






机器学习:
三个基本的要素,任务T、经验E和性能P。机器学习=通过经验E的改进后,机器在任务T上的性能p所度量的性能有所改进=T–>(从E中学习)–>P(提高)~~
监督学习
-
监督学习分为回归和分类问题
-
回归问题是预测连续输出的结果,
-
分类问题是预测离散数据的结果。(0/1输出)
-
-
训练集:几组样本数据用来拟合假设函数
-
代价函数:
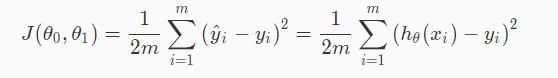
除以 m或2m代价函数最优化的结果都是相同的,这里为了后续求导计算方便,因此用2m
-
梯度下降:
-


- 上图中每个“星”之间的距离代表由我们的参数α确定的步长。较小的α将导致较小的步长,较大的α将导致较大的步长。步骤的执行方向由的偏导数确定
(θ0,θ1)。取决于一个人在图上开始的位置,一个人可能会在不同的点结束。上图为我们显示了两个不同的起点,它们以两个不同的位置结束。(会有不同的局部最优解)
- 上图中每个“星”之间的距离代表由我们的参数α确定的步长。较小的α将导致较小的步长,较大的α将导致较大的步长。步骤的执行方向由的偏导数确定
-

-
:=表示赋值,而=表示声明 -
α:学习速率(步长) -
θ0和θ1需要同时更新(右下并不是同时更新,因为temp1的计算用到了更新后的θ0) -

-
当我们接近局部最优时, 其定义就是导数等于0。 当我们接近局部最优,导数项会自动变 小,所以梯度下降会自动采取更小的步子。 这就是不需要减小alpha或时间的原因。
无监督学习
- 无监督学习是在几乎或根本不知道问题结果的情况下进行预测
- 可以通过基于数据中变量之间的关系对数据进行聚类来推导此结构(非集群:(鸡尾酒会))。
之间的关系对数据进行聚类来推导此结构(非集群:(鸡尾酒会))。















 9188
9188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









