







文章目录
Zero-shot Blind Image Denoising via Implicit Neural Representations
1.作者首先指出 blind-spot denoising 策略的缺点
在遇到噪声比较小的图像或者真实场景的图像容易失效,比如变模糊。

2.Implicit Neural Representations
INR(隐式神经表示)可以建立坐标到像素值的映射关系。之前的文章有介绍过。
INR也是一个深度学习网络,卷积或者全连接。输入是图像的坐标,输出是像素值,然后这个网络就是这个图像的一个表示。说白了就是拟合。
然后作者发现,拟合一个有噪声的图像,在前期会有一个阶段拟合的结果与 无噪声图像接近,然后最后训练完成与噪声图像接近。如下图a, 下图a还可以看出 在INR output与 clean最接近的时候,与 noisy的psnr 变化也更加平台。
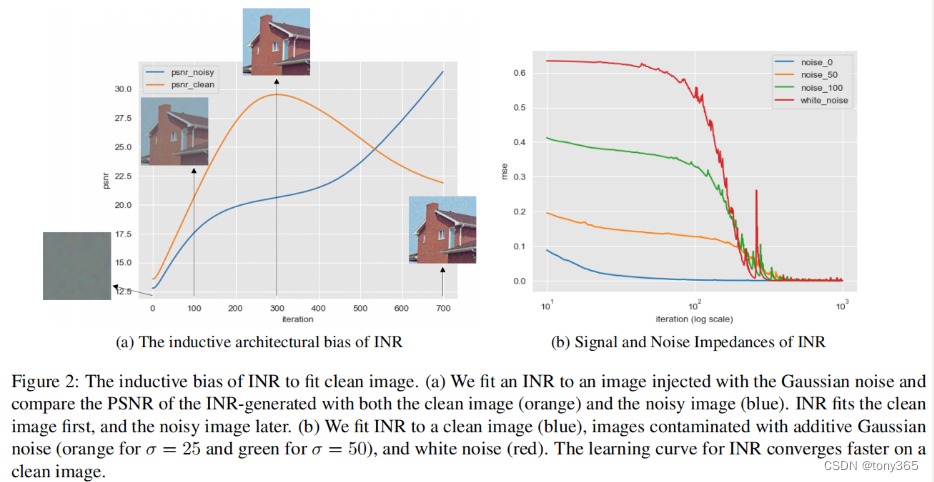
图b说明 拟合clean image 速度更快。
那么既然INR拟合一个有噪声的图像,在前期会有一个阶段拟合的结果与 无噪声图像接近,那么是不是在这个时候让网络停止训练就可以了。如何确定这个停止训练的时机呢?
2.1 策略一:early stopping 标准
作者指定的策略是这样的:
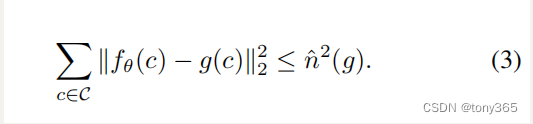
当 output 和 noisy 的mse小于等于 估计的noise level,则停止。
noise level 估计,作者利用的是Chen, G., Zhu, F., and Heng, P. A. An efficient statistical method for image noise level estimation.(ICCV), 2015.
2.2 策略二:Selective Weight Decay
作者发现INR的前几层网络 主要学习 图像基础和低频信息,后面的layer主要学习更多细节和高频信息。并通过实验证实了这一点。
而且实验还表明 early stopping和 训练直到收敛 这2种方法得到的feature主要在后面的layer表现处更大差异。

因此作者提出的策略是:
we propose to apply weight decay selective
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









