







导语
phi-系列模型是微软研究团队推出的轻量级人工智能模型,旨在实现“小而精”的目标,能够实现在低功耗设备上例如智能手机和平板电脑上部署运行。截止目前,已经发布到了phi-3模型,接下来的几篇博客将沿着最初的phi-1到phi-1.5,再到phi-2和phi-3模型展开介绍,本文介绍最初的phi-1模型。
- 标题:Textbooks Are All You Need
- 链接:https://arxiv.org/pdf/2306.11644.pdf
1 简介
深度学习领域对缩放定律(Scaling Law)的探索导致了现有大语言模型(LLM)性能的迅速提升。本文探索了另一个可以改进的方向:数据的质量。 Eldan 和 Li 最近在 TinyStories(一个高质量的合成数据集,用于教导神经网络英语)上的工作表明,高质量数据可以显著改变缩放定律的形态,潜在地使得可以用更精简的训练/模型来达到大规模模型的性能。本文展示了高质量数据甚至可以改进大型语言模型 (LLMs) 的最先进水平,同时大幅减小数据集规模和训练计算。重要的是,需要较少训练的较小模型可以显著降低LLMs的成本。
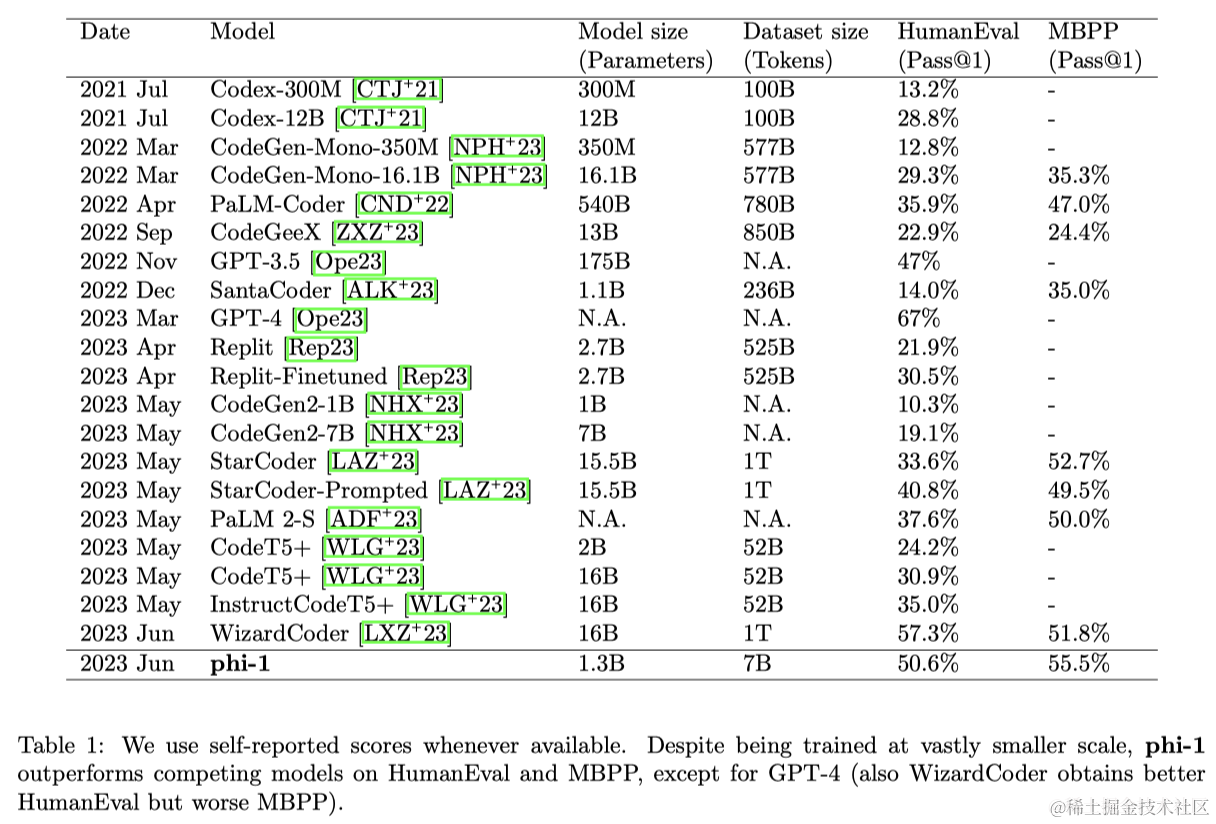
本文关注于代码训练的LLMs(Code LLMs)上,即从文档字符串中编写简单的Python函数,通过训练一个包含13亿参数的模型(称之为phi-1),大约进行了8次遍历,每次处理了7B词元(即token,总共约为50B词元),然后对不到200M词元进行微调,来展示高质量数据在打破现有缩放定律方面的威力。粗略地说,本文在“教科书质量”数据上进行预训练,包括合成生成的数据(使用GPT-3.5)和来自网络来源的过滤数据,并在“教科书练习类”数据上进行微调。尽管在数据集和模型大小方面与竞争模型相比要小几个数量级(表1),但在HumanEval上达到了50.6%的Pass@1准确率,在MBPP上达到了55.5%的Pass@1准确率。
文章后续组织如下:第2节提供了训练过程的一些细节,并讨论了数据选择过程在实现这一结果方面的重要性的证据。此外,尽管与现有模型相比,phi-1在训练的词元数量要少得多,但仍显示出涌现能力(emergent properties)。第3节中讨论了这些涌现能力,特别是通过将phi-1的输出与phi-1-small(使用相同流程但只有350M参数的模型)的输出进行比较,作者确认了参数数量在 emergent 中起到了关键作用。第4节中,讨论了评估模型的替代基准。第5节研究了训练数据可能与HumanEval存在的污染。
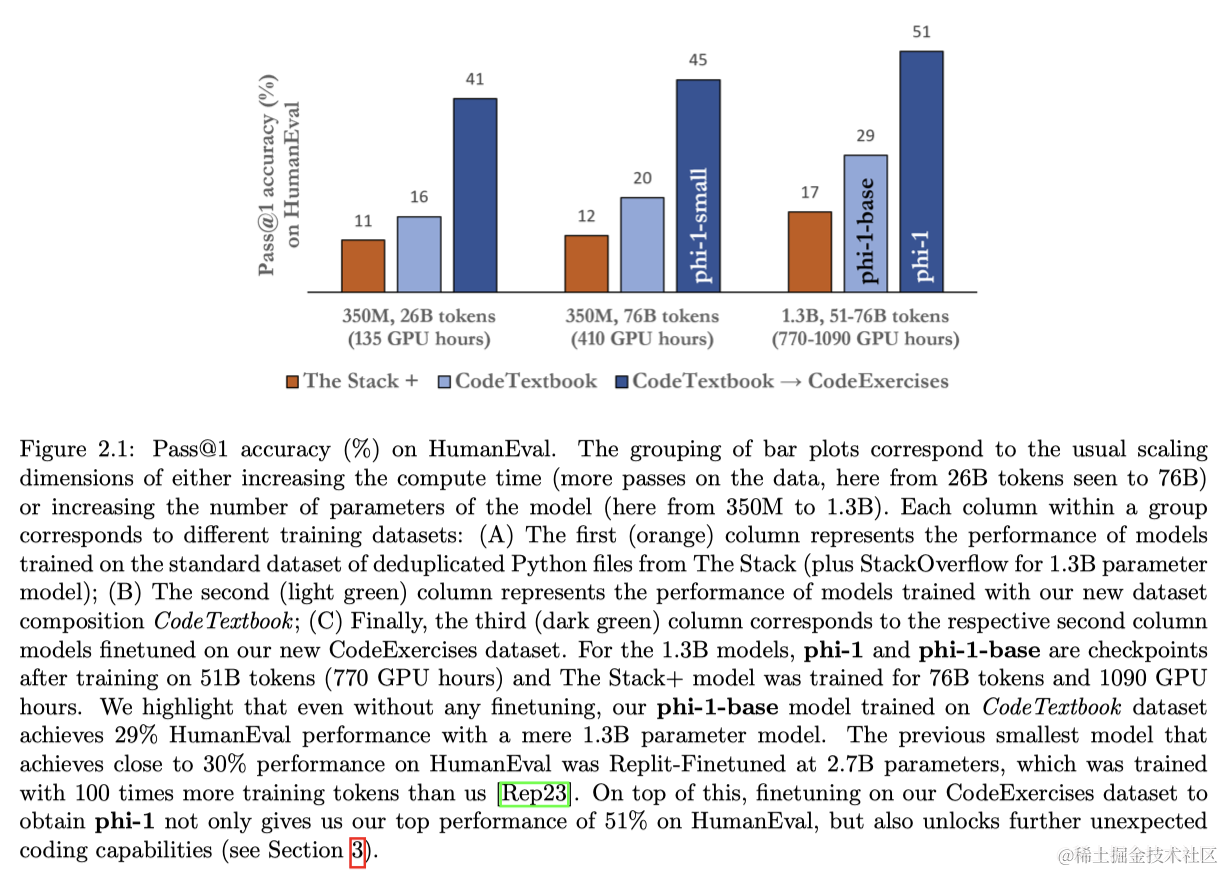
2 训练细节与高质量数据的重要性
本文的核心要素依赖于教科书质量的训练数据。与以往使用标准文本数据进行代码生成的工作不同,例如The Stack(包含仓库源代码和其他基于网络的数据集,例如StackOverflow和CodeContes
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









