








论文标题:TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods
论文链接:https://arxiv.org/pdf/2403.20150.pdf
代码链接:https://github.com/decisionintelligence/TFB
前言
五一过后读的第一篇文章,质量非常高。与以往对时序模型修补、改进类的算法论文不同,TFB这篇文章关注的是整个时间序列领域更高的层面的问题。其实从我开始写文章以来,就陆续收到私信,询问:为什么论文中SOTA的模型,放到我的数据集不work /效果不好/不如线性模型?包括我在kaggle社区也发现,几乎所有的业界时序预测竞赛,大家用XGboost类算法,而非深度学习。
这说明:不同应用领域的数据集与不同时序模型之间其实存在一个内在的Gap,本篇文章就通过对当前时序研究“不规范”、不全面的地方进行系统分析,从数据集、对比方法、评估流程三个方面,构造了一个可插拔的自动化基准。为时序研究人员提供了更全面可用的基准工具集。
当前时序研究框架存在的不足
现有时序研究在整个评估框架上存在的三方面问题:
问题1:数据领域覆盖不足。
不同领域的时间序列可能会表现出多样化的特征。图1a是环境领域的时序数据,呈现出明显的季节性模式。图1b展示了一个经济领域的时间序列,具有明显的增长趋势。图1c是电力领域时序,可以看到在某个时间点数据发生了显著变化,这可能是一个突发事件等。以上这些简单模式只是冰山一角,不同领域的时序可能具有更复杂的模式。因此,仅使用有限的领域会导致时间序列特征的覆盖范围有限,无法提供一个完整的视角。
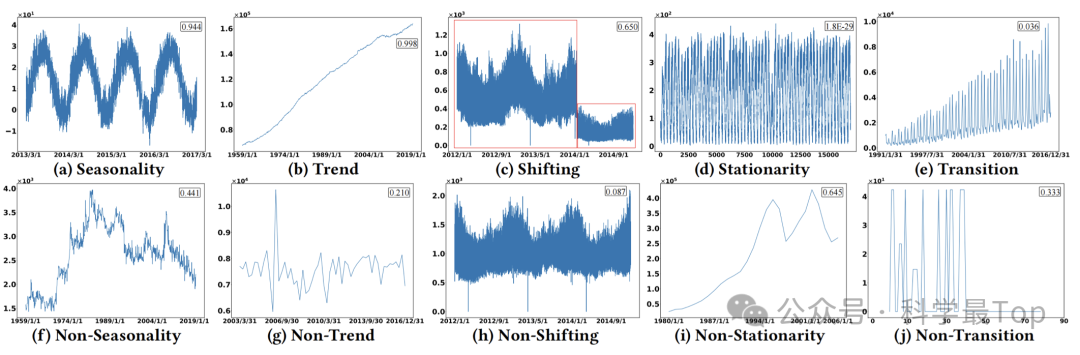
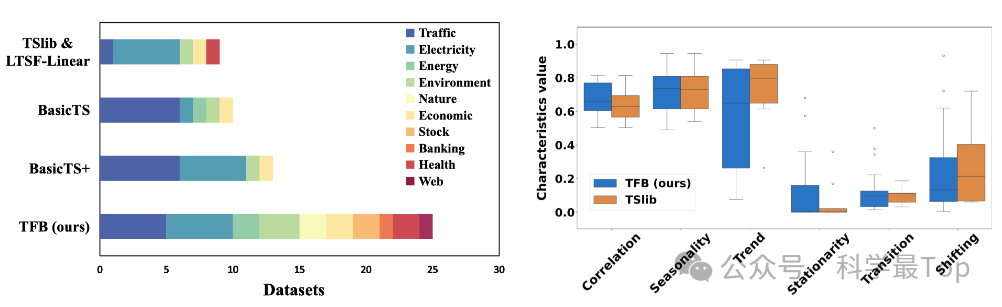
图2总结了现有预测基准测试中使用的多变量数据领域。可以观察到TSlib、LTSF-Linear、BasicTS和BasicTS+只包含了大约10个数据集,覆盖的领域少于或等于5个。而且这些数据集主要集中在交通和电力这两个领域。由于TSlib中的多变量时间序列数据集是最常用的,作者调查了TSlib和TFB中数据集特征值的变化——如下右图。可以观察到TFB数据集在六个特征上的分布比TSlib更加多样化。由此可以认为:扩大领域覆盖范围是有益的,这有助于对方法性能进行更广泛的评估。
问题2:对传统方法的刻板偏见。
作者在不同领域(股票市场、能源、健康)的三个数据集上对VAR、PatchTST、线性回归(LR)、NLinear、FEDformer和Crossformer等方法进行了实验,结果如下表。令人惊讶的是,VAR在股票数据上超越了所有最近提出的最新技术(SOTA)方法,在ILI上也优于FEDformer和Crossformer。此外,LR在Wind上的表现也优于最近提出的最新技术方法。
然而,原始论文的实验却并没有将VAR和LR纳入基线比较,而是假设传统方法无法获得有竞争力的性能!通过比较广泛的方法范围,消除对传统方法的刻板偏见是有益的。

问题3:缺乏一致且灵活的流程。
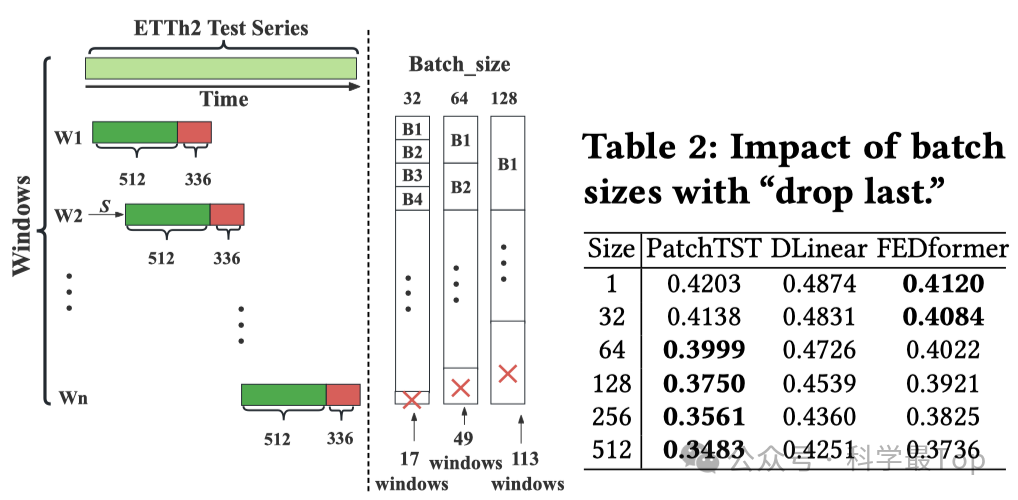
不同方法的性能会随着实验设置的变化而变化,例如,在训练/验证/测试数据之间的划分、归一化方法的选择以及超参数设置的选择。这一部分就是我的上一篇文章想讲的“drop last”的影响,作者详细讨论了当前时序研究"Drop last"带来的对比误差,结果如下图,具体可参考原论文。此外,大多数基准测试中的流程缺乏灵活性,不支持统计学习、机器学习和深度学习方法的同时评估。而确保一个一致且灵活的流程至关重要,这样就可以在相同的设置下进行评估,从而提高发现的公平性。
本文工作
围绕以上问题,作者提出时间序列预测基准(Time series Forecasting Benchmark,TFB),以更全面地跨应用领域和方法对时间序列预测(TSF)方法进行实证评估和比较,并提高评估的公平性。
解决问题1:
根据数据集特征分类方法进行全面的数据集收集,提供多样化的特征,涵盖来自多个领域和复杂设置的时间序列。包含25个多变量和8,068个单变量数据集,其数据格式都是一致的,涵盖了广泛的领域和特性。这一部分作者对单变量、多变量数据集进行细致分析,具体可看原文。
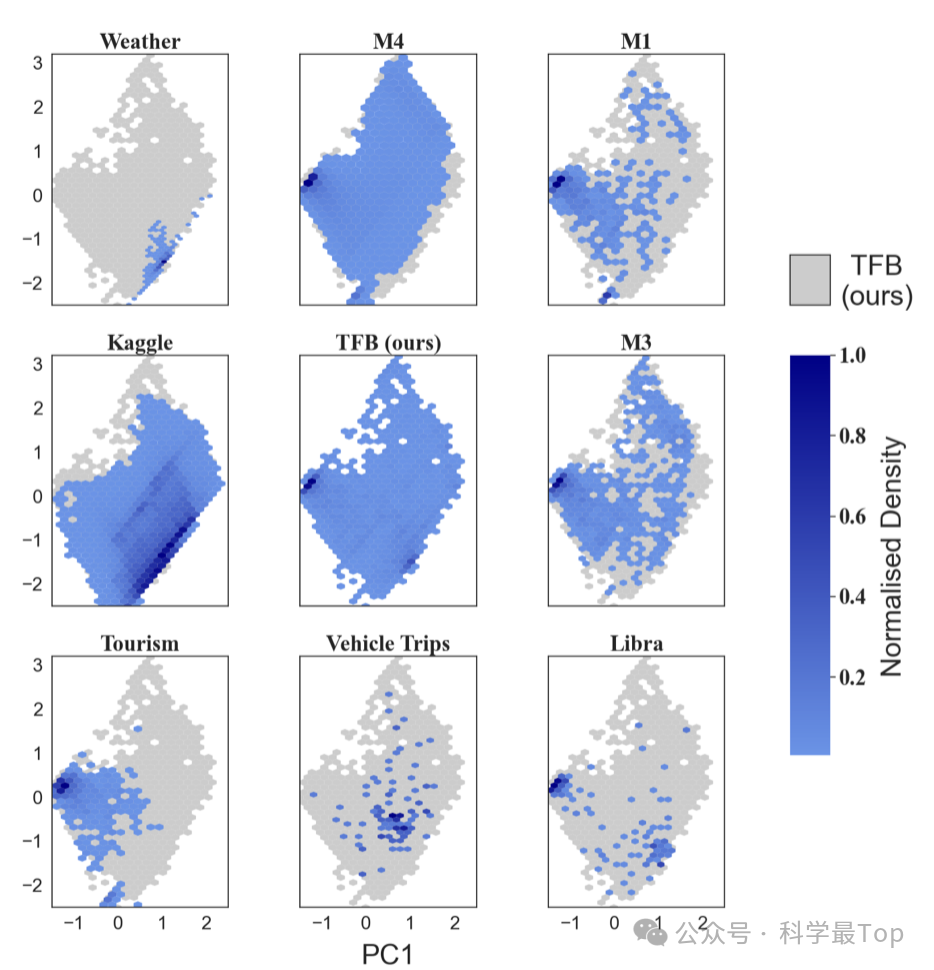
特别是还对数据集的全面性进行讨论。考虑数据的五个特征值:趋势性、季节性、平稳性、漂移性和转移。采用PCA将维度从五维降低到二维,并可视化了八个单变量时间序列数据集。可以看到,TFB和M4覆盖的单元格最多,而其他所有基准相对于TFB都较小。这说明数据集在特征分布多样性方面的覆盖了更广泛的领域。
解决问题2:
如下图,TFB框架扩展了评估策略和指标:包括统计学习、机器学习和深度学习方法,引入多种评估策略和指标,使其更全面地评估模型。
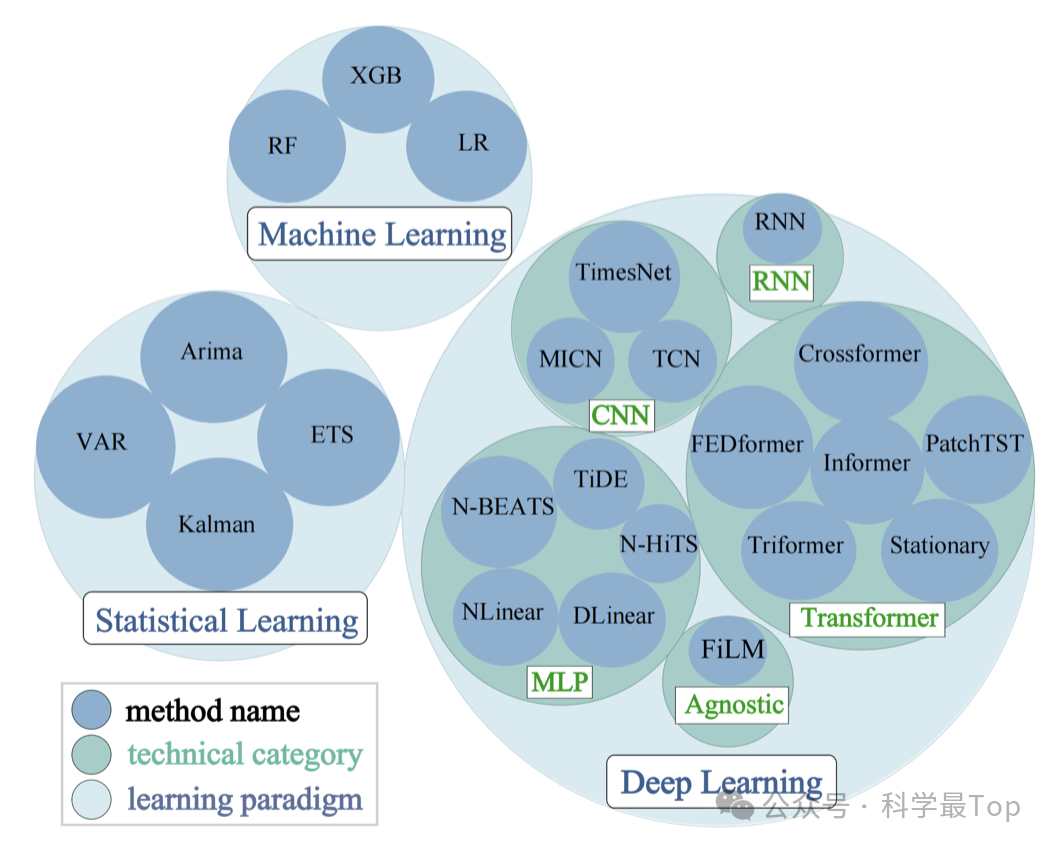
解决问题3:
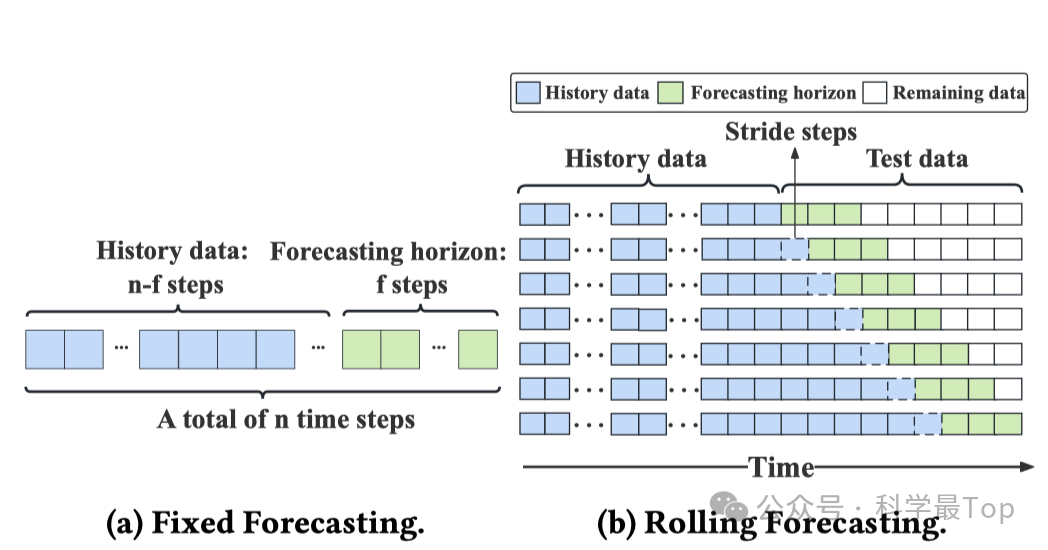
设计灵活且可扩展的评估流程框架,通过统一的流程进行评估,采用一致且标准化的评估策略。包括:固定预测和滚动预测。以及包括MAE、MSE等在内的八种误差度量指标。
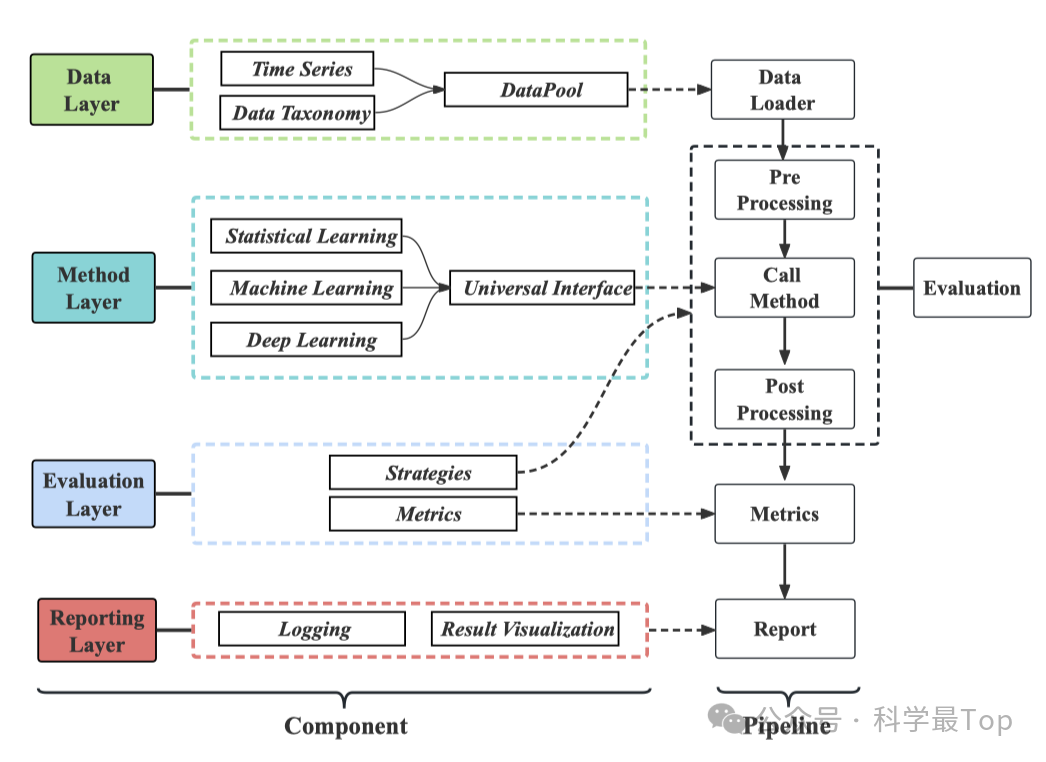
最后,如下图:作者引入了一个统一的评估流程,分为数据层、方法层、评估层和报告层。用户只需在方法层部署他们的方法架构,并选择或配置配置文件,然后TFB就可以自动运行图中的流程。
实验和总结
作者对TFB中包含的所有数据集,包括25个多变量数据集和8,068个单变量时间序列,以及前文提到的所有baseline方法,进行细致的实验分析,限于篇幅不在展示。
我比较关心的一些结论:
-
线性模型在数据集呈增长趋势或具有显著漂移时表现出色。这可以归因于线性模型的线性建模能力,使其能够很好地捕捉线性趋势和漂移。
-
Transformer方法在展现明显季节性、平稳性和非线性模式,以及更明显模式或内在相似性的数据集上优于线性方法。这种优越性可能源于Transformer方法增强的非线性建模能力。
Anaway,没有适合所有数据集的模型,要根据具体情况选择。本文给出的数据集,以及构建的一整套训练框架对于模型效果评估验证是很好的。
大家一定要关注我的公众号【科学最top】,第一时间follow时序高水平论文解读!!!
















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









