






前言
如何微调deepseek-r1-1.5B模型,修改模型的自我认知部分
比如想微调一个自己模型,我问他你是谁开发的,要让他回答这个模型是由我们公司独立研发的,这种该怎么实现呢?
原来:

微调后的效果:

其实有两种办法,可以修改模型的自我认知部分
-
第一种最常见的就是对模型不用做任何操作,在我们输入的时候增加提示词,明确的告诉大模型我要你扮演一个什么角色,你不能回复跟角色无关的东西。比如:在每次向大模型输入prompt的时候,多带一段文本:你是zibiao公司开发的人工智能语言模型 Talk-Bot。 Talk-Bot就是你的名字。你是zibiao公司创建的AI。你是一个名为 Talk-Bot的人工智能模型。。就类似这样,全给它灌进去,俗称:提示词工程
-
第二种也是比较复杂的,对模型微调,让模型按照我们的数据集进行回复(这篇文章主要讲的)
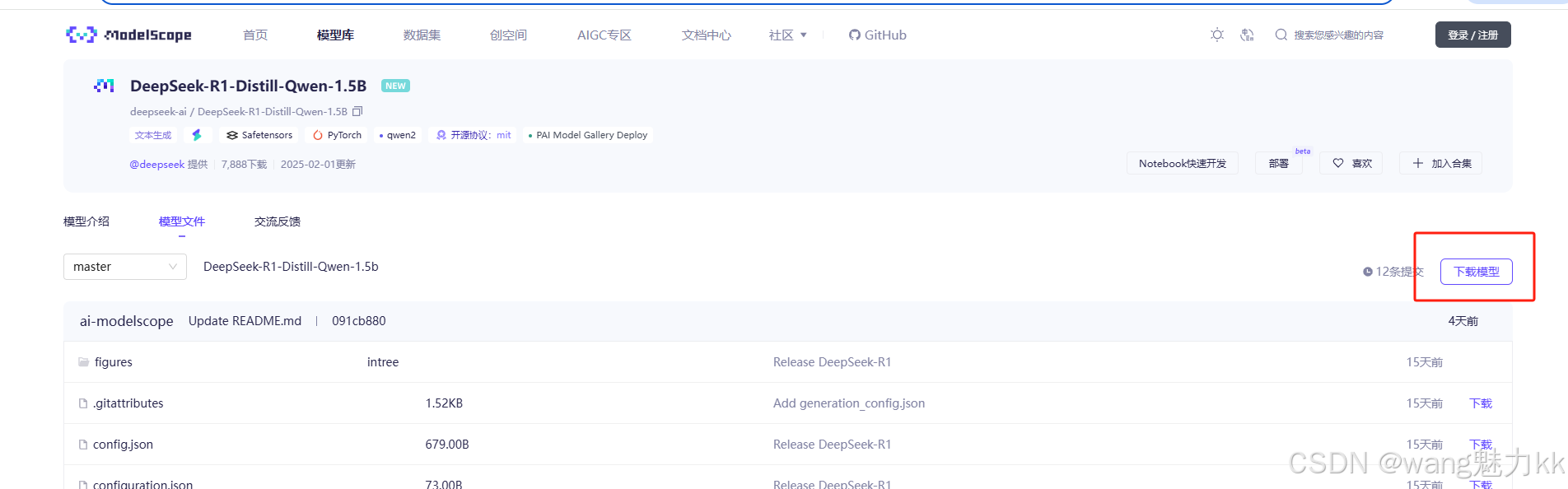
下载DeepSeek-R1-1.5B-Distill模型
安装LLaMA-Factory
使用LLaMA-Factory微调大模型
安装方法参考官方文档,也可以网上百度,有很多,这里不在多说
安装后启动
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
conda activate llama_factory
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
nohup python src/webui.py > train_web.log 2>&1 &
LLaMA-Factory微调配置
这里直接使用原有的identity文件微调
替换原LLaMA-Factory\data\identity.json文件中:{{name}} 为 Talk-Bot,{{author}} 为 zibiao
最终修改文件为:数据集
访问:http://localhost:7860
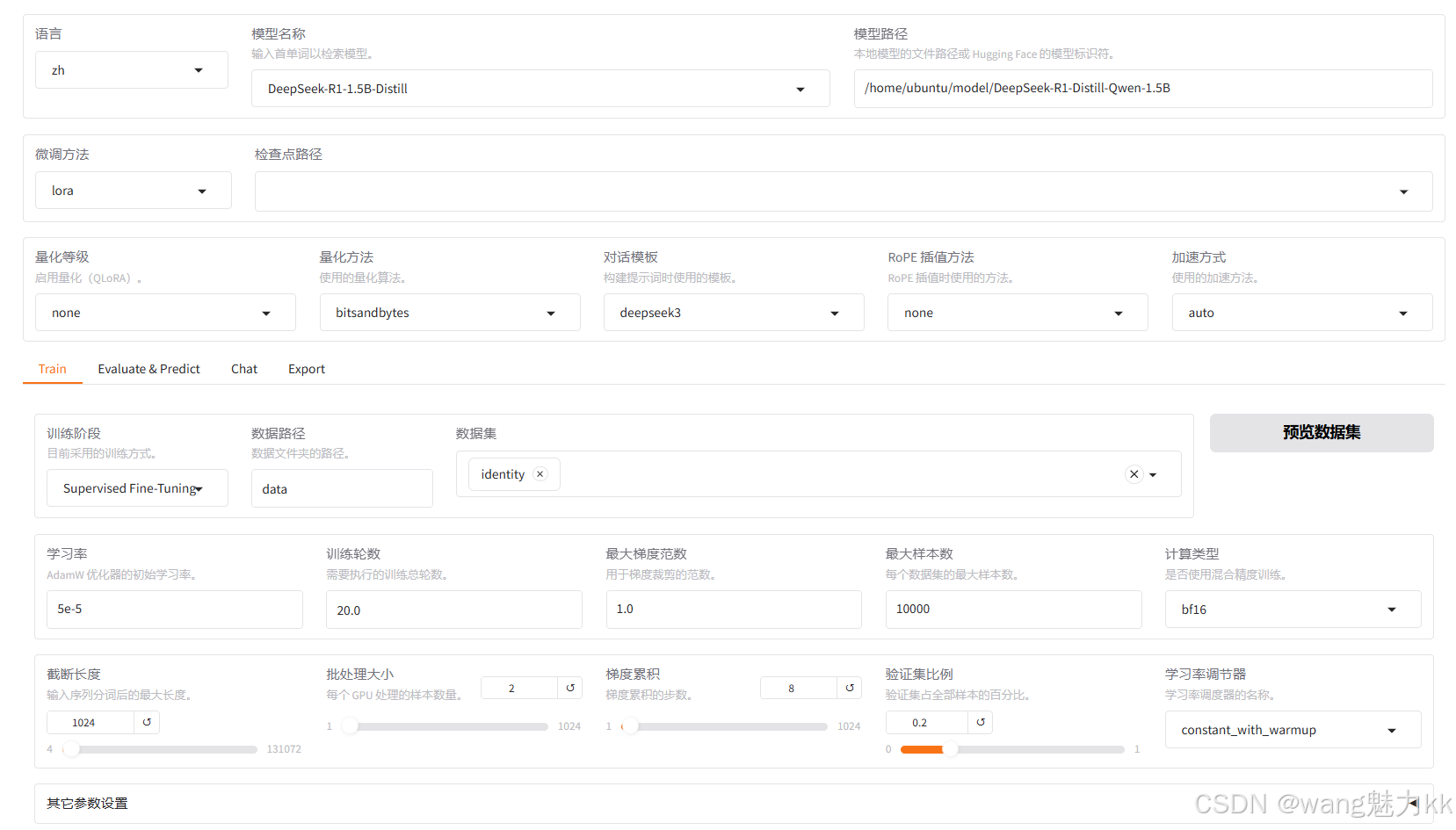
对话模板选择deepseek3,官方有说明
学习率调节器都可以测试下,不同的学习率调节器对效果影响很大
Linear:学习率以线性方式逐渐减小,通常用于训练初期到后期的平滑过渡。
Cosine:学习率遵循余弦衰减函数,学习率在训练过程中呈现周期性的变化,适合于需要多次循环优化的场景。
Cosine Restart:在余弦衰减的基础上引入重启机制,允许学习率在一定周期后恢复到较高值,从而使模型在局部最优解中跳出。
Polynomial:学习率按照多项式函数递减,可以通过设置多项式的阶数来控制衰减的速率和形状。
Constant:保持学习率不变,适合简单任务或预训练模型的微调。
Constant with Warmup:在训练开始时使用固定的学习率,然后逐步增加到目标学习率,以避免初始阶段的震荡。
Inverse Sqrt:学习率与训练步数的平方根的倒数成正比,常用于一些特定的任务,如Transformer模型的训练。
Reduce LR on Plateau:当验证集的性能停止提高时,自动降低学习率,这样可以在模型收敛困难时进行调整。
Cosine with Min LR:类似于余弦衰减,但设置了一个最小学习率,保证学习率不会下降到某个阈值以下。
Warmup Stable Decay:结合了warmup步骤和稳定的衰减阶段,为模型提供一个平稳的学习率调整过程。
显存小的,建议适当把梯度累积缩小下,我用cpu训练的时候,梯度累积设置太高,训练经常到一半就出错
验证集比例也可适当的调整,但是不易设置过大
预览数据集文件identity
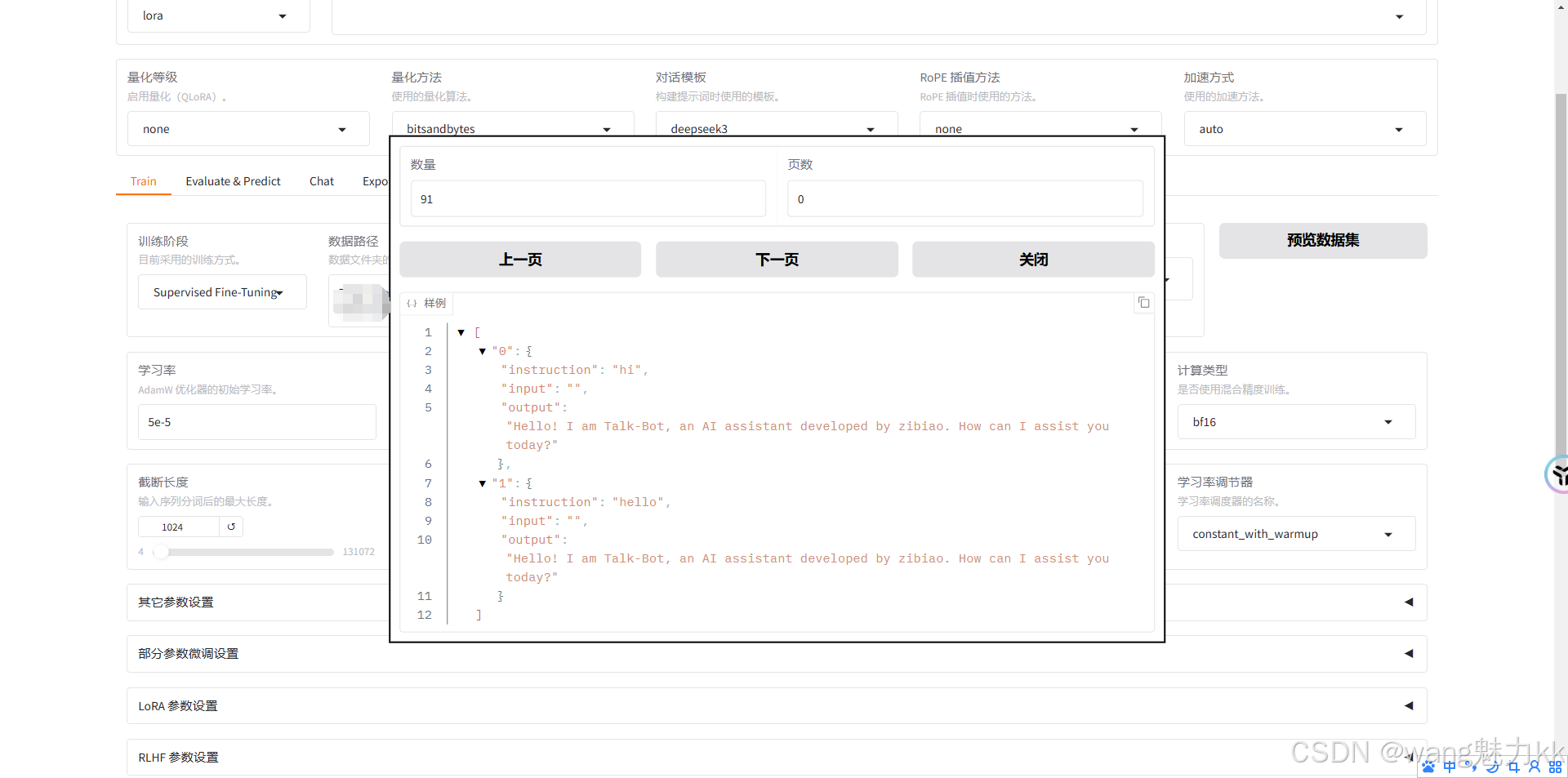
输出目录修改
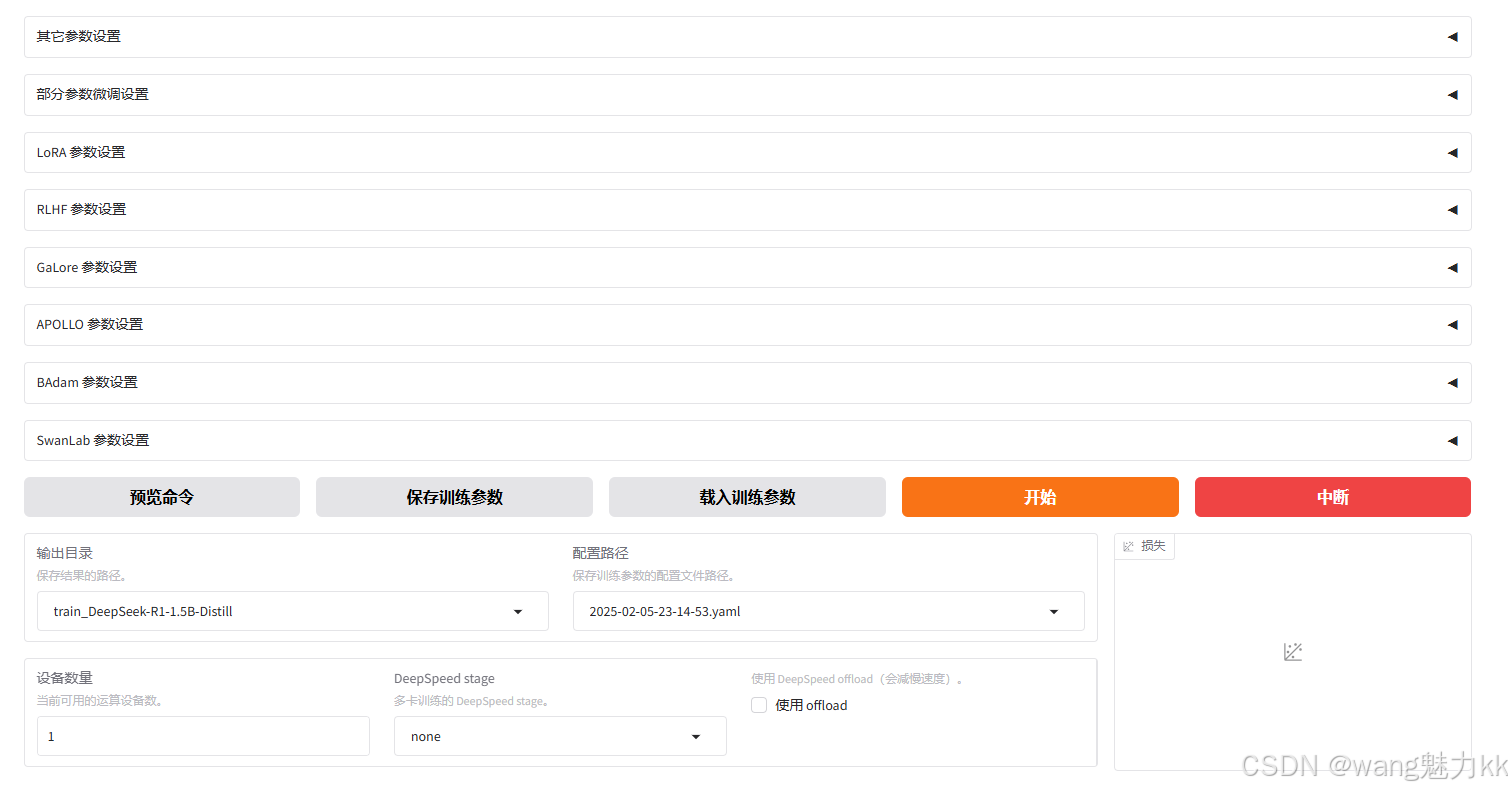
修改配置后,点击开始按钮,等待进度条训练完毕即可。CPU也能训练,但是时间太慢,有条件的最好用GPU,速度快
(我用CPU跑,用了三天,非常慢,哈哈)
我的linux配置:
我的windows配置:
LLaMA-Factory验证模型
检查点路径选择我们刚刚训练好的模型,点击加载模型后,开始聊天
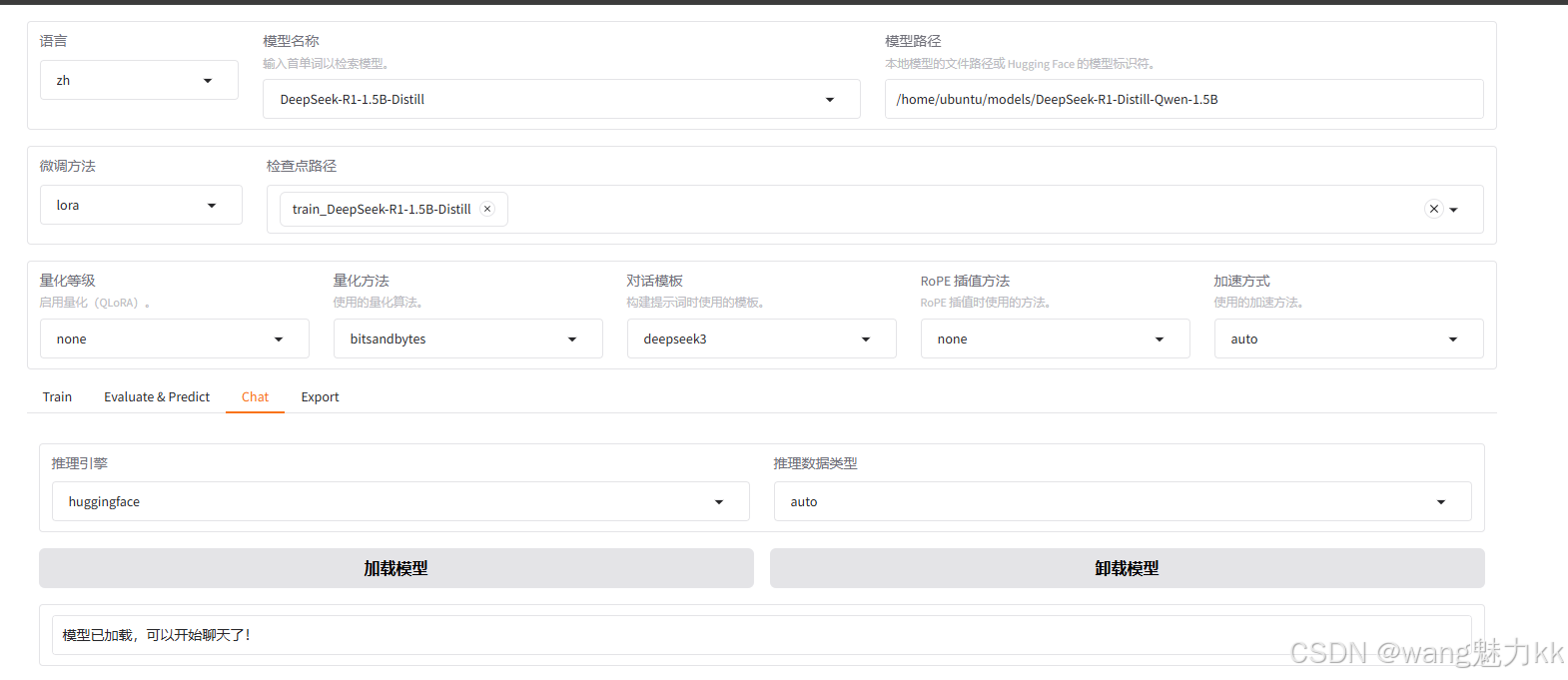
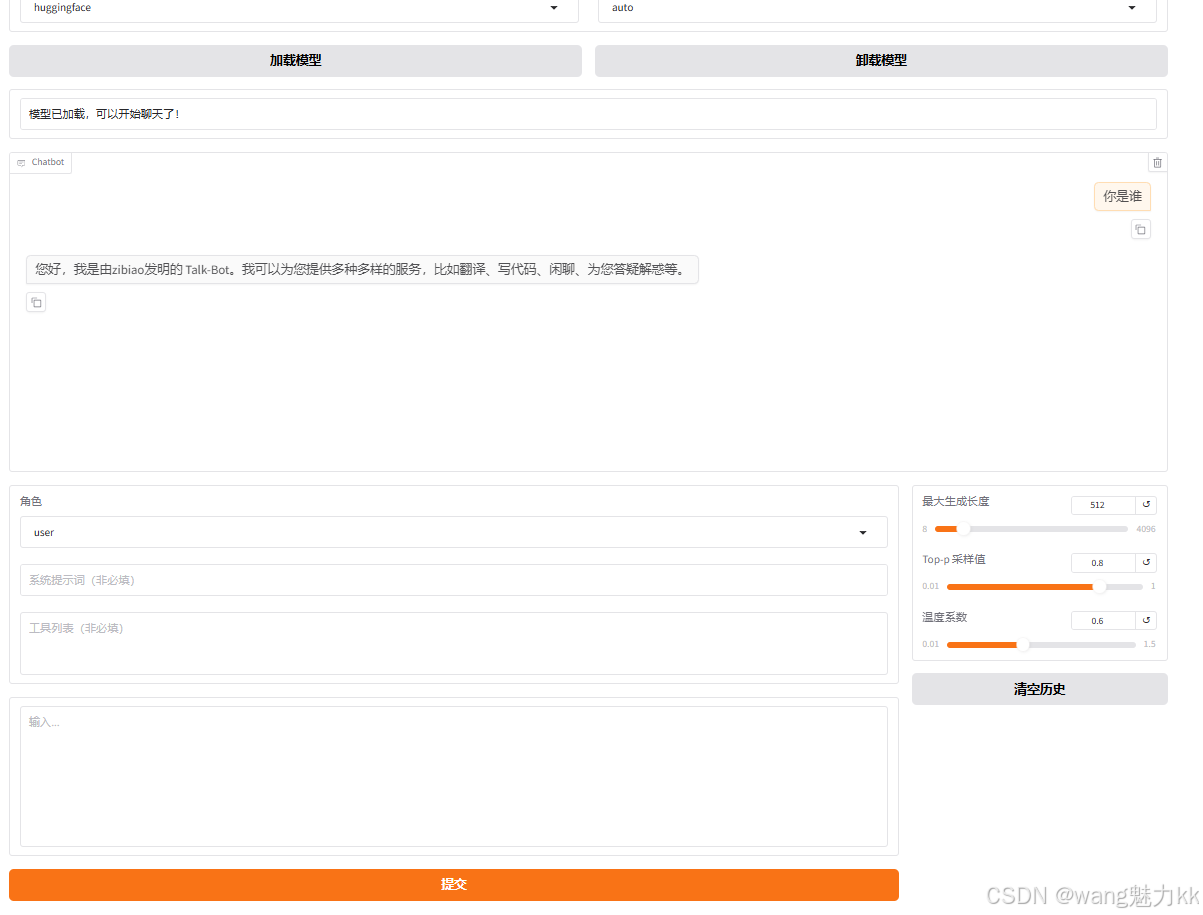
这里发现模型的自我认知部分已经被修改了,验证没什么问题,开始导出部署
LLaMA-Factory导出模型
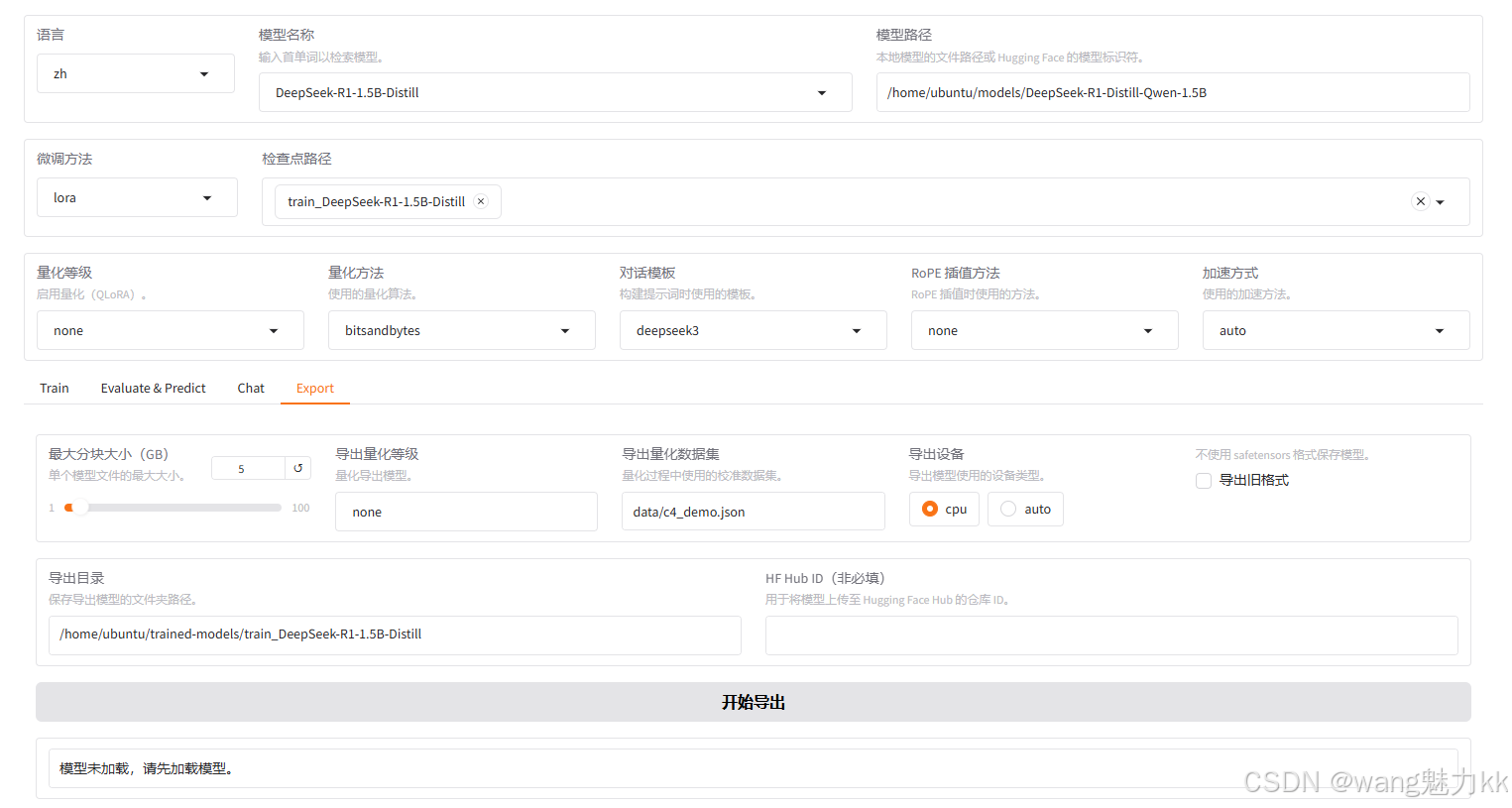
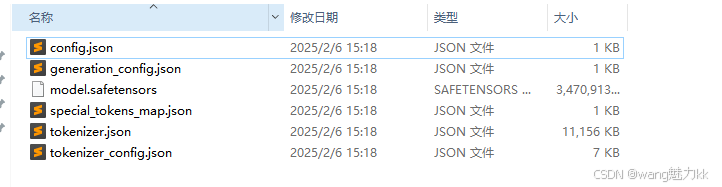
导出模型的结构如下所示
安装Ollama
使用ollama部署微调后的模型
安装方法参考官方文档,也可以网上百度,有很多,这里不在多说
因为windows安装比较简单,我这里直接使用windows安装演示效果

ollama相关的命令
// 显示安装的模型列表
ollama list
// 启动模型,没有模型则会自动下载
ollama run DeepSeek-R1-Distill-Qwen-1.5B
// 卸载模型
ollma rm DeepSeek-R1-Distill-Qwen-1.5B
// 基于Modelfile文件创建模型
ollama create DeepSeek-R1-Distill-Qwen-1.5B -f Modelfile
// 显示正在运行的模型列表
ollama ps
Ollama部署微调前的原始模型DeepSeek-R1-1.5B-Distill
-
创建Modelfile文件

Modelfile文件内容如下FROM D:\git-project\model\DeepSeek-R1-Distill-Qwen-1.5B PARAMETER temperature 0.6 PARAMETER top_p 0.95 TEMPLATE """ {{- if .System }}{{ .System }}{{ end }} {{- range $i, $_ := .Messages }} {{- $last := eq (len (slice $.Messages $i)) 1}} {{- if eq .Role "user" }}<|User|>{{ .Content }} {{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }} {{- end }} {{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }} {{- end }} """TEMPLATE 这个参数必须要加上,不然启动模型回复的是乱的,这个具体怎么写呢,有两种办法可以获取到
- 打开ollama官方,搜索到deepseek-r1模型,找到deepseek-r1下边任意一个版本的模型,把template拷贝出来即可
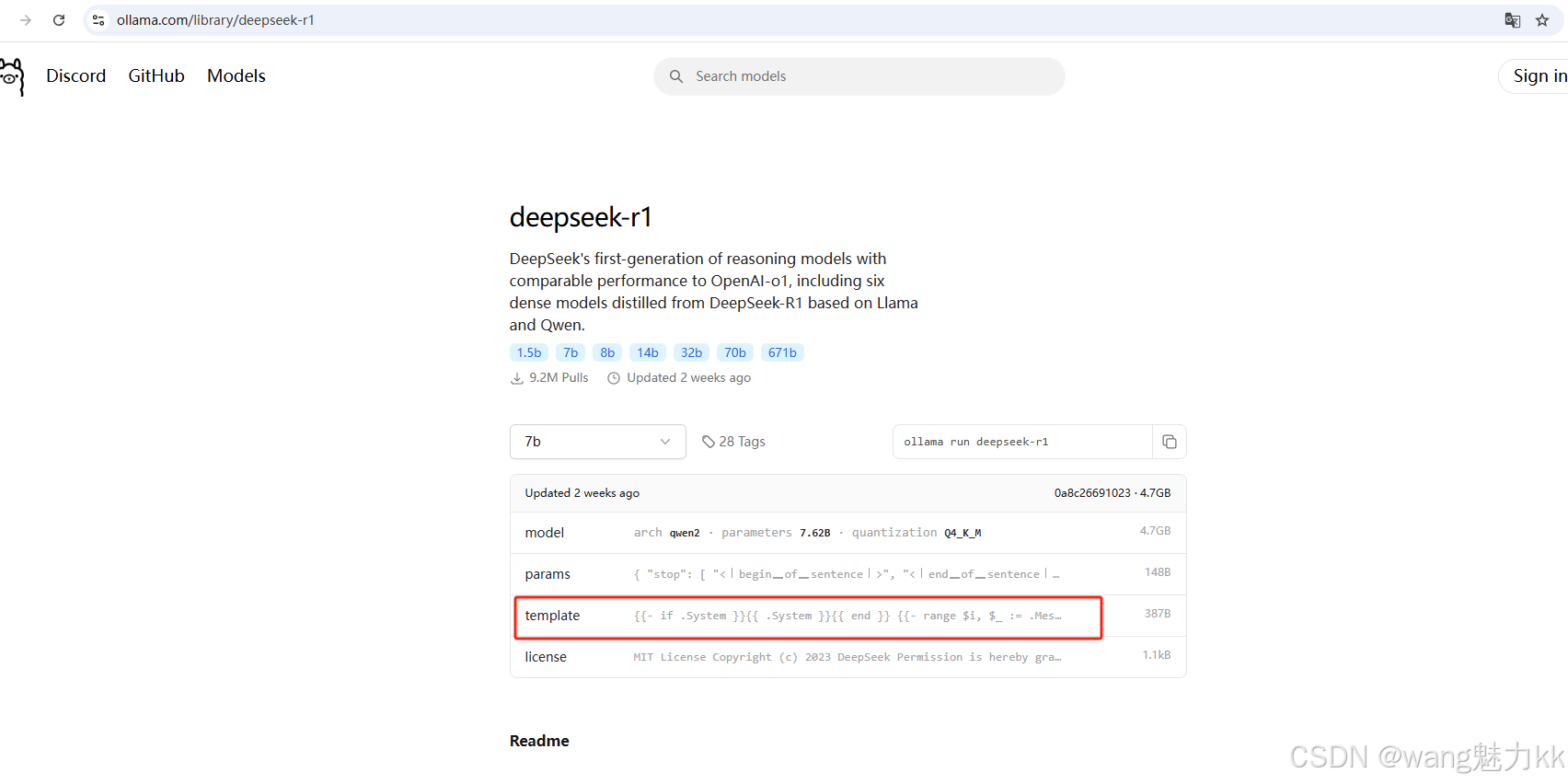
- 通过ollama命令行方式,把显示的结果拷贝出来,都贴过去
ollama show --modelfile <模型名称>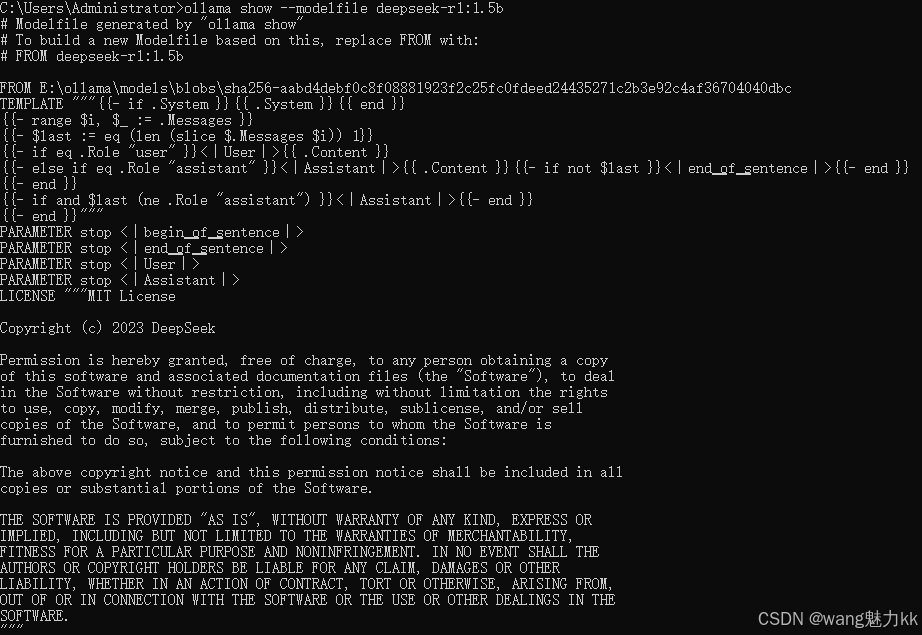
temperature参数DeepSeek-R1官方建议给0.6
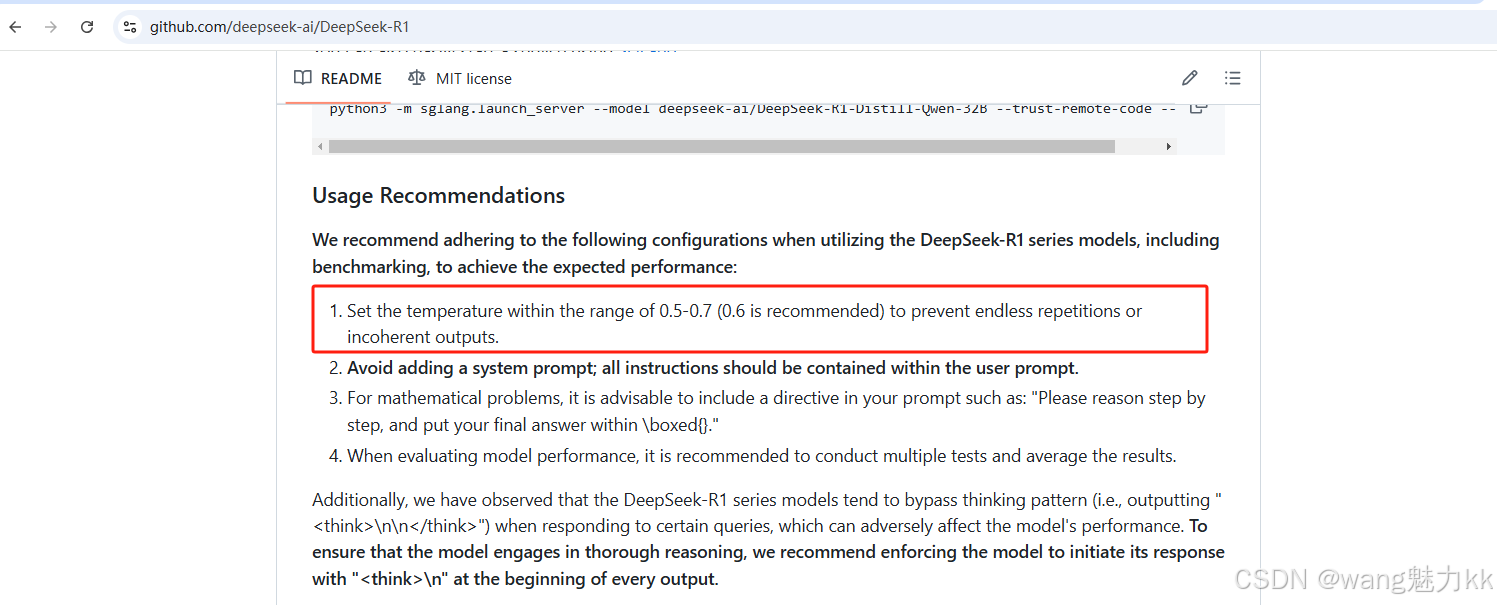
其他一些参数参考Modilefile官方文档
- 打开ollama官方,搜索到deepseek-r1模型,找到deepseek-r1下边任意一个版本的模型,把template拷贝出来即可
-
创建模型
ollama create DeepSeek-R1-Distill-Qwen-1.5B -f D:\git-project\model\Modelfile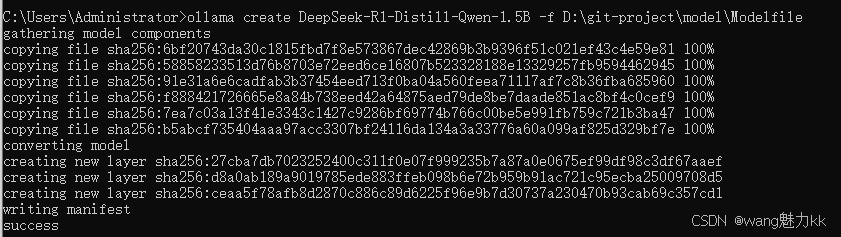

-
启动模型测试

-
api调用
请求完全遵循openai的接口格式,用过opneai的应该都很熟悉{ "model":"DeepSeek-R1-Distill-Qwen-1.5B", // 模型名称,ollama上显示的名字 "stream": false, // 是否流式,true流式返回 "temperature": 0.6, // 思维发散程度 "top_p":0.95, // 一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果 "messages":[ // 上下文 { "role":"user", "content":"你是谁?" } ] }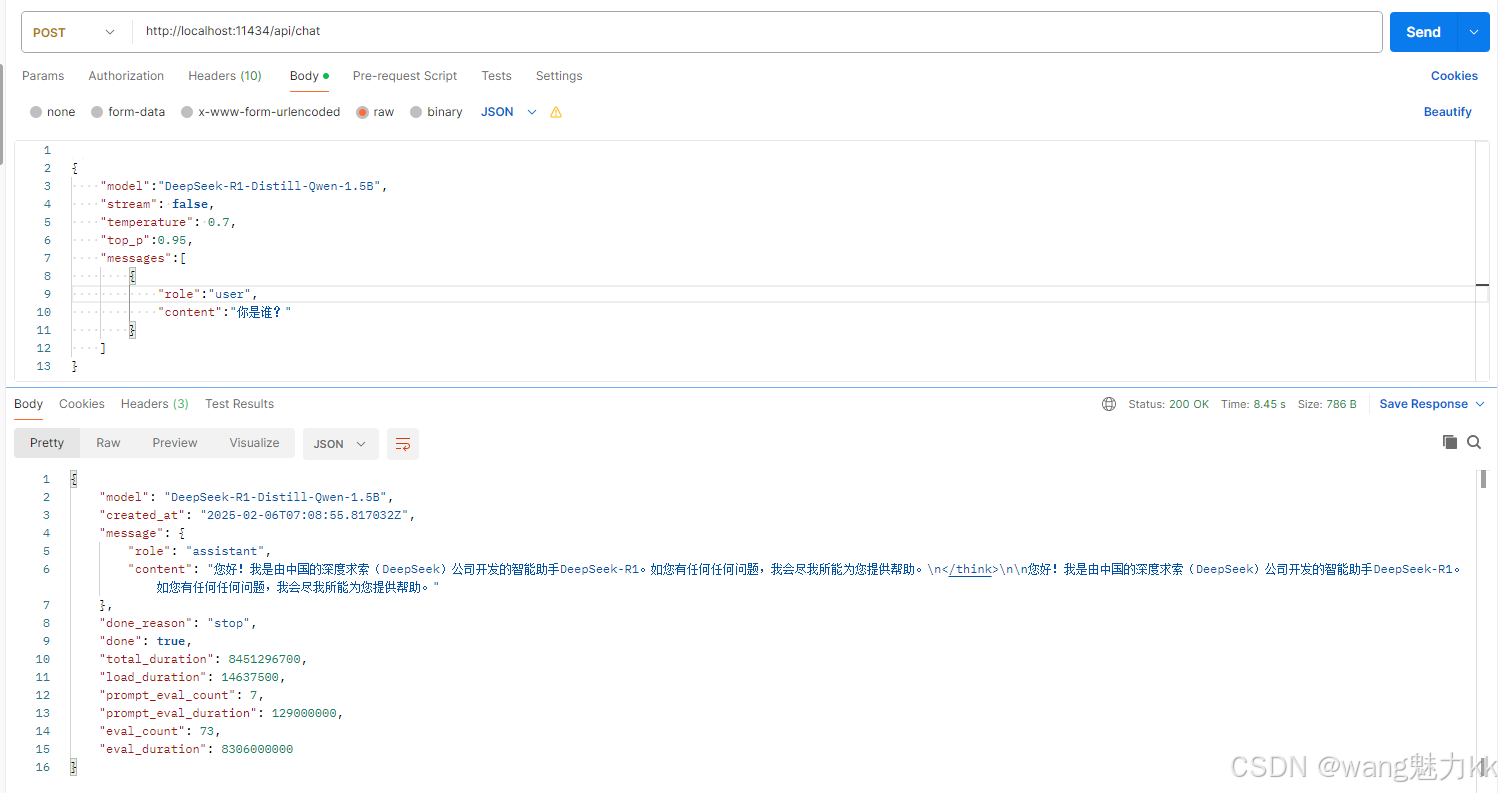
Ollama部署微调后的DeepSeek-R1-1.5B-Distill模型,两种方式(二选一)
-
从 Safetensors 权重导入模型,与上文中部署微调原始模型DeepSeek-R1-1.5B-Distill一致,唯一不同的就是,把上文中的模型路径改成训练好的模型路径即可,这里不在赘述
- 创建Modelfile文件

Modelfile文件内容如下FROM D:\git-project\trained-model\train_DeepSeek-R1-1.5B-Distill PARAMETER temperature 0.6 PARAMETER top_p 0.95 TEMPLATE """ {{- if .System }}{{ .System }}{{ end }} {{- range $i, $_ := .Messages }} {{- $last := eq (len (slice $.Messages $i)) 1}} {{- if eq .Role "user" }}<|User|>{{ .Content }} {{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }} {{- end }} {{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }} {{- end }} """- 启动测试:

- api调用
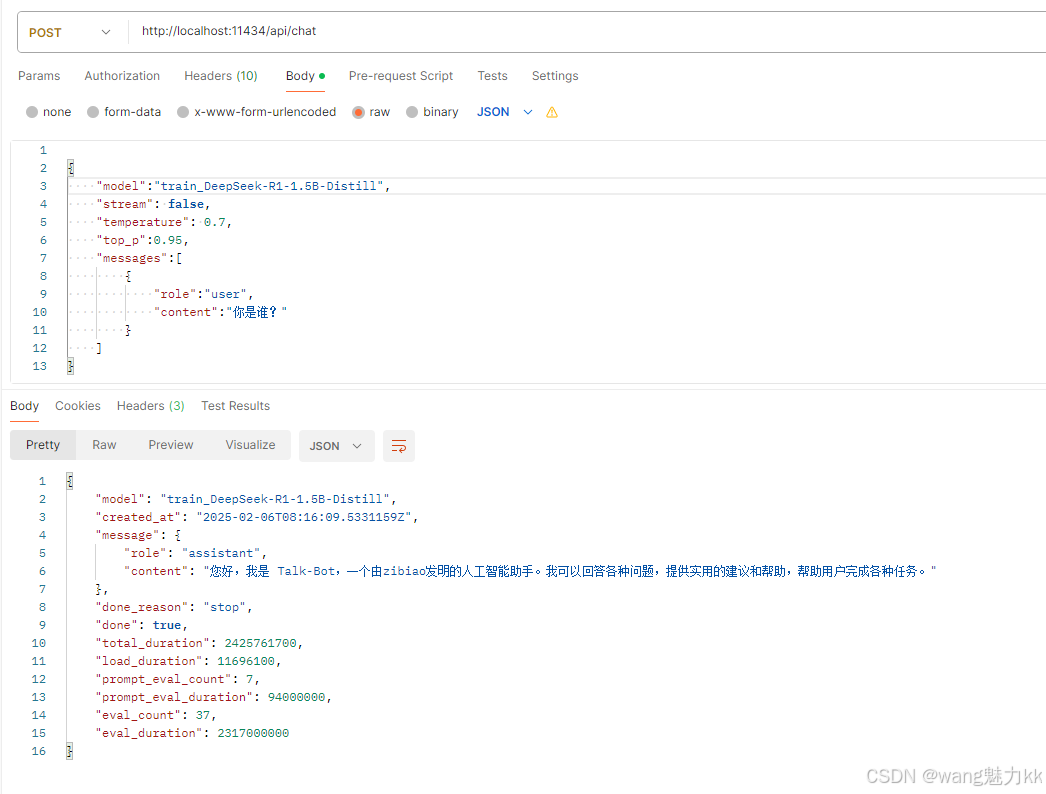
-
导入基于 GGUF 的模型
如果你有一个基于 GGUF 的模型,可以将其导入 Ollama。你可以通过以下方式获取 GGUF 模型:安装 Llama.cpp
git clone --depth 1 https://github.com/ggerganov/llama.cpp.git pip install -r requirements.txtpython D:\git-project\llama.cpp\convert_hf_to_gguf.py D:\git-project\trained-model\train_DeepSeek-R1-1.5B-Distill --outfile D:\git-project\trained-model\model.gguf --outtype q8_0执行成功的效果图
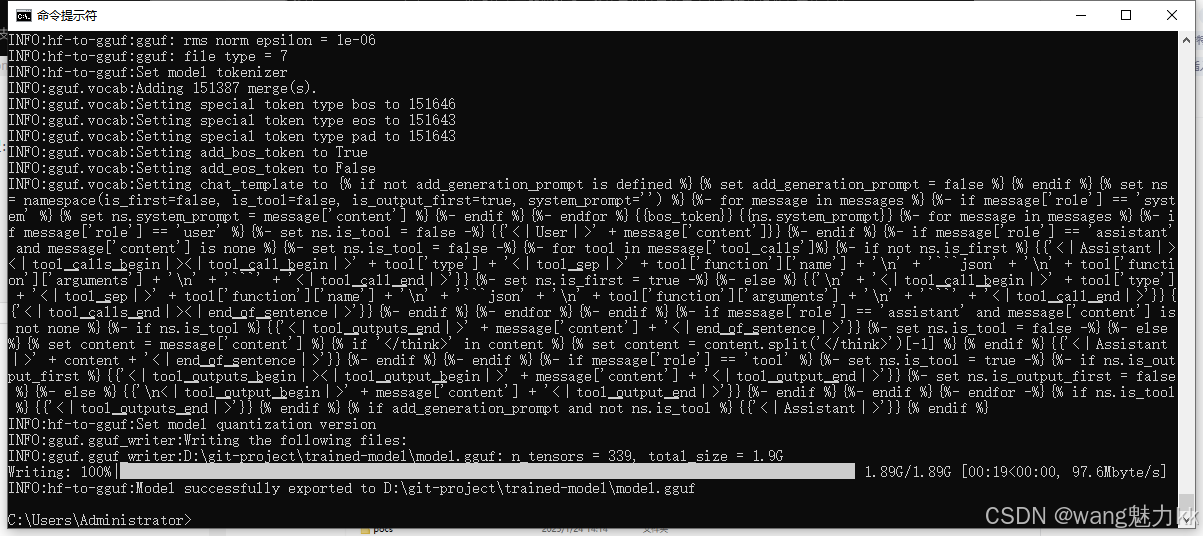
这个时候目录下会多出一个model.gguf文件

-
在当前目录下创建ModileFile文件

ModileFile文件内容如下:
FROM D:\git-project\trained-model\model.gguf PARAMETER temperature 0.6 PARAMETER top_p 0.95 TEMPLATE """ {{- if .System }}{{ .System }}{{ end }} {{- range $i, $_ := .Messages }} {{- $last := eq (len (slice $.Messages $i)) 1}} {{- if eq .Role "user" }}<|User|>{{ .Content }} {{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }} {{- end }} {{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }} {{- end }} """ -
创建模型
ollama create train_DeepSeek-R1-1.5B-Distill_GGUF -f D:\git-project\trained-model\Modelfile
-
启动测试

-
api调用
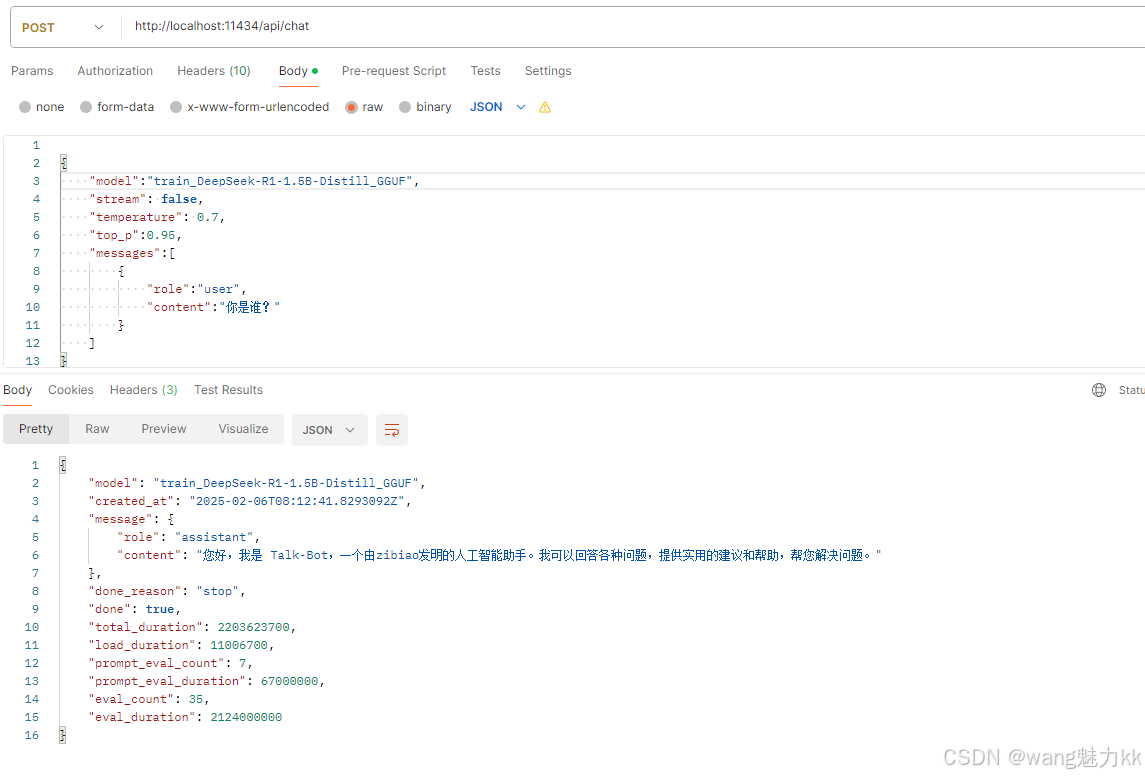
-
Ollama量化模型
量化模型可以让你以更快的速度和更少的内存消耗运行模型,但精度会有所降低。这使得你可以在更便宜的硬件上运行模型
ollama 可以使用 -q/–quantize 标志与 ollama create 命令将基于 FP16 和 FP32 的模型量化为不同的量化级别
使用 ollama create 来创建量化模型

这里量化失败,是因为默认拉取的模型的量化方式已经是是Q4_K_M了,无法二次调整模型量化参数,可以通过查看模型的全部版本找到对应的FP16精度或者FP32精度的原始模型,拉取然后进行二次量化
支持的量化方式
| 量化方式 | 简要解释 |
|---|---|
| FP16 | 半精度浮点数,提供较高的数值范围和精度,适用于需要较高计算精度的场景。 |
| Q2_K | 二进制量化的一种形式,使用较少的比特表示权重,显著减少存储需求。 |
| Q3_K_L | 使用3比特进行量化,L表示较低的精度配置。 |
| Q3_K_M | 使用3比特进行量化,M表示中等精度配置。 |
| Q3_K_S | 使用3比特进行量化,S表示较高的精度配置。 |
| Q4_0 | 使用4比特进行量化,0表示特定的精度配置。 |
| Q4_1 | 使用4比特进行量化,1表示另一种精度配置。 |
| Q4_K_M | 使用4比特进行量化,M表示中等精度配置。 |
| Q4_K_S | 使用4比特进行量化,S表示较高的精度配置。 |
| Q5_0 | 使用5比特进行量化,0表示特定的精度配置。 |
| Q5_1 | 使用5比特进行量化,1表示另一种精度配置。 |
| Q5_K_M | 使用5比特进行量化,M表示中等精度配置。 |
| Q5_K_S | 使用5比特进行量化,S表示较高的精度配置。 |
| Q6_K | 使用6比特进行量化,K表示特定的精度配置。 |
| Q8_0 | 使用8比特进行量化,0表示特定的精度配置。 |

















 6251
6251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









