







 本文介绍Xception网络,一种基于深度可分离卷积的深度学习模型。该模型在InceptionV3基础上提出,通过深度可分离卷积提升模型效率。文章详细解析了Xception的核心思想、网络结构,并给出了实验结果及TensorFlow实现。
本文介绍Xception网络,一种基于深度可分离卷积的深度学习模型。该模型在InceptionV3基础上提出,通过深度可分离卷积提升模型效率。文章详细解析了Xception的核心思想、网络结构,并给出了实验结果及TensorFlow实现。
论文阅读笔记:Xception: Deep Learning with Depthwise Separable Convolutions
论文下载地址:Xception: DeepLearning with Depthwise Separable Convolutions
本文主要包含如下内容:
核心思想
这篇文章主要在 Inception V3 的基础上提出了 Xception(Extreme Inception),基本思想就是设计了通道分离式卷积 depthwise separable convolution operation
网络结构

我们可以将上面网络看作,把整个输入做1*1卷积,然后切成三段,分别3*3卷积后相连,如下图,两种形式是等价的:

现在我们想,如果不是分成三段,而是分成 5 段或者更多,那模型的表达能力是不是更强呢?于是我们就切更多段,切到不能再切了,正好是 Output channels 的数量(极限版本):

于是,就有了深度卷积 depthwise convolution。文章中将 depthwise separable convolution 分成两步,一步叫depthwise convolution,另一步是 pointwise convolution。深度卷积是对输入的每一个 channel 独立的用对应 channel 的卷积核去卷积,假设卷积核的 shape 是 [filter_height, filter_width, in_channels, channel_multiplier],那么每个 in_channel 会输出 channel_multiplier 那么多个通道,最后的 feature map 就会有 in_channels * channel_multiplier 个通道了。原文在深度卷积后面又加了 pointwise convolution,这个 pointwise convolution 就是 1*1 的卷积,可以看做是对那么多分离的通道做了个融合。
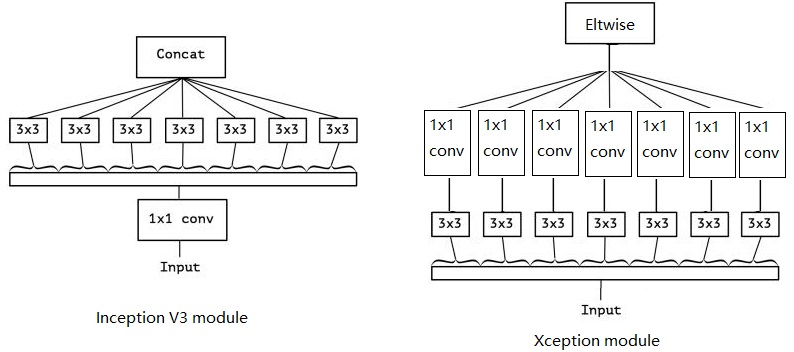
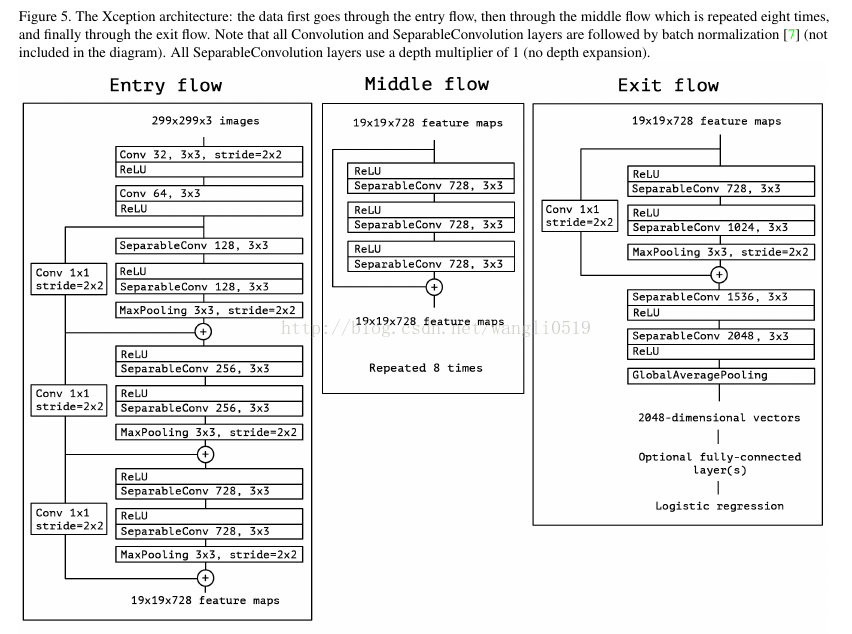
Xception 结构由36个卷积层组成网络的特征提取基础。我们的评估实验中只进行图像分类,因此我们在卷积之后使用了逻辑回归层。可选的,也可以在逻辑回归层之前加入完全连接层。36个卷积层被分成14个模块,除最后一个外,模块间有线性残差连接。


实验结果
精度较Inception V3有提高,ImageNET上的精度如下:
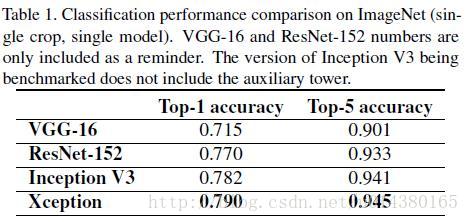
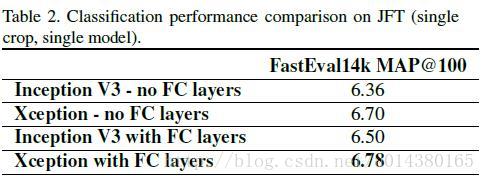
Table2表示几种网络结构在JFT数据集上的对比。大数据上的提升会比Table1好一点。:
tensorflow实现
#tensorflow 1.2.0 python 2.7
tf.nn.depthwise_conv2d(input,filter,strides,padding,rate=None,name=None,data_format=None)
#结果返回一个Tensor,shape为[batch, out_height, out_width, in_channels * channel_multiplier],注意这里输出通道变成了in_channels * channel_multiplier
- name:指定操作的名字
- data_format:指定数据格式
- input:指需要做卷积的输入图像,要求是一个4维Tensor,具有[batch, height, width, in_channels]这样的shape,具体含义是[训练时batch的图片数量, 图片高度, 图片宽度, 图像通道数]
- filter:相当于CNN中的卷积核,要求是一个4维Tensor,具有[filter_height, filter_width, in_channels, channel_multiplier]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,输入通道数,输出卷积乘子],这里第三维in_channels,就是参数input的第四维
- strides:卷积的滑动步长。
- padding:string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同边缘填充方式。
- rate:rate=1时,此时这个函数就变成了普通卷积,并非空洞卷积。
空洞卷积atrous convolutions又名扩张卷积dilated convolutions,向卷积层引入了一个称为 “扩张率dilation rate”的新参数,该参数定义了卷积核处理数据时各值的间距。


















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









