







一、概述
关于LSTM同系列的前一篇文章写的是利用LSTM网络对电力负荷进行预测【LSTM预测】,其本质是sequence-to-sequence problems,序列到序列的预测应用。这里做一下sequence-to-label classification problems,序列到标签的分类应用【LSTM分类】。关于LSTM的网络特性不再赘述。
本篇博文的具体示例是对给定的电力负荷进行分类,电力负荷数据格式为每日96个数据点的一维时间序列值,每条负荷数据均对应一个类型标签,总共类别为6类。其他的例子可以参考官网给定的japaneseVowelsTrainData 案例。
负荷数据是某电力公司内部数据,鉴于保密要求,这里仅描述数据格式,负荷数据集不提供。
- 类别:6
- 数据长度:96
- 训练数据条数:9821
- 测试数据条数:2456
二、数据格式转换
首先看一下需要传到LSTM网络的训练参数格式。
trainedNet = trainNetwork(C, Y, layers, options);它必须从序列输入层开始,C是一个包含序列或时间序列预测器的元胞数组。C是d行1列,d代表有多少个训练样本,每个训练样本又包括N行M列,N代表训练样本的数据维度,M代表序列长度,y是标签的分类向量,是categorical类型。
因此,训练数据应该转换成元胞数组,训练数据标签应该转换成categorical类型。
2.1 训练数据格式转换
代码如下所示,用XTrain和YTrain来代替上述训练网络中的C和Y。
dataStandardlized是原始数据标准化后的数据,dataStandardlizedLable是每条数据对应的类别标签,num型。获得XTrain需要通过XTrainData转换成元胞数组,XTrain每一行是一条负荷训练样本数据,即1*96的数据。
YTrain是categorical类别数组,可以通过categorial函数转换,但是输入参数时字符元胞数组,因此现将XTrainLabel转换成字符矩阵,然后再将矩阵转换成元胞数组,最后转换成categorical类型。
%提取训练样本数据
XTrainSize = 9821;
XTrainData = dataStandardlized(1:XTrainSize,:);
XTrainLabel = dataStandardlizedLable(1:XTrainSize,:);
%XTrain
for i = 1:size(XTrainData,1)
XTrain{i,1} = XTrainData(i,:);
end
%YTrain
TrainstrLable = num2str(XTrainLabel);% num to str
for i = 1:size(XTrainData,1)% str matrix to cell
TraincellLable{i,1} = TrainstrLable(i,1);
end
YTrain = categorical(TraincellLable);%cell to categorical2.2 测试数据格式转换
测试数据格式转换方法与训练数据格式转换相同,见代码。
%提取测试样本
XTestData = dataStandardlized(1+XTrainSize:end,:);
XTestLabel = dataStandardlizedLable(1+XTrainSize:end,:);
%XTest
for i = 1:size(XTestData,1)
XTest{i,1} = XTestData(i,:);
end
%YTest
TeststrLable = num2str(TestLabel);% num to str
for i = 1:size(XTestData,1)
TestcellLable{i,1} = TeststrLable(i,1);% str matrix to cell
end
YTest = categorical(TestcellLable);%cell to categorical三、网络参数设置
前面讲到了TrainNetwork的C和Y,这里描述一下网络参数 layers和options的具体配置。
3.1 layers
layers用于定义训练网络的架构,按照网络架构的先后,依次填写到layers的每一行。
首先定义LSTM网络架构:
- 将输入大小指定为序列大小 1(输入数据的维度,指同一时间下的数据维度)
- 指定具有 100 个隐含单元的双向 LSTM 层,并输出序列的最后一个元素。
- 指定六个类,包含大小为 1 的全连接层,后跟 softmax 层和分类层。
inputSize = 1;
numHiddenUnits = 100;
numClasses = 6;
layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(numHiddenUnits,'OutputMode','last')
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer]具体地:
- sequenceInputLayer(inputSize):序列输入层,指定输入维度
- bilstmLayer(numHiddenUnits,'OutputMode','last'):双向LSTM层,指定隐藏节点,输出模式为‘last’即输出最后一个分类值
- fullyConnectedLayer(numClasses):全连接层,指定输出类别的个数
- softmaxLayer:这层是输出各类别分类的的概率
- classificationLayer:分类层,输出最后的分类结果,类似于概率竞争投票。
3.2 options
options用于指定训练网络的优化选项,通过调用trainingOptions进行设置。
此处指定训练选项:
- 求解器为 'adam'
- 梯度阈值为 1,最大轮数为 100。
- 100作为小批量数。
- 填充数据以使长度与最长序列相同,序列长度指定为 'longest'。
- 数据保持按序列长度排序的状态,不打乱数据。
- 'ExecutionEnvironment' 指定为 'cpu',设定为'auto'表明使用GPU。
maxEpochs = 100;
miniBatchSize = 100;
options = trainingOptions('adam', ...
'ExecutionEnvironment','cpu', ...
'GradientThreshold',1, ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'SequenceLength','longest', ...
'Shuffle','never', ...
'Verbose',0, ...
'Plots','training-progress');四、训练LSTM网络
将前面准备好的参数送入训练网络,等待训练结束。
net = trainNetwork(XTrain,YTrain,layers,options);我这里的训练时间非常长,当然训练过程与隐藏节点数,训练数据的维度和训练次数以及电脑配置有关系,我这里单CPU训练耗时112分钟。
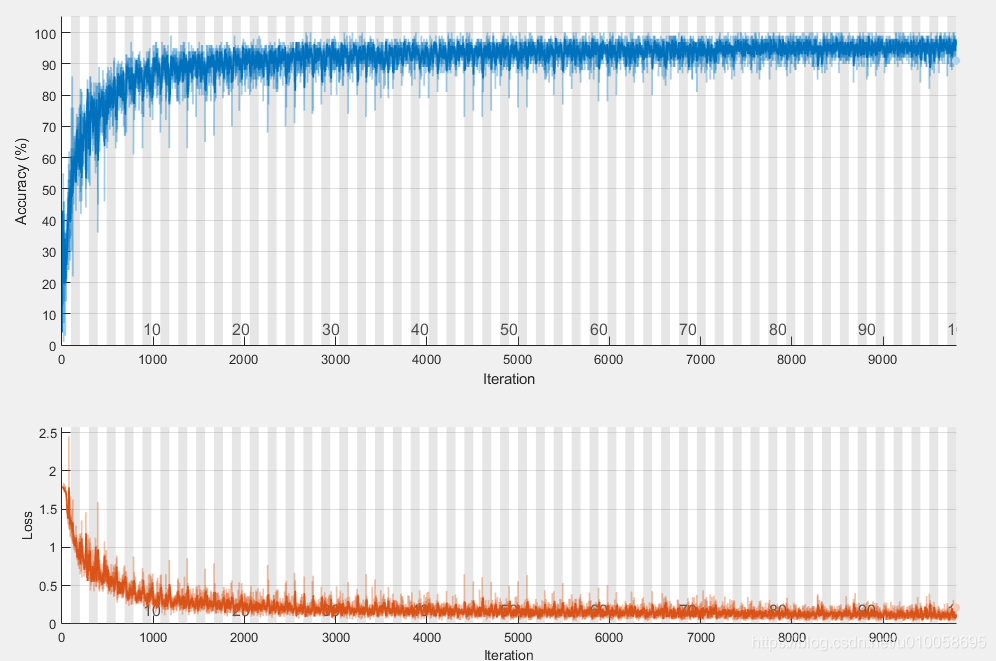
五、利用LSTM网络进行分类
利用标准结果和分类结果计算分类的正确率。
使用classify函数进行分类,同训练过程一样,仍然要指定小批量大小为100,指定组内数据按照最长的数据填充。
miniBatchSize = 100;
YPred = classify(net,XTest, ...
'SequenceLength','longest','MiniBatchSize',miniBatchSize);
%计算分类准确度
acc = sum(YPred == YTest)./numel(YTest)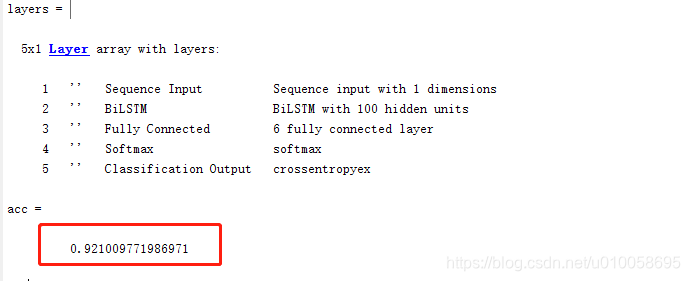
可以看到分类精度达到92%,还是很不错了。
------分享知识,让人愉悦,原创博文,支持请点赞。

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









