







写在前面
在了解了图像分类和目标检测的基本概念后,很多同学发现现有的算法模型往往只能识别特定类别的目标,面对全新的目标类别,这些训好的模型往往就无能为力了。
本次分享将带领大家从 0 到 1 搭建一个面向现实场景的商品识别系统,旨在帮助初学者快速走通从理论到应用的过程,希望对感兴趣的同学提供一点帮助。
项目地址:https://aistudio.baidu.com/projectdetail/7541293
1、商品识别基本原理
本项目将采用飞桨团队开源的 PP-ShiTu,一个实用轻量级通用图像识别方案。其流程图如下所示:
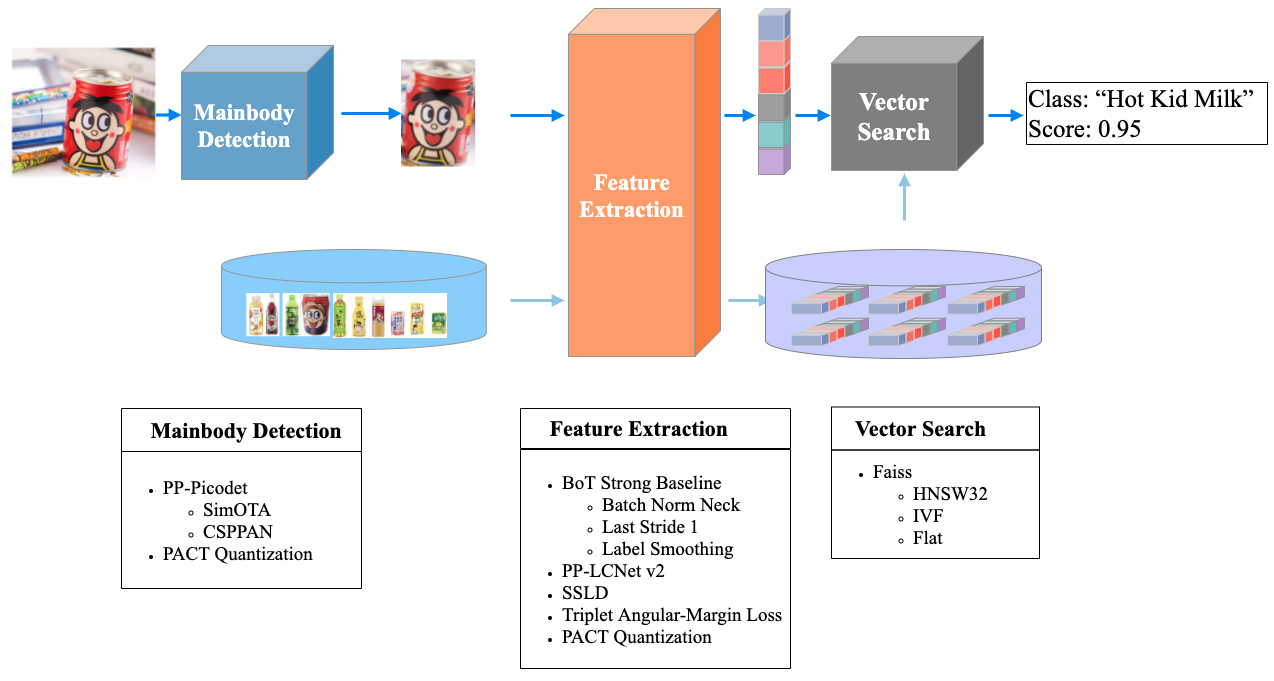
从图中可以发现,上述模型由主体检测、特征提取、向量检索三个模块构成。
- 主体检测:采用 picodet_lcnet_x2_5_640_mainbody ,用于检测出图像中的主体目标
- 特征提取:采用 PPLCNetV2_base_ShiTu 作为特征提取器,对主体目标提取特征,得到固定维度的特征向量
- 向量检索:采用 Faiss 向量检索库,可参考官方文档。
- 检索库生成:应用启动前,对于所有已知类别的图片,将特征向量存入检索库
- 检索库查询:应用启动后,对于需要识别的图片,经过 主体检测+特征提取 后,将其特征向量和检索库中的所有特征向量进行比对,找到相似度最高的返回,如果相似度高于一定阈值,则识别成功;否则识别失败,该图片的类别在检索库中不存在
- 检索库更新:如果待识别的图片在检索库中不存在,可以人工给图片打上标签,并将其特征向量存入到检索库中。
2、源码实践
为了更好理解上述方案的基本原理,参考PP-ShiTu V2图像识别系统官方文档,我们需要逐步完成如下步骤。
2.1 环境准备:
打开一个终端,在根目录下执行如下命令:
git clone https://gitee.com/paddlepaddle/PaddleClas.git
# 安装依赖
cd PaddleClas/
pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
# 编译安装paddleclas
python setup.py install
2.2 数据准备:
在系统根目录下下载并解压示例数据,后面建议检索库需要用到:
cd ~
wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/data/drink_dataset_v2.0.tar && tar -xf drink_dataset_v2.0.tar
2.3 推理模型准备:
进入 PaddleClas 目录,在deploy/models中准备好模型:
cd deploy/models
# 下载主体检测模型并解压
wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/models/inference/picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer.tar && tar -xf picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer.tar
# 下载特征提取模型并解压
wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/models/inference/PP-ShiTuV2/general_PPLCNetV2_base_pretrained_v1.0_infer.tar && tar -xf general_PPLCNetV2_base_pretrained_v1.0_infer.tar
2.4 建立索引库:
建立索引库的核心代码在python/build_gallery.py,可以发现它主要会读取 yaml 配置文件中的配置来完成建库的任务。我们来看下yaml 配置文件中的几个关键参数:
IndexProcess:
index_method: "HNSW32" # supported: HNSW32, IVF, Flat
image_root: "/home/aistudio/drink_dataset_v2.0/gallery/"
data_file: "/home/aistudio/drink_dataset_v2.0/gallery/drink_label.txt"
index_dir: "/home/aistudio/drink_dataset_v2.0/index"
index_operation: "new" # suported: "new","append", "remove"
delimiter: "\t"
index_method: 代表检索算法,支持三种检索算法HNSW32、IVF、FLAT。每种检索算法,满足不同场景。其中 HNSW32 为默认方法,该方法检索精度、检索速度可以取得一个较好的平衡,关于HNSW32算法的简单介绍可以查看官方文档;image_root: 文件夹下保存所有已知类别的图片;data_file: 是一个txt文件,存储的是图像文件的路径和标签,每一行格式为:image_path label,中间间隔以delimiter参数作为间隔;index_dir: 存储生成的检索库;index_operation: 构建检索库的三种方法,new 代表重新构建一个检索库,append 代表在已有的检索库中新增类别,remove 代表从已有的检索库中删除类别。
综上,python/build_gallery.py 将根据 data_file 的图像列表,对 image_root 下的所有图像进行特征提取,在 index_dir 下进行存储,以待后续检索使用。
下面我们执行如下代码实现检索库的构建:
# 进入 deploy 目录
cd deploy
# 根据需要改成自己所需的具体 yaml 文件
python python/build_gallery.py -c configs/inference_general.yaml
构建完成后,在 index 文件夹下生成两个文件:
|-- id_map.pkl # 类别序号 类别名称 的对应关系
|-- vector.index # 存放类别的特征向量
2.5 执行推理:
推理的核心代码在 python/predict_system.py,同样它会读取yaml 配置文件中的配置,-o 后面的参数代表覆盖配置文件中的参数,比如我们要对 "../../drink_dataset_v2.0/test_images/100.jpeg" 这张图像进行推理,就可以采用如下命令:
python python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="../../drink_dataset_v2.0/test_images/100.jpeg" -o Global.use_gpu=False
最终得到的结果如下,推理结果是一个列表,其中每个元素包含了:目标框位置,目标类别以及置信度得分。
Inference: 173.80523681640625 ms per batch image
[{'bbox': [437, 71, 660, 728], 'rec_docs': '元气森林', 'rec_scores': 0.77402496}, {'bbox': [221, 72, 449, 701], 'rec_docs': '元气森林', 'rec_scores': 0.6950995}, {'bbox': [794, 104, 979, 652], 'rec_docs': '元气森林', 'rec_scores': 0.630515}]

3、应用搭建
问题来了:命令行中查看结果并不是特别直观,如果能搭建一个简单的可视化界面,显然对理解识别原理更友好一些。本次实验,我们同样还是采用 Gradio 来搭建前端界面。
3.1 需求分析
为了完成一个最小可运行版本(MVP),本实验主要需要完成两个功能:
- 图像识别:上传一张图像,要能够识别出图像中的主体目标。
- 索引库更新:对于未识别成功的图像,将其类别加入到索引库中。
3.2 功能实现
核心代码放在了项目中
pp_shitu_demo/文件夹下
我们先来看下 pp_shitu_demo/ 这个项目的主要构成:
pp_shitu_demo/
├── data/
├── models/
├── utils/
├── build_gallery.py
├── predict_system.py
├── inference_general.yaml
├── demo.gradio.py
├── requirements.txt
data文件夹用来存放图片,可以将上面我们采用的官方示例 drink_dataset_v2.0/gallery/ 复制一份过来models文件夹用来存放推理需要的模型参数,可以将上面我们已经下载好的检测和识别模型文件复制一份过来utils文件夹下存放了字体文件,用于在结果图片上渲染汉字
step1 建立检索库:
建立检索库主要是用到了 PaddleClas/deploy/python/build_gallery.py,为此我们可以复制一份到当前项目目录下。为了能够调用它,在 test.py 中编写如下函数:
import os
import subprocess
import json
def build_initial_gallery(image_root=None, data_file=None, index_operation=None):
script = 'python build_gallery.py -c inference_general.yaml'
if image_root:
script += f' -o IndexProcess.image_root={image_root}'
if data_file:
script += f' -o IndexProcess.data_file={data_file}'
if index_operation:
script += f' -o IndexProcess.index_operation={index_operation}'
# os.system(script)
result = subprocess.run(script, shell=True, capture_output=True, text=True)
if result.stdout:
return result.stdout
else:
return 'built failed'
if __name__ == "__main__":
build_initial_gallery(image_root='data/gallery', data_file='data/gallery/drink_label.txt', index_operation='new')
执行上述函数,便可以在 data/index/ 文件夹下生成新的检索库。
step2 实现图像识别:
实现图像识别主要是用到了 PaddleClas/deploy/python/predict_system.py,为此我们可以复制一份到当前项目目录下。为了能够调用它,在 test.py 中编写如下函数:
def recognition_predict(infer_imgs=None):
script = 'python predict_system.py -c inference_general.yaml'
if infer_imgs:
script += f' -o Global.infer_imgs={infer_imgs}'
# os.system(script)
result = subprocess.run(script, shell=True, capture_output=True, text=True)
if result.stdout:
print("STDOUT:")
print(result.stdout)
res = result.stdout.split('\n')[1].replace('\'', '\"')
print(json.loads(res))
# 打印标准错误
# if result.stderr:
# print("STDERR:")
# print(result.stderr)
3.3 前端界面实现
在上述两个功能测试没问题后,采用 gradio 搭建界面就比较容易了。核心代码在 demo.gradio.py ,上述两个功能分别通过两个 button 组件实现交互。
with gr.Blocks() as demo:
html_title = '''
<h1 style="text-align: center; color: #333;">PP-ShiTu海量商品图识别</h1>
'''
gr.HTML(html_title)
with gr.Row():
with gr.Column():
image_input = gr.Image(label='输入图像', type='pil',height=400)
gr.Examples(['data/test_images/'+img for img in os.listdir('data/test_images')], [image_input], label='示例图片', examples_per_page=7)
with gr.Column():
image_output = gr.Image(type='pil', height=400, show_label=False)
rec_output = gr.Textbox(label='处理结果')
with gr.Row():
image_button = gr.Button(value="识别图像", variant="primary")
label_box = gr.Textbox(label='类别标签')
index_button = gr.Button(value="加入索引库", variant="primary")
image_button.click(fn=process_image, inputs=[image_input], outputs=[image_output, rec_output])
index_button.click(fn=add_index, inputs=[image_input, label_box], outputs=[rec_output])
demo.launch(server_name='0.0.0.0', server_port=7860)
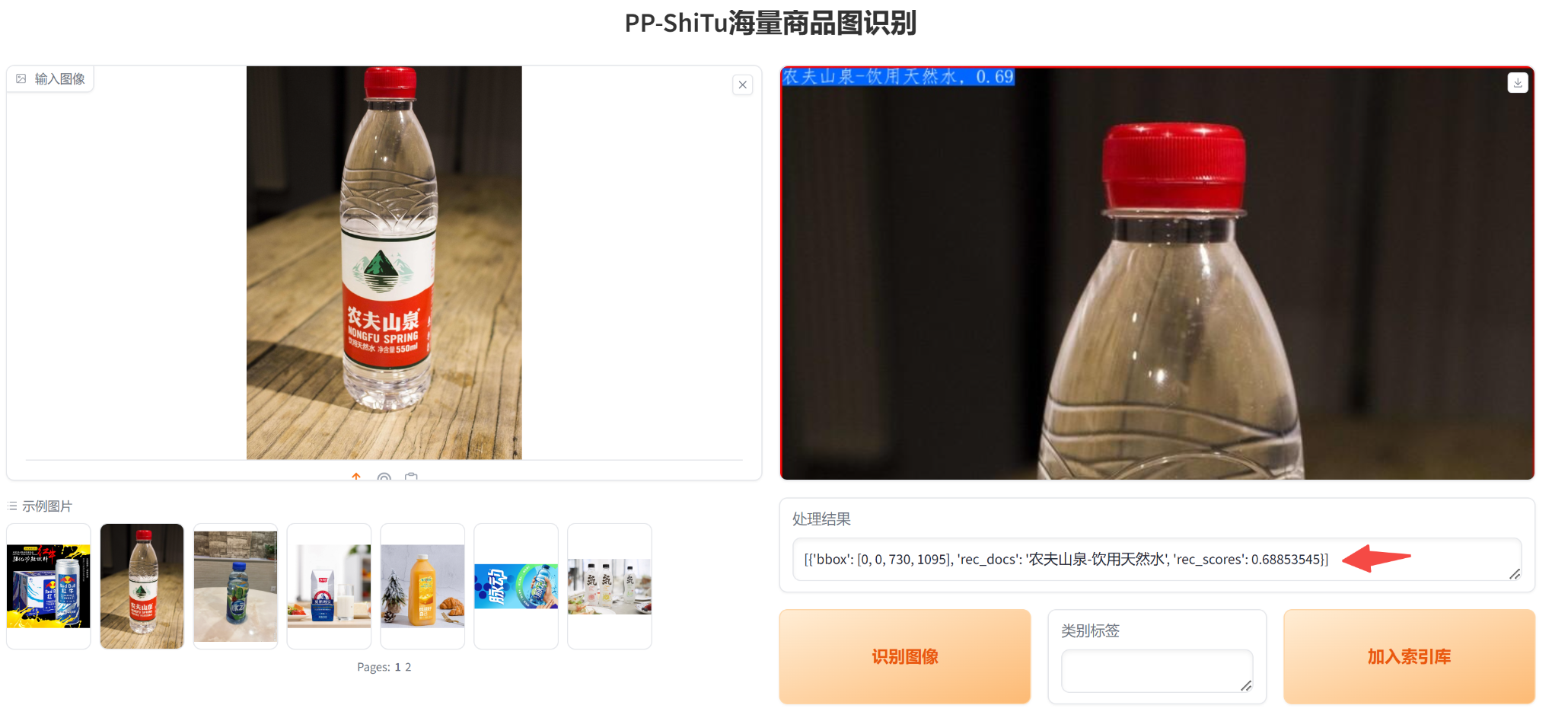
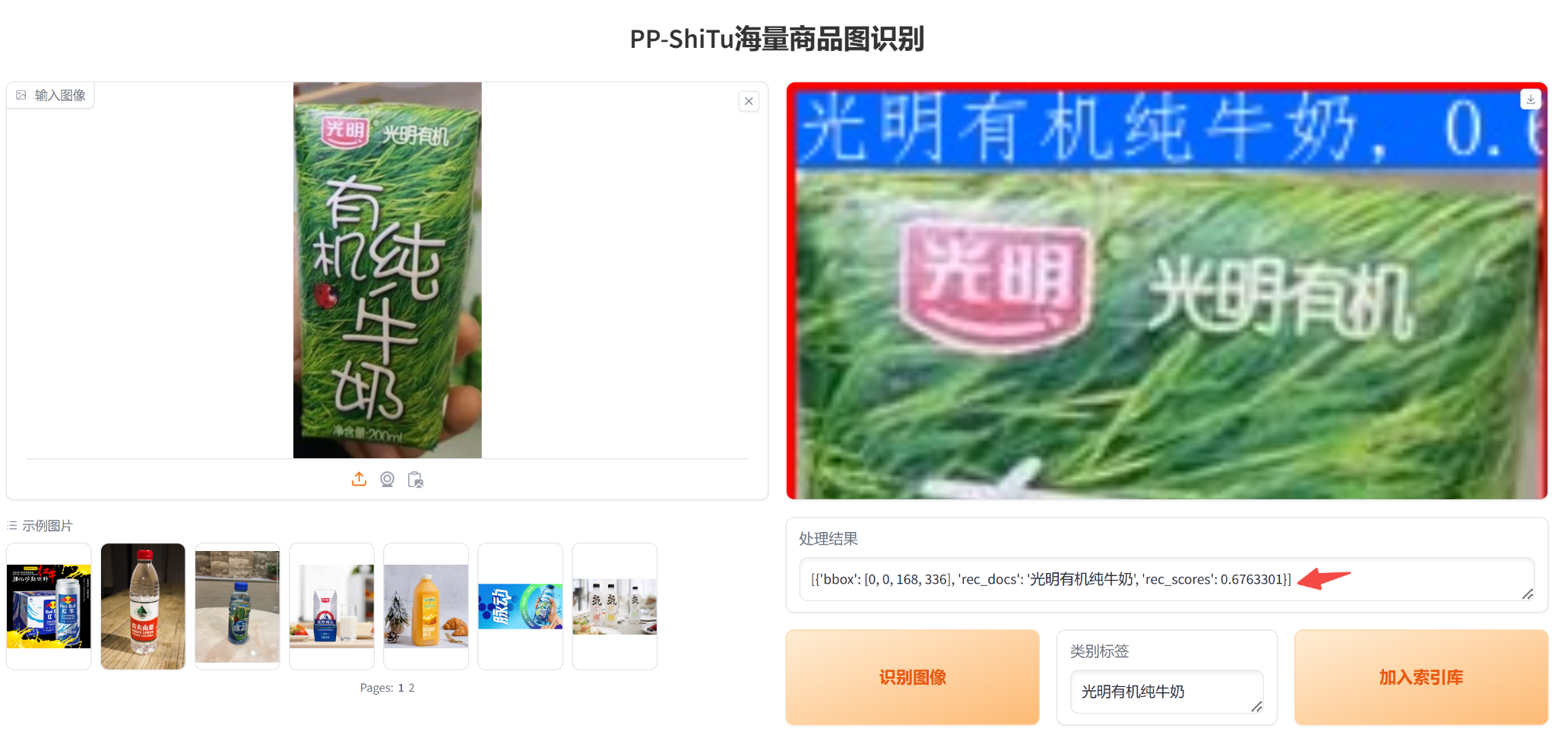
前端我们给出了示例图片,这些示例图片对应的类别基本在我们的索引库都出现过,任意选择一张,然后点击“识别图像”,右侧将展示识别结果。
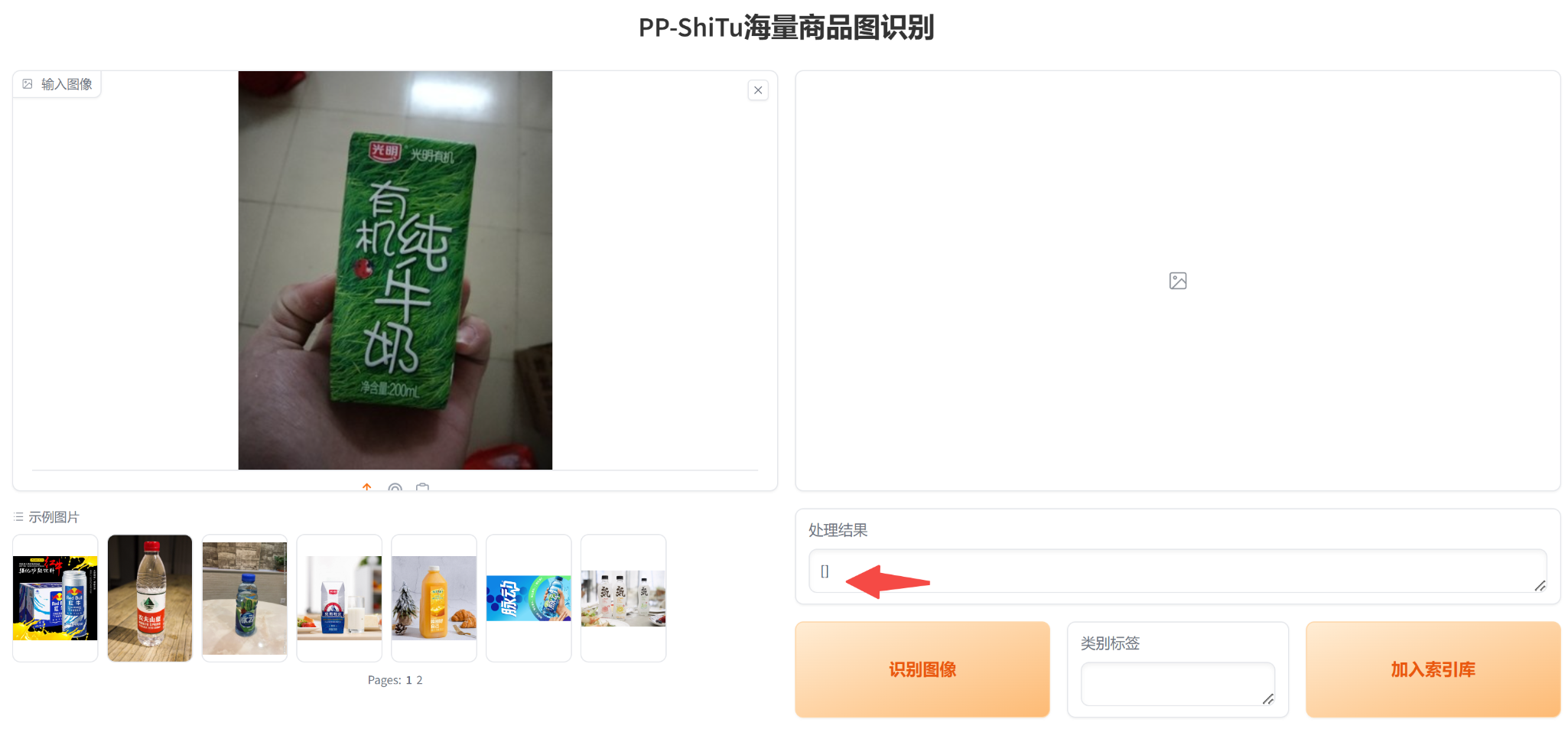
对于未出现在检索库中的类别,当前模型将无法识别出来,如下图所示。
为此,我们可以人工将这张图像对应的类别加入到索引库中。首先在 “类别标签” 中输入你想要命名的类别标签-比如这里的“光明有机纯牛奶”,然后点击“加入索引库”。最后在“处理结果”文本框中显示:当前类别已成功添加到索引库中。
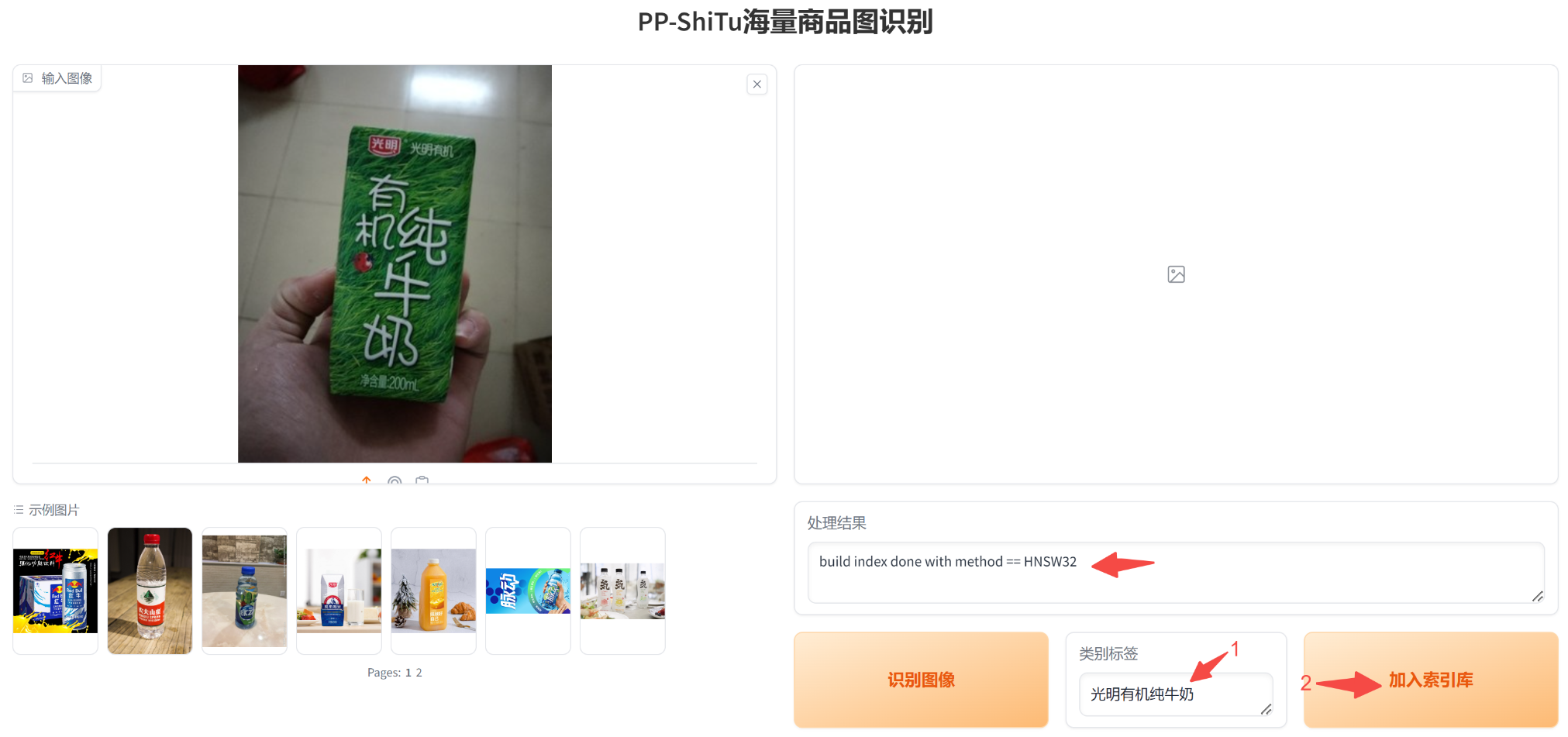
接下来我们再次测试“光明有机纯牛奶”的另一张图像,发现模型已经可以成功搞定了,结果如下图所示,值得注意的是,这里我们不需要再重新训练一个模型:
总结
至此,我们共同走完了一个完整的面向现实场景的商品识别项目,从基础的动手跑通 PP-ShiTu 源码,再到应用搭建,旨在帮助初学者快速入门图像识别相关技术并搭建一个简单的应用。希望能给你带来一点启发,感兴趣的小伙伴可以基于这个项目进一步拓展,实现更多功能和创意。
本系列的后续文章将沿袭这一思路,继续分享更多采用 Paddle 深度学习框架服务产业应用的案例。如果对你有帮助,欢迎 关注 收藏 支持~
往期实战案例:

















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









