







 本文深入探讨了共轭梯度法在一般函数形式下的应用,尤其关注非二次型函数带来的挑战。通过对比不同β值公式(如Hesyenes-Stiefel、Polak-Ribiere等),以及步长搜索策略(如非精确方法、划界法),阐述了如何有效迭代求解最小值。同时,提供了Julia代码示例,展示了方法的实现细节。
本文深入探讨了共轭梯度法在一般函数形式下的应用,尤其关注非二次型函数带来的挑战。通过对比不同β值公式(如Hesyenes-Stiefel、Polak-Ribiere等),以及步长搜索策略(如非精确方法、划界法),阐述了如何有效迭代求解最小值。同时,提供了Julia代码示例,展示了方法的实现细节。
共轭梯度法(一般函数形式)
文章目录
一般形式函数对共轭梯度法的挑战
一般形式的函数,黑塞矩阵不一定是个常量,这就必须寻找另外一个办法来迭代计算。当然也可以使用牛顿法进行近似,但是牛顿法到每步迭代都需要再迭代n步来近似,所以计算量还是很大的。
复习一下二次型函数的共轭梯度法
迭代过程**
-
初始条件:
g 1 = H x 1 − b d 1 = r 1 = − g 1 g_1 = Hx_1-b\\ d_1 = r_1 = -g_1 g1=Hx1−bd1=r1=−g1 -
迭代关系
a k = d K T r K d k T H d k x k + 1 = x k + a k d k r k + 1 = r k − a k H d k β k = r k + 1 T H d k d k T H d k d k + 1 = r k + 1 − β k d k a_k = \frac{d^T_Kr_K}{d^T_kHd_k}\\x_{k+1} = x_k + a_kd_k\\r_{k+1} = r_k - a_kHd_k\\\beta_{k} = \frac{r_{k+1}^THd_{k}}{d^T_{k}Hd_{k}}\\d_{k+1} = r_{k+1} - \beta_kd_k ak=dkTHdkdKTrKxk+1=xk+akdkrk+1=rk−akHdkβk=dkTHdkrk+1THdkdk+1=rk+1−βkdk
黑塞矩阵H在非二次型函数中是一个n*n的每个元素都是一个关于自变量 X X X的函数的矩阵,所以计算量是很大的,特别是当函数是个多元函数的时候
所以我们既想要保留共轭梯度法的优势,有想要尽量避免H的计算
由上面的迭代关系可以看到,H的计算主要是在 a k 和 β k a_k和\beta_k ak和βk的计算中,所以我们现在需要的就是变形这两个公式,来近似原本的迭代过程。( r k + 1 r_{k+1} rk+1这边没写是因为 r k + 1 r_{k+1} rk+1可以变形成 − g k + 1 -g_{k+1} −gk+1)
步长 a k a_k ak的变形
步长的迭代其实就是找到该搜索方向下降速度最快的步长,(该方向的极小值),我们可以使用一维搜索算法,如果希望得到精确结果,可以使用牛顿法(一维的牛顿法H是常量矩阵),但是计算量比较大;也可以使用非精确的搜搜,例如划界法,黄金分割法等等…
β k \beta_k βk的变形
β k \beta_k βk的变形存在许多数学家提出的变形公式,不同的公式对不同的目标函数可能有不同的效果,我们在之后的代码中会进行比较
Hesyenes-Stiefel公式
我们知道
β
k
\beta_k
βk的迭代公式是这样的
β
k
=
r
k
+
1
T
H
d
k
d
k
T
H
d
k
\beta_{k} = \frac{r_{k+1}^THd_{k}}{d^T_{k}Hd_{k}}
βk=dkTHdkrk+1THdk
该方法选择使用一下公式来近似
H
d
k
Hd_k
Hdk
H
d
k
=
g
k
+
1
−
g
k
a
k
Hd_k = \frac{g_{k+1}-g_k}{a_k}
Hdk=akgk+1−gk
于是原本的公式就变形称为了
β
k
=
−
g
k
+
1
T
(
g
k
+
1
−
g
k
)
d
k
T
(
g
k
+
1
−
g
k
)
\beta_{k} = -\frac{g_{k+1}^T(g_{k+1}-g_k)}{d^T_{k}(g_{k+1}-g_k)}
βk=−dkT(gk+1−gk)gk+1T(gk+1−gk)
Polak-Ribiere 公式
是在上一个公式的基础上进一步变形,这里不详细说了
β
k
=
−
g
k
+
1
T
(
g
k
+
1
−
g
k
)
d
k
T
(
g
k
+
1
−
g
k
)
=
−
g
k
+
1
T
(
g
k
+
1
−
g
k
)
d
k
T
g
k
+
1
−
d
k
T
g
k
=
g
k
+
1
T
(
g
k
+
1
−
g
k
)
d
k
T
g
k
\beta_{k} = -\frac{g_{k+1}^T(g_{k+1}-g_k)}{d^T_{k}(g_{k+1}-g_k)}=-\frac{g_{k+1}^T(g_{k+1}-g_k)}{d^T_{k}g_{k+1}-d^T_{k}g_k}= \frac{g_{k+1}^T(g_{k+1}-g_k)}{d^T_{k}g_k}
βk=−dkT(gk+1−gk)gk+1T(gk+1−gk)=−dkTgk+1−dkTgkgk+1T(gk+1−gk)=dkTgkgk+1T(gk+1−gk)
这里的变形用到了共轭梯度法的性质:当前点的梯度方向与之前所有点的搜索方向都正交
d
k
=
r
k
−
β
k
−
1
d
k
−
1
=
−
g
k
−
β
k
−
1
d
k
−
1
g
k
T
d
k
=
−
g
k
T
g
k
−
β
k
−
1
g
k
T
d
k
−
1
=
−
g
k
T
g
k
β
k
=
g
k
+
1
T
(
g
k
−
g
k
+
1
)
g
k
T
g
k
d_k = r_k - \beta_{k-1}d_{k-1}=-g_k - \beta_{k-1}d_{k-1}\\ g_k^Td_k =-g_k^Tg_k - \beta_{k-1}g_k^Td_{k-1}=-g_k^Tg_k\\ \beta_k = \frac{g_{k+1}^T(g_{k}-g_{k+1})}{g_k^Tg_k}
dk=rk−βk−1dk−1=−gk−βk−1dk−1gkTdk=−gkTgk−βk−1gkTdk−1=−gkTgkβk=gkTgkgk+1T(gk−gk+1)
Fletcher-Reeves公式
β k = − g k + 1 T g k + 1 g k T g k \beta_k = -\frac{g^T_{k+1}g_{k+1}}{g^T_kg_k} βk=−gkTgkgk+1Tgk+1
可以看出明显也是从上面的改进而来的。
Dai-Yuan公式
β k = − g k T g k d k − 1 T ( g k − g k − 1 ) \beta_k = -\frac{g^T_kg_k}{d^T_{k-1}(g_k-g_{k-1})} βk=−dk−1T(gk−gk−1)gkTgk
Powell公式
β k = m a x { 0 , g k + 1 T ( g k − g k + 1 ) g k T g k } \beta_k = max\lbrace0, \frac{g_{k+1}^T(g_{k}-g_{k+1})}{g_k^Tg_k}\rbrace βk=max{0,gkTgkgk+1T(gk−gk+1)}
重置搜索方向
这里还有一个问题,对于二次型函数共轭函数可以在n步之内达到极小值,但是对于非二次型的函数,由于我们采用的是近似的方法,并不能保证在n步之内就达到最小值,但是n元的目标函数最多只能构建n个互相线性独立的共轭防线,所以我们需要
将n次或者n次以后的搜索方向重置为梯度负方向
迭代过程
-
初始条件
g 1 = g ( x 0 ) d 1 = − g 1 g_1 = g(x0) \\d_1 = -g1 g1=g(x0)d1=−g1 -
迭代
α k = s e a c h − a l p h a ( . . . ) x k + 1 = x k + α k d k β k = 选 择 一 种 公 式 d k + 1 = − g k + 1 − β k d k \alpha_k = seach-alpha(...) \\x_{k+1} = x_k + \alpha_kd_k \\\beta_k = 选择一种公式 \\d_{k+1} = -g_{k+1}-\beta_kd_k αk=seach−alpha(...)xk+1=xk+αkdkβk=选择一种公式dk+1=−gk+1−βkdk
代码示例
using LinearAlgebra
using Gadfly
## 非精确方法
function inexact_alpha(f,g,xk,fk,gk,d;
α0 =1,ϵ=0.1,τ =0.5,
η = 0.5,ζ=2.0)
α = α0
Φ0 = d' * gk
δ = α .* d
xn = xk .+ δ
fn = f(xn...)
gn = g(xn...)
# Armijo 不太大条件
while fn > fk + ϵ*α*Φ0
α = τ * α
δ = α .* d
xn = xk .+ δ
fn = f(xn...)
gn = g(xn...)
end
# Wolfe 不太小条件
while d' *gn < η * Φ0
α = ζ*α
δ = α .* d
xn = xk .+ δ
fn = f(xn...)
gn = g(xn...)
end
return α,δ,xn,fn,gn
end
## TODO 划界法搜索步长
function aecant_alpha(f,g,xk,fk,gk,d;α0=1,accuracy=0.001,maxIter = 128)
# _l是当前点,k-1
# _u是下一个点,k
αl = α0
αu = α0*1.1
xl = xk .+ αl .* d
xu = xk .+ αu .* d
gl = g(xl...)
gu = g(xu...)
Φl = d' * gl
Φu = d' * gu
for i in 1:maxIter
Δ = Φu - Φl
# 防止出现分母为0的数学错误
if Δ == 0.0
println("error:出现分母为0的数学错误")
return αu,αu.*d,xu,f(xu...),gu
else
Δ = Φu * (αu - αl)/ Δ
end
if abs(Δ) <= accuracy
return αu,αu.*d,xu,f(xu...),gu
end
αl = αu
xl = xu
gl = gu
Φl = Φu
αu = αu - Δ
xu = xk .+ αu .* d
gu = g(xu...)
Φu = d' * gu
end
return αu,αu.*d,xu,f(xu...),gu
end
# β值公式函数,可供选择
function Hestence_Stiefel(d,gk,gn)
return -1 * (gn' * (gn .- gk))/(d' * (gn .- gk))
end
function Polak_Ribiere(d,gk,gn)
return (gn' * (gk .- gn)) / (gk' * gk)
end
function Fletcher_Reeves(d,gk,gn)
return -1 * (gn' * gn) / (gk' * gk)
end
function Dai_Yuan(d,gk,gn)
return -1 * (gn' * gn) /(d' * (gn .- gk))
end
function Powell(d,gk,gn)
return max(0,(gn' * (gn .- gk)/(d' * (gn .- gk))))
end
function ConjugateGradient(f,
g,
x0;
fβ = Hestence_Stiefel,
fα = seach_alpha, ##定义搜索步长的方法
accuracy = 0.001,
#accurary_α = 0.001, #用来搜寻α的精度
accuracy_x = accuracy,
accurary_f = accuracy,
accurary_g = accuracy,
convergence_rule = x -> reduce(&,x),
convergence_abs = true,
iterations = 256,
plotStep = false,
debug = false)
n = length(x0)
xk = x0
fk = f(xk...)
gk = g(xk...)
d = -gk
## 输出的列表用来画图
pts = []
push!(pts,xk)
#从0开始是因为第一次和第n次要重置共轭方向
for i in 0:iterations
# δ是 xn .- xk的结果
α,δ,xn,fn,gn = fα(f,g,xk,fk,gk,d)
# 第一次迭代和第n次迭代重置搜索方向
if mod(i,n) == 0
β = 0
else
β = fβ(d,gk,gn)
end
# 判断收敛
conditions = [norm(δ),abs(fn-fk),norm(gn)]
denominator = [max(1,norm(xk)),max(1,fk),1]
if !convergence_abs
conditions = conditions ./ denominator
end
if convergence_rule(conditions .< [accuracy_x,accurary_f,accurary_g])
println("-------------------达到迭代条件,结束迭代-----------------")
println("迭代步数:",i+1) ##因为迭代从i=0开始
println("最后一步x差值的模长:",norm(δ))
println("最后一步g的模长:",norm(gn))
println("最后一步的f差值:",abs(fn-fk))
return xn,fn,gn,pts
end
d = -gn .- β*d
xk = xn
fk = fn
gk = gn
## 如果需要绘画出迭代过程
if plotStep
push!(pts,xk)
end
if debug
println(i,"\tx:",xn,"\tf:",fn,"\ng:",gn,"\tα:",α,"\tδ:",δ,"\tnorm(δ):",norm(δ))
end
end
println("-------------------达到最大迭代步数,结束迭代-----------------")
return xn,fn,gn,pts
end
# 测试用例
x,f,g,pts = ConjugateGradient((x1, x2) -> 2.5*x1^2 + 0.5*x2^2 +2*x1*x2-3*x1-x2,
(x1, x2) -> [5*x1+2*x2-3,
x2+2*x1-1],
[100,100],
plotStep=true,
debug = true,fα = inexact_alpha)
# 画图
n = length(pts)
rosen = layer((x1, x2) -> 2.5*x1^2 + 0.5*x2^2 +2*x1*x2-3*x1-x2,-100.0,100.0,-100.0,100.0,Geom.contour())
steps = layer(
## convert()函数将数据转化成了浮点型,这样子才不会报错
## 最后一点不作为起点
x = convert(Vector{Float64},[pts[i][1] for i in 1:n-1]),
y = convert(Vector{Float64},[pts[i][2] for i in 1:n-1]),
## 第一点不作为终点
xend = convert(Vector{Float64},[pts[i][1] for i in 2:n]),
yend = convert(Vector{Float64},[pts[i][2] for i in 2:n]),
Geom.point,Geom.vector(filled = true))
plot(rosen,steps,Scale.x_continuous(minvalue = low,maxvalue = up),
Scale.y_continuous(maxvalue=up,minvalue=low))
# # 比较多种方法之间的差异
# map(b ->
# map(a -> println("\n",a,"\t",b,"\t",
# ConjugateGradient((x1,x2) -> 2.5*x1^2 + 0.5*x2^2 +2*x1*x2-3*x1-x2,
# (x1, x2) -> [5*x1+2*x2-3,
# x2+2*x1-1],
# [0,0],
# fβ = b,
# fα = a,
# accuracy = 0.01,
# debug = false),"\n\n"),
# [seach_alpha, inexact_alpha]),
# [Hestence_Stiefel,Polak_Ribiere,Fletcher_Reeves,Powell,Dai_Yuan])
调用函数
using LinearAlgebra
using Gadfly
定义搜索步长的函数
## 非精确方法
function inexact_alpha(f,g,xk,fk,gk,d;
α0 =1,ϵ=0.1,τ =0.5,
η = 0.5,ζ=2.0)
α = α0
Φ0 = d' * gk
δ = α .* d
xn = xk .+ δ
fn = f(xn...)
gn = g(xn...)
# Armijo 不太大条件
while fn > fk + ϵ*α*Φ0
α = τ * α
δ = α .* d
xn = xk .+ δ
fn = f(xn...)
gn = g(xn...)
end
# Wolfe 不太小条件
while d' *gn < η * Φ0
α = ζ*α
δ = α .* d
xn = xk .+ δ
fn = f(xn...)
gn = g(xn...)
end
return α,δ,xn,fn,gn
end
##划界法搜索步长
function aecant_alpha(f,g,xk,fk,gk,d;α0=1,accuracy=0.001,maxIter = 128)
# _l是当前点,k-1
# _u是下一个点,k
αl = α0
αu = α0*1.1
xl = xk .+ αl .* d
xu = xk .+ αu .* d
gl = g(xl...)
gu = g(xu...)
Φl = d' * gl
Φu = d' * gu
for i in 1:maxIter
Δ = Φu - Φl
# 防止出现分母为0的数学错误
if Δ == 0.0
println("error:出现分母为0的数学错误")
return αu,αu.*d,xu,f(xu...),gu
else
Δ = Φu * (αu - αl)/ Δ
end
if abs(Δ) <= accuracy
return αu,αu.*d,xu,f(xu...),gu
end
αl = αu
xl = xu
gl = gu
Φl = Φu
αu = αu - Δ
xu = xk .+ αu .* d
gu = g(xu...)
Φu = d' * gu
end
return αu,αu.*d,xu,f(xu...),gu
end
函数提供了非精确搜索和划界法两种方法来线性搜索步长
关于非精确搜索和划界法可以查看一下这个视频
构建搜索 β \beta β 的函数
# β值公式函数,可供选择
function Hestence_Stiefel(d,gk,gn)
return -1 * (gn' * (gn .- gk))/(d' * (gn .- gk))
end
function Polak_Ribiere(d,gk,gn)
return (gn' * (gk .- gn)) / (gk' * gk)
end
function Fletcher_Reeves(d,gk,gn)
return -1 * (gn' * gn) / (gk' * gk)
end
function Dai_Yuan(d,gk,gn)
return -1 * (gn' * gn) /(d' * (gn .- gk))
end
function Powell(d,gk,gn)
return max(0,(gn' * (gn .- gk)/(d' * (gn .- gk))))
end
这里提供了我们上面学习到的全部 β \beta β变形公式,可以根据自己的需要选择,下面我们也会提供函数对这几个公式的性能进行比较。
构造函数接口
function ConjugateGradient(f,
g,
x0;
fβ = Hestence_Stiefel,
fα = seach_alpha, ##定义搜索步长的方法
accuracy = 0.001,
#accurary_α = 0.001, #用来搜寻α的精度
accuracy_x = accuracy,
accurary_f = accuracy,
accurary_g = accuracy,
# 用来定义结束迭代阈值的方法,
# x -> x[3],表示用accurary_g作为条件结束迭代
# x -> reduce(&,x),表示三个都要满足
# x -> reduce(|,x),表示只要满足其中一个
convergence_rule = x -> reduce(&,x),
convergence_abs = true,
iterations = 256,
plotStep = true,
debug = false)
end
每n次迭代重置一次搜索方向
我们知道在对于n元的函数最多只能有n个共轭方向,但是我们并不一定能在n次迭代中完成寻找最小值的迭代,所以每逢n次迭代我们就需要重置一下搜索方向。
if mod(i,n) == 0
β = 0
else
β = fβ(d,gk,gn)
end
mod函数是取模,和取余有点相似,只有当i是0或者n的倍数的时候,mod(i,n)才会等于0
判断收敛
# 判断收敛
conditions = [norm(δ),abs(fn-fk),norm(gn)]
denominator = [max(1,norm(xk)),max(1,fk),1]
if !convergence_abs
conditions = conditions ./ denominator
end
if convergence_rule(conditions .< [accuracy_x,accurary_f,accurary_g])
println("-------------------达到迭代条件,结束迭代-----------------")
println("迭代步数:",i+1) ##因为迭代从i=0开始
println("最后一步x差值的模长:",norm(δ))
println("最后一步g的模长:",norm(gn))
println("最后一步的f差值:",abs(fn-fk))
return xn,fn,gn,pts
end
这里convergence_abs是选择绝对收敛和相对收敛的参数,可以根据自己的需要进行选择。有时候使用绝对收敛条件的效果并不是很好,我们就可以选择相对收敛条件。
比较多个方法之间的差异
map(b ->
map(a -> println("\n",a,"\t",b,"\t",
ConjugateGradient((x1,x2) -> 2.5*x1^2 + 0.5*x2^2 +2*x1*x2-3*x1-x2,
(x1, x2) -> [5*x1+2*x2-3,
x2+2*x1-1],
[0,0],
fβ = b,
fα = a,
accuracy = 0.01,
debug = false),"\n\n"),
[seach_alpha, inexact_alpha]),
[Hestence_Stiefel,Polak_Ribiere,Fletcher_Reeves,Powell,Dai_Yuan])
map()函数是用来组合多个函数的效果,例如:
map(x -> x^2,[3,4,5])
## 结果:[9,16,25]
map(x -> map(y -> x+y,[2,3]),[3,5])
##结果:[5,6][7,8]
-------------------达到迭代条件,结束迭代-----------------
迭代步数:14
最后一步x差值的模长:0.0030420392224767886
最后一步g的模长:0.005562147029090805
最后一步的f差值:1.0047870551255222e-5seach_alpha Hestence_Stiefel ([0.999118440357853, -1.0003654682602674], -0.9999973459838314, [-0.
-------------------达到迭代条件,结束迭代-----------------
迭代步数:14
最后一步x差值的模长:0.0030420392224767886
最后一步g的模长:0.005562147029090805
最后一步的f差值:1.0047870551255222e-5inexact_alpha Hestence_Stiefel ([0.999118440357853, -1.0003654682602674], -0.9999973459838314, [-0.
-------------------达到迭代条件,结束迭代-----------------
迭代步数:40
最后一步x差值的模长:0.003228212139500723
最后一步g的模长:0.007127315086803913
最后一步的f差值:1.5304993490783403e-5seach_alpha Polak_Ribiere ([0.9907284387629632, -0.9751557156334197], -0.9999371667555162, [0.00333076
-------------------达到迭代条件,结束迭代-----------------
迭代步数:40
最后一步x差值的模长:0.003228212139500723
最后一步g的模长:0.007127315086803913
最后一步的f差值:1.5304993490783403e-5inexact_alpha Polak_Ribiere ([0.9907284387629632, -0.9751557156334197], -0.9999371667555162, [0.00333076
-------------------达到迭代条件,结束迭代-----------------
迭代步数:14
最后一步x差值的模长:0.00503044661683969
最后一步g的模长:0.00979124983859048
最后一步的f差值:3.0293491641519843e-5seach_alpha Fletcher_Reeves ([0.990048831814127, -0.9800175405374091], -0.9999504839160135, [-0.00979092
-------------------达到迭代条件,结束迭代-----------------
迭代步数:14
最后一步x差值的模长:0.00503044661683969
最后一步g的模长:0.00979124983859048
最后一步的f差值:3.0293491641519843e-5inexact_alpha Fletcher_Reeves ([0.990048831814127, -0.9800175405374091], -0.9999504839160135, [-0.00979092
-------------------达到迭代条件,结束迭代-----------------
迭代步数:67
最后一步x差值的模长:0.0033054909578306693
最后一步g的模长:0.009896610447074796
最后一步的f差值:4.319662391782941e-6seach_alpha Powell ([0.9805380034157036, -0.9553978185618385], -0.9997944944334644, [-0.008105620045158
-------------------达到迭代条件,结束迭代-----------------
迭代步数:67
最后一步x差值的模长:0.0033054909578306693
最后一步g的模长:0.009896610447074796
最后一步的f差值:4.319662391782941e-6inexact_alpha Powell ([0.9805380034157036, -0.9553978185618385], -0.9997944944334644, [-0.008105620045158
-------------------达到迭代条件,结束迭代-----------------
迭代步数:17
最后一步x差值的模长:0.004073036874444339
最后一步的f差值:1.839296890449038e-5seach_alpha Dai_Yuan ([0.9907792986521452, -0.9748192338314118], -0.999934779823317, [0.004258025
最后一步的f差值:1.839296890449038e-5
inexact_alpha Dai_Yuan ([0.9907792986521452, -0.9748192338314118], -0.999934779823317, [0.004258025597902559, 0.006739363472878512], Any[[0, 0]])
测试并绘图
# 测试用例
x,f,g,pts = ConjugateGradient((x1, x2) -> 2.5*x1^2 + 0.5*x2^2 +2*x1*x2-3*x1-x2,
(x1, x2) -> [5*x1+2*x2-3,
x2+2*x1-1],
[100,100],
plotStep=true,
debug = true,fα = inexact_alpha)
# 画图
n = length(pts)
rosen = layer((x1, x2) -> 2.5*x1^2 + 0.5*x2^2 +2*x1*x2-3*x1-x2,-100.0,100.0,-100.0,100.0,Geom.contour())
steps = layer(
## convert()函数将数据转化成了浮点型,这样子才不会报错
## 最后一点不作为起点
x = convert(Vector{Float64},[pts[i][1] for i in 1:n-1]),
y = convert(Vector{Float64},[pts[i][2] for i in 1:n-1]),
## 第一点不作为终点
xend = convert(Vector{Float64},[pts[i][1] for i in 2:n]),
yend = convert(Vector{Float64},[pts[i][2] for i in 2:n]),
Geom.point,Geom.vector(filled = true))
plot(rosen,steps,Scale.x_continuous(minvalue = low,maxvalue = up),
Scale.y_continuous(maxvalue=up,minvalue=low))
结果:
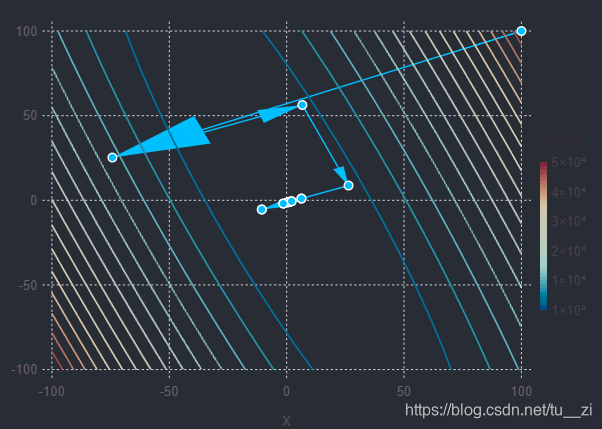
可以看出来共轭梯度法的效果还是很好的,相比较于梯度下降法。
声明
这个博客是博主根据博主的老师上传的视频整理得到的,仅供参考和学习,也欢迎大家和我交流讨论。

















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









