






导语
大型语言模型(LLMs)现在已成为代码生成的重要工具。然而,这些模型面临一个关键挑战:如何确保一次性生成的代码具有高质量。传统方法依赖于生成多个代码样本并从中选择最佳选项,但这种方法往往忽略了代码执行的实际结果。为应对这一挑战,本文提出了一种“Self-Debugging”的方法。该方法赋予LLMs自我调试能力,使它们能够基于自己生成的代码执行结果来不断进行调试和优化,从而显著提升代码质量和性能。
Self-Debugging的核心创新在于模拟人类程序员的调试过程,使模型不仅能生成代码,还能自行识别和修正错误,而无需人类的直接指导。这种方法在多个代码生成领域实现了前所未有的性能,特别是在缺乏单元测试的复杂任务中表现突出。
- 论文标题:《Teaching Large Language Models to Self Debug》
- 链接:https://arxiv.org/abs/2304.05128
1 简介
代码生成一直是一个长期存在的挑战,应用范围广泛,包括从自然语言到代码的合成、示例编程以及代码翻译。近期的大型语言模型在这一领域取得了显著的进步,但对于复杂的编程任务,一次性生成正确的代码依然具有挑战性。因此,一些研究通过设计程序修复方法来改善代码生成的性能。即使是人类程序员,第一次尝试写出的代码也不一定准确。与其完全放弃错误代码,人们通常会检查代码并调查执行结果,然后进行更改以解决实现错误。因此,先前的工作提出了深度学习技术来修复预测的代码。
本文提出了名为“Self-Debugging”的方法,通过少量示例教授大型语言模型自我调试预测的代码。与以往依赖人类反馈的代码修复方法不同,Self-Debugging教导模型通过检查执行结果并自行解释代码来识别实现错误。这个过程类似于人类程序员进行的橡皮鸭调试,即向橡皮鸭逐行解释代码以提高调试效率,而无需专家指导。
在多种模型上评估了Self-Debugging的性能,包括code-davinci-002、gpt-3.5-turbo、gpt-4以及StarCoder。Self-Debugging在多种代码生成任务上实现了最先进的性能。特别是在Spider基准测试(文本到SQL生成)中,Self-Debugging通过代码解释一致提高了基线性能,并在最复杂的SQL查询上提高了预测准确率9%。在TransCoder(代码翻译)和MBPP(文本到Python生成)上,使用单元测试结合代码解释可将准确度提高高达12%,而单纯的代码解释也能提高代码翻译性能2-3%。同时,Self-Debugging提高了样本效率,能与采样量是其10倍以上的基线模型匹敌或超越。

2 用于代码生成的提示方法
Few-shot prompting:这种提示方法通过提供几个输入-输出示例来指导语言模型解决任务。以文本到SQL生成为例,少数示例提示在感兴趣的问题前附加一系列(问题,SQL)对,使得模型在被要求预测给定提示的后续token时,会遵循提示格式生成SQL查询。此外,可以选择性地在提示中添加指令,提供高层次的任务描述。例如,在Self-Debugging提示的前两步中,都以要求模型生成解释的指令开头。
基于执行的代码选择:先前的工作显示,解码多个样本可以显著提高大型语言模型的性能。特别是对于代码生成任务,可以利用代码执行来选择最终预测。一些工作通过执行结果的多数投票来选择最终预测,而其他工作设计了重新排序方案以提高性能。在本研究中,当有多个预测时,遵循第一种方法,选择在不遇到执行错误的情况下最频繁执行结果的预测代码,然后对该代码应用Self-Debugging。
单元测试:一些代码生成任务伴随着单元测试来指定程序执行行为。特别是,单元测试是一组输入-输出对,程序P通过单元测试当且仅当 P ( i k ) = o k P(i_k ) = o_k P(ik)=ok,对于所有 k ∈ 1 , . . . , K k ∈ { 1, ..., K } k∈1,...,K。当问题描述中呈现单元测试时,会在执行基于多数投票之前过滤掉未通过单元测试的程序。
3 Self-Debug 框架
如图1所示,Self-Debugging框架使用预训练的大型语言模型进行迭代调试,而无需对其进行微调。Self-Debugging的一轮调试包括三个步骤:生成(Generation)、解释(Explanation)和反馈(Feedback)。
- 生成:根据问题描述,模型预测候选程序。
- 解释:模型被提示以语义上有用的方式处理预测,例如用自然语言解释预测,或为预测代码的样本输入创建执行轨迹。
- 反馈:生成关于预测代码正确性的反馈信息。这可以通过询问模型本身确定,或从单元测试中外部生成。
当反馈信息表明预测是正确的,或达到最大允许的调试轮次时,调试过程终止。
实际中,一轮Self-Debugging不总是包括上述所有步骤。下面讨论可以自动获取和生成的不同类型的反馈。
- 简单反馈:自动反馈的最简单形式是一句仅指示代码正确性的话,没有更详细的信息,省略了完整Self-Debugging轮次中的解释步骤。
- 单元测试反馈(UT):对于问题描述包含单元测试的代码生成任务,除了利用代码执行来检查代码正确性,还可以在反馈中纳入执行结果,为调试提供更丰富的信息。
- 代码解释反馈(Expl):提出通过解释生成的代码来进行Self-Debugging。这个调试过程类似于小黄鸭调试法,程序员通过逐行向小黄鸭解释代码进行调试。作者观察到,当单元测试不可用时,大型语言模型也可以从小黄鸭调试中受益。
- 执行轨迹反馈(Trace):除了解释代码本身,程序员通常通过模拟执行过程来理解代码的语义含义。因此,当单元测试可用时,检查另一种解释反馈格式,即指导LLM逐行解释中间执行步骤。

4 应用
4.1 文本到SQL生成
文本到SQL任务的目标是根据问题和数据库信息生成相应的SQL查询。由于没有单元测试,模型需要通过解释预测的代码来辨别错误并证明代码正确性。在Spider基准的开发集上评估Self-Debugging,发现仅包含简单反馈的少数示例提示对准确预测SQL正确性是不足的。Self-Debugging的调试过程包括三个步骤:首先,提示模型总结问题并推断问题所需的返回类型;其次,执行SQL查询并将返回的表格添加到模型输入中进行代码解释;最后,模型比较推断的SQL解释和问题描述,然后预测当前SQL查询的正确性。

4.2 代码翻译
在代码翻译任务中,目标是将一种编程语言的代码翻译成另一种语言。使用TransCoder数据集进行实验,该数据集包含不同编程语言的并行函数以及单元测试。评估Self-Debugging在C++到Python翻译上的性能,仅在预测的Python代码未通过所有单元测试时应用Self-Debugging。迭代应用Self-Debugging,直到预测的Python代码通过所有单元测试或达到最大调试轮次。

4.3 文本到Python
此外,还在问题描述中仅展示部分单元测试的设置下评估Self-Debugging,这是编码作业和竞赛中常见的设置。特别地,在MBPP测试集上进行评估,该测试集包含500个Python问题,每个问题有3个单元测试。模型仍需推断代码正确性,即使预测的代码通过了给定的单元测试。完整的提示在附录G中提供。

5 实验
5.1 主要结果
模型比较:在Spider基准上对Self-Debugging进行了评估,与特别为文本到SQL生成训练的T5-3B模型和基于执行的重排序方法进行了比较。Self-Debugging在Codex上一致提高了性能。
不同反馈格式的比较:在Spider基准测试中,由于没有单元测试,简单反馈无法显著提升性能。在TransCoder和MBPP基准上,至少有一个单元测试可用,即使执行信息未在反馈信息中呈现,简单反馈仍可改善模型预测。在所有任务上,当执行信息出现在反馈中时,模型通常受益于更丰富的反馈。
不同LLMs的比较:虽然GPT-4在许多任务上比前代GPT模型表现更强,但在Spider上,其初始SQL生成和Self-Debugging性能比Codex差。GPT-4在MBPP上的初始Python代码生成性能显著优于Codex和GPT-3.5。StarCoder虽然基线性能不如GPT模型,但在MBPP上,Self-Debugging带来了显著的性能提升。


5.2 消融实验
5.2.1 Self-Debugging提高样本效率
在Spider上,应用Self-Debugging到贪婪解码生成的预测与使用16个样本的基线准确度相匹配。在其他基准上也观察到类似的样本效率提升。

5.2.2 代码执行的重要性
默认情况下,当可行时,Self-Debugging利用单元测试执行。在Transcoder和MBPP上,未涉及代码执行的Self-Debugging场景表明,模型需要完全依赖自身来推断代码正确性。结果显示,尽管有执行轨迹反馈,但没有单元测试执行时,GPT-4在MBPP上的准确度提升了3.6%,在其他基准上提升约1%。

5.2.3 Self-Debugging如何改进性能
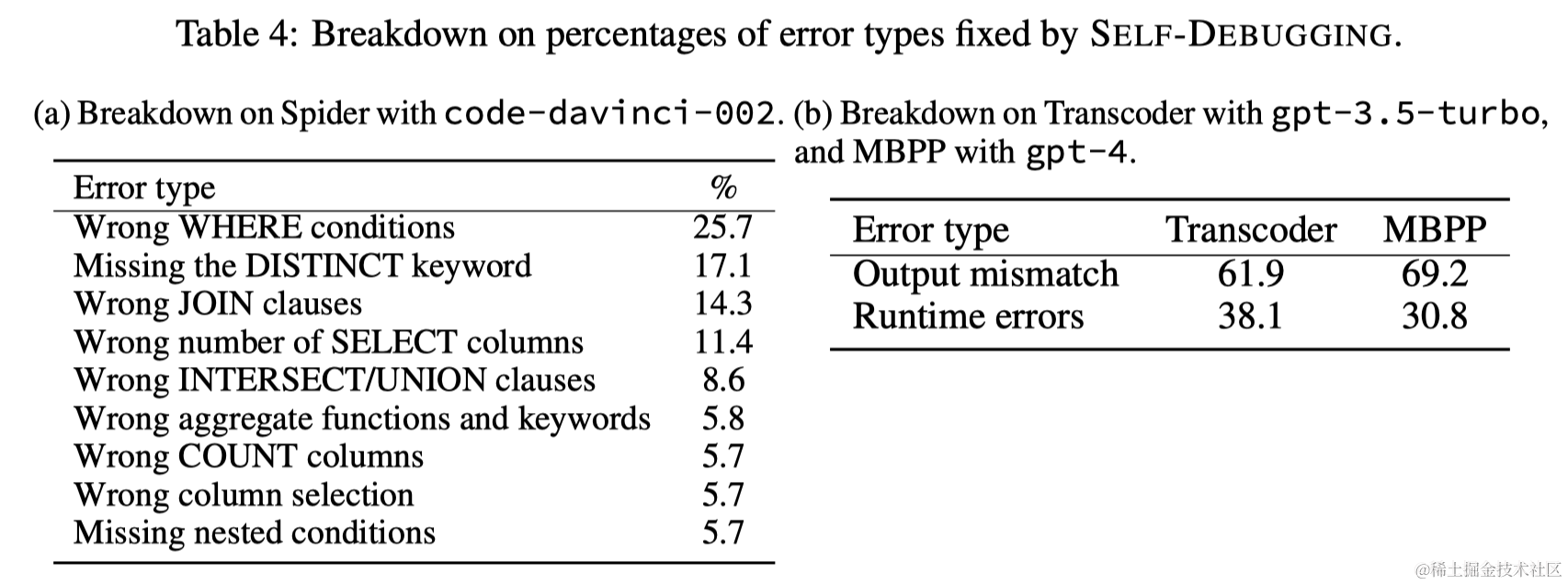
Self-Debugging在困难问题上取得更显著的改进。特别是在极难问题上,Self-Debugging提高了准确度9%。通过代码解释,Self-Debugging帮助LLM识别问题和预测SQL查询之间的不一致,从而提升了更复杂任务的准确度。
6 相关工作
略
7 总结
本文介绍了Self-Debugging,一种使大型语言模型能够自我调试其生成的代码的方法。特别地,本文展示了Self-Debugging赋予模型进行小黄鸭调试的能力,使得模型无需人类指导即可识别和修复错误。在多个代码生成领域,Self-Debugging实现了最先进的性能,并显著提高了样本效率。在没有单元测试的文本到SQL生成任务中,利用代码解释的Self-Debugging一致提高了基线2-3%,并在最难的问题上提供了9%的性能提升。对于有单元测试的代码翻译和文本到Python生成任务,Self-Debugging将基线准确率提高了高达12%。
本工作突出了通过教授大型语言模型迭代调试自己的预测来提高编码性能的潜力,而不是要求模型从零开始生成正确的代码。Self-Debugging指导模型理解代码、识别错误,并遵循错误信息修复错误。作者认为提高模型执行这些步骤的能力是重要的未来工作。特别是,假设更好的代码解释能力会导致更好的调试性能。一个方向是指导模型在其解释中更好地描述代码的高层语义含义以及实现细节。另一个方向是在模型反馈中包含额外的调试信息,如潜在错误的描述。初步结果表明,关于语义错误的模型生成的反馈信息在逐行代码解释之上没有提供额外的好处,未来的工作可以探索预测更具信息性错误信息的技术。















 1195
1195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









