










鸢尾花(iris)数据集
更新时间:2021-03-21 01:01:09标签:数据集 鸢尾花
说明
机器学习教程 正在计划编写中,欢迎大家加微信 sinbam 提供意见、建议、纠错、催更。
鸢【音:yuān】尾花(Iris)是单子叶百合目花卉,是一种比较常见的花,可能不经意间你就能在某个公园里碰见它,而且鸢尾花的品种较多。

它是一个很小的数据集,仅有150行,5列。该数据集的四个特征属性的取值都是数值型的,他们具有相同的量纲,不需要你做任何标准化的处理,第五列为通过前面四列所确定的鸢尾花所属的类别名称。
背景
鸢尾花数据集最初由Edgar Anderson 测量得到,而后在著名的统计学家和生物学家R.A Fisher于1936年发表的文章「The use of multiple measurements in taxonomic problems」中被使用,用其作为线性判别分析(Linear Discriminant Analysis)的一个例子,证明分类的统计方法,从此而被众人所知,尤其是在机器学习这个领域。
数据中的两类鸢尾花记录结果是在加拿大加斯帕半岛上,于同一天的同一个时间段,使用相同的测量仪器,在相同的牧场上由同一个人测量出来的。这是一份有着70年历史的数据,虽然老,但是却很经典,详细数据集可以在UCI 数据库(http://archive.ics.uci.edu/ml/datasets/Iris) 中找到。
简介
Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa(山鸢尾),Versicolour(杂色鸢尾),Virginica(维吉尼亚鸢尾))三个种类中的哪一类。
鸢尾花(iris)数据集,它共有4个属性列和一个品种类别列:sepal length(萼片长度)、sepal width(萼片宽度)、petal length(花瓣长度)、petal width (花瓣宽度),单位都是厘米。3个品种类别是Setosa、Versicolour、Virginica,样本数量150个,每类50个。
数据集详情
鸢尾花数据集共收集了三类鸢尾花,即Setosa鸢尾花、Versicolour鸢尾花和Virginica鸢尾花,每一类鸢尾花收集了50条样本记录,共计150条。
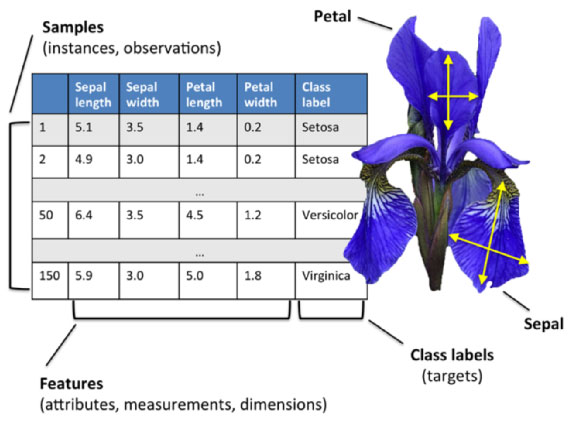
数据集包括4个属性,分别为花萼的长、花萼的宽、花瓣的长和花瓣的宽。对花瓣我们可能比较熟悉,花萼是什么呢?花萼是花冠外面的绿色被叶,在花尚未开放时,保护着花蕾。四个属性的单位都是cm,属于数值变量,四个属性均不存在缺失值的情况,字段如下:
- sepal length(萼片长度)
- sepal width(萼片宽度)
- petal length(花瓣长度)
- petal width (花瓣宽度)
- Species(品种类别):分别是:Setosa、Versicolour、Virginica
单位都是厘米。
盖若
盖若网站提供下载为在线读取,在线地址为:
https://www.gairuo.com/file/data/dataset/iris.data
用 Pandas 的读取方法:
import pandas as pd
url = 'https://www.gairuo.com/file/data/dataset/iris.data'
df = pd.read_csv(url)
df.head()
'''
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 virginica
146 6.3 2.5 5.0 1.9 virginica
147 6.5 3.0 5.2 2.0 virginica
148 6.2 3.4 5.4 2.3 virginica
149 5.9 3.0 5.1 1.8 virginica
[150 rows x 5 columns]
'''
替换列和分类为中文:
url = 'https://www.gairuo.com/file/data/dataset/iris.data'
df = pd.read_csv(url, header=1,
names=['萼片长度', '萼片宽度', '花瓣长度', '花瓣宽度', '品种'])
'''
萼片长度 萼片宽度 花瓣长度 花瓣宽度 品种
33 4.9 3.1 1.5 0.1 setosa
7 4.4 2.9 1.4 0.2 setosa
0 4.9 3.0 1.4 0.2 setosa
148 5.9 3.0 5.1 1.8 virginica
47 5.3 3.7 1.5 0.2 setosa
'''
各库的集成
一此常见的数据科学 Python 库,都集成了鸢尾花(iris)数据集:
sklearn
机器学习库 sklearn 的读取方法为:
from sklearn.datasets import load_iris
data = load_iris()
data.data # 特征
data.target # 标签
seaborn
可视化库 seaborn 的读取方法为:
import seaborn as sns
# 导入鸢尾花数据集
df = sns.load_dataset("iris")
参考
- https://www.jianshu.com/p/6ada344f91ce
- http://archive.ics.uci.edu/ml/datasets/Iris


















 3299
3299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











