







1.代码源
国内镜像站在gitcode。这个镜像站也基本上包含了github上常用项目的镜像。然后它的主发布源在这里:
yolov10是清华主导做的...
然后,在维护列表里看到了这个:
- 2024年05月31日:感谢kaylorchen整合rk3588!
2.三方性能评价

kaylorchen的yolov8 yolov10在3588平台的自测数据在这里(单位ms):
| V8l-2.0.0 | V8l-1.6.0 | V10l-2.0.0 | V10l-1.6.0 |
|---|---|---|---|
| 133.07572815534 | 133.834951456311 | 122.992233009709 | 204.471844660194 |
| V8n-2.0.0 | V8n-1.6.0 | V10n-2.0.0 | V10n-1.6.0 |
|---|---|---|---|
| 17.8990291262136 | 18.3300970873786 | 21.3009708737864 | 49.9883495145631 |
从FLOPs的数据看,相应的-l和-n的识别时间近似与yolov10公布的性能参数对照表保持一致。
3.实测(处理中...)
看到官方公布的模型特征,我最终选取的应该不是-n而是-s,实际部署时还会考虑-m
3.1 环境的建立
试过了yolov10, yolov10注释中提到的:3588 v10,编译不过。现在测试一下:
https://github.com/kaylorchen/rk3588-yolo-demo
3.1.1安装docker
https://support.huawei.com/enterprise/zh/doc/EDOC1100372015/cd7a15db
curl -fsSL https://repo.huaweicloud.com/docker-ce/linux/debian/gpg | sudo apt-key add - apt-get update apt-get install -y docker-cedocker pull kaylor/rk3588_pt2onnx #这一步还没走通,
3.2 配置
<缺>
3.3 模型训练
3.3.1 预训练模型 .pt格式
然后coco训练集的完备的模型(pytorch .pt格式)下载位置在:
Release v8.2.0 - YOLOv8-World and YOLOv9-C/E Models · ultralytics/assets · GitHub
这里可以找到yolov3,v5,v8,v10的预训练模型。
3.3.1 预训练模型 .rknn格式
测试期间直接取了kaylorchen的模型 百度网盘 请输入提取码 Password: gmcs
3.3.3 自训练
3.3.3.1 注意事项
当前常用的yolo模型,基本上都是v8系列,rknn的模型转换不仅与rk3588 - RKNN Toolkit关联的模型转换提示,还与yolo一侧的training 以及export方案有关:
Ultralytics YOLOv8 Modes - Ultralytics YOLO Docs
这里包含一些训练和发布的指导意见。这里是一位网友自己做的模型转换环境和步骤清单:
rk3588's yolov8 model conversion from pt to rknn | Memories
3.3.3.2 实操
.pt与.onnx的转换可以使用yolov8自己的命令行工具进行:
root@debian-ai:/home/model#yolo export model=yolov10s.pt format=onnx opset=12 simplify
Ultralytics YOLOv8.1.34 🚀 Python-3.10.0 torch-2.0.1+cu117 CPU (12th Gen Intel Core(TM) i5-12400)
YOLOv10s summary (fused): 293 layers, 8096880 parameters, 0 gradients, 24.8 GFLOPs
platform = rk3588
platform = rk3588PyTorch: starting from 'yolov10s.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s) ((1, 64, 80, 80), (1, 80, 80, 80), (1, 1, 80, 80), (1, 64, 40, 40), (1, 80, 40, 40), (1, 1, 40, 40), (1, 64, 20, 20), (1, 80, 20, 20), (1, 1, 20, 20)) (31.4 MB)
ONNX: starting export with onnx 1.14.0 opset 12...
platform = rk3588
============= Diagnostic Run torch.onnx.export version 2.0.1+cu117 =============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================ONNX: simplifying with onnxsim 0.4.36...
ONNX: export success ✅ 2.2s, saved as 'yolov10s.onnx' (27.7 MB)Export complete (5.4s)
Results saved to /home/model
Predict: yolo predict task=detect model=yolov10s.onnx imgsz=640
Validate: yolo val task=detect model=yolov10s.onnx imgsz=640 data=coco.yaml
Visualize: https://netron.app
💡 Learn more at https://docs.ultralytics.com/modes/export
然后是.onnx到rknn的模型转换:
3.4 部署
yolov10其实是yolov8的改进版,在rk3588平台部署时,直接使用yolov8的外围结果析取代码就可以。参见附录B
3.5 实测数据
3.5.1 预训练模型的实测数据
单位是s,也就是平均25ms一帧,不含后续的post_procedure。
相应的model文件取自3.3.1那里下载的model - yolov10.2.0.0
运行环境:rk3588 npu(只激活一个核)运行的结果:
diff 0.03168988227844238
diff 0.025350093841552734
diff 0.0268709659576416
diff 0.02390575408935547
diff 0.024686574935913086
这里有个奇怪的知识:
1. rknn自己提供的各种针对模型的分析,比如内存分析,效能分析,无法在rknn.lite平台,也就是最终的部署平台上进行,因为rknn.lite的api压根就没有这些性能分析工具。
2.rknn的性能分析工具无法靠直接加载 .rknn运行:
I rknn-toolkit2 version: 2.0.0b15+2edec668
E init_runtime: RKNN model that loaded by 'load_rknn' not support inference on the simulator, please set 'target' first!
If you really want to inference on the simulator, use 'load_xxx' & 'build' instead of 'load_rknn'!
E accuracy_analysis: Please load & build model first!
E eval_perf: The runtime has not been initialized, please call init_runtime first!
你必须先加载标准模型,然后在转换完成后,进行性能分析。
附录A epochs对模型识别精度的影响
这张图参见:
简述YOLOv8与YOLOv5的区别_yolov8和yolov5对比-CSDN博客
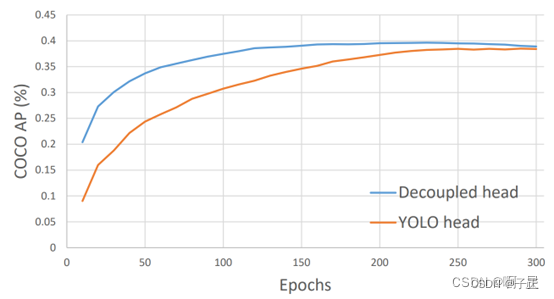
我因为在i5-12400上跑的实在是太慢,然后做实验时往往跑了两遍就结束了。看起来之后训练的遍数还得定在200~250次。普通的I5芯片,COCO数据集需要跑4~5天才能跑完。
看上面的数据点:训练集跑10遍,达到的识别精度大概是最终可能精度的25%...它在逐渐收敛。在蓝色的优化方法的末端,你能看到那个以为过度训练造成的识别精度下降的现象。机器学习的识别过程类似一个反馈环,识别效果出现震荡是正常的。
附录B yolov10 - rk3588平台的适配代码
这里的主入口是:processImage,第二个参数是rknn针对图片的计算输出.这里的代码已经验证,可用。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# 获取当前脚本文件所在目录的父目录,并构建相对路径
import os
import sys
current_dir = os.path.dirname(os.path.abspath(__file__))
project_path = os.path.join(current_dir, '..')
sys.path.append(project_path)
sys.path.append(current_dir)
import urllib
import time
import sys
import numpy as np
import cv2
from rknnlite.api import RKNNLite
import cat4Config
OBJ_THRESH = 0.25
NMS_THRESH = 0.45
# The follew two param is for map test
# OBJ_THRESH = 0.001
# NMS_THRESH = 0.65
IMG_SIZE = (640, 640) # (width, height), such as (1280, 736)
target = "rk3588"
img_path = "./model/bus.jpg"
CLASSES = ("person", "bicycle", "car","motorbike ","aeroplane ","bus ","train","truck ","boat","traffic light",
"fire hydrant","stop sign ","parking meter","bench","bird","cat","dog ","horse ","sheep","cow","elephant",
"bear","zebra ","giraffe","backpack","umbrella","handbag","tie","suitcase","frisbee","skis","snowboard","sports ball","kite",
"baseball bat","baseball glove","skateboard","surfboard","tennis racket","bottle","wine glass","cup","fork","knife ",
"spoon","bowl","banana","apple","sandwich","orange","broccoli","carrot","hot dog","pizza ","donut","cake","chair","sofa",
"pottedplant","bed","diningtable","toilet ","tvmonitor","laptop ","mouse ","remote ","keyboard ","cell phone","microwave ",
"oven ","toaster","sink","refrigerator ","book","clock","vase","scissors ","teddy bear ","hair drier", "toothbrush ")
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with object threshold.
"""
box_confidences = box_confidences.reshape(-1)
candidate, class_num = box_class_probs.shape
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score* box_confidences >= OBJ_THRESH)
scores = (class_max_score* box_confidences)[_class_pos]
boxes = boxes[_class_pos]
classes = classes[_class_pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
# modified here, remove depends towards "torch", by fengxh, Jun18,2024
def dfl(position):
# Distribution Focal Loss (DFL)
x = np.array(position)
n, c, h, w = x.shape
n,c,h,w = x.shape
p_num = 4
mc = c//p_num
y = x.reshape(n,p_num,mc,h,w)
# Softmax function along the second dimension (channel dimension)
y = np.exp(y - np.max(y, axis=2, keepdims=True))
y /= np.sum(y, axis=2, keepdims=True)
# Create an accuracy matrix based on the channel size per part
acc_matrix = np.arange(mc, dtype=np.float32).reshape(1, 1, mc, 1, 1)
# Compute the weighted sum using the accuracy matrix
y = (y * acc_matrix).sum(2)
return y
def box_process(position):
grid_h, grid_w = position.shape[2:4]
col, row = np.meshgrid(np.arange(0, grid_w), np.arange(0, grid_h))
col = col.reshape(1, 1, grid_h, grid_w)
row = row.reshape(1, 1, grid_h, grid_w)
grid = np.concatenate((col, row), axis=1)
stride = np.array([IMG_SIZE[1]//grid_h, IMG_SIZE[0]//grid_w]).reshape(1,2,1,1)
position = dfl(position)
box_xy = grid +0.5 -position[:,0:2,:,:]
box_xy2 = grid +0.5 +position[:,2:4,:,:]
xyxy = np.concatenate((box_xy*stride, box_xy2*stride), axis=1)
return xyxy
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2])*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(sigmoid(input[..., 2:4])*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
boxes = boxes.reshape(-1, 4)
box_confidences = box_confidences.reshape(-1)
box_class_probs = box_class_probs.reshape(-1, box_class_probs.shape[-1])
_box_pos = np.where(box_confidences >= OBJ_THRESH)
boxes = boxes[_box_pos]
box_confidences = box_confidences[_box_pos]
box_class_probs = box_class_probs[_box_pos]
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score >= OBJ_THRESH)
boxes = boxes[_class_pos] #np.ndarray
classes = classes[_class_pos]
scores = (class_max_score* box_confidences)[_class_pos]
indexes = np.where(classes ==0) #only concert person.
filter_classes = classes[indexes]
filter_boxes = boxes[indexes]
filter_scores = scores[indexes]
return filter_boxes, filter_classes, filter_scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
#print('{}'.format(score))
#print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (0, 0, 255), 2)
'''
cv2.putText(image, '{0:.2f}'.format(score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
'''
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
def ai_result_filter(boxes, classes, scores, classes_prefered, scores_prefered):
filtered_boxes = []
filtered_classes = []
filtered_scores = []
print(f"pre_filter, classes = {classes}", len(classes))
for i in range(len(classes)):
if classes[i] in classes_prefered and scores[i] >= scores_prefered:
filtered_boxes.append(boxes[i])
filtered_classes.append(classes[i])
filtered_scores.append(scores[i])
print(f"want classes: {classes_prefered}")
return filtered_boxes, filtered_classes, filtered_scores
def post_process(input_data):
boxes, scores, classes_conf = [], [], []
defualt_branch=3
pair_per_branch = len(input_data)//defualt_branch
# Python 忽略 score_sum 输出
for i in range(defualt_branch):
boxes.append(box_process(input_data[pair_per_branch*i]))
classes_conf.append(input_data[pair_per_branch*i+1])
scores.append(np.ones_like(input_data[pair_per_branch*i+1][:,:1,:,:], dtype=np.float32))
def sp_flatten(_in):
ch = _in.shape[1]
_in = _in.transpose(0,2,3,1)
return _in.reshape(-1, ch)
boxes = [sp_flatten(_v) for _v in boxes]
classes_conf = [sp_flatten(_v) for _v in classes_conf]
scores = [sp_flatten(_v) for _v in scores]
boxes = np.concatenate(boxes)
classes_conf = np.concatenate(classes_conf)
scores = np.concatenate(scores)
# filter according to threshold
boxes, classes, scores = filter_boxes(boxes, scores, classes_conf)
# nms
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
if len(keep) != 0:
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
#RATIO = 8
RATIO = 1
ratio = RATIO
imageInner = None
def process_image(image, outputs, classes_prefered, latch):
global ratio
global imageInner
ratio -= 1
if(ratio <= 0):
ratio = RATIO
else:
if imageInner is None:
imageInner = image.copy()
return imageInner
#print(outputs);
boxes, classes, scores = post_process(outputs)
if(classes is not None):
boxes, classes, scores = ai_result_filter(boxes, classes, scores, classes_prefered, latch)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(image, boxes, scores, classes)
imageInner = image.copy()
return imageInner, boxes, classes, scores
附录C 一段仅能进行yolov8 onnx->rknn转换代码
它在尝试转换yolov10.onnx模型时会反馈:
root@debian-ai:/home/model# python3 ./pt2rknn.py
.onnx => .rknn
I rknn-toolkit2 version: 2.0.0b15+2edec668
<rknn.api.rknn.RKNN object at 0x7f58ddb93e20>
I It is recommended onnx opset 19, but your onnx model opset is 12!
I Model converted from pytorch, 'opset_version' should be set 19 in torch.onnx.export for successful convert!
I Loading : 100%|██████████████████████████████████████████████| 177/177 [00:00<00:00, 24977.01it/s]
load_onnx 0
D base_optimize ...
D base_optimize done.
D
D fold_constant ...E build: Traceback (most recent call last):
File "rknn/api/rknn_log.py", line 309, in rknn.api.rknn_log.error_catch_decorator.error_catch_wrapper
File "rknn/api/rknn_base.py", line 1885, in rknn.api.rknn_base.RKNNBase.build
File "rknn/api/graph_optimizer.py", line 947, in rknn.api.graph_optimizer.GraphOptimizer.fold_constant
File "rknn/api/session.py", line 34, in rknn.api.session.Session.__init__
File "rknn/api/session.py", line 131, in rknn.api.session.Session.sess_build
File "/usr/local/lib/python3.10/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 383, in __init__
self._create_inference_session(providers, provider_options, disabled_optimizers)
File "/usr/local/lib/python3.10/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 435, in _create_inference_session
sess.initialize_session(providers, provider_options, disabled_optimizers)
onnxruntime.capi.onnxruntime_pybind11_state.NotImplemented: [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : Could not find an implementation for Reshape(19) node with name '/model.10/attn/Reshape'
源码附着在这里(这段代码可以对yolov8进行正确的转换,因为调试开关打开,可以看到更多的模型细节,以及转换前后的模型细节 - 比如内存映射,不同的代码实际执行的步骤等):
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
# 获取当前脚本文件所在目录的父目录,并构建相对路径
import os
import sys
current_dir = os.path.dirname(os.path.abspath(__file__))
project_path = os.path.join(current_dir, '..')
sys.path.append(project_path)
sys.path.append(current_dir)
import numpy as np
import cv2
from rknn.api import RKNN
import subprocess
#执行某个外部脚本.sh
def Invoke_Script(script_releated_path):
sh_path = os.path.join(project_path, script_releated_path)
if(os.path.exists(sh_path)):
subprocess.run(f'sudo {sh_path}', shell=True, check=False)
return True
return False
def pt2onnx(onnx_tgt_filename, pt_src_filename):
Invoke_Script('yolo export model=yolov10s.pt format=onnx opset=12 simplify')
def onnx2rknn(rknn_tgt_filename, onnx_src_filename, imagefiles):
print(".onnx => .rknn")
rknn = RKNN(verbose=True)
print(rknn)
rknn.config(
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
#quant_img_RGB2BGR=False,
#quantized_algorithm='normal',
#quantized_method='channel',
# optimization_level=2,
#compress_weight=False, # 压缩模型的权值,可以减小rknn模型的大小。默认值为False。
#single_core_mode=True,
# model_pruning=False, # 修剪模型以减小模型大小,默认值为False。
target_platform='rk3588')
# Load the PyTorch model yolov5s in the current path
ret1 = rknn.load_onnx(model=onnx_src_filename,
# inputs=[imagefiles],
input_size_list=[[1, 3, 640, 640]])
print("load_onnx", ret1)
# Build and quantize RKNN model
ret2 = rknn.build(do_quantization=1, rknn_batch_size=1, dataset=imagefiles)
print(ret2)
# save the built RKNN model as a yolov5s.rknn file in the current path
ret3 = rknn.export_rknn(export_path=rknn_tgt_filename)
print(f'transfer...{ret1}, {ret2}, {ret3}')
ret = rknn.accuracy_analysis(inputs=[
'./20240613111647_20240613115258_67799264.jpg'
],
target='rk3588',
device_id='515e9b401c060c0b')
# Evaluate model performance
perf_detail = rknn.eval_perf()
# eval memory usage
memory_detail = rknn.eval_memory()
rknn.release()
if __name__ == "__main__":
onnx2rknn('./yolov8l.rknn', './yolov8l.onnx',
'/home/dataset/COCO/coco_subset_20.txt'
) #None means on user developement platform
附录C.1 使用rknn_model_zoo的yolov8 onnx->rknn工具转换
转换v10.onnx模型,仍然有相同的异常出现,所以这个问题似乎是yolov10的模型与yolov8不同造成的。那位第一个转换.yolov10的同志似乎增加了一些额外的处理,我有印象它说把一部分原本在cpu上的代码转移到npu了,也许是这个原因。
root@debian-ai:/home/rknn/rknn_model_zoo-2.0.0/examples/yolov8/python# python3 /home/rknn/rknn_model_zoo-2.0.0/examples/yolov8/python/convert.py /home/model/yolov10s.onnx rk3588
I rknn-toolkit2 version: 2.0.0b15+2edec668
--> Config model
done
--> Loading model
I It is recommended onnx opset 19, but your onnx model opset is 12!
I Model converted from pytorch, 'opset_version' should be set 19 in torch.onnx.export for successful convert!
I Loading : 100%|██████████████████████████████████████████████| 177/177 [00:00<00:00, 15915.79it/s]
done
--> Building model
E build: Traceback (most recent call last):
File "rknn/api/rknn_log.py", line 309, in rknn.api.rknn_log.error_catch_decorator.error_catch_wrapper
File "rknn/api/rknn_base.py", line 1885, in rknn.api.rknn_base.RKNNBase.build
File "rknn/api/graph_optimizer.py", line 947, in rknn.api.graph_optimizer.GraphOptimizer.fold_constant
File "rknn/api/session.py", line 34, in rknn.api.session.Session.__init__
File "rknn/api/session.py", line 131, in rknn.api.session.Session.sess_build
File "/usr/local/lib/python3.10/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 383, in __init__
self._create_inference_session(providers, provider_options, disabled_optimizers)
File "/usr/local/lib/python3.10/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 435, in _create_inference_session
sess.initialize_session(providers, provider_options, disabled_optimizers)
onnxruntime.capi.onnxruntime_pybind11_state.NotImplemented: [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : Could not find an implementation for Reshape(19) node with name '/model.10/attn/Reshape'
注意,这个转换工具处理yolov8的.onnx =>rknn的转换是可行的:
root@debian-ai:/home/rknn/rknn_model_zoo-2.0.0/examples/yolov8/python# python3 /home/rknn/rknn_model_zoo-2.0.0/examples/yolov8/python/convert.py /home/model/yolov8l.onnx rk3588
I rknn-toolkit2 version: 2.0.0b15+2edec668
--> Config model
done
--> Loading model
I It is recommended onnx opset 19, but your onnx model opset is 12!
I Model converted from pytorch, 'opset_version' should be set 19 in torch.onnx.export for successful convert!
I Loading : 100%|███████████████████████████████████████████████| 206/206 [00:00<00:00, 2967.79it/s]
done
--> Building model
W build: found outlier value, this may affect quantization accuracy
const name abs_mean abs_std outlier value
model.0.conv.weight 4.89 7.71 -77.665
I GraphPreparing : 100%|████████████████████████████████████████| 253/253 [00:00<00:00, 9649.36it/s]
I Quantizating 1/2: 9%|███▋ | 22/253 [00:40<03:54, 1.01s/it]
看这个转换工具的的逻辑(直接计算mean std...),它似乎能对任意的.pt=>.onnx模型转换,待会儿测试一下。yolov8的模型与rk3588无关的模型是可以在yolov8 github库下载的。
















 2821
2821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











