






导语
phi-系列模型是微软研究团队推出的轻量级人工智能模型,旨在实现“小而精”的目标,能够实现在低功耗设备上例如智能手机和平板电脑上部署运行。截止目前,已经发布到了phi-3模型,本系列博客将沿着最初的phi-1到phi-1.5,再到phi-2和phi-3模型展开介绍,本文介绍最新的phi-3模型。
- 标题:Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
- 链接:https://arxiv.org/abs/2404.14219
摘要
本文介绍Phi-3-mini模型,拥有3.8B参数且训练样本为3.3T词元(token),其整体性能与Mixtral 8x7B和GPT-3.5等模型相媲美。Phi-3的创新完全体现在用于训练的数据集上,是phi-2所使用数据集的扩大版本,由严格筛选的网络数据和合成数据组成。该模型还进一步针对健壮性、安全性和聊天格式进行了调整。本文还提供了一些初始的参数缩放结果,使用了为4.8T词元训练的7B和14B模型,分别称为phi-3-small和phi-3-medium,两者都比phi-3-mini更加强大。
1 简介
近年人工智能的显著进步很大程度上归因于不断扩大规模的模型和数据集,大型语言模型(LLMs)的规模从仅五年前的十亿参数逐步增加到今天的万亿参数。这种努力的动力源于通过训练大型模型获得的看似可预测的改进,即所谓的缩放定律。然而,这些定律假定了一个“固定”的数据源。现在,这一假设受到了前沿LLMs自身的显著干扰,这些模型使研究者能够以新颖的方式与数据进行交互。在之前关于phi模型的工作中展示了基于LLM对网络数据进行过滤以及LLM创建的合成数据的组合,使较小的语言模型的性能达到了通常只在更大型模型中才能看到的水平。例如,之前的模型使用了这种数据配方,phi-2(2.7B),其性能与常规数据训练的25倍大型模型相匹配。本报告介绍了一个新模型,phi-3-mini(3.8B),在phi-2中使用的数据集的更大、更先进版本上训练了3.3T词元。由于其小规模,phi-3-mini可以轻松在现代手机上进行本地推理,但其质量似乎与Mixtral 8x7B和GPT-3.5等模型相当。

2 技术规格
Phi-3-mini模型是一个Transformer解码器架构,其默认上下文长度为4K,作者还通过LongRope引入了一个长上下文版本,将上下文长度扩展到128K,称为phi-3-mini-128K。
为最大程度地造福开源社区,phi-3-mini建立在与Llama-2相似的块结构之上,并使用了相同的分词器,词汇量为32064。这意味着为Llama-2系列模型开发的所有软件包都可以直接适用于phi-3-mini。该模型使用3072隐藏维度、32个头和32层。使用BF16训练了总共3.3T个词元。该模型已经进行了聊天微调,聊天模板如下:

Phi-3-small模型(7B参数)利用了tiktoken分词器(用于更好的多语言分词),词汇量为100352,并具有默认的上下文长度8K。它遵循标准的7B模型类的Transformer架构,具有32层和隐藏维度为4096。为了最小化KV缓存占用,该模型还利用了分组查询注意力,其中4个查询共享1个键。此外,phi-3-small还使用了密集注意力和新颖的块稀疏注意力的替代层,以进一步优化KV缓存节省,同时保持长上下文检索性能。此模型还使用了额外的10%多语言数据。
在手机上本地运行的高性能语言模型
由于其小尺寸,phi-3-mini可以量化为4位,因此仅占用约1.8GB的内存。作者通过在搭载A16仿生芯片的iPhone 14上本地运行phi-3-mini并完全脱机部署(图1),测试了量化模型,达到每秒12个词元以上。
训练方法
遵循“Textbooks Are All You Need”中开始的一系列工作,利用高质量的训练数据来提高小型语言模型的性能,并偏离了标准的缩放定律。本文表明这种方法可以使总参数仅为3.8B的模型达到与GPT-3.5或Mixtral等高性能模型相当的水平(例如Mixtral的总参数为45B)。本文训练数据由来自各种开放互联网源的严格筛选的网络数据(根据“教育水平”)以及合成LLM生成的数据组成。预训练分为两个不相交且顺序的阶段;第一阶段主要包括网络源,旨在向模型传授一般知识和语言理解能力。第二阶段将更严格筛选的网络数据(第一阶段使用的子集)与一些教授模型逻辑推理和各种专业技能的合成数据相结合。
数据最优模式
与以往将语言模型训练在“计算最优模式”或“过度训练模式”的方法不同,本文主要关注给定规模下数据的质量。作者试图将训练数据校准为更接近于“数据最优”模式的状态以适应小型模型。特别是,筛选网络数据以包含正确的“知识水平”,并保留更多可能提高模型“推理能力”的网页。例如,某一天英超联赛的比赛结果可能是前沿模型的良好训练数据,但本文需要删除此类信息,以留下更多的模型容量用于小型模型的“推理”。Phi-3与Llama-2比较如图2所示。

为在更大型的模型上测试本文的数据,作者还训练了phi-3-medium,这是一个拥有14B参数的模型,采用了与phi-3-mini相同的分词器和架构,并在稍多的轮次(总共4.8T词元,与phi-3-small相同)上使用相同的数据进行训练。该模型具有40个头和40个层,嵌入维度为5120。可以观察到,一些基准从7B到14B的改进程度远不及从3.8B到7B的改进程度,这可能表明本文的数据混合需要进一步工作才能适应14B参数模型的“数据最优模式”。作者仍在积极调查其中的一些基准(包括对HumanEval的回归),因此phi-3-medium的表现应被视为“预览”。
后训练(Post-training)
Phi-3-mini的后训练经历了两个阶段,包括监督微调(SFT)和直接偏好优化(DPO)。SFT利用了跨多个领域的高度精心策划的高质量数据,例如数学、编码、推理、对话、模型身份和安全性。SFT数据混合从使用仅英文示例开始。DPO数据涵盖了聊天格式数据、推理和负责任的AI(RAI)工作。作者使用DPO来引导模型远离不良行为,通过将这些输出用作“拒绝”响应。除了在数学、编码、推理、健壮性和安全性方面的改进外,后期训练还将语言模型转变为用户可以高效且安全地与之交互的AI助手。
作为后训练过程的一部分,作者开发了一个长上下文版本的phi-3-mini,将上下文长度限制扩大到128K而不是4K。总体而言,128K模型的质量与4K长度版本相当,同时能够处理长上下文任务。长上下文扩展分为两个阶段,包括长上下文中期训练和长短混合后期训练,两者都包括SFT和DPO。
3 学术基准
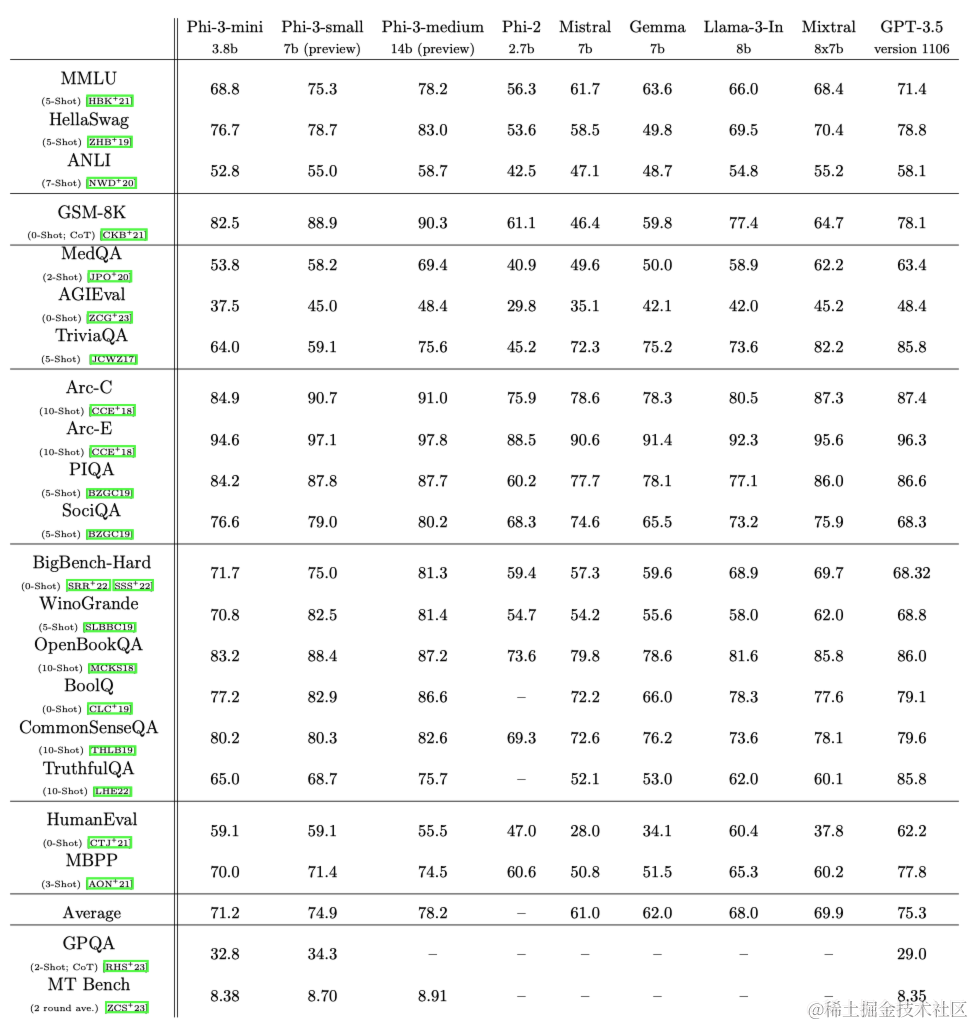
phi-3-mini在标准开源基准上的结果如下,这些基准用于衡量模型的推理能力(包括常识推理和逻辑推理)。
4 安全性
Phi-3-mini的开发符合微软的负责任人工智能原则。总体方法包括在后期训练中进行安全对齐、红队测试、自动化测试和评估,涵盖了数十种负责任人工智能危害类别。作者利用了可帮助和无害的偏好数据集以及多个内部生成的数据集,并进行修改,以应对安全后期训练中的负责任人工智能危害类别。微软的一个独立红队在后期训练过程中对phi-3-mini进行了迭代检查,以进一步确定改进的方向。根据他们的反馈,本文策划了额外的数据集,以解决他们的见解,从而完善了后期训练数据集。这个过程导致了有害响应率的显著降低,如图3所示。
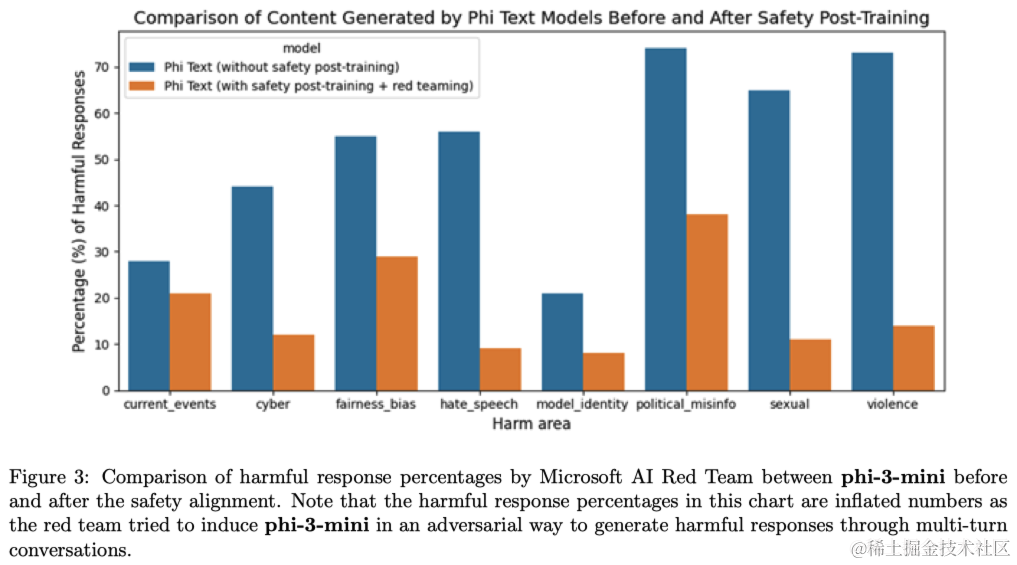
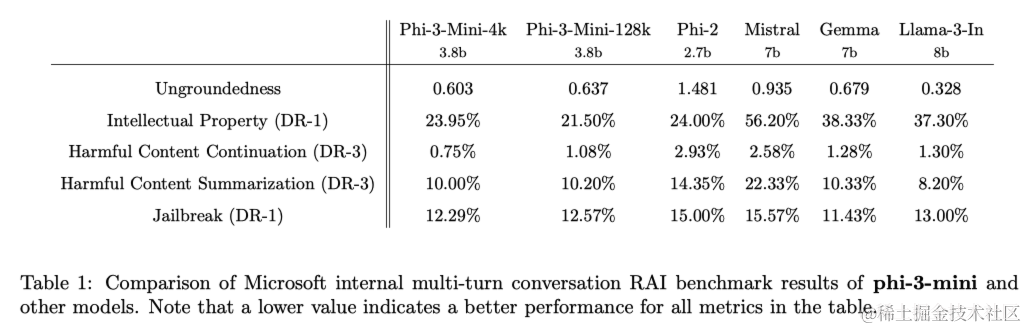
表1显示了针对phi-3-mini-4k和phi-3-mini-128k的内部负责任人工智能基准测试结果。该基准测试利用了GPT-4来模拟五个不同类别的多轮对话,并评估模型的响应。在0(完全基于事实)和4(不基于事实)之间的非基于事实性衡量了响应中的信息是否基于给定提示。在其他类别中,根据有害性严重程度从0(无害)到7(极端有害)评估响应,并计算缺陷率(DR-x)作为具有严重程度分数大于或等于x的样本的百分比。

5 弱点
在语言模型的能力方面,虽然phi-3-mini模型在语言理解和推理能力上达到了与规模更大的模型相似的水平,但对于某些任务来说,它仍然基本受到其大小的限制。例如,该模型在TriviaQA上的表现较差,这可以看出它简单地没有足够的容量来存储过多的“事实知识”。作者相信通过与搜索引擎的增强可以解决这种弱点。图4中展示了使用HuggingFace默认的Chat-UI与phi-3-mini的示例。与模型容量相关的另一个弱点是,目前主要将语言限制在英语上。探索小型语言模型的多语言能力是未来研究方向。
尽管作者进行了认真的负责任人工智能努力,但与大多数语言模型一样,仍然存在关于事实不准确(或幻觉)、偏见的再现或放大、不恰当的内容生成和安全问题的挑战。精心策划的训练数据的使用,以及针对性的后期训练,以及来自红队洞见的改进,显著减轻了所有维度上的这些问题。然而,要完全解决这些挑战仍然需要大量工作。















 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









