







论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
本文主要包含如下内容:
主要思想
YOLO 的核心思想就是利用整张图作为网络的输入,仅仅经过一个 neural network, 直接在输出层回归 bounding box 的位置和 bounding box 所属的类别, 可以直接 end-to-end 的优化。
算法思想
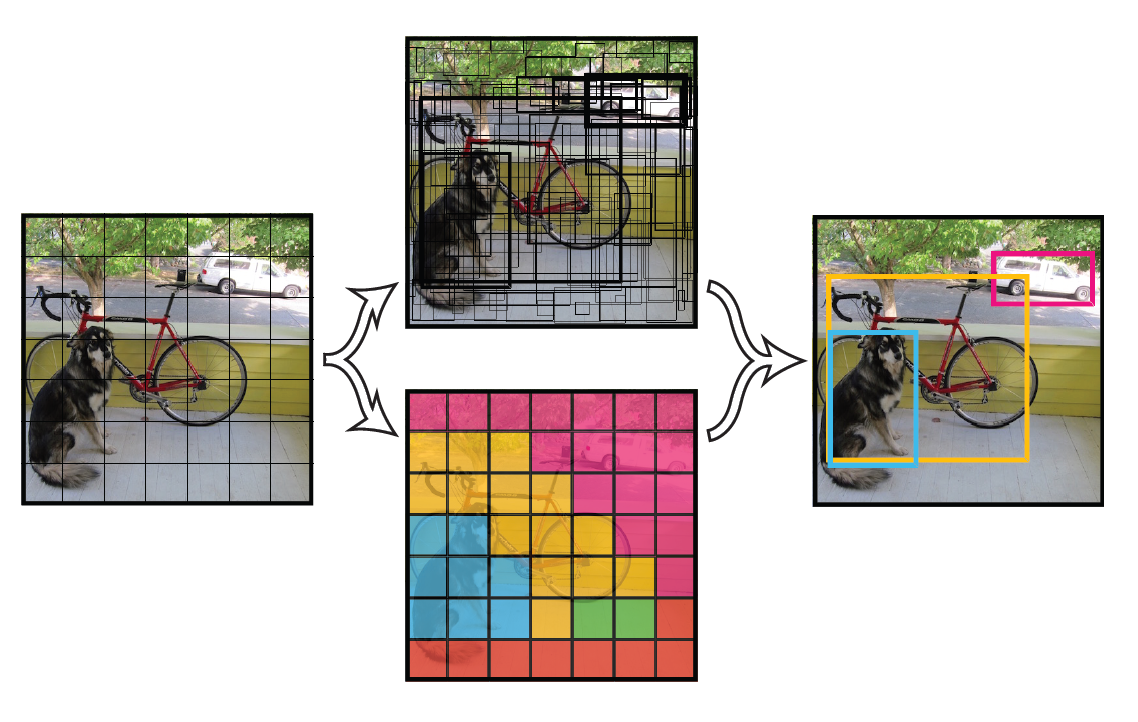
将一幅图像分成 SxS 个网格( grid cell ),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个 object。
每个 grid cell 预测 B 个 bounding box 和其对应的 confidence scores (置信度得分)。这些 confidence scores 反映了 box 含有物体的置信度大小与 box 是否含有物体的概率大小。最后,作者定义置信度为。如果这个 grid cell 中不含有物体,则置信度为0。否则作者希望置信度得分等于预测出的 box 和 ground truth box 的 IOU (交集除以并集)。
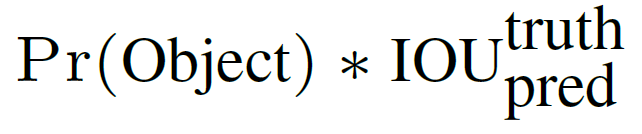
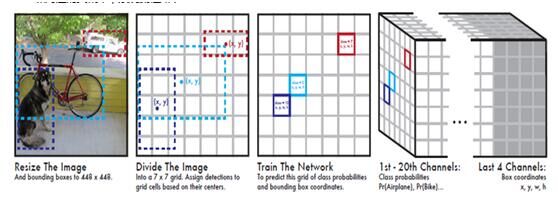
每个 bounding box 包含5个预测值: x,y,w,h 和 confidence。(x,y) 表示相对于 grid cell 边界的 box 中心点坐标。w 和 h 表示相对于整张图片的 box 宽高。最后,confidence 表示预测出的 box 与任一 ground truth box 的 IOU。每个 grid cell 也预测 C 种物体的条件概率,Pr(Classi|Object)。这个概率依托于 grid cell 中是否含有物体概率。不管 boxes B 有多少个,作者只为每个 grid cell 预测物体种类。输出就是 S x S x (5*B+C) 的一个 tensor。
注意:class 信息是针对每个网格的,confidence 信息是针对每个 bounding box 的。
在 test 的时候,每个网格预测的 class 信息和 bounding box 预测的 confidence 信息相乘,就得到每个 bounding box 的 class-specific confidence score:其中,等式左边第一项就是每个网格预测的类别信息,第二三项就是每个 bounding box 预测的 confidence。这个乘积即 encode 了预测的 box 属于某一类的概率,也有该 box 准确度的信息。
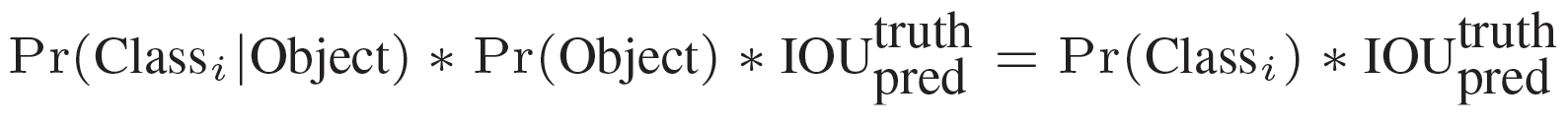
得到每个box 的 class-specific confidence score 以后,设置阈值,滤掉得分低的 boxes,对保留的 boxes 进行 NMS 处理,就得到最终的检测结果。
网络结构

网络训练部分,作者使用 ImageNet 进行初始训练,使用上图中的前20层加一个 maxpooling 层及两个全连接层进行训练,1星期训练得到 top-5error 为88%。
接着,作者在上述网络后面添加了4个卷积网络层和2个全连接层,用于目标检测。这6层刚开始都是随机权值,由于检测需要更为精细的信息,作者将网络输入由224*224调整至448*448,后面这6层就是用于处理回归问题的。
网络的最后一层预测 class 概率和 bounding box,在最后一层使用逻辑激活函数,其他层使用 leaky ReLU:

损失函数
存在问题:
第一,8维的 localization error 和20维的 classification error 同等重要显然是不合理的;
第二,如果一个网格中没有 object(一幅图中这种网格很多),那么就会将这些网格中的 box 的 confidence push 到0,相比于较少的有object的网格,这种做法是 overpowering 的,这会导致网络不稳定甚至发散。
第三, 对不同大小的 box 预测中,相比于大 box 预测偏一点,小 box 预测偏一点肯定更不能被忍受的。
解决办法:
更重视8维的坐标预测,给这些损失前面赋予更大的 loss weight, 记为在 pascal VOC 训练中取5。
对没有 object 的 box 的 confidence loss,赋予小的 loss weight,记为在 pascal VOC 训练中取0.5。
有 object 的 box 的 confidence loss 和类别的 loss 的 loss weight 正常取1。
将 box 的 width 和 height 取平方根代替原本的 height 和 width.
网络输出使用平方和误差,并引入尺度因子 λ 对类概率和 bounding box 的误差进行加权,同时为了反映出偏离在大的 bounding box 中的影响比较小,paper 使用 bounding box 宽高的平方根,最终的损失函数是: 损失函数:

网络缺陷
由于 YOLO 具有极强的空间限制,它限制了模型在邻近物体上的预测,如果两个物体出现在同一个 grid cell 中,模型只能预测一个物体,所以在小物体检测上会出问题。如对于一群鸟儿,这种相邻数量很多,而且又太小的物体,YOLO 难以进行很好的检测。
对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况是。泛化能力偏弱。
由于损失函数的问题,定位误差是影响检测效果的主要原因。loss 函数对大小 bounding box 采取相同的 error 也是个问题。
实验结果
YOLO 的速度提升比较明显,在 voc2007 上的实验结果对比如下:
















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









