







来源:时序人
本文约3400字,建议阅读5分钟
本文介绍了多维时序分类中的Transformer。多变量时间序列分类(MTSC)由于其多样的现实世界应用而引起了广泛的研究关注。最近,利用 Transformer 进行MTSC已经取得了最先进的性能。然而,现有方法主要关注通用特征,提供了对数据的全面理解,但它们忽略了对于学习每个类别代表性特征至关重要的类别特定特征。这导致在数据集不平衡或整体模式相似但在类别特定细节上存在差异的数据集上表现不佳。
针对上述问题,本文介绍一篇来自墨尔本大学和莫纳什大学的最新相关研究工作,目前已被KDD 2024接收。研究者提出了一种新颖的Shapelet Transformer(ShapeFormer)用于多变量时间序列分类。它包含两个 Transformer 模块,旨在识别时间序列数据中的类别特定特征和通用特征。特别是,第一个模块通过利用从整个数据集中提取的判别性子序列(shapelets)来发现类别特定特征。同时,第二个 Transformer 模块采用卷积滤波器来提取跨所有类别的通用特征。实验结果表明,通过结合这两个模块,ShapeFormer 在分类准确性方面与最先进的方法相比达到了最高排名。

【论文标题】
ShapeFormer: Shapelet Transformer for Multivariate Time Series Classification
【论文地址】
https://arxiv.org/abs/2405.14608
【论文源码】
https://github.com/xuanmay2701/shapeformer
论文背景
时间序列分类在时间序列分析领域是一个基础和至关重要的方面。然而,在多元时间序列分类(MTSC)的研究中仍然存在许多挑战,尤其是在捕获变量之间的相关性方面。
在过去的几十年里,不少研究者已经引入了各种方法来提高 MTSC 的性能。其中,shapelet(类别特定的时间序列子序列)展示了其有效性。这种成功源于每个 shapelet 包含代表其类别的特定类信息,且 shapelet 与其类别时间序列之间的距离远小于与其他类别时间序列的距离(见图1)。因此,人们越来越关注在 MTSC 领域利用 shapelet 的能力。
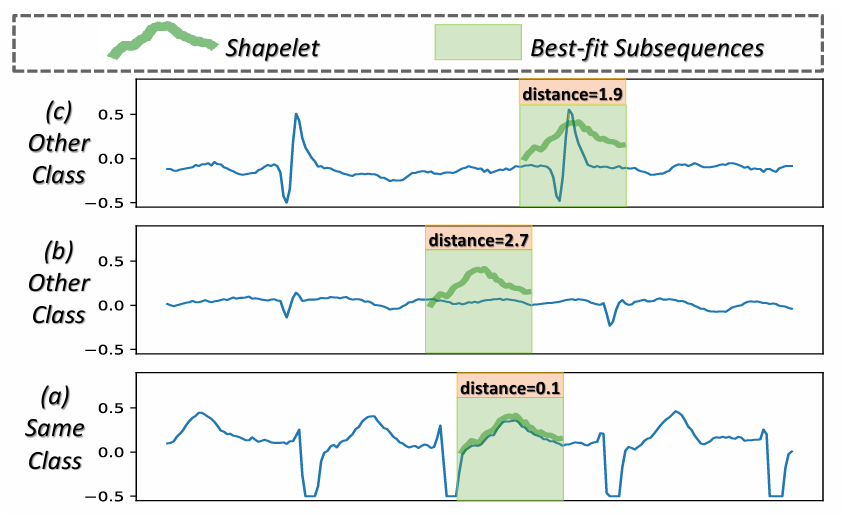
图1:心房颤动数据集中的shapelet
显然,在多元时间序列分类(MTSC)中使用的 Transformer 已经展示了最先进的(SOTA)性能。现有方法仅从时间戳或时间序列中的公共子序列中提取通用特征作为 Transformer 模型的输入,以捕获它们之间的相关性。这些特征仅包含时间序列的通用特性,提供了对数据的广泛理解。然而,它们忽略了模型捕获每个类别代表性特征所必需的关键类别特定特征。
因此,模型在以下两种情况下表现不佳:
数据集中的实例在总体模式上非常相似,仅在次要类别特定模式上存在差异,仅使用通用特征无法实现有效分类;
不平衡数据集,其中通用特征仅关注于对大多数类别的分类,而忽略了少数类别。
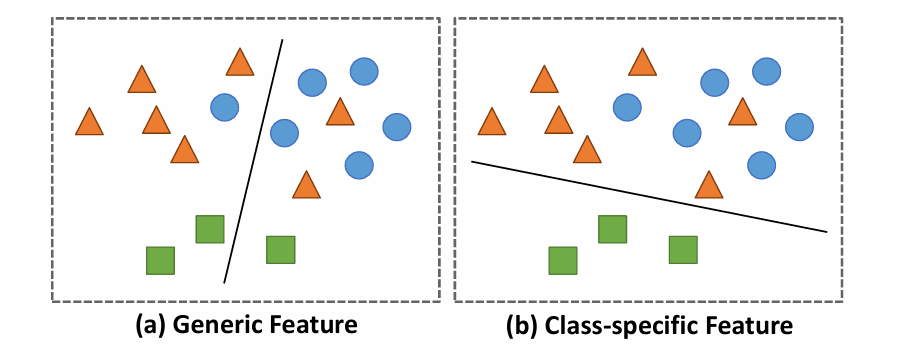
图2:使用(a)通用特征的分离超平面具有更高的总体准确率,而使用(b)类别特定特征的分离超平面在分类单个类别时表现更好。
模型方法
ShapeFormer 是一种基于 Transformer 的方法,它结合了时间序列中类别特定特征和通用特征的优点。与现有的基于Transformer 的MTSC方法相比,ShapeFormer 首先从训练数据集中提取 shapelet,随后对于给定的输入时间序列,它将被处理通过两个Transformer模块,包括类别特定的shapelet Transformer 和通用的卷积 Transformer。这两个模块的输出随后被连接起来,并送入最终的分类头。
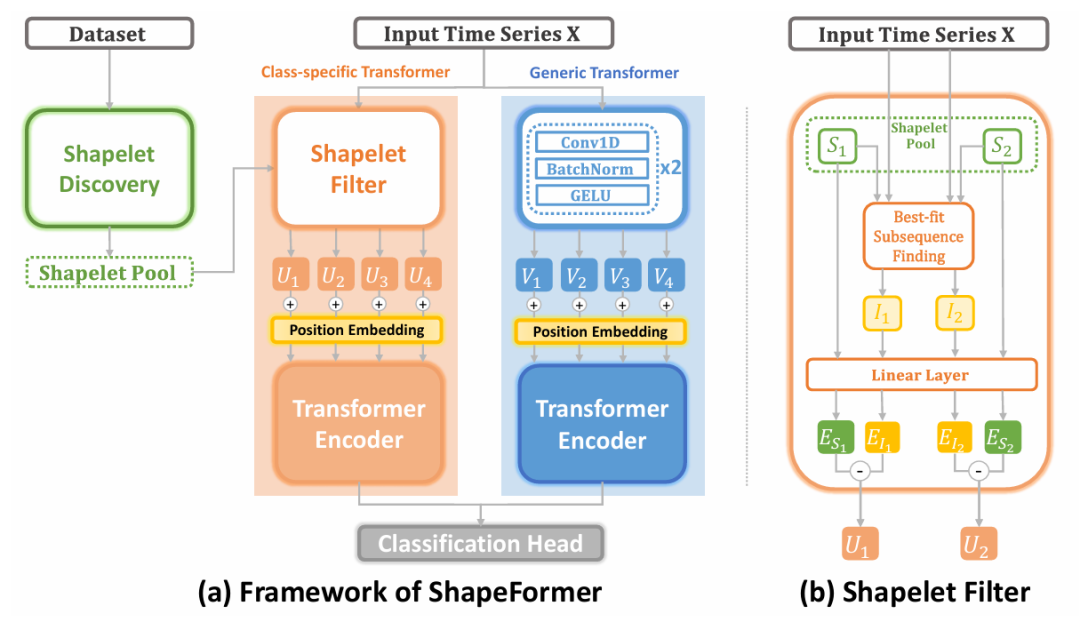
图3:ShapeFormer的总体架构
01 Shapelet的发现
研究者引入了一种 Offline Shapelet Discovery (OSD) 方法,用于从多变量时间序列的训练数据集中提取 Shapelets。与其他方法相比,OSD 采用感知重要点(PIPs),通过选择紧密模拟原始数据的点来压缩时间序列数据,从而高效地选择高质量的 shapelet。选择过程基于重构距离,并且连续选择最高索引。文中将重构距离定义为目标点与由两个最近选择的重要点重构的直线之间的垂直距离。
该方法包含两个主要阶段:shapelet 提取和 shapelet 选择。
在第一阶段,OSD 首先通过识别 PIPs 来提取 shapelet 候选者;在第二阶段,为每个类别选择相同数量的 shapelet。
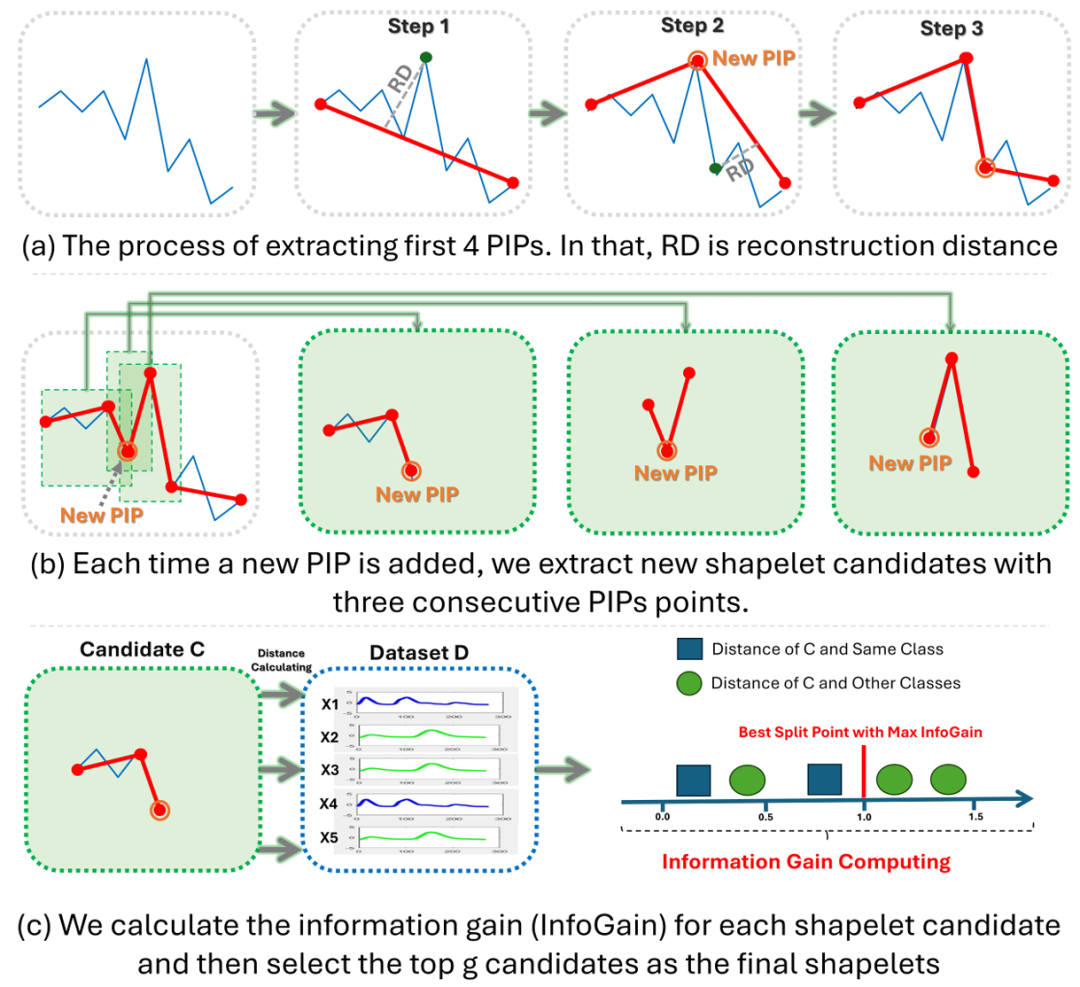
图4:Offline Shapelet Discovery(离线Shapelet发现)的过程
02 特定类别的Transformer
Shapelet Filter。为了利用 shapelet 的特定类别特性,研究者提出了 Shapelet Filter,该过滤器用于有效地为 Transformer 模型发现输入标记,并在输入时间序列中发现与 Shapelets 最匹配的子序列(如图5a所示)。为了减少计算时间并有效利用 shapelet 的位置信息,研究者提出将最佳匹配子序列的搜索限制在 shapelet 实际位置左右两侧的超参数窗口大小𝑤内的邻近区域。
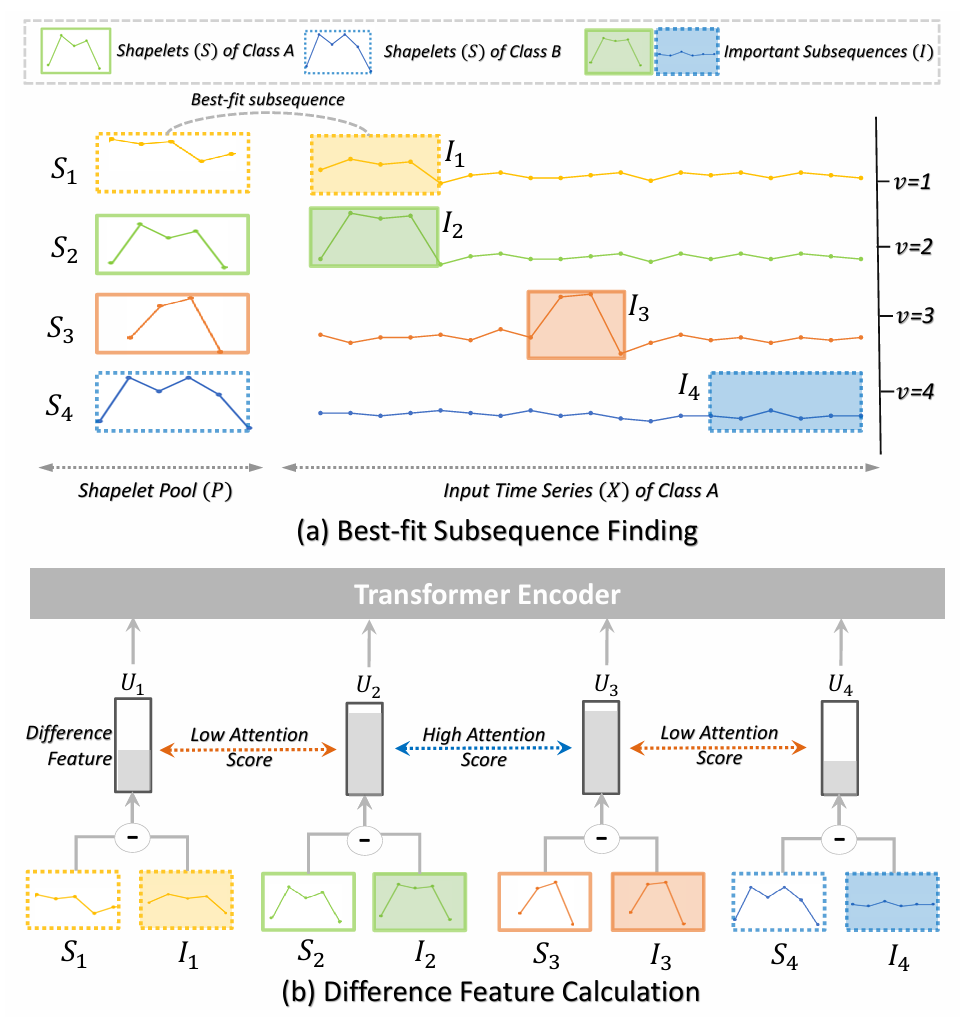
图5:(a)最佳匹配子序列查找方法;(b)差异特征计算方法
位置嵌入。为了更好地指示 shapelets 的位置信息,此处考虑了三种类型的位置嵌入:起始索引、结束索引和变量。具体来说,研究者建议使用这些索引的独热向量表示,然后使用线性投影器来学习它们的嵌入。仅仅使用 shapelets 的位置而不是最佳匹配子序列的位置时,性能会得到提升。这种改进可以归因于固定位置比最佳匹配子序列的不稳定位置更容易学习。
Transformer编码器。将特定类别的差异特征及其对应的位置嵌入输入到 Transformer 编码器中,以学习它们之间的相关性。由于这些特征具有类别代表性特征,与不同类别的特征相比,同一类别内的特征的注意力得分会得到提升。这种增强有助于模型更好地区分不同的类别。此外,由于 shapelets 的性质,差异特征具有跨时间序列中不同时间位置和变量的显著子序列的识别能力。这种能力使该模块能够有效地捕获时间序列数据中的时间和变量依赖性。
类别标记。使用信息增益最高的 shapelet 的第一个差异特征作为用于最终分类的类别标记。这样做的原因是,当对所有标记进行平均时,会丢失关于不同特征𝑈𝑖的信息。此外,携带最高信息增益的第一个标记包含了对于有效分类时间序列最重要的特征。
03 通用Transformer
通用 Transformer 利用卷积滤波器从时间序列中提取通用特征。具体来说,研究者采用了两个 CNN 组件,每个组件都包含 Conv1D、BatchNorm 和 GELU,以有效地发现通用特征。第一个块旨在通过使用 Conv1D 滤波器∈R^(1×𝑑𝑐)来捕获时间序列中的时间模式。另一方面,第二个块使用 Conv1D 滤波器∈R^(𝑉×1)来捕获时间序列中变量之间的相关性。
之后,这些特征将被送入多头注意力头中以学习相关性。每个注意力头都有能力捕获时间序列数据中的不同模式。
实验分析
数据集方面,研究者使用了 UEA 存档中的 30 个不同的多变量时间序列分类数据集,这些数据集涵盖了多个领域,如人体活动识别、运动分类、心电图分类等。
表1展示了 ShapeFormer 与其他方法在 UEA 数据集上的准确率对比结果,ShapeFormer 在多个数据集上取得了最佳性能,并在平均排名和 top-1 数量上均表现优异。ShapeFormer 可以被认为是 MTSC 领域的最新技术水平(SOTA)。
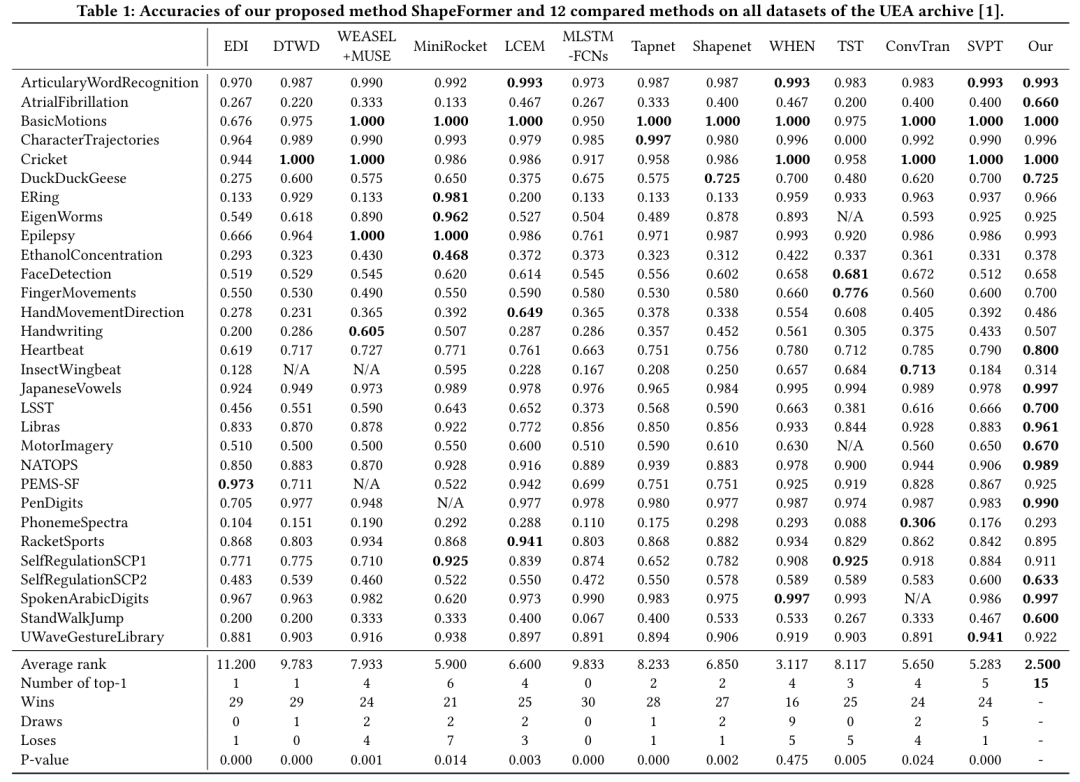
表1:在UEA档案的所有数据集上,ShapeFormer方法与12种对比方法的准确率
对于使用 Shapelets 的有效性方面,研究者比较了使用随机子序列、如通用子序列和本文方法中的 shapelets 时的性能。结果表明,在所有五个数据集上,shapelets 在准确性方面都优于其他两种方法。这突出了高区分度的 shapelet 特征在提高基于Transformer 的模型性能方面的优势。
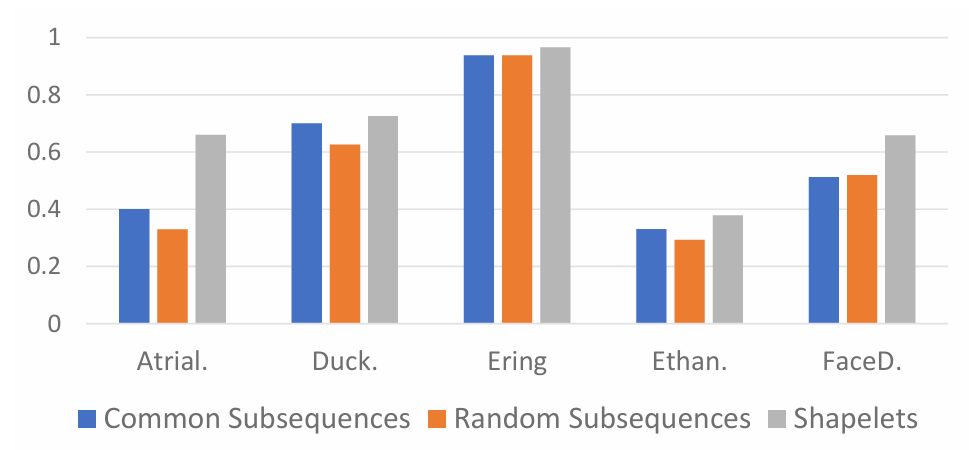
图6:使用shapelets和其他两种类型子序列的准确率

图7:ShapeFormer的三种变体与基线(SVP-T[50]——当前基于Transformer的SOTA方法)的平均排名
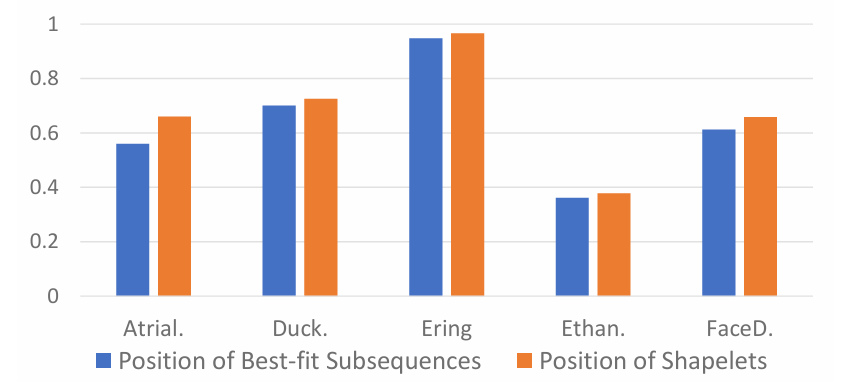
图8:使用最佳拟合子序列位置和shapelets位置的准确率

图9:不同差异特征计算方法的平均准确率排名
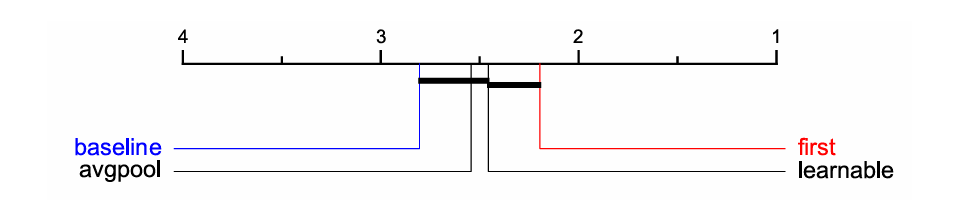
图10:不同类别标记设计的平均准确率排名
为了说明结合类别特定和通用特征 Transformer 模块对不平衡数据进行分类的有效性,研究者在 LSST 数据集上进行了实验。LSST 数据集包含16个类别,实验随机选择了 4 个类别,分别用蓝色、橙色、绿色和红色表示。显然,蓝色和红色类别的样本数量与绿色和橙色类别相比显著较少。图11(a)显示,通用 Transformer 优先考虑了多数类(绿色和橙色),但忽略了少数类(蓝色和红色)。然而,在图11(b)中,类别特定 Transformer 和通用 Transformer 的结合有效地区分了所有四个类别。
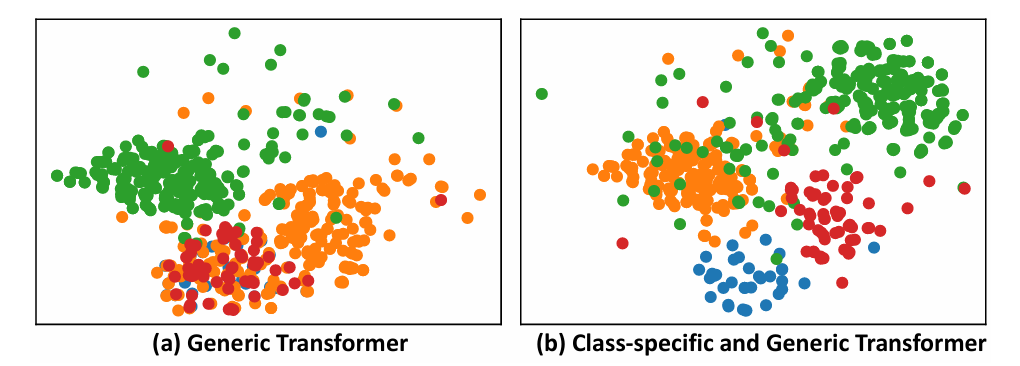
图11:LSST数据集4个类别在使用(a)通用Transformer和(b)类别特定与通用Transformer结合时的t-SNE可视化
为了解释 ShapeFormer 的结果,研究者使用了来自 UEA 存档的 BasicMotions 数据集,重点关注具有4个类别(打羽毛球、站立、行走和跑步)的人类活动识别。图12(a)突出了 ShapeFormer 在时间序列的不同位置和变量中识别关键子序列的能力。此外,属于同一“行走”类别的 shapelets 往往与最佳拟合子序列的相似性更高,而不是来自其他类别的 shapelets。在图12(b)揭示了同一类别内的 shapelets 通常获得更高的注意力分数。这种增强的注意力使模型能够更多地关注同一类别内 shapelets 之间的相关性,从而提高整体性能。
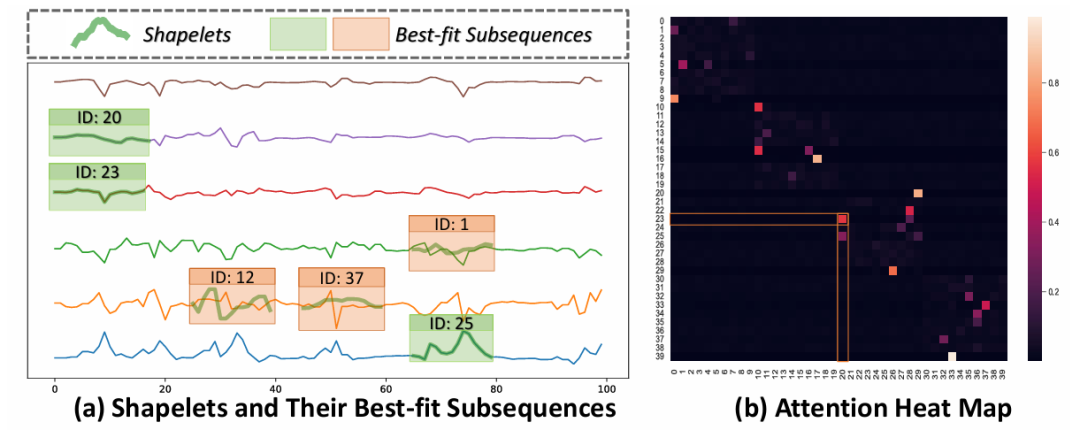
图12:(a) 绿色框描绘了排名前三的shapelets,橙色框展示了从BasicMotions数据集中“行走”类别的一个随机输入时间序列中提取的来自其他类别的三个随机shapelets。(b) 所有shapelets的注意力热图。
在未来的工作中,研究者计划利用 shapelets 在许多不同的时间序列分析任务(如预测或异常检测)中的强大功能。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 1592
1592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









