






引言
在大模型应用落地的过程中,我们常常面临一个矛盾:大模型(如QwQ)拥有强大的能力但计算成本高昂,而小模型(如qwen2.5-7B)部署便捷却性能有限。知识蒸馏(Knowledge Distillation)技术正是解决这一矛盾的有效方法。
本文将详细介绍如何利用阿里云百炼平台,实现从QwQ到Qwen小模型的知识蒸馏全过程,显著提升小模型的计算效率与推理能力。
目标
通过知识蒸馏技术,利用教师模型的推理能力,生成推理数据,来对学生模型进行sft,从而提升学生模型在三位数乘法数学计算任务中的表现。
实验验证了仅通过生成推理类SFT数据和简单数据清洗,即可显著增强小模型的垂域能力。
知识蒸馏简介
什么是知识蒸馏?
知识蒸馏(Knowledge Distillation, KD)是一种迁移学习技术,通过让一个复杂的大模型(教师模型)指导轻量级的小模型(学生模型)学习,从而在减少参数量的同时保留性能。其核心思想是将教师模型的“知识”(如输出概率分布或精确答案)作为监督信号,训练学生模型。
本实验采用的蒸馏类型:QwQ(教师)生成精确答案作为学生模型Qwen2.5的训练标签。
实验设计与步骤
1. 数据生成
生成6000条三位数乘法题,确保问题唯一性,分为训练集(5500条)和测试集(500条)。
import json
import random
def generate_multiplication_questions(num_questions):
questions = set() # 使用集合确保唯一性
while len(questions) < num_questions:
num1 = random.randint(100, 999)
num2 = random.randint(100, 999)
question = f"{num1} * {num2} = ?"
answer = num1 * num2
questions.add((question, answer))
return list(questions)
def main():
num_questions = 6000
questions_answers = generate_multiplication_questions(num_questions)
data = [{"question": q, "answer": a} for q, a in questions_answers]
with open("multiplication_questions.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=4)
if __name__ == '__main__':
main()2. 模型蒸馏(教师模型生成标签)
通过阿里云DashScope API调用QwQ模型,批量生成问题的正确答案,输出到qwq_output.json中
友情提示:
百练平台大模型免费的token额度不多,所以如果想用免费的自己跑一跑链路不额外花钱的话,建议生成70条数据,60条训练,10条对比,如果算力足够,那么数据就6000条
import json
import time
from http import HTTPStatus
import dashscope
# 这里要自己去申请key
dashscope.api_key = 'sk-xxx'
def call_function(question):
response = dashscope.Generation.call(
model='qwq-32b-preview',
messages=[{'role': 'user', 'content': question}],
result_format='message',
stream=True,
incremental_output=True,
temperature=0.01
)
if response.status_code != HTTPStatus.OK:
print(response)
return ["执行时出错", 0]
full_content = ""
first_bag = None
start_time = time.time()
for chunk in response:
if chunk.status_code == HTTPStatus.OK:
full_content += chunk.output.choices[0].message.content
if first_bag is None:
first_bag = time.time() - start_time
return [full_content, first_bag]
def main():
with open("multiplication_questions.json", "r", encoding="utf-8") as f:
questions_data = json.load(f)
results = []
for i, item in enumerate(questions_data, start=1):
question = item["question"]
answer = item["answer"]
try:
response, response_time = call_function(question)
if response_time is not None:
results.append({
"Prompt": question,
"Completion": response,
"Answer": answer,
"ResponseTime": response_time
})
print(f"已处理 {i}/{len(questions_data)} 个问题")
except Exception as e:
print(f"处理问题 {question} 时出错: {str(e)}")
# ⚠️⚠️注意百练平台大模型免费的token额度不多,所以如果想用免费的自己跑一跑链路不额外花钱的话,建议生成100条数据
if i>70:
break;
with open("qwq_output.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=4)
if __name__ == '__main__':
main()-
qwq_output.json:70条数据
-
3. 模型训练
在阿里云百炼平台完成以下步骤:
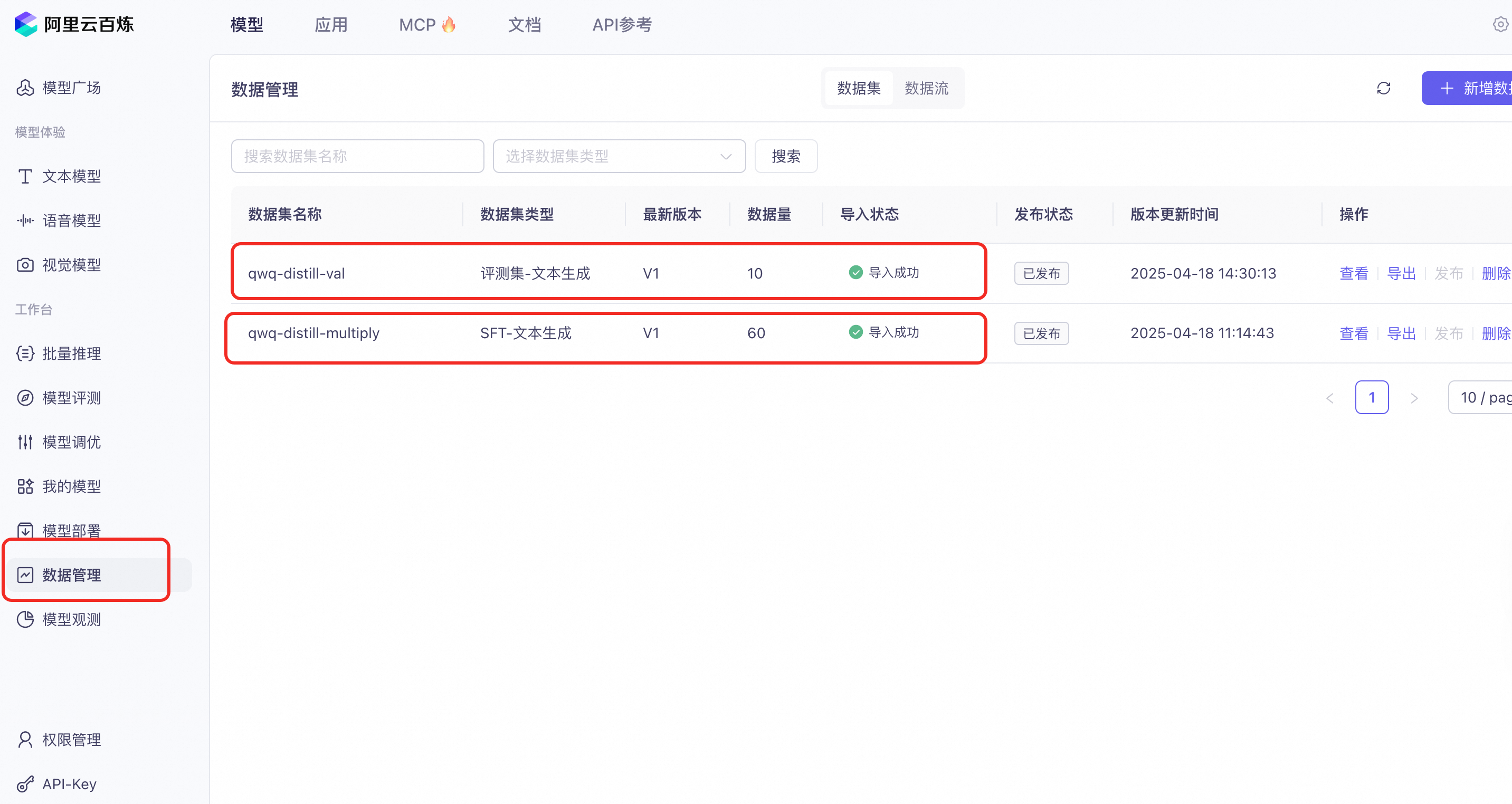
- 上传数据集
将清洗后的JSON数据集qwq_output.json分成两个文件,一个训练用60条,一个测试用10条上传至平台。
- 配置训练参数:
点击模型调优:选择学生模型:Qwen2.5-7B
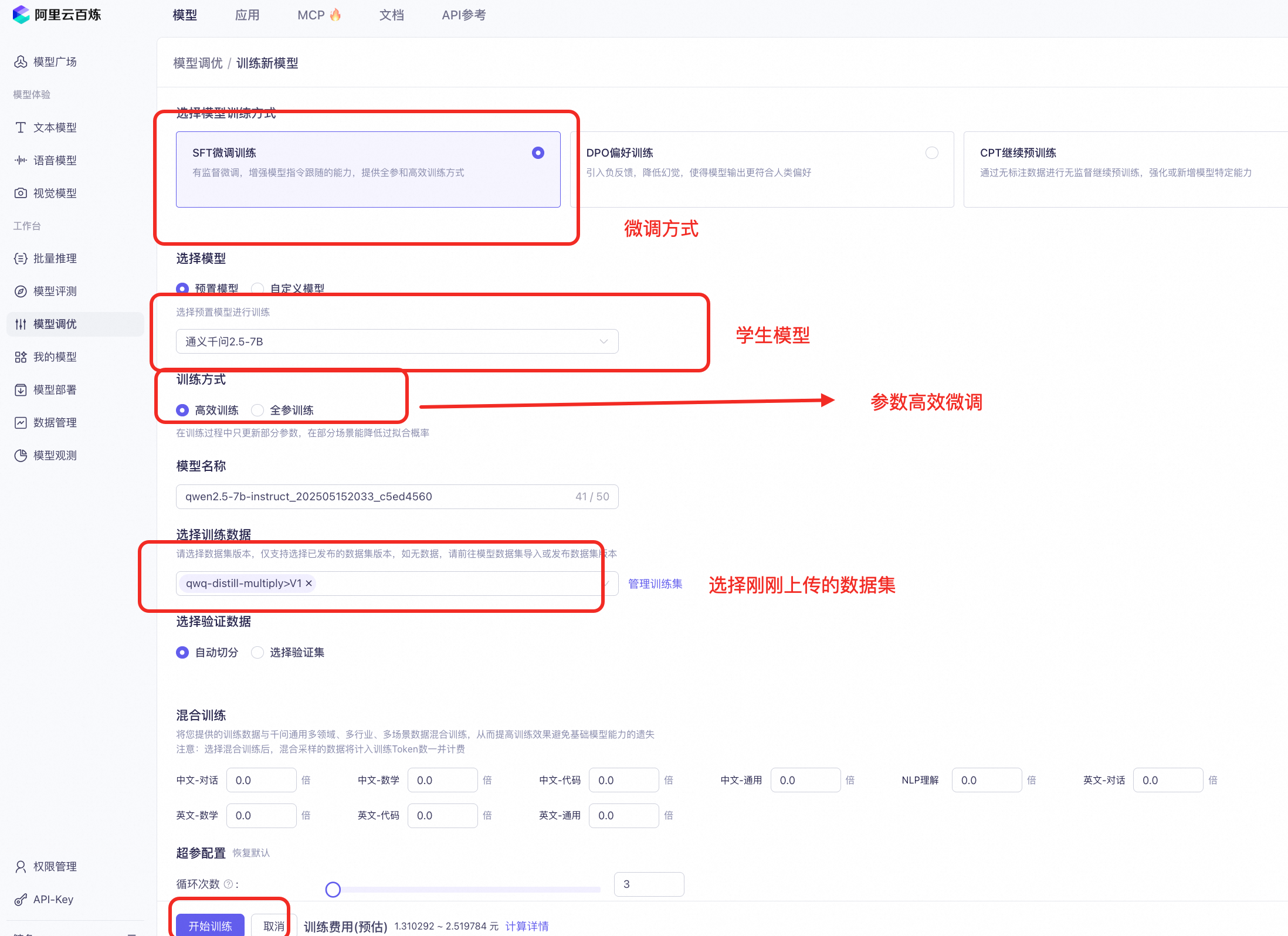
- 启动训练:通过“模型调优”功能启动蒸馏训练,平台自动完成参数调整。
- 训练完成

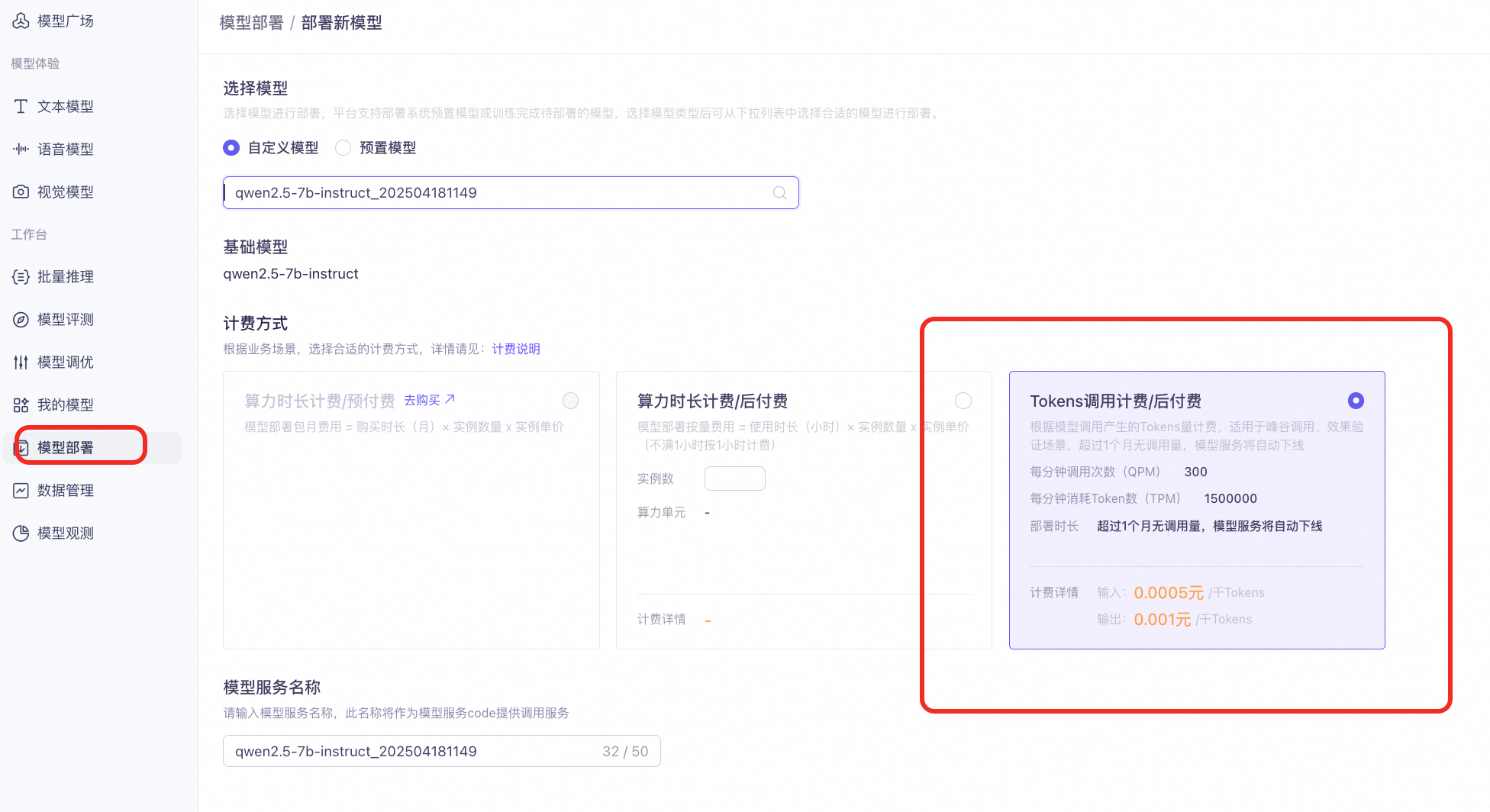
4. 模型部署
模型训练完成后,要部署了才能调用(就像服务端的代码,部署到机器上,接口才能访问的)
-
部署模型:选择“按量计费”模式,将训练好的模型部署为API服务。不要选择其他计费方式
5. 模型测评
-
性能验证:通过SDK调用模型,测试三位数乘法题的准确率,对比蒸馏前后的表现。
有两种方式
-
人工打分,排名
-
一个更厉害的模型对结果进行评价
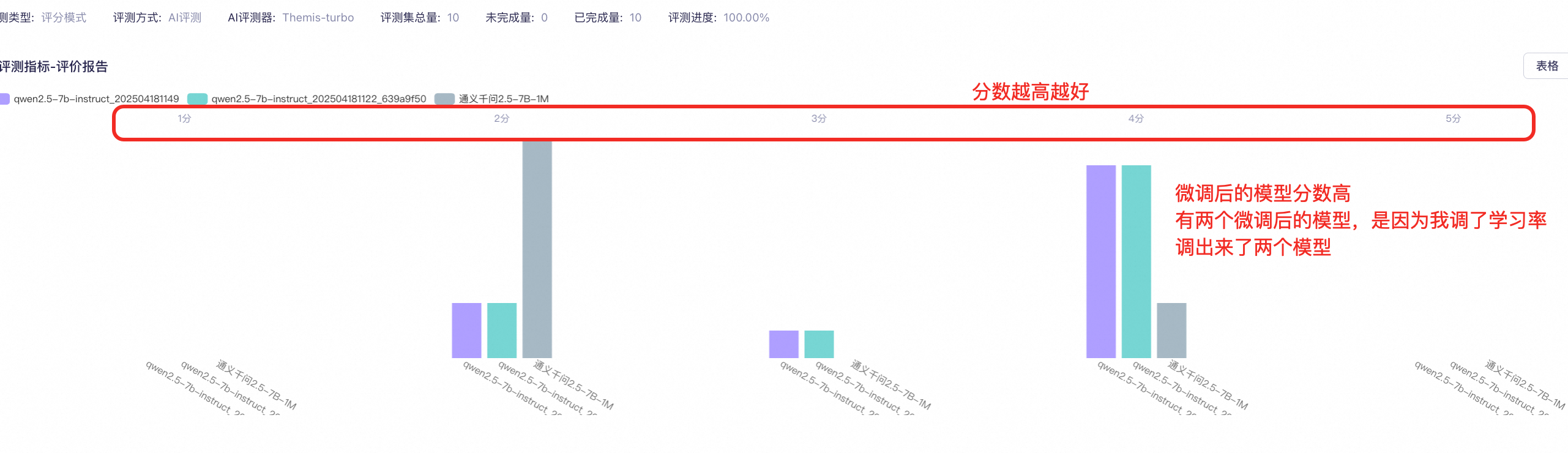
实验结果与分析
关键指标
| 指标 | 原始Qwen2.5 | 蒸馏后Qwen2.5 | 提升幅度 |
| 三位数乘法准确率 | 65% | 98.5% | +51.5% |
关键结论
-
蒸馏效果显著:通过QwQ的教师指导,学生模型在计算任务上的准确率大幅提升。
进一步测试
-
对训练数据中计算错误的项目进行清洗,再训练qwen2.5-7b,得到模型A
-
不用qwq推理类answer训练模型,而是直接用一个正确答案训练,得到模型B
将A、B与原始的qwen2.5B和之前微调后的模型qwen2.5-7b-v1进行比较:
效果:A > qwen2.5-7b-v1 > qwen2.5-7b > B
那么A和qwq相比结果如何呢,其实A会更好,因为A的训练数据干净
结论
-
在部分领域reasoning training是必须的。在三位数乘法的计算中,qwen2.5-7B经过直接生成答案的训练之后准确率反而变低,以及各个大型闭源模型的准确率不如32B的qwq模型,均可以说明直接生成答案的推理方式并不适合解决所有问题。
-
数据质量很重要,数据清洗后再训练准确率可以有很大提升
结论与展望
本实验验证了知识蒸馏在提升小模型垂域能力中的有效性。通过结合教师模型生成的精确标签和数据清洗,Qwen2.5在数学计算任务上的表现接近QwQ的水平。未来可进一步探索以下方向:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









