







上一节我们介绍了梯度下降算法,这里我们会将梯度下降算法和代价函数相结合,最小化我们的代价函数。下面是关于公示的推导部分(自己推)。
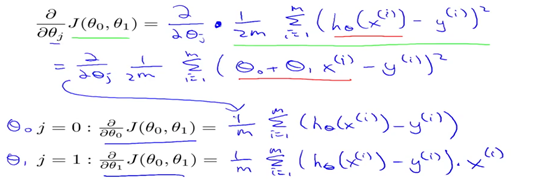
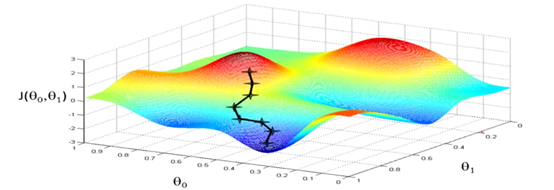
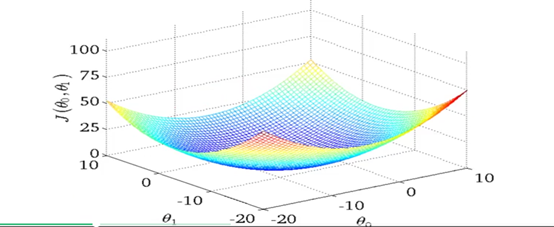
让我们看看梯度下降算法是怎么工作的???当我们第一次展示梯度下降算法的时候,我们展示过下面这张图,在表面上,不断下降 ,并且我们知道 ,根据你的不同的初始化值,你会得到不同的局部最优解。但是事实表明,用于线性回归的代价函数,通常是如下面第二张图这样的。你可以发现,这种函数没有局部最优解,只有一个全局的最优解。在这种代价函数上使用梯度下降算法得到的一定是全局最优解,因为不存在局部最优解。
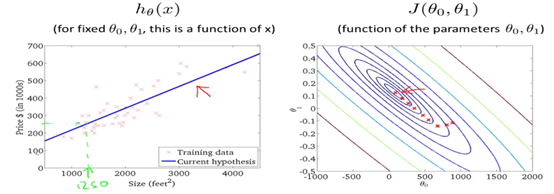
现在让我们看看算法的执行流程,如下图所示。我们有一个假设函数以及一个代价函数。通常我们初始化我们的参数为0,如图所示,对应的假设函数如图左边所示。

随着梯度下降算法的运行,代价函数会越来越接近最小值点,对应的假设函数也将会越来越拟合数据。如下图所示。红色叉叉表示梯度下降过程。
最终我们得到了假设函数,就可以使用它来进行房价预测了。
下面给出梯度下降算法的另一个名字,Batch Gradient Descent。寻找最优解的每一步都是使用所有的训练数据,因为我们可以发现在梯度下降的公式中都是使用的求和项。当然,也有一些梯度下降算法不使用所有的训练数据,可能只是使用一小部分,后面我们会介绍。

最小化代价函数不一定要使用梯度下降算法,还有另一种算法,我们称他为normal equation method,梯度下降算法更加适用于大的数据集。















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









