







本文转自:智药邦
数据可用性、数据安全和隐私问题通常会影响机器学习技术的最佳性能。
因此,在药物发现领域,人们提出了利用私人/敏感数据来完成机器学习模型构建任务的新技术。
这些新技术包括安全多方计算、分布式深度学习、同态加密、基于区块链的点对点网络 、差分隐私和联邦学习,以及这些技术的组合。
2023年11月5日,奥地利维也纳大学Aljoša Smajić等人在Drug Discov Today发表文章Privacy-preserving techniques for decentralized and secure machine learning in drug discovery。

文章概述了这些被用于药物发现的多种去中心化机器学习技术。这些技术将使各方有可能在不披露内部数据集的情况下共同开发模型。
前言
近年来,机器学习(ML)和深度学习(DL)方法被广泛应用于药物发现和开发。这些AI技术彻底改变了新药发现方式。
然而,制药和生物技术公司的数据集通常不会向公众披露。数据共享和访问还存在侵犯商业利益或其它私人利益的风险,对收入和盈利能力产生负面影响。
因此,人们提出了用于药物发现的去中心化机器学习方法。这将使多方合作开发模型成为可能,而无需像传统做法那样披露内部数据集。
去中心化机器学习方法对于虚拟筛选和药物设计等应用来说非常有利。研究人员可以利用分布在许多制药公司和研究机构的数据集,针对治疗靶点训练化合物活性预测模型,从而提高虚拟筛选的准确性,加快药物开发过程。
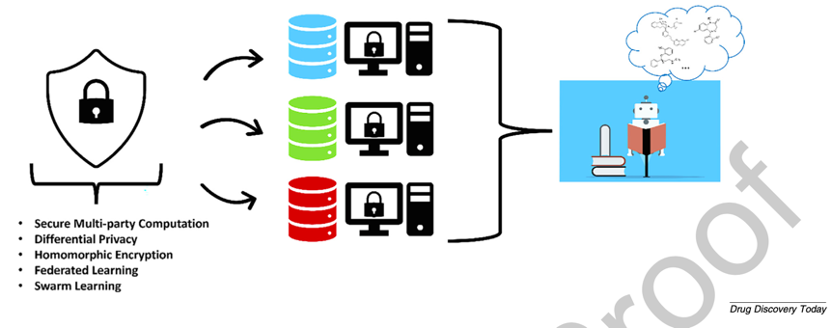
适用于药物发现的现有隐私保护技术
本文讨论了这些方法在药物发现中的最新应用、策略的适用性、在药物发现早期阶段的意义,以及未来的潜力、新发展和优缺点。
用于药物发现的隐私保护的去中心化ML技术
安全多方计算
安全多方计算(Secure multiparty computation, SMPC)是20世纪70年代末引入的一种新兴的密码技术。与确保通信安全性和完整性的传统密码学方法相比,SMPC更强调保护数据不被参与计算的其他参与者泄露。SMPC通过遵循特定的加密协议避免了参与者之间的直接数据交换或任何敏感信息的披露,从而保护了各参与者提供数据的安全性。该方法允许数据被用于进行联合分析的同时,仅将结果发送回参与方。此外,与联邦学习不同,SMPC在计算过程中向参与者揭示最终结果,而不披露中间信息,从而提供了更高级别的安全性。

安全多方计算的原理图
安全多方计算在药物发现中的应用
SMPC在生物医学研究领域的一个例子是EasyMPC,这是一种用于实用和安全的多方计算的强大工具。该工具在输入共享和输出重构期间安全地总结不同参与者之间的预定义变量集,并将结果展现在图形用户界面。
随着近年来的计算和技术的进步,定量结构-活性关系(QSAR)方法被引入与SMPC结合使用于保护隐私的药物-靶标相互作用(DTI)。已经有研究团队在一种名为QSARMPC的方法中证明了SMPC与QSAR的结合使用。MPC建立在具有两个隐藏层神经网络的DTINet上,主要用于解决回归问题。当应用于MPC协议下的QSAR时,该方法显示出相当好的性能。此外,同一研究小组还推出了一种基于MPC的DTI预测工具,称为DTIMPC,用于根据药物相关的异质信息预测新的DTI。DTIMPC表明,制药公司或机构可以实现高质量的合作。
此外,在基因组序列比较领域通常有两种工具可以被使用,第一种工具是安全两方计算(S2PC)。这种方法允许以安全的方式对两个基因组序列进行比对。S2PC可以分为两组:基于同态加密的构造和基于乱码电路的构造。另一种方法,Sequre,一种用于安全多方计算的高性能框架,是允许基于敏感生物医学数据进行计算的加密工具。Sequre已被应用于不同的任务,如安全的全基因组关联分析、安全的药物-靶标相互作用预测和安全的宏基因组装。
差分隐私与差分隐私深度学习
差分隐私(Differential privacy, DP)可以被认为是一种去中心化技术。这种技术允许参与者相互共享数据,同时保护每个人的数据隐私。在使用中DP通过将校准的噪声应用于输出,可以掩盖数据集中任何个体的贡献,同时仍然保持分析/计算的整体准确性。此外,通过仔细调整隐私设置并利用自适应隐私预设和隐私放大等创新方法,可以提高DP-ML模型的准确性。
差分隐私在药物发现中的应用
到目前为止,DP主要应用于药物敏感性预测和组学数据。在Honkela等人的工作中,已经证明DP的使用可以提高药物敏感性预测,并且可以在中等大小的数据集的强大DP保证下学习有用的预测因子。2022年,Islam等人证明,DP和DL的组合,即差分隐私深度学习,可用于使用敏感的人类基因组数据预测癌症细胞系中的乳腺癌症状态、癌症类型和药物敏感性,同时保护个人隐私。但是,DP和差分隐私深度学习方法并没有像联邦学习等其他方法那样应用于药物发现的许多领域。
同态加密与全同态加密
同态加密(Homomorphic encryption, HE)是另一种允许计算加密数据集的加密技术,但有一些局限性。在FHE中,通过将任意函数描述为加密方案中的布尔电路,可以对加密数据执行加法和乘法。2012至2013年推出的“第三代”FHE带来了实际的改进,极大地提高了FHE方案的效率。

全同态加密的简化图示
技术改进产生了一系列开源软件库,如SEAL、HElib、TFHE、HEAAN和PALISADE。一个由行业、政府和学术界专家组成的同态加密标准化联盟在2018年开发了同态加密标准,说明了FHE应用程序的安全要求。FHE被联盟描述为基于同态计算的三个模型:布尔电路、模(精确)算法和近似数算法。此外,联盟还提出了用于加密数据的神经网络的实现方法,并将其应用于推理。不幸的是,由于在数据集上执行的计算的复杂性,大规模去中心化的模型构建变得不切实际。然而,随着硬件加速和优化算法的进一步进步,这项技术可能成为保护隐私的去中心化模型构建的潜在关键参与者,这可能会在药物发现方面带来新的应用。
联邦学习
上述三种技术对于保护数据集的隐私和实现避免任何数据泄露的目标都至关重要。通常,这些技术中的一些与联邦学习(Federated learning, FL)等方法相结合。
谷歌于2016年首次披露的一种独特的算法--联邦平均(FedAvg),借助这种算法,可以在保护任何机构数据隐私的同时重新定位数据计算。在不直接访问训练数据的情况下将模型发送给组织,降低了与隐私和安全相关的风险。这被称为模型驱动的联邦学习(MD-FL),数据被本地存储,而只有参数被发送到第三方保管人。
根据参与者的规模,联邦学习可以分为两类:跨设备联邦学习和跨孤岛联邦学习。后者涉及少数实体之间的知识共享,已广泛用于药物发现。
联邦学习也可以分为三类:水平联邦学习(HFL)、垂直联邦学习(VFL)和联邦迁移学习(FTL),每类都能够处理各种学习任务。
联邦学习在药物发现中的应用
在药物发现领域,联邦学习是最具活力的研究方法。
具体参见
AI药物发现的数据共享模式探索:以十大顶尖药企参加的MELLODDY项目为例
MELLODDY运营的总结文章参见
MELLODDY: Cross-pharma Federated Learning at Unprecedented Scale Unlocks Benefits in QSAR without Compromising Proprietary Information
https://pubmed.ncbi.nlm.nih.gov/37642660/
目前,它是最大的基于FL的研究,分析了来自10家制药公司的2,000万种小分子化合物的40,000多项生物检测结果。该项目采用了基于MD-FL的大规模多任务设置,使每个参与者都能参与一系列任务。所有任务都共享一个共同的主干,使模型能够学习数据集的共同表示。每个任务都可以被视为模型的一个独立"头",可以学习其他任务的独特特征。主干和"头"之间还进一步应用了迁移学习,使模型能够利用从一项任务中获得的知识来提高其在另一项任务中的性能。
同济大学刘琦等人发表的FL-QSAR,展示了用于QSAR任务的FL设置。参见
FL-QSAR: a federated learning based QSAR prototype for collaborative drug discovery
https://www.biorxiv.org/content/10.1101/2020.02.27.950592v1
其他已应用于药物/分子发现的FL项目包括FedChem、FedGraphNN、FL-Disco、kMol和Xiong等人的工作。Thierry Hanser的工作中对这些项目和FL的应用进行了详细描述,说明了FL应用于分子发现的好处和其他挑战。
群学习及其在药物发现中的应用
虽然FL需要一个中央协调器,但群学习(swarm learning, SL)是一种完全独立的方法,因为它使用基于区块链的对等网络来交换由单独训练的本地模型建立的参数。通过使用群体应用程序编程接口(API),模型参数被传递和合并,以创建类似于FL方法的更新模型。使用案例有:使用外周血单核细胞(PBMC)转录组预测白血病,使用血液转录组鉴定结核病,以及鉴定新冠肺炎。此外,SL通过设计提供了保密性,并有可能结合DP、功能加密和加密迁移学习等进步。
案例参见
Nature:优于联邦学习的医疗数据共享技术Swarm Learning及应用案例
总结
在药物研究中,保护隐私的去中心化方法至关重要。到目前为止,在药物发现领域引入和部署的实际应用还很少。
通过对这些技术进行比较,我们可以发现,联邦学习作为一个与药物发现相结合的研究领域,已经获得了相当高的知名度。这一点可以通过研究MELLODDY和Effiris这两个现实世界中的实施方案得到证明。
多方隐私保护的ML技术,如HE、DP和SMPC,与去中心化数据和联邦ML相结合,在药物发现领域也具有重要意义。















 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









