







前言
本次分享将带领大家从 0 到 1 完成一个人体姿态估计任务,覆盖数据准备、模型训练、推理部署和应用开发的全流程,项目将采用以PaddlePaddle为核心的飞桨深度学习框架进行开发,并总结开发过程中踩过的一些坑,希望能为有类似项目需求的同学提供一点帮助。
项目背景和目标
背景:
人体姿态估计,通常也称为人体关键点检测,方法通常可以分成两类:
- 一种是用坐标回归的方式来解决,直接输出各个关键点的位置坐标
- 另一种是将关键点建模成热力图,通过像素分类任务,回归热力图分布得到关键点位置。
与人脸关键点检测不同,人体的躯干部位更为灵活,变化更为难以预测,基于坐标回归的方法难以胜任,通常使用热力图回归的关键点检测方法。
为此,本次实验将将采用“热力图回归”的方式进行模型搭建: 将关键点建模成热力图,通过像素分类任务,回归热力图分布得到关键点位置。每一类坐标用一个概率图来表示,对图片中的每个像素位置都给一个概率,表示该点属于对应类别关键点的概率。距离关键点位置越近的像素点的概率越接近于1,距离关键点越远的像素点的概率越接近于0。
目标:
- 掌握如何用paddlepaddle深度学习框架搭建一个人体关键点检测模型;
- 掌握关键点检测卷积神经网络的架构的设计原理以及构建流程;
- 掌握如何完成模型的训练、评估、保存、预测等深度学习工作过程;
数据集介绍
本次实验使用的数据集来自 COCO,目前 COCO keypoint track是人体关键点检测的权威公开比赛之一,COCO数据集中把人体关键点表示为17个关节,分别是鼻子,左右眼,左右耳,左右肩,左右肘,左右腕,左右臀,左右膝,左右脚踝。人体关键点检测的任务就是从输入的图片中检测到人体及对应的关键点位置。

百度AI Studio平台
本次实验将采用AI Studio实训平台中的免费GPU资源,在平台注册账号后,点击创建项目-选择NoteBook任务,然后添加数据集,如下图所示,完成项目创建。启动环境可以自行选择CPU资源 or GPU资源,创建任务每天有8点免费算力,推荐大家使用GPU资源进行模型训练,这样会大幅减少模型训练时长。
创建项目的方式有两种:
- 一是在AI Studio实训平台参考如下方式,新建项目。
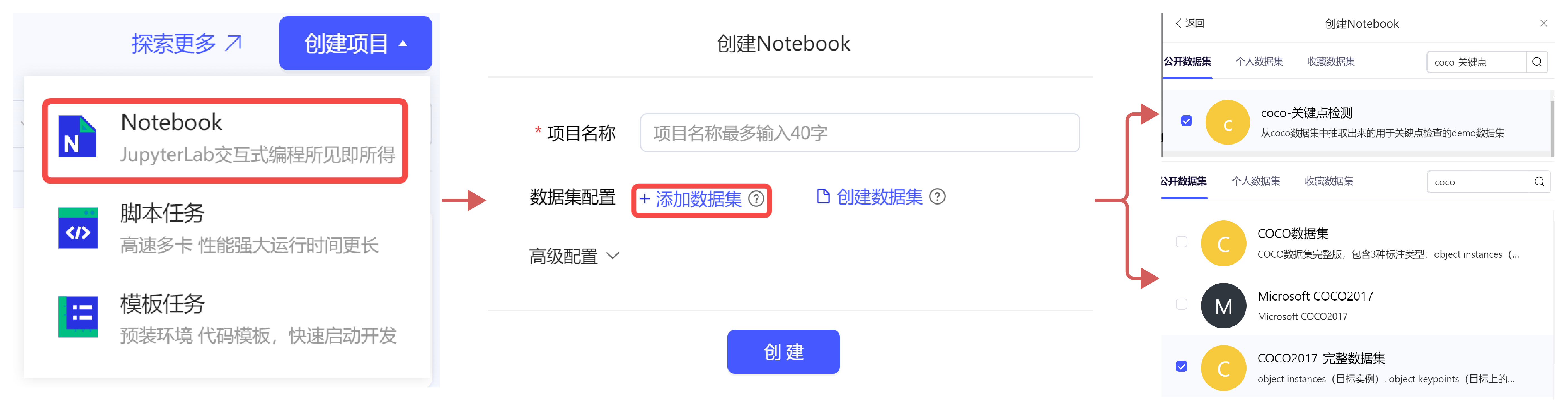
- 二是直接 fork 一个平台上的已有项目,比如本次实验,可以选择【飞桨AI实战】实验5-人体关键点检测的最新版本,然后点击 fork,成功后会在自己账户下新建一个项目副本,其中已经挂载了源项目自带的数据集和本次项目用到的核心代码。
为了快速跑通项目流程,建议直接 fork 源项目。
从零开始实战
1 基础:动手跑通人体关键点检测任务全流程
核心代码在:
core/文件夹下
1.1 数据准备
本案例中使用了两个数据集,分别是:
- COCO2017完整数据集,对应项目中的 data/data7122,用于训练得到更好的模型
- COCO2017抽取的子集,对应项目中的 data/data9663,用于快速验证,跑通流程
step 1:解压缩数据
# 打开终端
# 解压子集 -d 指定解压缩的路径,会在data0文件夹下生成
unzip data/data9663/coco.zip -d data0/
## 解压完成后,目录结构如下:
data0/
`-- coco
|-- annotations
`-- images
# 如果想解压完整数据集 -- 会很慢
mkdir -p data1/coco
cd data1/coco
unzip ../../data/data7122/train2017.zip -d images/
unzip ../../data/data7122/annotations_trainval2017.zip -d ./
step 2: 准备数据部分代码
# 为了读取 coco 数据, 需要安装COCO API,用于加载、解析和可视化COCO数据集
pip install pycocotools
# 自定义Dataset,核心代码见:
reader.py
step 3: 数据可视化
# 打开一个 notebook 比如在main.ipynb中,输入:
from core.reader import COCOPose
debug_data = COCOPose('data0/coco', mode='train', shuffle=True, debug=True)
img, heatmaps, heatmaps_weight = debug_data[0]
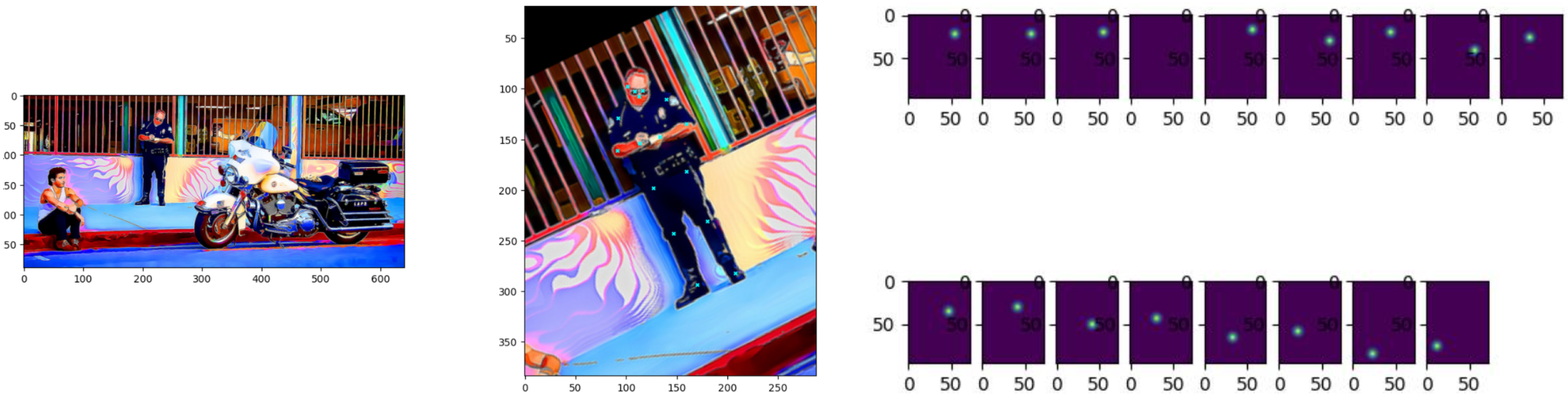
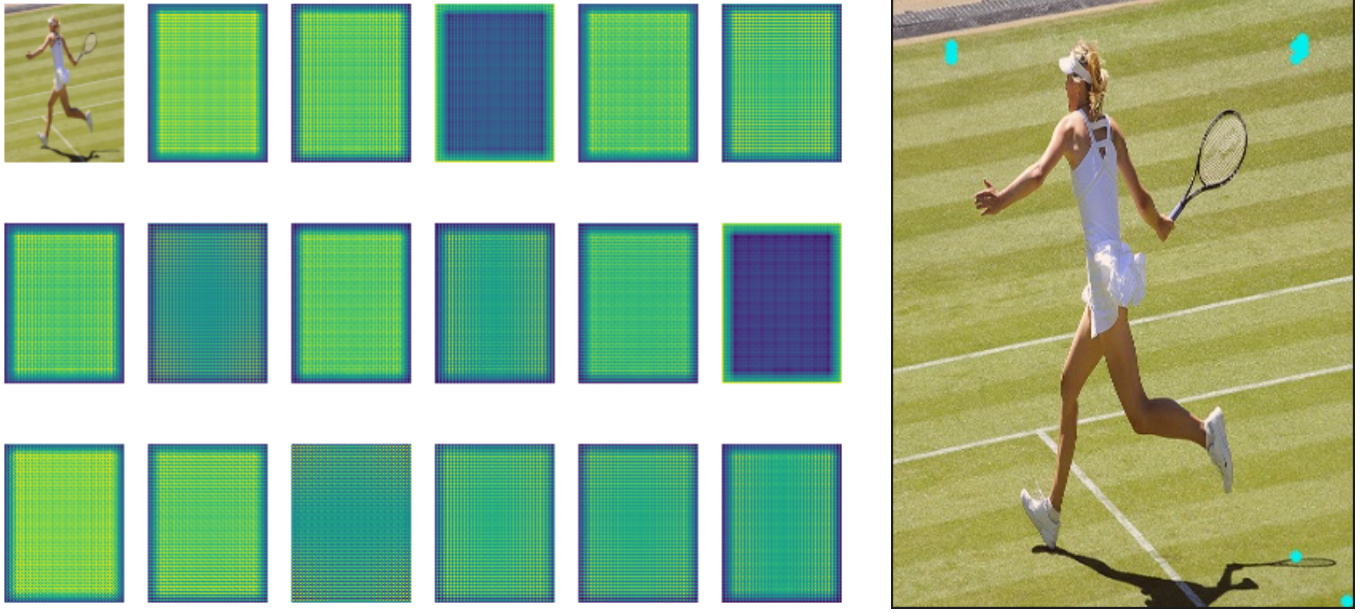
COCOPose 中定义了可视化函数,指定 debug=True,就会打印出数据的可视化结果,如下图所示:
- 左:原始图像
- 中:crop 出的人物图像 及其身上的关键点
- 右:关键点对应的 HeatMap,也即模型要预测的目标
1.2 模型构建
本次实验我们将采用最简单的网络架构,定义为 PoseNet ,backbone模型采用去掉最后池化层和全连接层的ResNet模型,然后通过反卷积和上采样,生成热力图。训练和推理阶段的流程是:输入一张图片,模型生成热力图,通过像素分类任务,回归热力图分布得到关键点位置。
step 1: 搭建 PoseNet
# 定义模型类
net.py
step 2: 定义损失函数
# 定义 HeatMap loss, 位于 net.py
class HMLoss(paddle.nn.Layer):
def __init__(self, kps_num):
super(HMLoss, self).__init__()
self.k = kps_num
def forward(self, heatmap, target, target_weight):
_, c, h, w = heatmap.shape
x = heatmap.reshape((-1, self.k, h*w))
y = target.reshape((-1, self.k, h*w))
w = target_weight.reshape((-1, self.k))
x = x.split(num_or_sections=self.k, axis=1)
y = y.split(num_or_sections=self.k, axis=1)
w = w.split(num_or_sections=self.k, axis=1)
# 计算预测热力图的目标热力图的均方误差
_list = []
for idx in range(self.k):
_tmp = paddle.scale(x=x[idx] - y[idx], scale=1.)
_tmp = _tmp * _tmp
_tmp = paddle.mean(_tmp, axis=2)
_list.append(_tmp * w[idx])
_loss = paddle.concat(_list, axis=0)
_loss = paddle.mean(_loss)
return 0.5 * _loss
1.3 模型训练
编写训练脚本 train.py 如下,主要是定义好数据集、模型,配置训练相关参数:
import paddle
from visualdl import LogWriter
from reader import COCOPose
from net import PoseNet, HMLoss
# 配置visualdl
write = LogWriter(logdir='logdir')
iters = 0 # 初始化为0
class Callbk(paddle.callbacks.Callback):
def __init__(self, write, iters=0):
self.write = write
self.iters = iters
def on_train_batch_end(self, step, logs):
self.iters += 1
#记录loss
self.write.add_scalar(tag="loss",step=self.iters,value=logs['loss'][0])
# 定义数据集
train_data = COCOPose('../data0/coco', mode='train', shuffle=True)
# 定义模型
net = PoseNet(layers=50, kps_num=17, pretrained=True, test_mode=False)
model = paddle.Model(net)
# 选择优化策略
lr = 0.001
batch_size = 64
num_epochs = 100
num_train_img = train_data.__len__()
batch_size = batch_size
step = int(num_train_img / batch_size + 1)
bd = [0.6, 0.85]
bd = [int(num_epochs * e * step) for e in bd]
lr_drop_ratio = 0.1
base_lr = lr
lr = [base_lr * (lr_drop_ratio**i) for i in range(len(bd) + 1)]
scheduler = paddle.optimizer.lr.PiecewiseDecay(boundaries=bd, values=lr, verbose=False)
optim = paddle.optimizer.Adam(learning_rate=scheduler, parameters=model.parameters())
# 准备模型的优化策略和损失函数
model.prepare(optimizer=optim, loss=HMLoss(kps_num=17))
# 使用示例数据集进行10个epoch训练
model.fit(train_data,
batch_size=batch_size,
epochs=num_epochs,
save_dir='outputs/',
save_freq=1,
callbacks=Callbk(write=LogWriter(logdir='logdir'), iters=0)) # 配置visualdl, iters初始化为0
# 运行训练脚本
python train.py
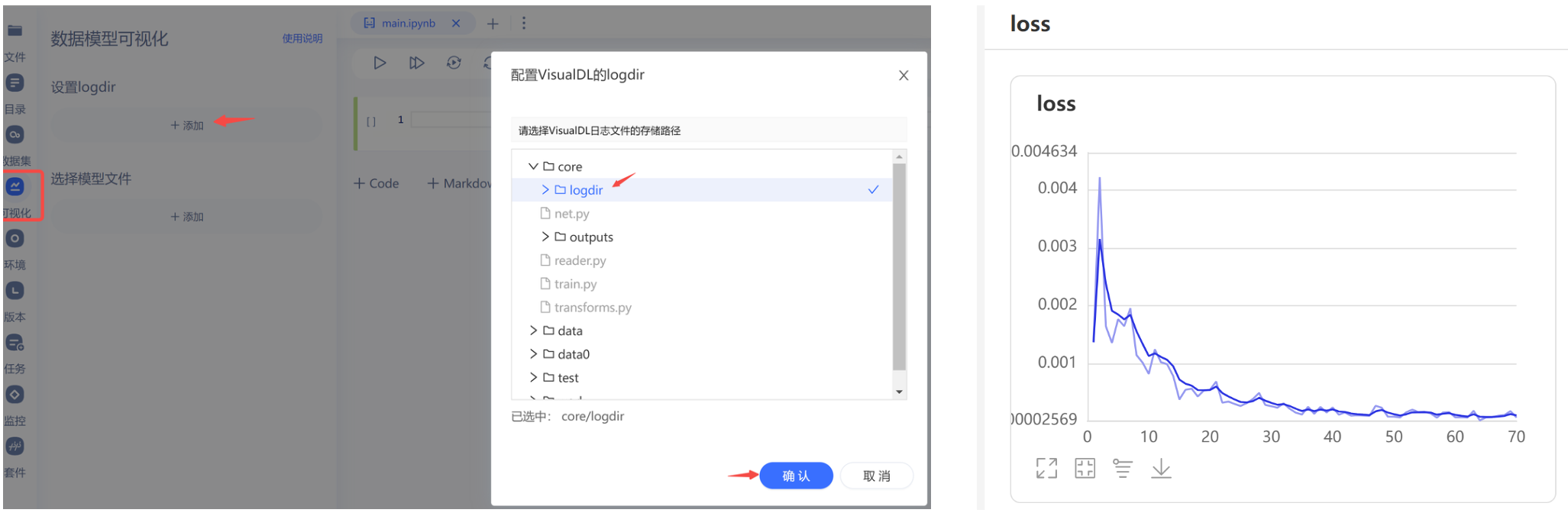
训练过程中,也可以尝试采用 VisualDL 工具,可视化训练过程中的loss:
1.4 模型预测
编写预测脚本 predict.py 如下,
import paddle
import cv2
import numpy as np
from matplotlib import pyplot as plt
from reader import COCOPose_test
from net import PoseNet
# 热力图转为关键点
def get_max_preds(batch_heatmaps):
"""Get predictions from score maps.
heatmaps: numpy.ndarray([batch_size, num_joints, height, width])
"""
assert isinstance(batch_heatmaps, np.ndarray), \
'batch_heatmaps should be numpy.ndarray'
assert batch_heatmaps.ndim == 4, 'batch_images should be 4-ndim'
batch_size = batch_heatmaps.shape[0]
num_joints = batch_heatmaps.shape[1]
width = batch_heatmaps.shape[3]
heatmaps_reshaped = batch_heatmaps.reshape((batch_size, num_joints, -1))
idx = np.argmax(heatmaps_reshaped, 2)
maxvals = np.amax(heatmaps_reshaped, 2)
maxvals = maxvals.reshape((batch_size, num_joints, 1))
idx = idx.reshape((batch_size, num_joints, 1))
preds = np.tile(idx, (1, 1, 2)).astype(np.float32)
preds[:, :, 0] = (preds[:, :, 0]) % width
preds[:, :, 1] = np.floor((preds[:, :, 1]) / width)
pred_mask = np.tile(np.greater(maxvals, 0.0), (1, 1, 2))
pred_mask = pred_mask.astype(np.float32)
preds *= pred_mask
return preds, maxvals
net = PoseNet(layers=50, kps_num=17, pretrained=False, test_mode=False)
net.set_state_dict(paddle.load('outputs/0.pdparams'))
model = paddle.Model(net)
model.prepare()
test_data = COCOPose_test(data_dir='testdata')
result = model.predict(test_data, batch_size=1)
for id in range(len(test_data)):
image, _ = test_data[id]
min = np.array(image.min(), dtype=np.float32)
max = np.array(image.max(), dtype=np.float32)
image = np.add(image, -min)
image = np.divide(image, max - min + 1e-5) * 255
image = image.clip(0, 255).astype(np.uint8)
image = cv2.cvtColor(image.transpose(1, 2, 0),cv2.COLOR_BGR2RGB)
# 绘制热力图
for i in range(18):
plt.subplot(3, 6, i+1)
plt.axis('off')
if i == 0:
plt.imshow(image)
else:
plt.imshow(result[0][id][0][i-1])
plt.savefig(f'result_hm_{id}.png')
# 绘制关键点
batch_heatmaps = result[0][id]
batch_size,num_joints,heatmap_height,heatmap_width = result[0][id].shape
preds, maxvals = get_max_preds(batch_heatmaps)
icolor = (0, 238, 238)
print('point num:',num_joints)
for j in range(num_joints):
x,y = preds[0][j]
cv2.circle(image, (int(x * 4), int(y * 4)), 3, icolor, -1, 16)
cv2.imwrite(f'result_kp_{id}.png', cv2.cvtColor(image, cv2.COLOR_RGB2BGR))
# 运行预测脚本
python predict.py
实验结果发现,如果只是用子集的 500 张图像进行训练,模型根本无法收敛,预测效果如下图所示:
这时需要改用 完整数据集 train2017 进行训练,在训练 1 个 epoch (单卡 V100 大概耗时在 1 小时左右) 后,模型基本可以收敛,预测效果如下图所示:

2 进阶:基于PP-TinyPose搭建应用
核心代码在:
pose-demo/文件夹下
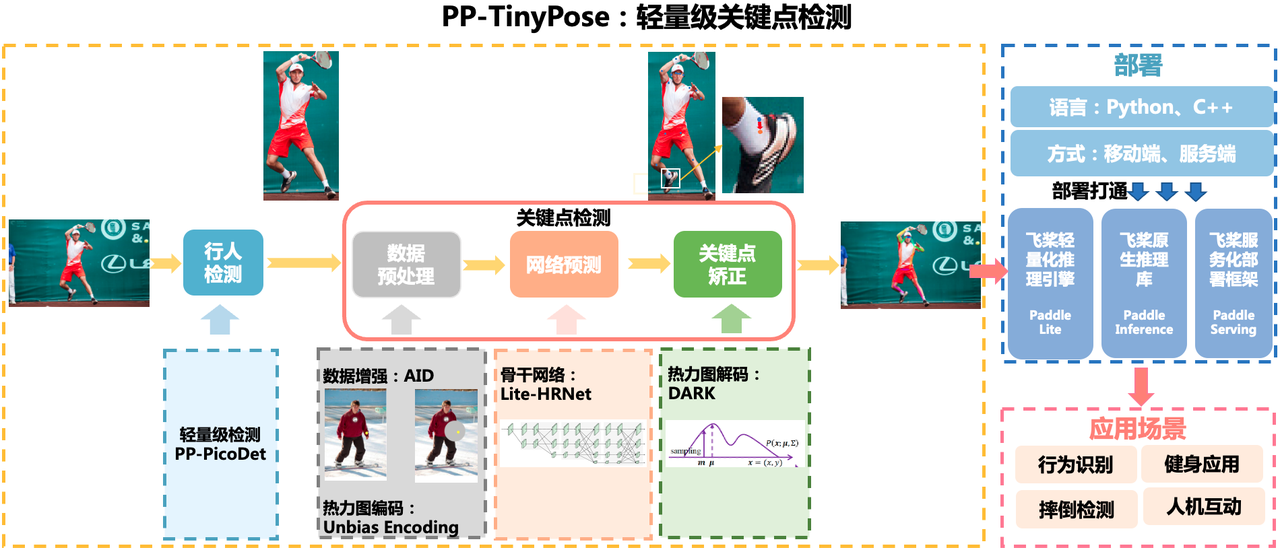
2.1 PP-TinyPose 简介
PP-TinyPose 是 PaddleDetecion 针对移动端设备优化的实时关键点检测模型,可流畅地在移动端设备上执行多人姿态估计任务。
本质上是一个自顶向下的方法,其处理流程图如下:人体检测 + 关键点检测。
2.2 模型准备
因为 PP-TinyPose 是基于 PaddleDetecion 框架实现的,所以我们需要首先下载 PaddleDetecion:
# 国内网络问题,可能导致下载失败,可以多尝试几次
git clone https://github.com/PaddlePaddle/PaddleDetection.git
如果要重新训练模型,可以参考笔者之前分享的目标检测的一个项目案例【飞桨AI实战】交通灯检测:手把手带你入门PaddleDetection,从训练到部署,完成环境准备。
但由于训练耗时较长,这里我们直接下载官方训练好的模型,并解压出来:
mkdir output_inference & cd output_inference
wget https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_enhance/picodet_s_320_lcnet_pedestrian.zip
wget https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_enhance/tinypose_256x192.zip
unzip picodet_s_320_lcnet_pedestrian.zip
unzip tinypose_256x192.zip
找一张图像测试了看看,发现效果是 OK 的:
python deploy/python/det_keypoint_unite_infer.py --det_model_dir=output_inference/picodet_v2_s_320_pedestrian --keypoint_model_dir=output_inference/tinypose_256x192 --image_file=../core/testdata/000000000016.jpg

2.3 部署准备
飞桨提供了众多的模型部署方式,有关不同部署方式的适用场景,可以参考之前的分享【飞桨AI实战】人像分割:手把手带你入门PaddleSeg,从模型训练、推理部署到应用开发。
本次实验为了带领大家快速跑通流程,这里采用最简单的推理方式-直接采用 Inference 模型进行推理,用到的函数主要在 PaddleDetection/deploy/python/ 下,所以首先将该文件夹复制到当前文件夹pose-demo/下。
然后编写模型推理函数,我放在了model.py中,其主要逻辑是新定义类UniModel,初始化中指定加载的人体检测模型和关键点检测模型,然后分别编写两个函数:infer_img 和 infer_vid ,分别实现对图片和视频的推理,最后通过visualize函数实现推理结果的可视化。具体实现逻辑如下:
import os
import time
import cv2
import math
import numpy as np
from deploy.python.infer import Detector
from deploy.python.keypoint_infer import KeyPointDetector
from deploy.python.det_keypoint_unite_infer import KeypointSmoothing
class UniModel():
def __init__(self):
dirpath = os.path.dirname(os.path.abspath(__file__))
self.detector = Detector(
model_dir= os.path.join(dirpath, 'output_inference/picodet_v2_s_320_pedestrian'),
device='CPU')
self.keypoint_detector = KeyPointDetector(
model_dir=os.path.join(dirpath, 'output_inference/tinypose_256x192'),
device='CPU')
def infer_img(self, img_file, vis=False):
if type(img_file) == str:
image = cv2.imread(img_file)
else:
image = img_file
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = self.detector.predict_image([image], visual=False)
results = self.detector.filter_box(results, threshold=0.5)
if results['boxes_num'] > 0:
keypoint_res = self.predict_with_given_det(image, results)
keypoint_res['boxes_num'] = results['boxes_num']
else:
keypoint_res = {"keypoint": [[], []], "boxes_num": 0}
if vis:
canvas = self.visualize(img_file, keypoint_res)
return canvas, keypoint_res
return keypoint_res
def predict_with_given_det(self, image, det_res):
keypoint_res = {}
rec_images, records, det_rects = self.keypoint_detector.get_person_from_rect(image, det_res)
if len(det_rects) == 0:
keypoint_res['keypoint'] = [[], []]
return keypoint_res
kp_results = self.keypoint_detector.predict_image(rec_images, visual=False)
kp_results['keypoint'][..., 0] += np.array(records)[:, 0:1]
kp_results['keypoint'][..., 1] += np.array(records)[:, 1:2]
keypoint_res['keypoint'] = [
kp_results['keypoint'].tolist(), kp_results['score'].tolist()
] if len(kp_results['keypoint']) > 0 else [[], []]
keypoint_res['bbox'] = det_rects
return keypoint_res
def infer_vid(self, video_file=None, camera_id=-1):
if camera_id != -1:
capture = cv2.VideoCapture(camera_id)
else:
capture = cv2.VideoCapture(video_file)
out_path = 'output.mp4'
width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(capture.get(cv2.CAP_PROP_FPS))
frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
print("fps: %d, frame_count: %d" % (fps, frame_count))
fourcc = cv2.VideoWriter_fourcc(* 'mp4v')
writer = cv2.VideoWriter(out_path, fourcc, fps, (width, height))
index = 0
keypoint_smoothing = KeypointSmoothing(width, height, filter_type='OneEuro', beta=0.05)
while True:
ret, frame = capture.read()
if not ret:
break
index += 1
print('detect frame: %d' % (index))
results = self.infer_img(frame, vis=False)
if results['boxes_num'] == 0:
writer.write(frame)
continue
if len(results['keypoint'][0]) == 1:
current_keypoints = np.array(results['keypoint'][0][0])
smooth_keypoints = keypoint_smoothing.smooth_process(current_keypoints)
results['keypoint'][0][0] = smooth_keypoints.tolist()
frame = self.visualize(frame, results)
writer.write(frame)
writer.release()
print('output_video saved to: {}'.format(out_path))
return out_path, "fps: %d, frame_count: %d" % (fps, frame_count)
def visualize(self, img_file, results, visual_thresh=0.5):
skeletons, scores = results['keypoint']
if len(skeletons) == 0:
return img_file
skeletons = np.array(skeletons)
kpt_nums = 17
if len(skeletons) > 0:
kpt_nums = skeletons.shape[1]
if kpt_nums == 17: #plot coco keypoint
EDGES = [(0, 1), (0, 2), (1, 3), (2, 4), (3, 5), (4, 6), (5, 7), (6, 8),
(7, 9), (8, 10), (5, 11), (6, 12), (11, 13), (12, 14),
(13, 15), (14, 16), (11, 12)]
else: #plot mpii keypoint
EDGES = [(0, 1), (1, 2), (3, 4), (4, 5), (2, 6), (3, 6), (6, 7), (7, 8),
(8, 9), (10, 11), (11, 12), (13, 14), (14, 15), (8, 12),
(8, 13)]
NUM_EDGES = len(EDGES)
colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
[0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \
[170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
img = cv2.imread(img_file) if type(img_file) == str else img_file
bboxs = results['bbox']
for rect in bboxs:
xmin, ymin, xmax, ymax = rect
color = colors[0]
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color, 2)
canvas = img.copy()
for i in range(kpt_nums):
for j in range(len(skeletons)):
if skeletons[j][i, 2] < visual_thresh:
continue
cv2.circle(
canvas,
tuple(skeletons[j][i, 0:2].astype('int32')),
2,
colors[i],
thickness=-1)
for i in range(NUM_EDGES):
for j in range(len(skeletons)):
edge = EDGES[i]
if skeletons[j][edge[0], 2] < visual_thresh or skeletons[j][edge[
1], 2] < visual_thresh:
continue
cur_canvas = canvas.copy()
X = [skeletons[j][edge[0], 1], skeletons[j][edge[1], 1]]
Y = [skeletons[j][edge[0], 0], skeletons[j][edge[1], 0]]
mX = np.mean(X)
mY = np.mean(Y)
length = ((X[0] - X[1])**2 + (Y[0] - Y[1])**2)**0.5
angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
polygon = cv2.ellipse2Poly((int(mY), int(mX)),
(int(length / 2), 2),
int(angle), 0, 360, 1)
cv2.fillConvexPoly(cur_canvas, polygon, colors[i])
canvas = cv2.addWeighted(canvas, 0.4, cur_canvas, 0.6, 0)
return canvas
2.4 应用搭建
本次实验同样还是基于 Gradio 搭建一个简单的前端应用,能够实现图片和视频的人体关键点检测。
首先,我们新建 Gradio 界面搭建脚本文件,pose-demo/demo.gradio.py,两个 tab 分别实现图片和视频推理,交互按钮调用 UniModel 中的处理函数,具体实现逻辑如下:
import gradio as gr
from model import UniModel
model = UniModel()
def process_frame(image):
canvas, keypoint_res = model.infer_img(image, vis=True)
return canvas, keypoint_res['boxes_num']
def process_video(video):
out_path, vid_info = model.infer_vid(video)
return out_path, vid_info
with gr.Blocks() as demo:
html_title = '''
<h1 style="text-align: center; color: #333;">PP-TinyPose人体关键点检测</h1>
'''
gr.HTML(html_title)
with gr.Tab("图像处理"):
# Blocks默认设置所有子组件按垂直排列Column
with gr.Row():
image_input = gr.Image(label='输入图像')
with gr.Column():
image_output = gr.Image(label='检测结果')
text_image = gr.Textbox(label='行人数量')
image_button = gr.Button(value="提交")
with gr.Tab("视频处理"):
with gr.Row():
with gr.Column():
video_input = gr.Video(label='输入图像')
with gr.Column():
video_output = gr.Video(label='检测结果')
text_video = gr.Textbox(label='视频信息')
video_button = gr.Button(value="提交")
image_button.click(process_frame, inputs=image_input, outputs=[image_output, text_image])
video_button.click(process_video, inputs=video_input, outputs=[video_output, text_video])
demo.launch()
编写完成后,我们在 AI Studio 的 CodeLab 界面测试一下,速度 Ok:
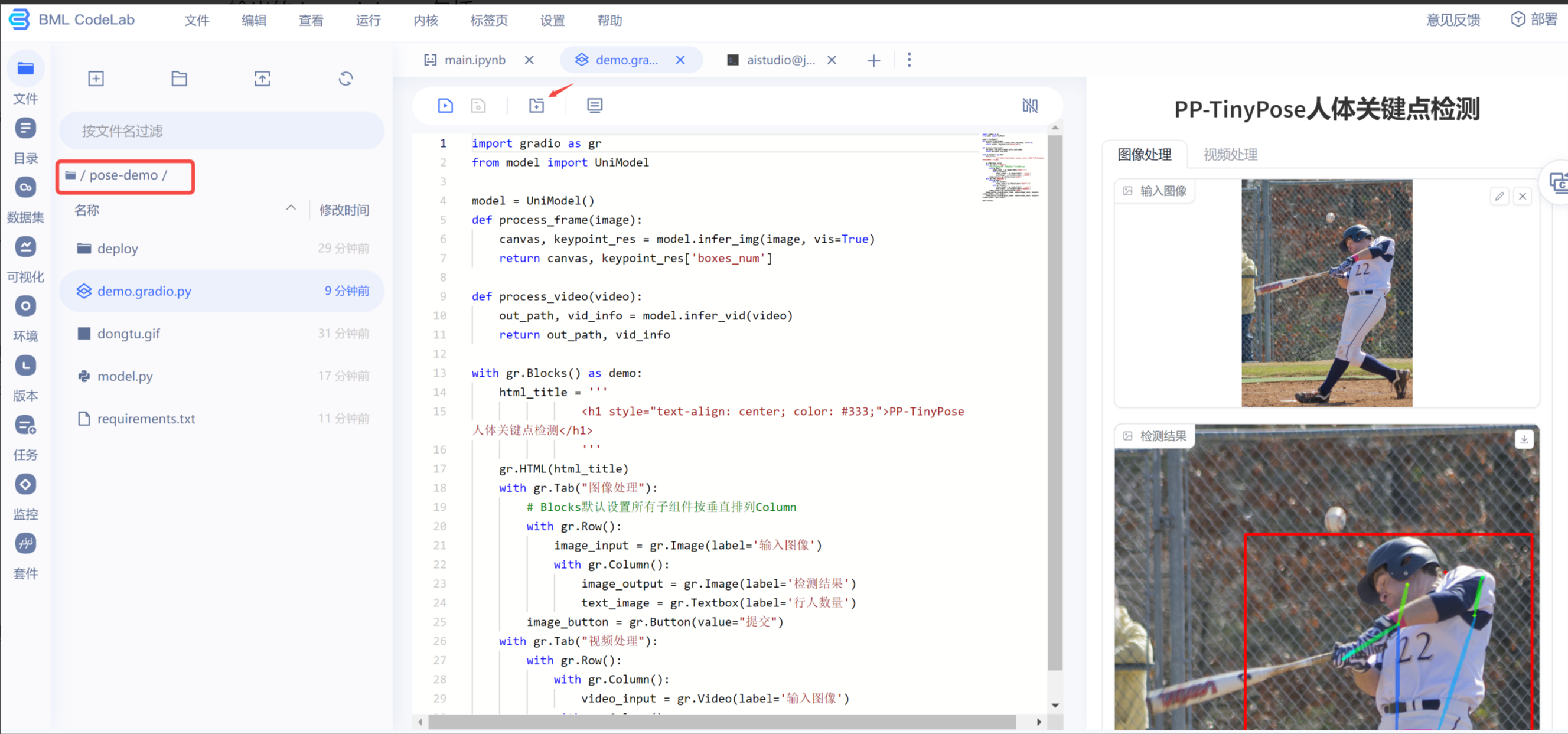
点击代码区域上方的 + 号,可以在浏览器中打开应用,让我们加载一个视频看看,测试结果如下,当然目前视频处理的耗时还比较长,后续可以考虑其他部署方式,加快模型推理速度。
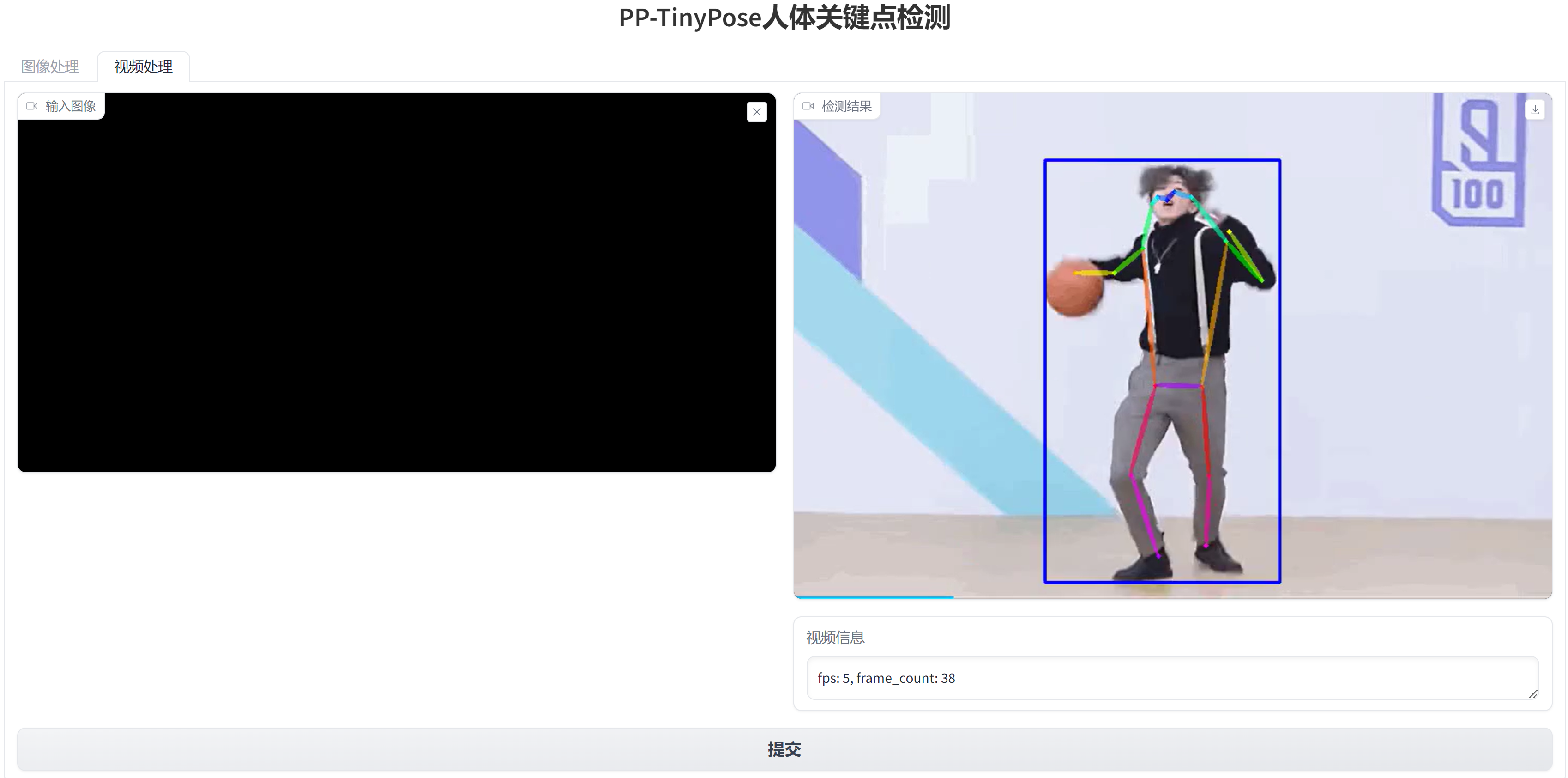
推理后输出的视频就是你在本篇开头看到的动图,这里通过 moviepy 库将 .mp4 文件转成了 .gif 进行展示。
from moviepy.editor import VideoFileClip
clip = VideoFileClip('output.mp4')
clip = clip.resize(0.5)
clip.write_gif('output.gif', fps=5)
clip.close()
总结
至此,我们共同走完了一个完整的人体姿态估计项目,从基础的数据准备到模型训练,再到应用开发和部署,旨在帮助初学者快速入门并掌握关键技能。首先了解了如何使用PaddlePaddle框架和COCO数据集来构建和训练一个高效的人体关键点检测模型,其次采用PP-TinyPose模型通过Gradio创建了一个交互式的前端应用。
人体姿态估计技术在多个领域都有着广泛的应用,从健康监测到增强现实,再到安全监控等。期待本文能够激发您对深度学习和计算机视觉的兴趣。
本系列的后续文章将沿袭这一思路,继续分享更多采用Paddle深度学习框架服务更多产业应用的案例。如果对你有帮助,欢迎 关注 收藏 支持啊~

















 6842
6842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









