






本文针对Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI 中的49个数据集进行完整下载地址整理收集。
2024年8月26日,由刘洋、陈伟星、白永杰、梁晓丹、李冠斌、高文、林亮等作者编写,深入探讨了具身智能AI。
具身人工智能的关键技术: 具身感知、具身交互、具身智能体、模拟到真实世界迁移。
具身感知主要涉及:主动视觉感知、三维视觉定位、视觉语言导航、非视觉感知:触觉
一、具身感知中 (22个)
1、视觉语言导航 的12个数据集
2、非视觉感知:触觉 的10个数据集
二、具身交互 (19个)
1、具身问答 的10个数据集
2、具身抓取的 9个数据集
三、论文中其他数据集等(8个)
一、研究背景与动机
1、具身AI的起源于定义
-
具身AI的起源:具身AI的概念最早可以追溯到1950年图灵提出的具身图灵测试,其核心在于判断智能体是否能够在虚拟环境中解决抽象问题的同时,也能在物理世界中导航和应对复杂性与不可预测性。
-
具身AI与非具身AI的区别:具身AI强调智能体通过物理实体(如机器人)与物理世界交互,与之相对的是非具身AI,后者主要在虚拟环境中运行,如ChatGPT等。
2、具身AI的重要性
-
实现AGI的关键途径:具身AI被认为是实现AGI的基础。与仅依赖语言交互的智能体(如ChatGPT)不同,具身AI通过控制物理实体与环境交互,能够更好地理解和适应现实世界。
-
多领域应用:具身AI在机器人技术、自动驾驶、医疗保健、家庭助理、工业自动化和搜索救援等领域具有广泛的应用前景。
3、多模态大模型和 世界模型的推动
MLMs的作用:多模态大模型为具身AI提供了强大的感知、交互和规划能力。这些模型通过整合视觉、语言和动作信息,使具身智能体能够更好地理解环境并执行复杂认为。
World Models的作用:世界模型通过模拟物理环境和物理规律,帮助具身智能体更好地理解现实世界。这些模型能够生成逼真的虚拟环境,为具身AI的训练和测试提供了有力支持。
二、Embodied Robots (具身机器人)
具身机器人分类
固定基座机器人(Fixed-base Robots):适合高精度任务
用于实验室自动化、教育和工业制造,具有高精度和可编程性,但移动范围有限。

轮式机器人(Wheeled Robots)
用于移动应用,例如物流、仓储,结构简单、成本相对较低、能效高,且在平坦表面上移动速度快。

履带式机器人(Tracked Robots)
用于移动应用,在农业、建筑和灾难恢复等领域表现出色,履带系统提供了较大的地面接触面积,能够在软质地面上(如泥沙和沙地)分散重量,减少陷入的风险。

四足机器人(Quadruped Robots)
用于适用于复杂地形探索、救援任务和军事应用。具有稳定性和适应性,但成本较高。

人形机器人(Humanoid Robots)
-
应用场景:在服务行业、医疗保健和协作环境中越来越常见。
-
设计特点:具有类似人类的外形,能够模仿人类的动作和行为模式,手部设计灵活,能够执行复杂的任务。

仿生机器人(Biomimetic Robots)
-
应用场景:在医疗保健、环境监测和生物研究等领域具有潜力。
-
设计特点:通过模仿自然生物的形态和运动机制,使用灵活的材料和结构来实现类似生物的敏捷运动。

具身机器人在多个领域具有广泛的应用前景,但不同类型机器人在设计、性能和应用场景上各有优缺点。
总结:
固定基座机器人适合高精度任务,轮式机器人适合平坦表面的快速移动,履带式机器人适合复杂地形,四足机器人适合复杂地形探索和救援任务,人形机器人适合与人类协作的环境,而仿生机器人则在能效和特定环境适应性方面具有优势。
三、Embodied Simulators (具身模拟器)
模拟器的分类
具身模拟器分为两大类:通用模拟器(General Simulators) 和基于真实场景的模拟器(Real-Scene Based Simulators)
通用模拟器提供了高度可配置的虚拟环境,适合多种研究需求。
而基于真实场景的模拟器则通过逼真的场景和丰富的交互对象,为家庭环境中的具身AI研究提供了强大的支持。
基于底层物理模拟的通用模拟器
通用模拟器提供了高度可配置的虚拟环境,能够模拟各种物理特征和动态变化。用于算法开发、模型训练等,具有成本低、安全性高等优势。

通用模拟器示例
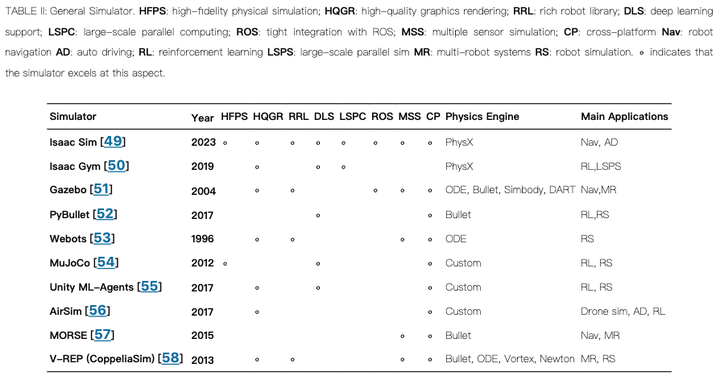
Isaac Sim:由NVIDIA开发,具有高保真物理模拟和实时光线追踪功能,适用于自动驾驶、工业自动化等领域。
Isaac Gym:基于Isaac Sim,专注于强化学习和大规模并行计算。
Gazebo:开源的机器人模拟器,具有丰富的机器人库和与ROS的紧密集成,适用于机器人导航和控制。
PyBullet:基于Bullet物理引擎的Python接口,易于使用,支持深度学习和强化学习。
Webots:具有丰富的机器人库和多种传感器模拟,适用于机器人导航和多机器人系统。
MuJoCo:专注于物理模拟的准确性,适用于强化学习和机器人控制。
Unity ML-Agents:基于Unity游戏引擎,提供丰富的图形渲染和深度学习支持,适用于强化学习。
AirSim:由微软开发,专注于无人机模拟和自动驾驶,支持多种物理引擎。
MORSE:基于Blender的模拟器,支持多种物理引擎和机器人导航。
V-REP (CoppeliaSim):支持多种物理引擎和机器人模拟,适用于多机器人系统和机器人研究。
基于真实场景的模拟器
基于真实场景的模拟器通过从真实世界中收集数据,创建逼真的3D资产,并使用3D游戏引擎(如UE5和Unity)构建场景。这些模拟器的目标是尽可能接近真实世界,以满足家庭环境中具身AI研究的需求。

基于真实场景的模拟器示例
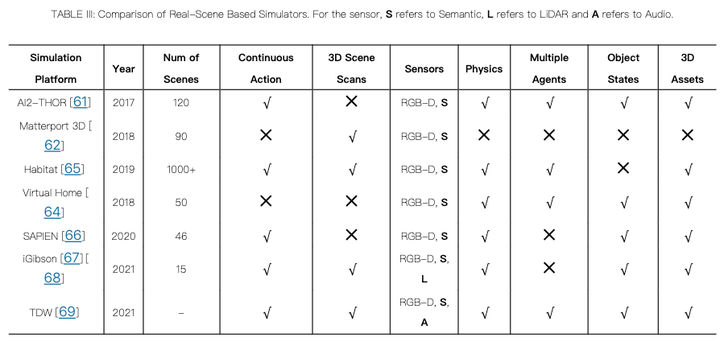
AI2-THOR:基于Unity3D的室内场景模拟器,具有丰富的交互对象和物理属性,支持多智能体模拟。
Matterport 3D:基于真实世界室内场景的2D-3D视觉数据集,支持导航和交互任务。
VirtualHome:通过环境图表示场景,支持复杂的交互任务和自然语言指令。
Habitat:由Meta开发的开源模拟器,支持大规模人类-机器人交互,具有高度的开放性和可扩展性。
SAPIEN:专注于物体交互的模拟器,提供细粒度的控制和物理交互。
iGibson:由斯坦福大学开发的开源模拟器,提供高质量的室内场景和丰富的物体属性。
TDW:由麻省理工学院开发的模拟器,结合了高保真视觉和音频渲染,支持多种物理引擎和多智能体模拟。
四、Embodied Perception (具身感知)
具身人工智能的关键技术: 具身感知、具身交互、具身智能体、模拟到真实世界迁移。
具身感知不仅仅是识别图像中的物体,而是要求智能体能够在物理世界中移动并交互,从而更深入地理解三维空间和动态环境。这要求智能体具备视觉感知、推理能力,以及理解场景中三维关系和预测复杂任务的能力。
具身感知主要涉及以下几个方面的内容:
主动视觉感知(Active Visual Perception)
1 、视觉同步定位语与建图(Visual SLAM) :
传统视觉SLAM :使用图像信息和多视图几何原理来估计机器人在未来环境中的位置,并构建环境的低级地图(如稀疏点云图)。
语义视觉SLAM:通过整合语义信息,显著提升了机器人在复杂环境中的导航能力。
2、三维场景理解(3D Scene Understanding):从三维数据中提取和理解场景的语义信息的过程。
3、主动探索(Active Exploration):通过与环境交互或改变观察方向来主动获取更多信息。
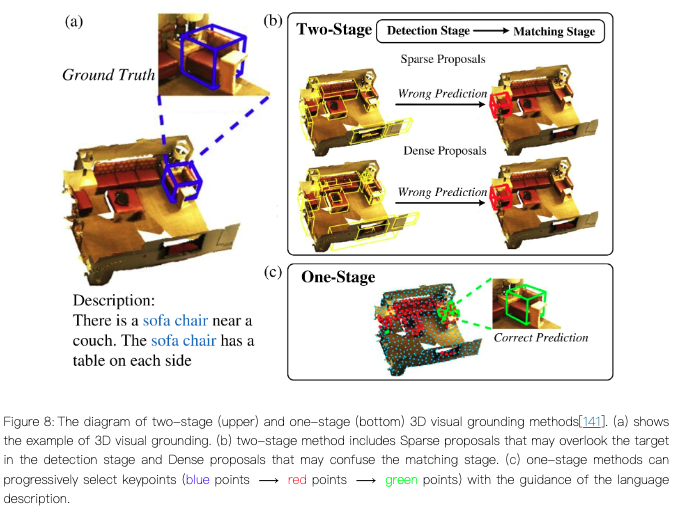
三维视觉定位(3D Visual Grounding)
目标定位:使用自然语言描述在3D环境中定位物体,分为两阶段方法和单阶段方法。两阶段方法包括检测和匹配两个步骤,而单阶段方法则将两个步骤合并。
视觉语言导航(Visual Language Navigation ,VLN)
视觉语言导航是具身AI中一个关键研究问题,要求智能体根据自然语言指令在未见过的环境中导航。主要分为基于记忆理解的方法和基于预测的方法。基于记忆的方法利用历史信息进行导航,而基于未来预测方法则预测未来的环境状态。
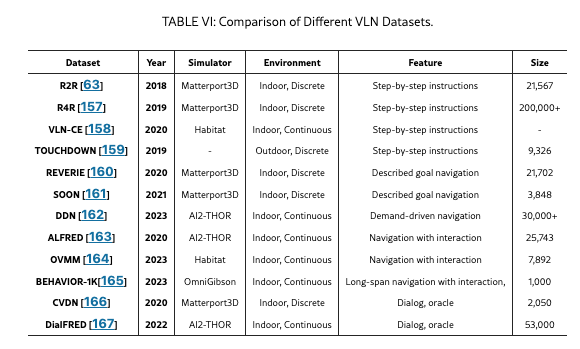
数据集:R2R
数据集地址:R2R (Room-to-Room)|自然语言处理数据集|计算机视觉数据集
数据集:R4R
数据集地址:R4R|视觉与语言导航数据集|路径规划数据集
数据集:VLN-CE
数据集地址:VLN-CE|机器人导航数据集|语言理解数据集
数据集:TOUCHDOWN
数据集地址:TOUCHDOWN|计算机视觉数据集|自然语言处理数据集
数据集:REVERIE
数据集地址:REVERIE|机器人视觉数据集|自然语言处理数据集
数据集:SOON
数据集地址:SOON|对象导航数据集|场景应用数据集
数据集:DDN
数据集地址:DDN|机器人视觉导航数据集|自然语言处理数据集
数据集:ALFRED
数据集地址:ALFRED|家庭自动化数据集|机器人技术数据集
数据集:OVMM
数据集地址:OVMM|机器人技术数据集|家庭自动化数据集
数据集:BEHAVIOR-1K
数据集地址:BEHAVIOR-1K|机器人行为数据集|日常任务执行数据集
数据集:CVDN
数据集地址:CVDN|人机交互数据集|机器人导航数据集
数据集:DialFRED
数据集地址:DialFRED|对话型机器人数据集|任务执行数据集
非视觉感知:触觉
触觉传感器:利用力、压力、振动和温度等信息进行感知,分为非视觉、视觉和多模态传感器。
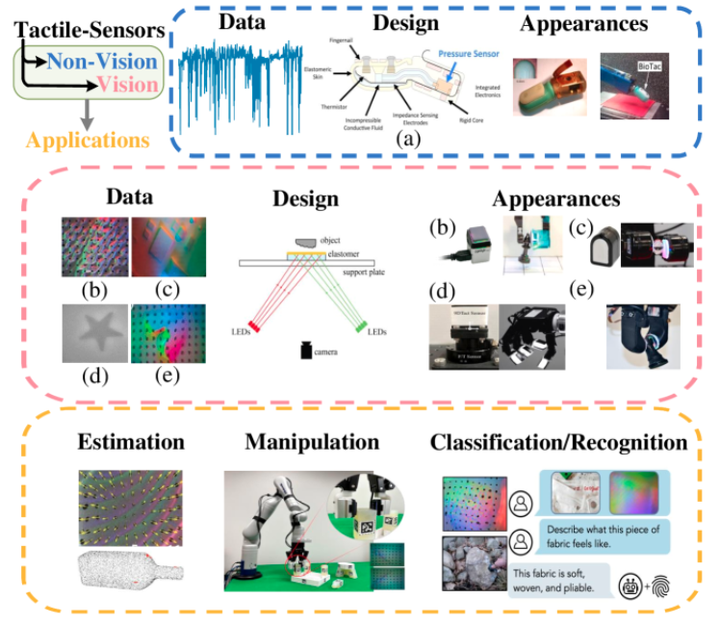
非视觉传感器:a(主要使用力、压力、振动和温度传感器来获取触觉知识) 视觉传感器:b~e(基于光学原理,将相机放置在凝胶后面,以使用来自不同方向的光源的照明来记录其变形的图像)
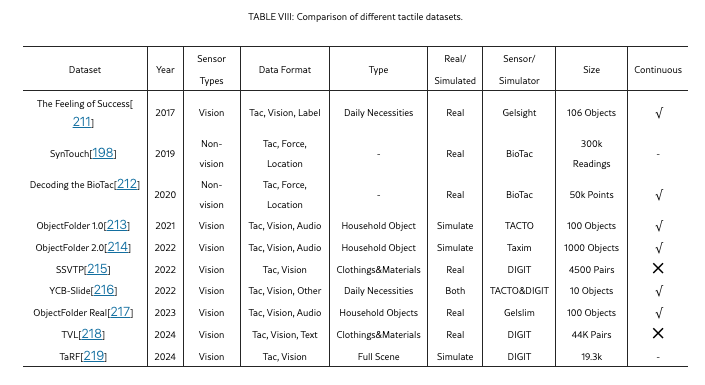
十个主要触觉数据集
数据集:The Feeling of Success
数据集地址:The Feeling of Success|机器人感知数据集|机器人抓取数据集
数据集:SynTouch
数据集地址:SynTouch|触觉传感器数据集|机器人技术数据集
数据集:Decoding the BioTac
数据集地址:Decoding the BioTac|机器人技术数据集|触觉感知数据集
数据集:ObjectFolder 1.0
数据集地址:ObjectFolder 1.0|多模态交互数据集|3D对象处理数据集
数据集:ObjectFolder 2.0
数据集地址:OBJECTFOLDER 2.0|计算机视觉数据集|机器人学数据集
数据集:SSVTP
数据集地址:SSVTP|机器人技术数据集|多模态感知数据集
数据集:YCB-Slide
数据集地址:YCB-Slide|触觉感知数据集|机器人技术数据集
数据集:ObjectFolder Real
数据集地址:ObjectFolder Real|多模态感知数据集|物体学习数据集
数据集:TVL
数据集地址:mlfu7/Touch-Vision-Language-Dataset|多模态学习数据集|数据对齐数据集
数据集:TaRF
数据集地址:TaRF|机器人交互数据集|虚拟现实数据集
五、Embodied Interaction(具身交互)
具身人工智能的关键技术: 具身感知、具身交互、具身智能体、模拟到真实世界迁移。
具身交互:指的是具身智能体在物理或模拟环境中与人类和环境进行交互的能力。这种交互不仅包括语言交流,还涉及对环境的感知、理解以及基于这些信息的行动。
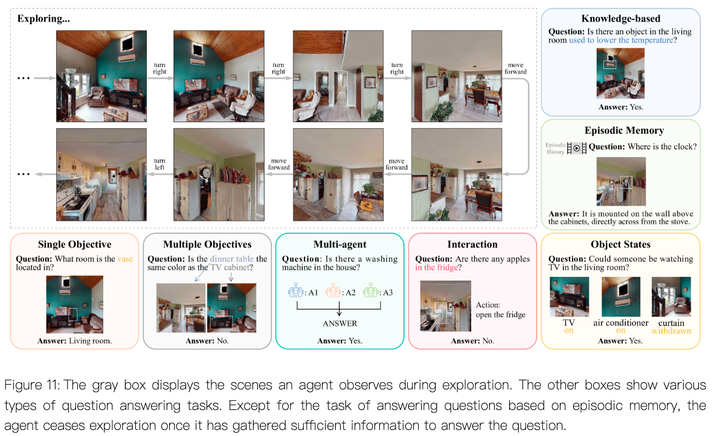
具身问答(Embodied Question Answering,EQA)
智能体需要通过探索环境来收集信息,以回答给定的问题。这要求智能体具备自主探索和决策的能力,同时需要理解问题的语义并找到答案。
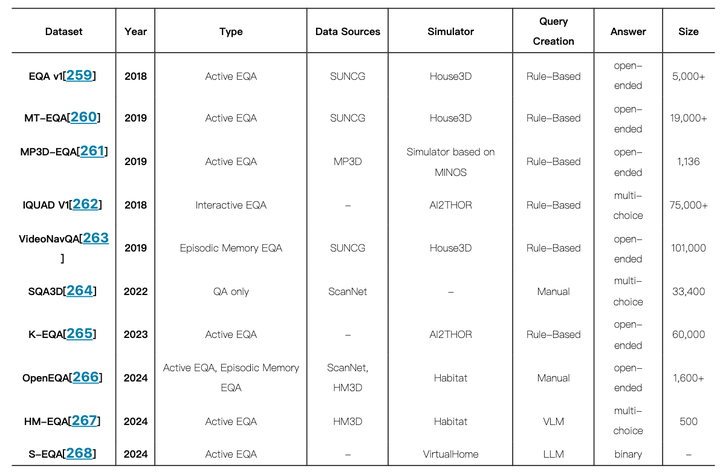
不同EQA数据集比较
数据集:EQA v1
数据集地址:EQA v1|三维视觉问答数据集|智能体交互数据集
数据集:MT-EQA
数据集地址:MT-EQA|具身问答数据集|虚拟环境导航数据集
数据集:MP3D-EQA
数据集地址:ALFRED|机器人技术数据集|自然语言处理数据集
数据集:IQUAD V1
数据集地址:IQUAD V1|交互式视觉问答数据集|智能体导航数据集
数据集:VideoNavQA
数据集地址:VideoNavQA|视觉问答数据集|具身智能数据集
数据集:SQA3D
数据集地址:SQA3D|3D场景理解数据集|智能推理数据集
数据集:K-EQA
数据集地址:K-EQA|具身问答数据集|人工智能数据集
数据集:OpenEQA
数据集地址:OpenEQA|具身智能数据集|视觉问答数据集
数据集:HM-EQA
数据集地址:HM-EQA|机器人技术数据集|视觉问答数据集
数据集:S-EQA
数据集地址:S-EQA|家庭机器人数据集|情境问答数据集
具身抓取(Embodied Grasping)
智能体根据人类的指令完成抓取和放置物体的任务。这不仅需要对语言的理解,还需要精确的视觉感知和运动控制能力。
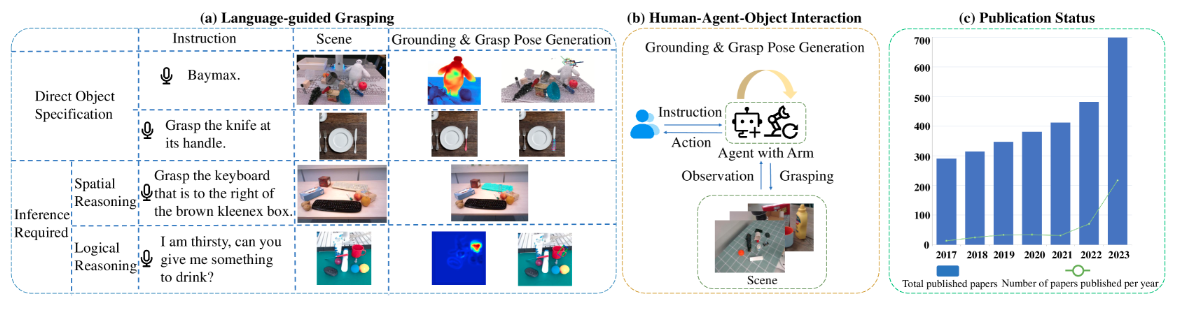
具身抓取任务的概述:a(演示了针对不同类型任务的语言引导抓取示例)b(提供了人-智能体-对象交互概述)c(抓取的结果)
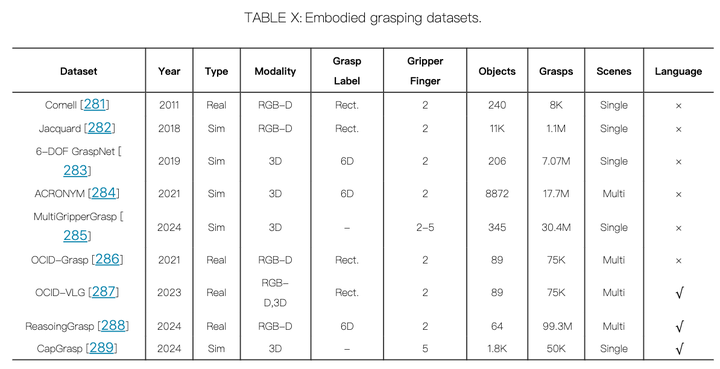
数据集:Cornell
数据集地址:Cornell|机器人抓取数据集|机器学习数据集
数据集:Jacquard
数据集地址:Jacquard Dataset|机器人抓取数据集|计算机视觉数据集
数据集:6-DOF GraspNet
数据集地址:6-DOF GraspNet|机器人技术数据集|抓取数据集
数据集:ACRONYM
数据集地址:ACRONYM|机器人抓取数据集|仿真技术数据集
数据集:MultiGripperGrasp
数据集地址:MultiGripperGrasp|机器人抓取数据集|机器人操作数据集
数据集:OCID-Grasp
数据集地址:OCID-Grasp|机器人抓取数据集|计算机视觉数据集
数据集:OCID-VLG
数据集地址:OCID-VLG
数据集:ReasoingGrasp
数据集地址:ReasoingGrasp|机器人抓取数据集|机器学习数据集
数据集:CapGrasp
数据集地址:CapGrasp
六、Embodied Agent(具身智能体)
具身人工智能的关键技术: 具身感知、具身交互、具身智能体、模拟到真实世界迁移。
具身智能体:是一种自主实体,能够感知其环境并采取行动以实现特定目标。
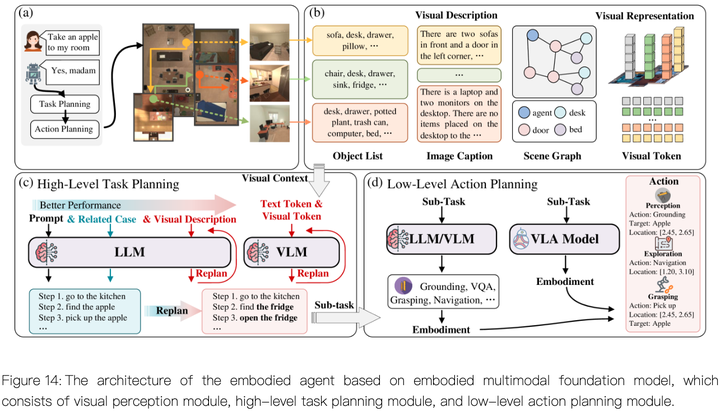
七、模拟到真实世界迁移(Sim-To-Real Adaptation)
具身人工智能的关键技术: 具身感知、具身交互、具身智能体、模拟到真实世界迁移。
模拟到真实世界的迁移:在具身智能中指的是将模拟环境中学习的技能或行为迁移到真实世界场景的过程。它涉及验证和改进在模拟环境中开发的算法、模型和控制策略的有效性,以确保它们能够在真实环境中稳健可靠地运行。
实现Sim-to-Real Adaptation 需要三个关键组件: Embodied World Model 、数据收集和训练方法以及Embodied Control 算法。
A. 具身世界模型(Embodied World Model)
模拟到真实世界迁移的关键在于创建于真实世界环境高度相似的模拟环境世界模型,帮助算法在迁移时更好的地泛化。
世界模型通过构建内部表征和预测未来状态,实现了从感知到决策的端到端映射。它不仅能够理解复杂的外部环境,还能通过预测未来动态来指导智能体做出合理行为。这种模型在自动驾驶、机器人技术和社会模拟等领域具有广泛的应用前景。
世界模型分为三种类型:
1、基于生成的模型:通过生成模型学习和理解物理规律。把这模型比作一个超级聪明的学生,它看了大量的图片、视频或点云数据(就是用激光扫描出来的物体形状),它学会了世界的样子,比如物体的形状、颜色、运动规律等。然后就可以自己“想象”出新的画面。比如夜晚满天星星的沙滩,它会根据之前学到的知识,画出一个有星星、海浪、沙滩的画面,而且这些元素看起来很真实。就好像你此刻 躺在沙滩看漫天的星星.
2、基于预测的模型:构建内部表示,通过预测下一个状态做出决策
3、基于知识的模型:将人工构建的知识注入模型,增强其对物理规律的理解
B.数据收集和训练
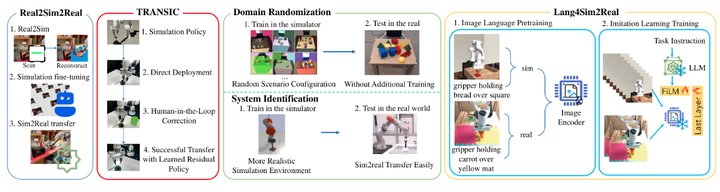
真实世界数据 :收集高质量的真实世界数据以训练大型模型,提升泛化能力。但这种方法需要大量的人力和物质资源,效率低下。
模拟数据:在模拟环境中收集数据,通常更高效且成本低,适合用于模型训练。
Sim-to-Real Paradigms:最近提出几种Sim-to-Real 迁移范式,以减少对大量真实世界演示数据的依赖,通过在模拟环境中进行大量学习,然后将他们迁移到真实世界设置中。
C . Embodied Control
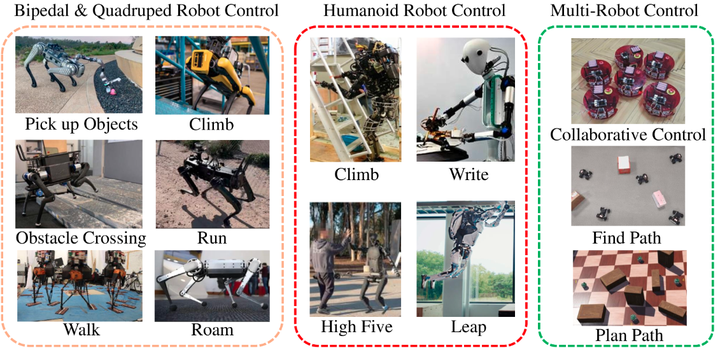
各种运动模式的具身控制示例
Embodied Control 通过与环境交互来学习,并使用奖励机制优化行为以获得最佳策略,从而避免传统物理建模方法的缺点。可以分为两类方法
深度强化学习(DRL):DRL 可以处理高维数据并学习复杂的行为模式,使其适合决策和控制。
模仿学习:为了减少数据使用量,提出模仿学习,它目的通过收集高质量的演示来最小化数据使用量。
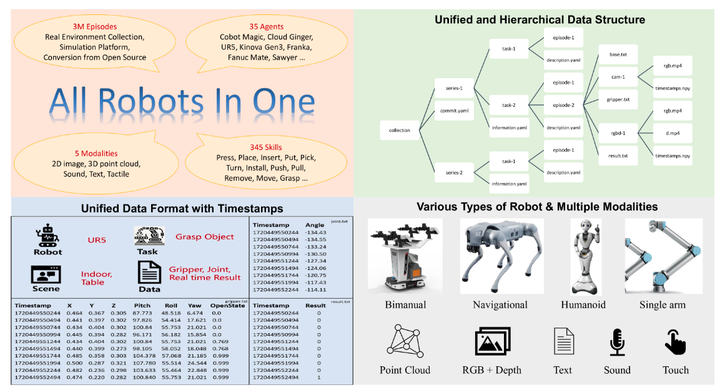
为了克服现有数据集的限制,ARIO (All Robots In One) 被引入,它是一种新的数据集标准,可以优化现有数据集并促进更通用和通用 embodied AI 代理的开发。
七、Challenges and Future Directions
面临的挑战:
1、高质量机器人数据集的获取
问题:获取足够的真实世界机器人数据既耗时又资源密集。仅依赖模拟数据会加剧模拟到现实(sim-to-real)的差距。
现状:尽管有一些大规模的数据集,但它们通常集中在特定任务或场景中,缺乏多样性和泛化能力。
解决方案:需要跨机构合作,开发更真实高效的模拟器,以提高模拟数据的质量。
2、复杂环境的认知:
问题:当前的Embodied AI系统在复杂、动态的现实环境中表现出有限的理解和执行能力。
现状:基于预训练语言模型(LLMs)的任务分解机制在简单任务规划中表现出色,但在复杂环境中缺乏具体场景理解。
解决方案:需要开发能够适应和泛化到复杂环境的架构,以实现更自然的语言指令理解和执行。
3、长跨度任务执行:
问题:执行单个指令可能涉及长跨度的任务,例如“打扫厨房”,需要机器人规划和执行一系列低级动作。
现状:当前的高级任务规划器在多样化场景中表现不足,缺乏对具体任务的调整能力。
解决方案:需要开发高效的规划器,具备强大的感知能力和常识知识,以更好地执行长跨度任务。
4、因果关系发现:
问题:现有的数据驱动的Embodied AI模型基于数据内在的相关性进行决策,缺乏对知识、行为和环境之间因果关系的理解。
现状:这导致模型在真实世界环境中难以以可解释、稳健和可靠的方式运行。
解决方案:需要通过因果推理和反事实推理来优化决策,减少探索迭代,提高决策的可靠性。
5、持续学习:
问题:在机器人应用中,持续学习对于在多样化环境中部署机器人学习策略至关重要,但目前这一领域仍处于探索阶段。
现状:一些研究关注了增量学习、快速运动适应和人机交互学习等子领域,但这些解决方案通常针对单一任务或平台。
解决方案:需要开发能够混合不同比例先验数据分布的方法,以缓解灾难性遗忘问题,并提高在线学习算法的训练稳定性和样本效率。
6、统一评估基准:
问题:目前存在许多用于评估低级控制策略的基准,但它们在评估的技能和使用的对象及场景方面存在显著差异。
现状:对于高级任务规划器,许多基准侧重于通过问答任务评估规划能力,但缺乏与低级控制策略的综合评估。
解决方案:需要开发能够全面评估Embodied AI系统的基准,涵盖从高级任务规划到低级控制策略的执行,以更全面地评估系统的能力。
未来发展方向:
1、多模态数据融合:
方向:将视觉、语言、触觉等多种模态的数据进行更深度的融合,以提高机器人的感知和理解能力。
2、强化学习与世界模型的结合:
方向:将强化学习(RL)与世界模型(World Models)相结合,以提高模型的泛化能力和适应性。
3、因果推理与反事实推理:
方向:开发能够进行因果推理和反事实推理的模型,以提高决策的可靠性和可解释性。
4、跨场景和跨任务的泛化能力:
方向:开发能够跨场景和跨任务进行泛化的模型,以提高机器人的适应性和灵活性。
5、人机协作与交互:
方向:开发能够与人类自然交互的机器人,以实现更高效的人机协作。
6、大规模数据集与预训练模型:
方向:开发更大规模的数据集和更强大的预训练模型,以提高机器人的泛化能力和适应性。
意义:大规模数据集和预训练模型可以为机器人提供更丰富的知识,使其更好地理解和执行任务。
7、硬件与软件的协同优化:
方向:开发能够与硬件协同优化的软件系统,以提高机器人的性能和效率。
八、论文中其他数据集信息
数据集:SUNCG
数据集介绍:一个大规模的合成3D室内场景数据集,包含超过45,000个精细建模的室内环境,涵盖了从客厅到厨房等多种房间类型。
数据集地址:SUNCG
数据集:Matterport3D
介绍:是一个大型RGB-D数据集,包含来自90个建筑规模场景的194,400个RGB-D图像的10,800个全景视图。
数据集地址:Matterport3D
数据集:SAPIEN
介绍:该数据集由加州大学圣地亚哥分校、斯坦福大学等机构联合创建,是一个大规模的 3D 交互模型数据集,专为机器人交互任务设计。
数据集地址:SAPIEN
数据集:ScanNet
介绍:ScanNet是一个大规模的3D场景数据集,它提供了丰富的室内场景重建和语义分割信息。
数据集地址:ScanNet
数据集:HM3D
介绍:Habitat-Matterport 3D(简称HM3D)是由Facebook Research和Matterport合作开发的一个大规模3D室内空间数据集。
数据集地址:HM3D|室内三维场景数据集|具身人工智能数据集
数据集:Open X-Embodiment
介绍:Open X-Embodiment Dataset 是由全球21个研究机构合作创建的机器人学习数据集,旨在为机器人操作任务提供大规模、多样化的数据支持。
数据集地址:Open X-Embodiment|机器人学习数据集|机器人操作数据集
数据集:GAPartNet
介绍:GAPartNet是由北京大学、清华大学、加州大学洛杉矶分校等机构共同构建的大型交互式部件级数据集,旨在推动跨品类通用对象感知与操作技能的研究。
数据集地址:GAPartNet|机器人视觉数据集|对象操作数据集
数据集:ARIO
介绍:ARIO数据集由南方科技大学、中山大学和鹏城实验室联合创建,旨在为多用途、通用型具身智能代理提供标准化的数据格式。
数据集地址:ARIO (All Robots In One)|具身智能数据集|数据标准化数据集
如果下载时间等待比较漫长,需要代下载数据集服务,请扫二维码咨询。



















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









