







Caffe源码解读2 —— SyncedMemory
欢迎大家多多交流,如有错误,欢迎指正 ^ - ^
上篇博客我们详细的解读了Blob类,了解了Blob是怎么实现对数据的存储和使用。今天我们来谈谈SyncedMemory类。
打开syncedmem.hpp和syncedmem.cpp我们可以看到这个类的具体实现,SyncedMemory类的实现很简单,但是却很重要,因为他可以对cpu和gpu的数据进行同步。
自动机模型
在传统的CUDA程序设计里,我们往往经历这样一个步骤:
->计算前
cudaMalloc(….) 【分配显存空间】
cudaMemset(….) 【显存空间置0】
cudaMemcpy(….) 【将数据从内存复制到显存】
->计算后
cudaMemcpy(….) 【将数据从显存复制回内存】
这些步骤相当得繁琐,你不仅需要反复敲打,而且如果忘记其中一步,就是毁灭性的灾难。
这还仅仅是GPU程序设计,如果考虑到CPU/GPU异构设计,那么就更麻烦了。
所以人们发明了主存管理自动机来代替我们手工操作,这样既能使代码可读性提高,也不容易出错。
caffe中使用了自动机模型对内存和显存进行管理。
enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };从这句代码我们可以看出自动机一共有四个状态,他们会被相应的状态转移函数触发: to_cpu()、to_gpu()、mutable_cpu_data()、mutable_gpu_data()。
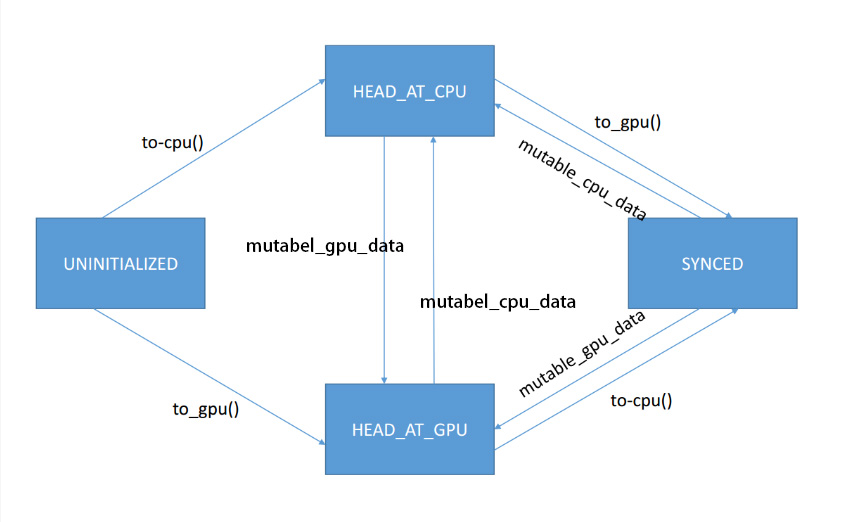
由上图可以清楚的看到状态是怎么根据相应的转移函数触发转移的。
其中mutable_cpu_data()、mutable_gpu_data()函数主要目的是为了得到可修改的cpu和gpu指针,但是从synced状态转移到其他状态只要一句代码就可以实现,所以caffe把转移也写到这两个函数中了。
UNINITIALIZED
这个状态是未初始化状态,也就是SyncedMemory最早的状态,这时候内存和显存都没有被分配,当cpu或者gpu申请内存时该状态终结。
HEAD_AT_CPU
这个状态表明最近一次数据修改是由cpu引起的。此时cpu和gpu的数据还没有同步,也就是cpu和gpu的数据可能不同。
HEAD_AT_GPU
这个状态表明最近一次数据修改是由gpu引起的。此时cpu和gpu的数据还没有同步,也就是cpu和gpu的数据可能不同。
SYNCED
同步状态,这个状态表明此时cpu和gpu的数据一致。
有同学会问我不要这个状态也可以啊。答案确实是可以,即便没有这个状态,状态自动机也可以非常正确的运行。但是仔细想想,如果我们没有这个状态,那么当cpu和gpu的数据相同时,假设head在HEAD_AT_GPU上,现在我们调用to_cpu(),那么head将从gpu复制数据到cpu(即便两个数据是相同的)。caffe是用来跑深度学习的框架,一般深度学习的数据量非常大,所以能减少一次没有意义的复制时间就尽量减少。现在caffe设置了这个状态,也就是如果内存和显存的数据是一致的,就没必要来回复制。
从上图可以看出mutable_cpu_data()、mutable_gpu_data()这两个函数可以打破这个状态,其实很好理解,带mutable的返回的指针是可以对其数据进行修改的,我们调用了这两个函数也就是想改变里面的数据,当我们改变数据后cpu和gpu的数据也就不同步了,所以synced状态被打破。
代码注释
syncedmem.hpp
#ifndef CAFFE_SYNCEDMEM_HPP_
#define CAFFE_SYNCEDMEM_HPP_
#include <cstdlib>
#include "caffe/common.hpp"
namespace caffe {
// If CUDA is available and in GPU mode, host memory will be allocated pinned,
// using cudaMallocHost. It avoids dynamic pinning for transfers (DMA).
// The improvement in performance seems negligible in the single GPU case,
// but might be more significant for parallel training. Most importantly,
// it improved stability for large models on many GPUs.
//CUDA使用memory pinned技术,使得分配的内存不会被释放,这样可以加速CPU和GPU数据的传输速度
inline void CaffeMallocHost(void** ptr, size_t size, bool* use_cuda) {
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
CUDA_CHECK(cudaMallocHost(ptr, size)); //GPU下使用cuda分配内存
*use_cuda = true;
return;
}
#endif
*ptr = malloc(size); //如果只是用cpu则用c的malloc分配内存
*use_cuda = false;
CHECK(*ptr) << "host allocation of size " << size << " failed";
}
//释放内存
inline void CaffeFreeHost(void* ptr, bool use_cuda) {
#ifndef CPU_ONLY
if (use_cuda) {
CUDA_CHECK(cudaFreeHost(ptr));
return;
}
#endif
free(ptr);
}
/**
* @brief Manages memory allocation and synchronization between the host (CPU)
* and device (GPU).
*
* TODO(dox): more thorough description.
*/
class SyncedMemory {
public:
//构造函数,初始化参数
SyncedMemory()
: cpu_ptr_(NULL), gpu_ptr_(NULL), size_(0), head_(UNINITIALIZED),
own_cpu_data_(false), cpu_malloc_use_cuda_(false), own_gpu_data_(false),
gpu_device_(-1) {}
explicit SyncedMemory(size_t size)
: cpu_ptr_(NULL), gpu_ptr_(NULL), size_(size), head_(UNINITIALIZED),
own_cpu_data_(false), cpu_malloc_use_cuda_(false), own_gpu_data_(false),
gpu_device_(-1) {}
~SyncedMemory(); //析构函数,调用CaffeFreeHost释放内存
const void* cpu_data(); //获得cpu数据指针
void set_cpu_data(void* data); //设置cpu共享数据
const void* gpu_data(); //获得gpu数据指针
void set_gpu_data(void* data); //设置gpu共享数据
void* mutable_cpu_data(); //获得可更改的cpu数据指针
void* mutable_gpu_data(); //获得可更改的gpu数据指针
enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };
SyncedHead head() { return head_; }
size_t size() { return size_; }
#ifndef CPU_ONLY
void async_gpu_push(const cudaStream_t& stream);
#endif
private:
void to_cpu(); //状态转移函数
void to_gpu(); //状态转移函数
void* cpu_ptr_; //cpu内存指针
void* gpu_ptr_; //gpu显存指针
size_t size_; //内存大小
SyncedHead head_; //数据状态
bool own_cpu_data_; //共享标记,是否使用的是自己的cpu数据
bool cpu_malloc_use_cuda_;
bool own_gpu_data_; //共享标记,是否使用的是自己的gpu数据
int gpu_device_; //gpu设备
DISABLE_COPY_AND_ASSIGN(SyncedMemory);
}; // class SyncedMemory
} // namespace caffe
#endif // CAFFE_SYNCEDMEM_HPP_
这段代码的其他部分很好理解,上面的介绍加上注释说的都很清楚了,有同学可能不理解own_cpu_data_和own_gpu_data_这两个变量。这两个变量主要是用来记录是否使用了共享的数据还是自己的数据。
举个例子
当我们调用cpu_data()函数,该函数内部会调用to_cpu()函数
inline void SyncedMemory::to_cpu() {
switch (head_) {
//如果head为UNINITIALIZED,则分配和初始化cpu内存
case UNINITIALIZED:
CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_);
caffe_memset(size_, 0, cpu_ptr_); //将分配的内存全部初始化为0
head_ = HEAD_AT_CPU;
own_cpu_data_ = true;
break;
//如果head为HEAD_AT_GPU,则把gpu的数据拷贝到cpu中
case HEAD_AT_GPU:
#ifndef CPU_ONLY
if (cpu_ptr_ == NULL) {
CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_);
own_cpu_data_ = true;
}
caffe_gpu_memcpy(size_, gpu_ptr_, cpu_ptr_);
head_ = SYNCED;
#else
NO_GPU;
#endif
break;
case HEAD_AT_CPU:
case SYNCED:
break;
}
}可以看到这个函数为cpu分配了内存,own_cpu_data_ 设置为了true。我的理解是现在使用了自己的数据。
而当我们调用set_cpu_data函数时
void SyncedMemory::set_cpu_data(void* data) {
CHECK(data);
if (own_cpu_data_) {
CaffeFreeHost(cpu_ptr_, cpu_malloc_use_cuda_);
}
cpu_ptr_ = data;
head_ = HEAD_AT_CPU;
own_cpu_data_ = false;
}我们可以看到set_cpu_data释放了当前的cpu内存,把指针指向data所指的内存中,own_cpu_data_ 设置为了false;表明当前使用的是宿主(data)的内存。
我们对own_cpu_data_ 进行标记是有必要的,因为当使用的是宿主的内存的时候,当这个类被释放而调用析构函数时,需要检查共享标记,不能释放宿主的内存。
这样可以保证自己申请的内存只能由自己释放。
syncedmem.cpp
#include "caffe/common.hpp"
#include "caffe/syncedmem.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
SyncedMemory::~SyncedMemory() {
if (cpu_ptr_ && own_cpu_data_) {
CaffeFreeHost(cpu_ptr_, cpu_malloc_use_cuda_); //own_cpu_data_为true时释放cpu内存,保证不释放宿主数据
}
#ifndef CPU_ONLY
if (gpu_ptr_ && own_gpu_data_) {
int initial_device;
cudaGetDevice(&initial_device);
if (gpu_device_ != -1) {
CUDA_CHECK(cudaSetDevice(gpu_device_));
}
CUDA_CHECK(cudaFree(gpu_ptr_)); //释放gpu内存
cudaSetDevice(initial_device);
}
#endif // CPU_ONLY
}
//把数据状态转到cpu
inline void SyncedMemory::to_cpu() {
switch (head_) {
//如果head为UNINITIALIZED,则分配和初始化cpu内存
case UNINITIALIZED:
CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_);
caffe_memset(size_, 0, cpu_ptr_); //将分配的内存全部初始化为0
head_ = HEAD_AT_CPU;
own_cpu_data_ = true;
break;
//如果head为HEAD_AT_GPU,则把gpu的数据拷贝到cpu中
case HEAD_AT_GPU:
#ifndef CPU_ONLY
if (cpu_ptr_ == NULL) {
CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_);
own_cpu_data_ = true;
}
caffe_gpu_memcpy(size_, gpu_ptr_, cpu_ptr_);
head_ = SYNCED;
#else
NO_GPU;
#endif
break;
case HEAD_AT_CPU:
case SYNCED:
break;
}
}
//把数据状态转到gpu
inline void SyncedMemory::to_gpu() {
#ifndef CPU_ONLY
switch (head_) {
//如果head为UNINITIALIZED,则分配和初始化gpu内存
case UNINITIALIZED:
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_)); //分配gpu内存
caffe_gpu_memset(size_, 0, gpu_ptr_); //初始化gpu内存
head_ = HEAD_AT_GPU;
own_gpu_data_ = true;
break;
//如果head为HEAD_AT_CPU,则把cpu的数据拷贝到gpu中
case HEAD_AT_CPU:
if (gpu_ptr_ == NULL) {
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_));
own_gpu_data_ = true;
}
caffe_gpu_memcpy(size_, cpu_ptr_, gpu_ptr_);
head_ = SYNCED;
break;
case HEAD_AT_GPU:
case SYNCED:
break;
}
#else
NO_GPU;
#endif
}
//获得cpu数据指针
const void* SyncedMemory::cpu_data() {
to_cpu();
return (const void*)cpu_ptr_;
}
//设置cpu共享
void SyncedMemory::set_cpu_data(void* data) {
CHECK(data);
if (own_cpu_data_) {
CaffeFreeHost(cpu_ptr_, cpu_malloc_use_cuda_);
}
cpu_ptr_ = data;
head_ = HEAD_AT_CPU;
own_cpu_data_ = false;
}
//获得gpu数据指针
const void* SyncedMemory::gpu_data() {
#ifndef CPU_ONLY
to_gpu();
return (const void*)gpu_ptr_;
#else
NO_GPU;
return NULL;
#endif
}
//设置gpu共享数据
void SyncedMemory::set_gpu_data(void* data) {
#ifndef CPU_ONLY
CHECK(data);
if (own_gpu_data_) {
int initial_device;
cudaGetDevice(&initial_device);
if (gpu_device_ != -1) {
CUDA_CHECK(cudaSetDevice(gpu_device_));
}
CUDA_CHECK(cudaFree(gpu_ptr_));
cudaSetDevice(initial_device);
}
gpu_ptr_ = data;
head_ = HEAD_AT_GPU;
own_gpu_data_ = false;
#else
NO_GPU;
#endif
}
//获得可更改的cpu数据指针
void* SyncedMemory::mutable_cpu_data() {
to_cpu();
head_ = HEAD_AT_CPU;
return cpu_ptr_;
}
//获得可更改的gpu数据指针
void* SyncedMemory::mutable_gpu_data() {
#ifndef CPU_ONLY
to_gpu();
head_ = HEAD_AT_GPU;
return gpu_ptr_;
#else
NO_GPU;
return NULL;
#endif
}
#ifndef CPU_ONLY
void SyncedMemory::async_gpu_push(const cudaStream_t& stream) {
CHECK(head_ == HEAD_AT_CPU);
if (gpu_ptr_ == NULL) {
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_));
own_gpu_data_ = true;
}
const cudaMemcpyKind put = cudaMemcpyHostToDevice;
CUDA_CHECK(cudaMemcpyAsync(gpu_ptr_, cpu_ptr_, size_, put, stream));
// Assume caller will synchronize on the stream before use
head_ = SYNCED;
}
#endif
} // namespace caffe
最后说一下async_gpu_push函数。
这个函数的作用是异步同步数据流,就是实现cpu的数据复制到gpu里面。使用异步方式可以有效的防止主进程阻塞。















 6057
6057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









