像,因此它隐式地学习关于类别及其形状的上下文信息。
参考论文链接:
[1] You Only Look Once: Unified, Real-Time Object Detection
[2] YOLO9000: Better, Faster, Stronger
2 YOLO 算法原理
YOLO 算法把输入图像分成 S x S 个方格,每个方格输出一个 B x 5 + C 维的张量。这里,B 是每个方格预测方框(Bounding box)的数目,C 表示需要检测的对象类别数目。如果检测目标的中点落在某个方格内,那么目标物体就由该方格进行检测与输出。
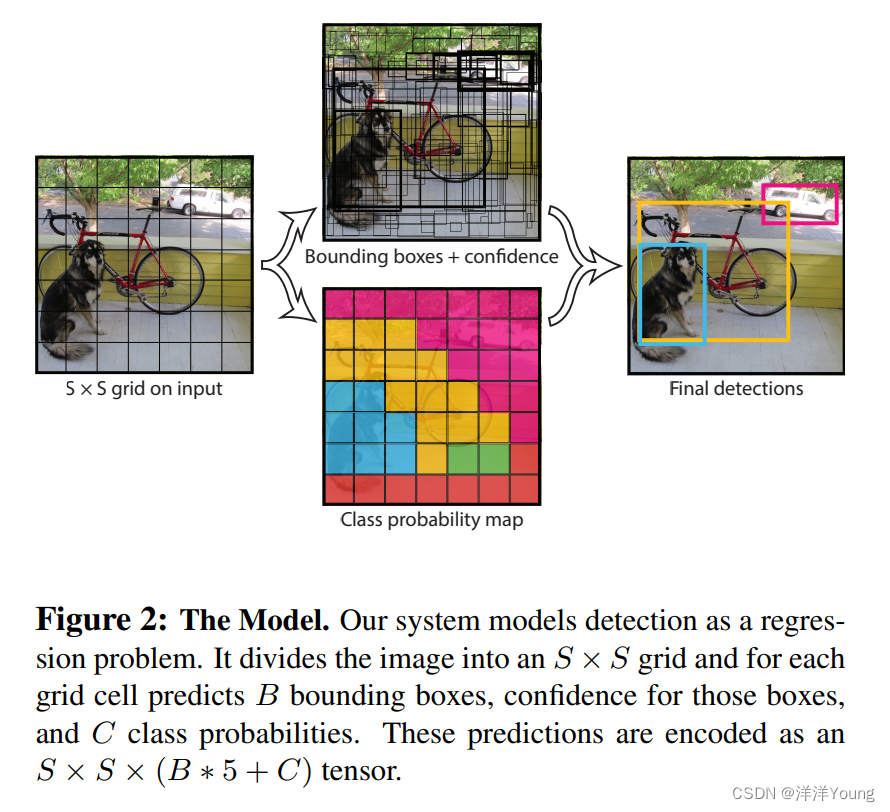
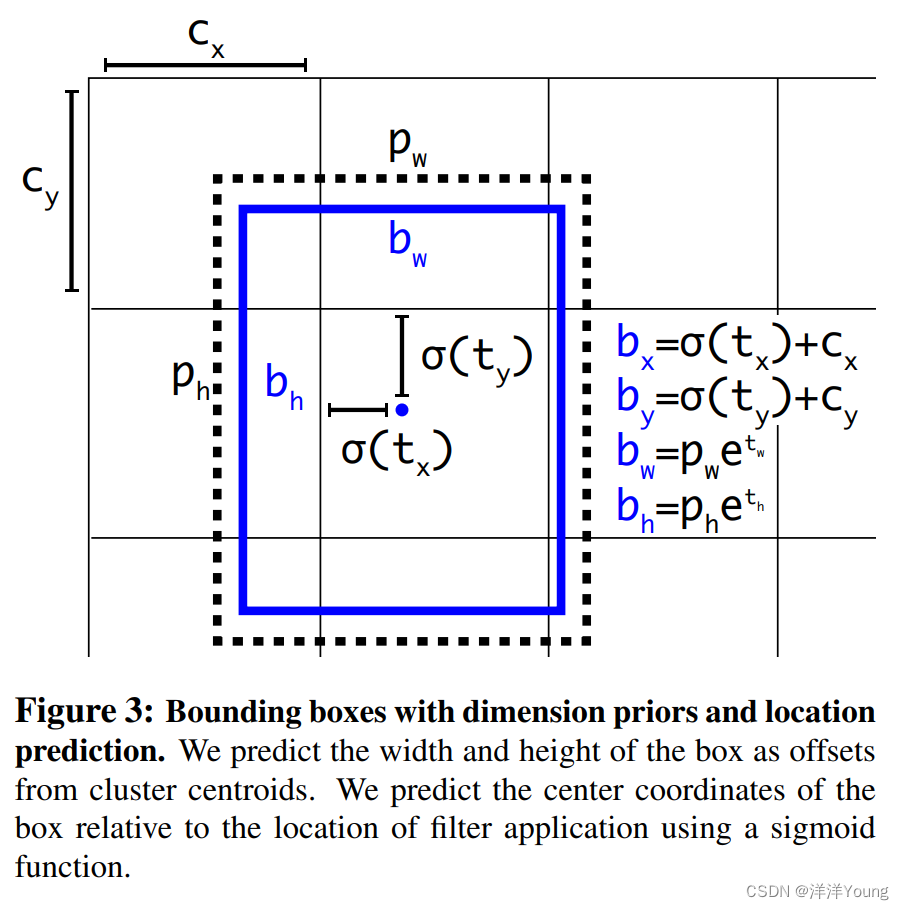
YOLO 算法采用了相对坐标的方法,并使用 Logistic 激活函数,使每个坐标的取值落在区间 0 到 1。目标检测网络在每个边界框处预测 5 个值,分别是 和
. 如果单元格相对图像左上角偏移记为
,并且先验边界框宽度、高度分别记为
,对应的预测结果为:
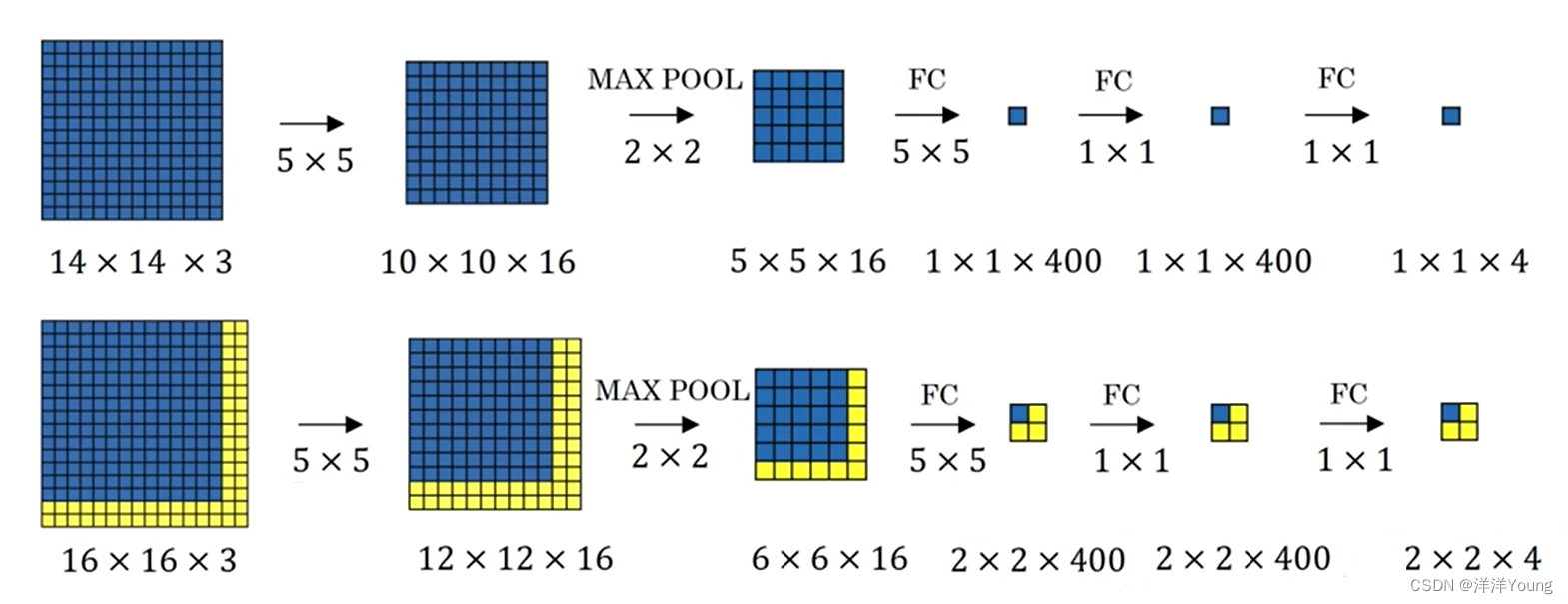
2.1 滑动窗口的卷积实现
YOLO v1 检测网络有 24 个卷积层,以及最后的 2 个全连接层。中间交替的 1×1 卷积层用于减少先前层的特征数量。

相比 YOLO v1 模型,YOLO v2 输出层使用卷积层代替全连接层。这样处理之后,间接地使用卷积算子实现滑动窗口的功能,滑动窗口移动的步长是卷积运算的步长。最终检测网络只需执行一次检测过程,就可以同时输出不同区域的预测结果。
2.2 非极大值抑制
把输入图像分成多个方格的设计思路,增强了网络检测多个物体的能力。通常一个待检测的对象由一个方格进行预测,然而对于较大的检测对象,同一个对象可能会触发多个预测框,非极大值抑制(Non-max suppression)可以解决这个问题。

非极大值抑制的大致过程如下:
(1)选择预测得分最高的预测框;
(2)遍历剩下的预测框,逐个计算 IoU 值;
(3)如果 IoU 值超过阈值(通常设为 0.5 或 0.6),则丢弃预测框,否则保留;
(4)选择预测得分第二高的预测框,重复 (2)~(3)步骤。
2.3 Anchor Box
当图像中存在两个物体,且这两个物体的中点均落在同一个方格中时,目标检测网络只能输出其中一个物体的位置结果。这时就需要引入 Anchor box 的设计思路。
Anchor box 的思路是,预先定义两个形状不同的预测框,然后重新定义预测标签。预测标签同时包含 anchor box1 与 anchor box2 的预测信息。在训练网络时,检测对象会分配给包含其中点的方格,并且具有较高 IoU 值的 anchor box。

由于这些预测框带有先验信息,因此也被称为先验框。

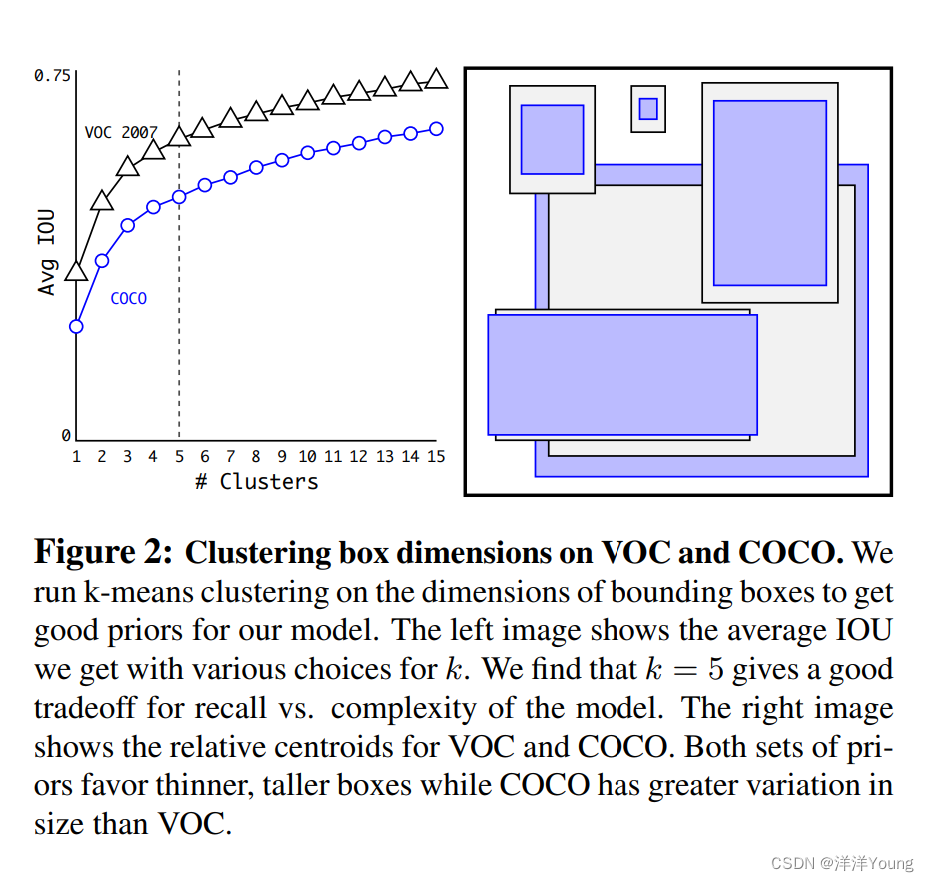
相比手工选择的方式,YOLO v2 模型对训练集的标注框进行了 k-means 聚类。在聚类个数 k 取 5 时,模型在召回率与复杂性之间折衷。

【参考文献】
[1] Joseph Redmon, et al. “You only look once: Unified, real-time object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[2] Joseph Redmon, et al. “YOLO9000: Better, Faster, Stronger” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











