






一、Transformer结构
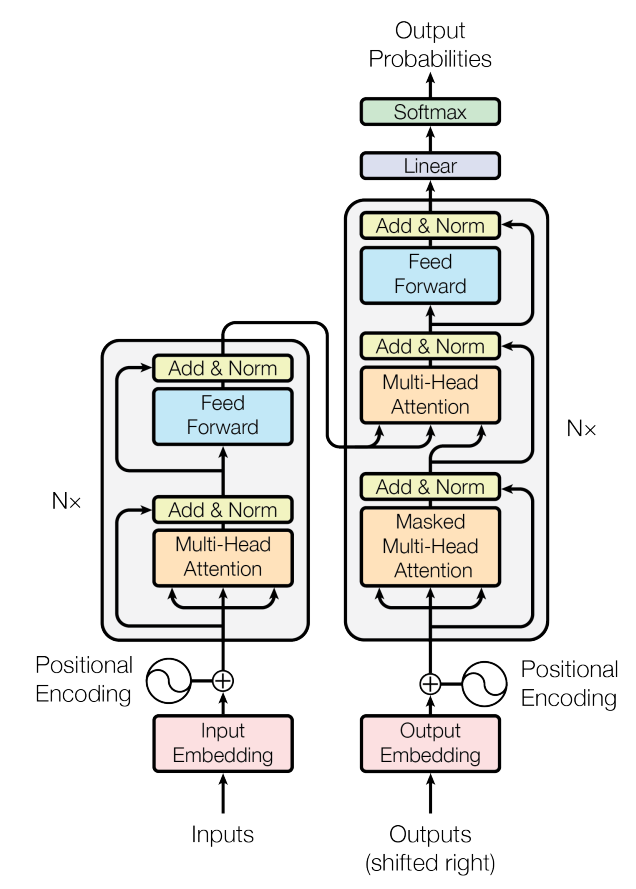
我们都知道,Transformer由编码器和解码器组成,用于序列到序列生成(seq2seq)的机器翻译问题,想必下面这张论文中的原图大家都看过。
但是出于版面的简洁考虑,这幅图只展示了一个encoder块和一个decoder块,那么当有多个encoder块和decoder块的时候,Transformer模型应该如何表述。训练阶段的Transformer和测试阶段的Transformer又有什么区别呢?
二、训练阶段的Transformer结构
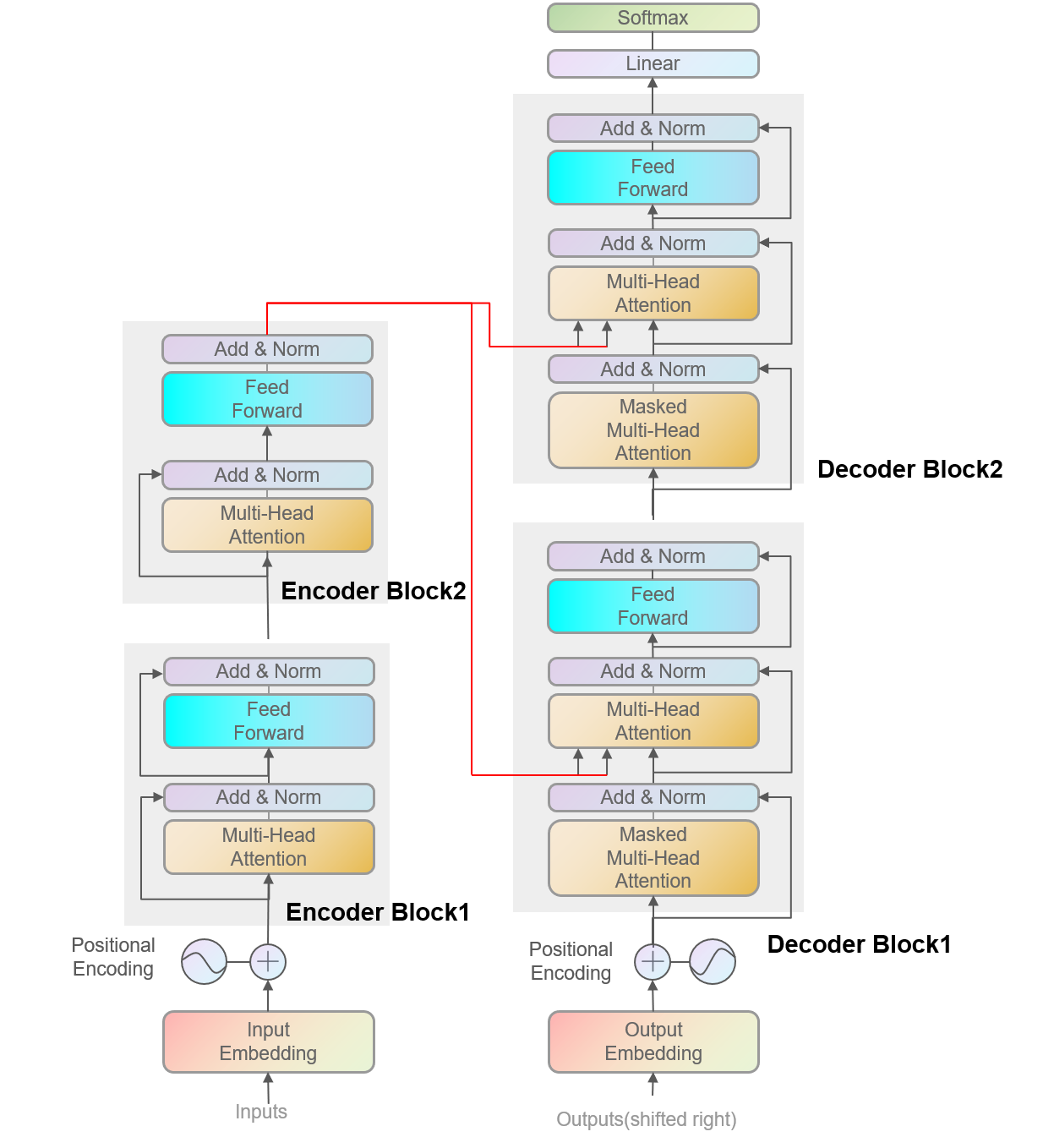
训练阶段的Transformer是比较简单的,需要注意的是编解码器连接的地方,这里用红线表示,编码器的状态会被依次传递给每一个解码器块的第二个注意力机制。作为注意力机制中的键值对。
三、测试阶段的Transformer结构
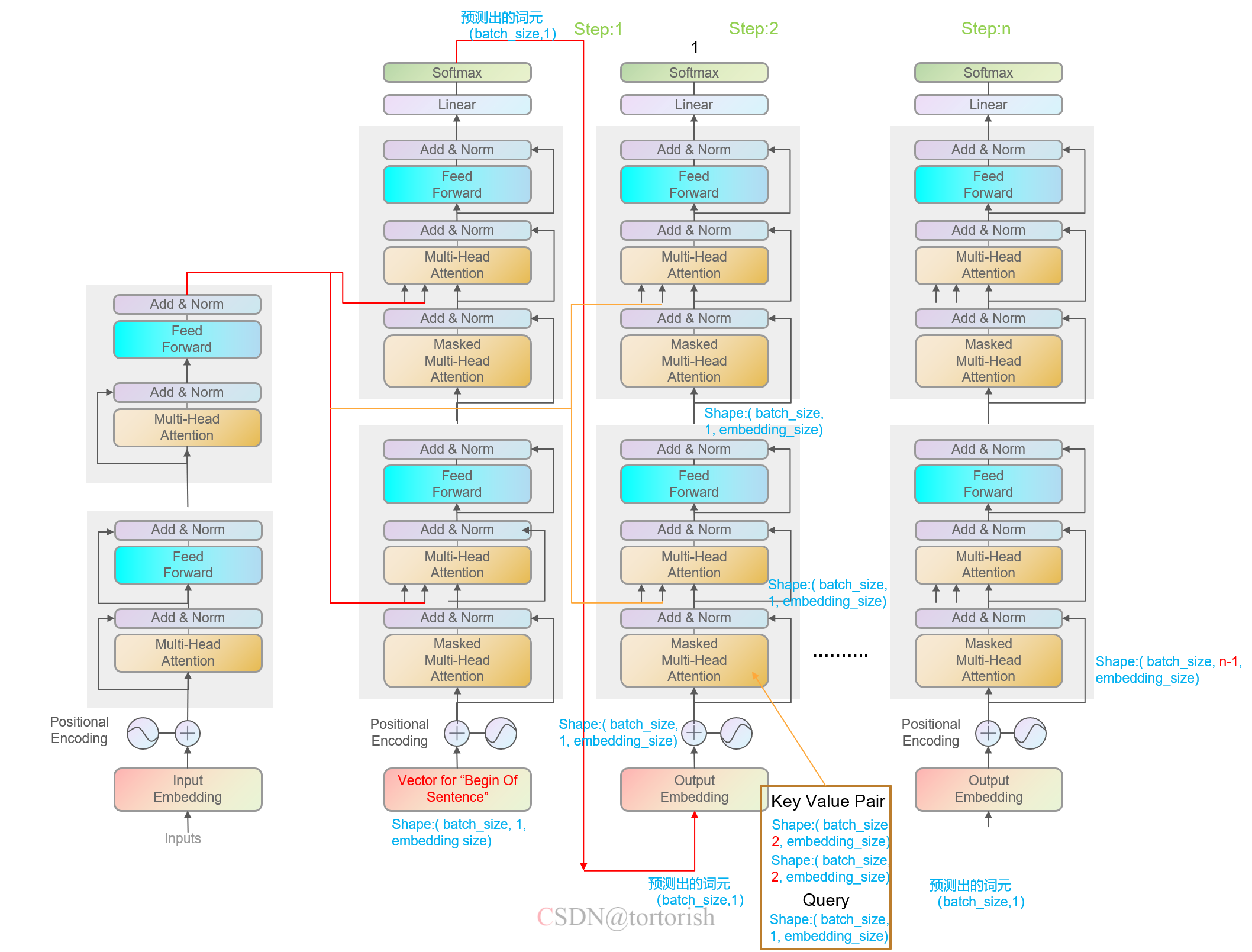
测试阶段的Transformer是较为繁琐的。编码器和训练阶段是一样的,即一次把所有的源语言序列全部输入,然后将输出传递给解码器。
解码器是典型的序列到序列生成模型,即每次生成一个词元。
首先看step1,输入为“BOS”(Begin of Sentence),张量的形状为(batch_size, 1, embedding_size),然后在纵向的方向上进行传递即可。
再来看第二步,step1的输出形状为(batch_size,1),然后传递到step2的底部,其被embedding层重新编码后,传入到第一个decoder块中。被编码后的向量作为注意力机制中的查询(query)。然后,该向量与多头注意力机制上一步(step1)中的向量在时间维度上做拼接,拼接后的向量作为注意力机制中的键值对(key-value pair),其形状为(batch_size, 2, embedding_size)。查询,键值对一起被输入到第一个解码器块的第一个注意力机制模块中,输出的形状是(batch_size, 1, num_hiddens),因为输出的形状是和query的形状相同的。最后在step2的纵向方向上进行传播,得到step2的输出,依次类推,得到整个预测阶段每一个时间步上的词元,将各时间步上的词元进行拼接,便得到了预测出的序列。
有关transformer结构,还可以看这个博主写的文章,写的很好















 8723
8723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









