









引言
在机器学习领域,分类问题是常见的任务之一。当我们面对的问题不仅限于两类分类(如正例和反例),而是需要处理多个类别时,就会遇到多类分类问题。例如,在手写数字识别中,我们需要将输入图像分类为0到9中的一个数字。解决这类问题的方法有很多种,其中一种流行且有效的方法是使用One-vs-All (OvA) 策略。
多分类问题举例:
- 鸾尾花数据集:山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)
- 电子邮件分类:工作邮件、朋友邮件、家庭邮件、爱好邮件
- 医疗图表(medical diagrams):没有生病、着凉、感冒
- 天气:晴天、多云、雨、雪
一 One-vs-All 策略简介
One-vs-All 策略是一种将多类分类问题转化为一系列二分类问题的方法。对于N个类别的分类问题,OvA 方法会构建N个二分类器,每个分类器负责区分一个类别与其他所有类别。具体来说:
- 构建分类器:对于第k个类别,训练一个二分类模型来识别该类别(正例)与所有其他类别(负例)。
- 预测阶段:当新的数据点到达时,将其输入到所有的N个分类器中,并选择输出分数最高的那个分类器所对应的类别作为最终预测结果。
这种方法的优点在于可以利用现有的二分类算法来处理多类分类问题,而不需要对算法本身进行任何修改。此外,它还能够为每个类提供独立的概率估计,这对于某些应用场景是非常有用的。
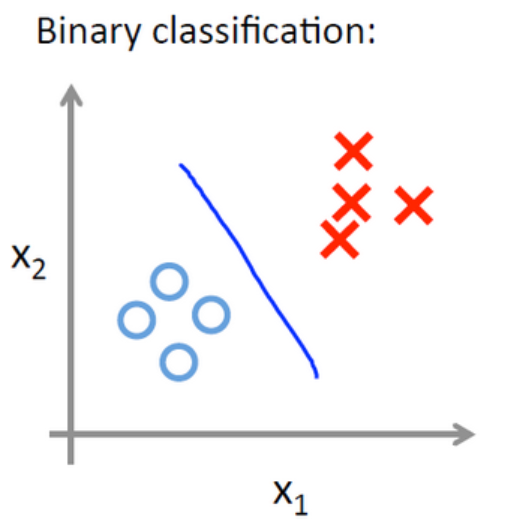
二分类问题如下图所示:
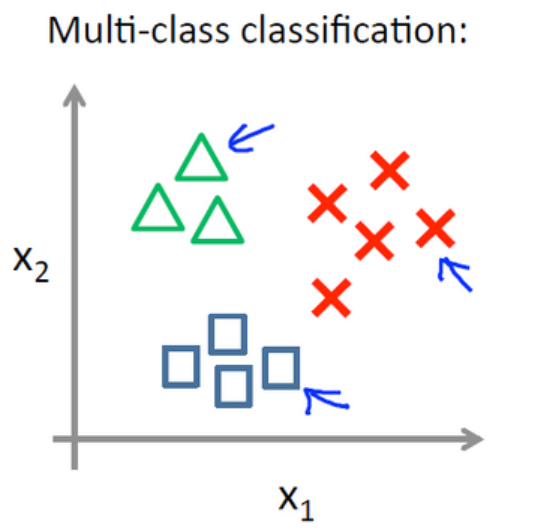
多分类问题如下图所示:
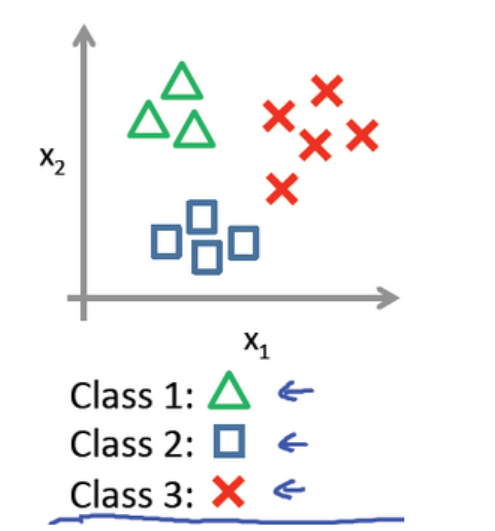
对于多分类问题,可以将其看成二分类问题:保留其中的一个类,剩下的作为另一个类。例如,洗浴下面这个例子:
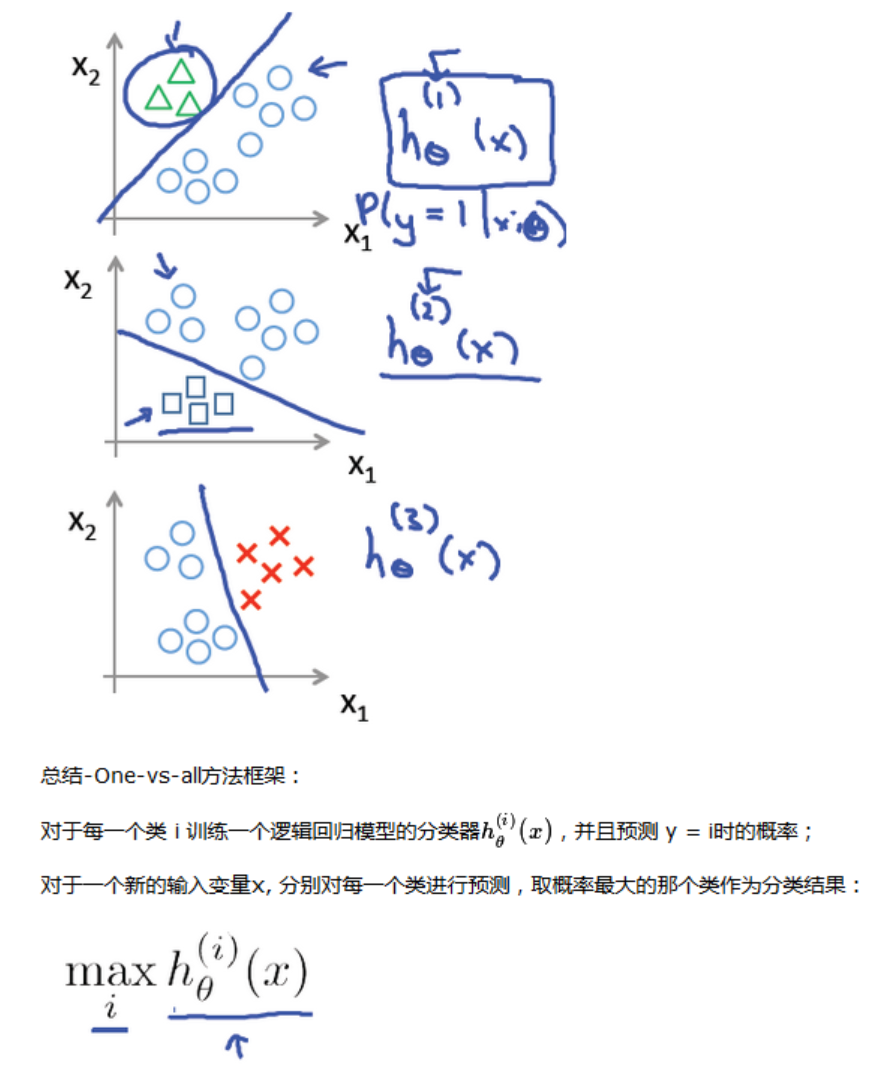
可以分别计算其中一个类别相对于其他类别的概率:
二 OvA 的实现步骤
2.1 训练过程
- 准备数据:首先,确保您的数据已经正确地划分为训练集和测试集。
- 定义分类器:选择一个合适的二分类器算法,例如逻辑回归、支持向量机等。
- 训练分类器:对于每个类别k(从1到N),创建一个分类器并用标记为k的数据点作为正例,其余所有数据点作为负例进行训练。
- 保存模型:为了后续使用,确保保存每个训练好的分类器。
2.2 预测过程
- 加载模型:加载之前训练好的所有分类器。
- 运行预测:将待分类的新样本分别输入到每个分类器中。
- 决策规则:根据各个分类器的输出,选择得分最高或概率最大的分类器对应的类别作为最终预测。
三 示例代码
3.1 OneVsRestClassifier实现
这里提供一个简单的 Python 示例,使用 scikit-learn 库实现 OvA 策略:
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.multiclass import OneVsRestClassifier
from sklearn.metrics import accuracy_score
# 加载数据
data = load_iris()
X, y = data.data, data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用逻辑回归作为基分类器,并通过OneVsRestClassifier实现OvA
classifier = OneVsRestClassifier(LogisticRegression())
classifier.fit(X_train, y_train)
# 进行预测
y_pred = classifier.predict(X_test)
# 输出准确率
print("Accuracy:", accuracy_score(y_test, y_pred))
3.2 LogisticRegression自带多分类实现
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.multiclass import OneVsRestClassifier
from sklearn.metrics import accuracy_score
# 加载数据
data = load_iris()
X, y = data.data, data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用逻辑回归中的默认多分类实现
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
# 进行预测
y_pred = classifier.predict(X_test)
# 输出准确率
print("Accuracy:", accuracy_score(y_test, y_pred))



















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











