







来源:专知
本文为论文介绍,建议阅读5分钟在这项工作中,我们展示了小规模语言模型的推理能力可以通过自训练得到增强,自训练是指模型从其自身输出中学习的过程。
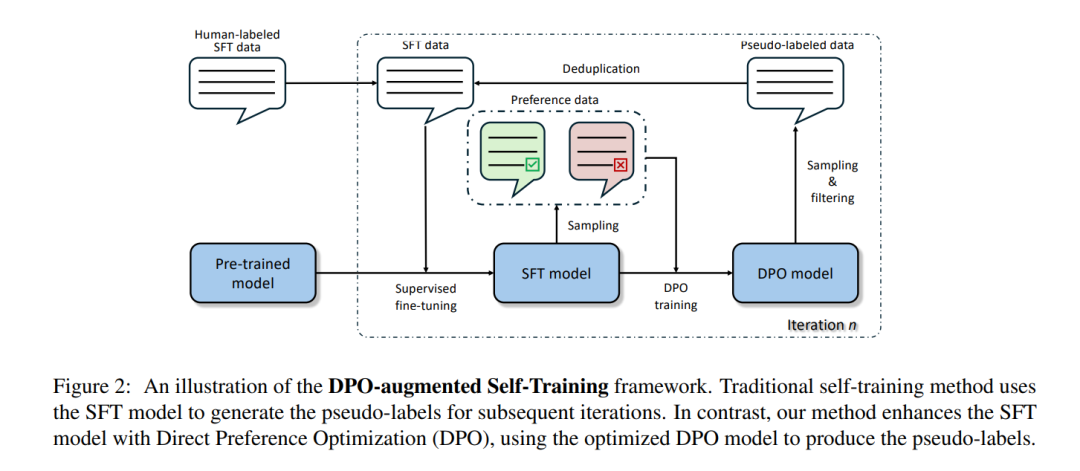
在数学推理任务中有效训练语言模型(LMs)需要高质量的有监督微调数据。除了从人类专家那里获得注释,常见的替代方法是从更大且更强大的语言模型中采样。然而,这种知识蒸馏方法可能成本高昂且不稳定,特别是依赖于如GPT-4(OpenAI, 2023)这样封闭源码的专有模型时,其行为往往不可预测。在这项工作中,我们展示了小规模语言模型的推理能力可以通过自训练得到增强,自训练是指模型从其自身输出中学习的过程。我们还展示了传统自训练可以通过一种称为直接偏好优化(Direct Preference Optimization, DPO)的方法进一步增强。通过将DPO整合到自训练中,我们利用偏好数据引导语言模型朝着更准确和多样化的链式思维推理发展。我们在各种数学推理任务中使用不同的基础模型评估了我们的方法。实验结果表明,与依赖大型专有模型相比,这种方法不仅提高了语言模型的推理性能,还提供了一种更具成本效益和可扩展的解决方案。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









