







关于为什么使用多个模型做问答知识融合,贴一段车轱辘话来说明几个重要的原因:
1. 多样性和丰富性
不同模型可能在不同类型的问题上表现优异。通过融合多个模型的答案,可以得到更全面和丰富的信息,覆盖更多的角度和细节。
2. 提高准确性
每个模型都有其优缺点,可能在某些领域表现较好,而在其他领域表现不佳。通过融合多个模型的答案,可以降低个别模型的偏差,提高整体的准确性。
3. 增强鲁棒性
使用多个模型可以提高系统对噪声和错误的鲁棒性。如果某个模型对特定输入产生不准确的答案,其他模型可能会提供更合适的替代方案,从而改善整体输出的质量。
4. 处理不同类型的问题
不同模型可能专注于不同的任务(如文本生成、分类、问答等),通过融合,可以更好地处理各种类型的问题,满足不同用户的需求。
5. 利用模型的专长
一些模型可能在特定领域有更强的表现,通过融合,可以利用各个模型的专长,为用户提供更专业的答案。
6. 减少偏见
单一模型可能受到训练数据的偏见影响。通过融合多个模型的答案,可以分散这种偏见,提供更客观的输出。
我计划选择三个模型和嵌入模型来做试验
1) internlm-7b-chat。InternLM是上海人工智能实验室开发的模型,Huggingface上的仓库可能属于InternLM团队。需要查一下正确的仓库名,可能类似“internlm/internlm-7b-chat”这样的结构。
2)Qwen-7b-chat,这是阿里通义千问的模型。正确的仓库名可能是“Qwen/Qwen-7B-Chat”,需要注意大小写,Huggingface仓库通常对大小写敏感。
3)是chatglm3-6b-chat,来自智谱AI。他们的模型通常以“THUDM/chatglm3-6b”这样的形式存在,但用户提到的是chatglm3-6b-chat,可能需要确认是否存在对应的仓库,或者是否是指版本的不同。
4)嵌入模型是bge-large-zh-v1.5,BAAI的模型,仓库名应该是“BAAI/bge-large-zh-v1.5”。
下载三个模型和一个嵌入模型。需要提供Huggingface的下载命令。首先得确认每个模型在Huggingface Hub上的具体名称,因为用户给出的路径可能不是直接的仓库名。
# 安装 huggingface_hub 工具(如果未安装)
pip install huggingface_hub
# 下载 InternLM-7B-Chat 模型
huggingface-cli download --resume-download internlm/internlm-chat-7b --local-dir ./base_model/internlm-chat-7b
# 下载 Qwen-7B-Chat 模型
huggingface-cli download --resume-download Qwen/Qwen-7B-Chat --local-dir ./base_model/Qwen-7b-chat
# 下载 ChatGLM3-6B-Chat 模型
huggingface-cli download --resume-download THUDM/chatglm3-6b --local-dir ./base_model/chatglm3-6b-chat
# 下载 BGE 中文嵌入模型
huggingface-cli download --resume-download BAAI/bge-large-zh-v1.5 --local-dir ./base_model/bge-large-zh-v1.5embedding 模型采用 BGE-large-zh-v1.5, 其它项目用下来这个开源embedding模型效果最好,top5召回和openai embedding模型差不多
pdf 解析参考了deepseek 给得答案
- 细粒度和完整上下文之间,小块的metadata存的是大块id,检索小块,利用id合并上下文
- 尽量去掉一些解析不正常的特殊符号啥的,保持语义的的连贯性,毕竟开源的模型理解能力有限
import re
import tqdm
import spacy
import PyPDF2
from some_module import Document # 假设 Document 在某个模块中定义
def extract_page_text(filepath, max_len=256):
# 初始化 spaCy 中文模型
spliter = spacy.load("zh_core_web_sm")
chunks = []
# 打开 PDF 文件
with open(filepath, 'rb') as f:
pdf_reader = PyPDF2.PdfReader(f)
page_count = 10 # 从第10页开始
pattern = re.compile(r'^\d{1,3}') # 编译正则表达式以提高效率
for page in tqdm.tqdm(pdf_reader.pages[page_count:]):
page_text = page.extract_text().strip()
if not page_text: # 检查文本是否为空
continue
# 清理文本
raw_text = [line.strip() for line in page_text.split('\n')]
new_text = '\n'.join(raw_text[1:]) # 去掉第一行
new_text = pattern.sub('', new_text).strip() # 移除数字开头的行
if len(new_text) <= 10:
continue # 跳过过短的文本
current_chunk = ""
for sentence in spliter(new_text).sents:
sentence_text = sentence.text
if len(current_chunk) + len(sentence_text) <= max_len:
current_chunk += sentence_text
else:
chunks.append(Document(page_content=current_chunk, metadata={'page': page_count + 1}))
current_chunk = sentence_text # 开始新的 chunk
# 添加最后一个 chunk(如果有的话)
if current_chunk:
chunks.append(Document(page_content=current_chunk, metadata={'page': page_count + 1}))
page_count += 1
# 合并相似的 chunks
cleaned_chunks = []
i = 0
while i < len(chunks):
current_chunk = chunks[i]
if i + 1 < len(chunks):
next_chunk = chunks[i + 1]
if len(next_chunk.page_content) < 0.5 * len(current_chunk.page_content):
new_chunk = Document(page_content=current_chunk.page_content + next_chunk.page_content, metadata=current_chunk.metadata)
cleaned_chunks.append(new_chunk)
i += 2 # 跳过下一个 chunk
else:
cleaned_chunks.append(current_chunk)
i += 1
else:
cleaned_chunks.append(current_chunk)
i += 1
return cleaned_chunks- 初始化一个空字符串
current_chunk用于存储当前的文本块。 - 使用 spaCy 对
new_text进行句子分割,"zh_core_web_sm"是 小型模型(sm),适用于轻量级任务。。 - 遍历每个句子,如果当前块加上新句子的长度不超过
max_len,则将句子添加到current_chunk。 - 如果超过最大长度,则将当前块作为一个
Document对象添加到chunks列表中,并将current_chunk重置为当前句子。 - 在处理完所有句子后,如果
current_chunk仍有内容,则将其添加到chunks列表中。 - 合并相似块: 初始化一个空列表
cleaned_chunks用于存储合并后的文本块。获取当前块和下一个块,检查下一个块的长度是否小于当前块的一半。如果是,则合并这两个块,并将合并后的块添加到cleaned_chunks中,同时跳过下一个块。
提示词模板,包含提示词和召回材料的组织格式
def build_template():
prompt_template = "你是一个汽车驾驶安全员,精通有关汽车驾驶、维修和保养的相关知识。请你基于以下汽车手册材料回答用户问题。回答要清晰准确,包含正确关键词。不要胡编乱造。\n" \
"以下是材料:\n---" \
"{}\n" \
"用户问题:\n" \
"{}\n"
return prompt_template使用一个汽车知识pdf文件作为问答语料

使用了FAISS语义召回
embedding_model = BGEpeftEmbedding(model_path=embedding_path)
db = FAISS.from_documents(docs, embedding_model)
db.save_local(folder_path='./vector', index_name='index_256')- FAISS这是一个高效的相似性搜索库,通常用于处理大规模的向量数据。可以快速找到相似的向量。from_documents:这是一个类方法,用于从给定的文档列表(
docs)和嵌入模型创建一个 FAISS 数据库。 - 加载一个嵌入模型。
- 将一组文档转换为向量表示,并使用 FAISS 创建一个相似性搜索数据库。
- 最后将该数据库保存到本地,以便后续可以快速进行相似性检索或查询。这种方法通常用于构建智能搜索引擎、推荐系统或问答系统等应用。
使用这样格式的json文件作为测试问题
{
"question": "我应该在哪里添加香氛精油?",
"answer_1": "",
"answer_2": "",
"answer_3": ""
}主程序代码
def main():
filepath = "./data/汽车知识.pdf"
from pdfparser import extract_page_text
docs = extract_page_text(filepath=filepath, max_len=256)
model1 = "./base_model/internlm-7b-chat"
model2 = "./base_model/Qwen-7b-chat"
model3 = "./base_model/chatglm3-6b-chat"
embedding_path ="./base_model/bge-large-zh-v1.5"
llm1 = LLMPredictor(model_path=model1, is_chatglm=False, device='cuda:0')
llm2 = LLMPredictor(model_path=model2, is_chatglm=False, device='cuda:1')
llm3 = LLMPredictor(model_path=model3, is_chatglm=True, device='cuda:2')
embedding_model = BGEpeftEmbedding(model_path=embedding_path)
db = FAISS.from_documents(docs, embedding_model)
db.save_local(folder_path='./vector', index_name='index_256')
# db = FAISS.load_local(folder_path='./vectors', index_name='index', embeddings=embeddings)
result_list = []
with open('./data/test.json', 'r', encoding='utf-8') as f:
result = json.load(f)
for i, line in enumerate(result):
print(f"question {i}:", line['question'])
search_docs = db.similarity_search(line['question'], k=5)
res1 = llm1.predict(search_docs, line['question'])
res2 = llm2.predict(search_docs, line['question'])
res3 = llm3.predict(search_docs, line['question'])
print('\n')
line['answer_1'] = res1
line['answer_2'] = res2
line['answer_3'] = res3
result_list.append(line)
with open('./data/submit.json', 'w', encoding='utf-8') as f:
json.dump(result_list, f, ensure_ascii=False, indent=4)调用模型predict方法
def predict(self, context, query):
# context List [doc]
# query str
content = ""
for i, doc in enumerate(context):
content += doc.page_content + "\n---\n"
#content = "\n".join(doc.page_content for doc in context) # 直接使用这个效果貌似更好
input_ids = self.tokenizer(content, return_tensors="pt", add_special_tokens=False).input_ids
if len(input_ids) > self.max_token:
content = self.tokenizer.decode(input_ids[:self.max_token-1])
warnings.warn("texts have been truncted")
content = self.prompt_template.format(content, query)
# print(prompt)
response, history = self.model.chat(self.tokenizer, content, history=[], **self.kwargs)
return response跑一下脚本,报错
ImportError: This modeling file requires the following packages that were not found in your environment: flash_attn. Run `pip install flash_attn`
但是pip install flash_attn 一直无法安装成功,查了下总结起来这几点
1、默认pip flash-attn 的时候,如果你之前没安装ninja会自动安装。
2、安装了ninja还要用echo $?来检测ninja是否正常。
3、正常的情况下。报了error: <urlopen error [Errno 110] Connection timed out>。说明网络超时,还得用whl文件这才能安装上flash-attn。
再次运行成功
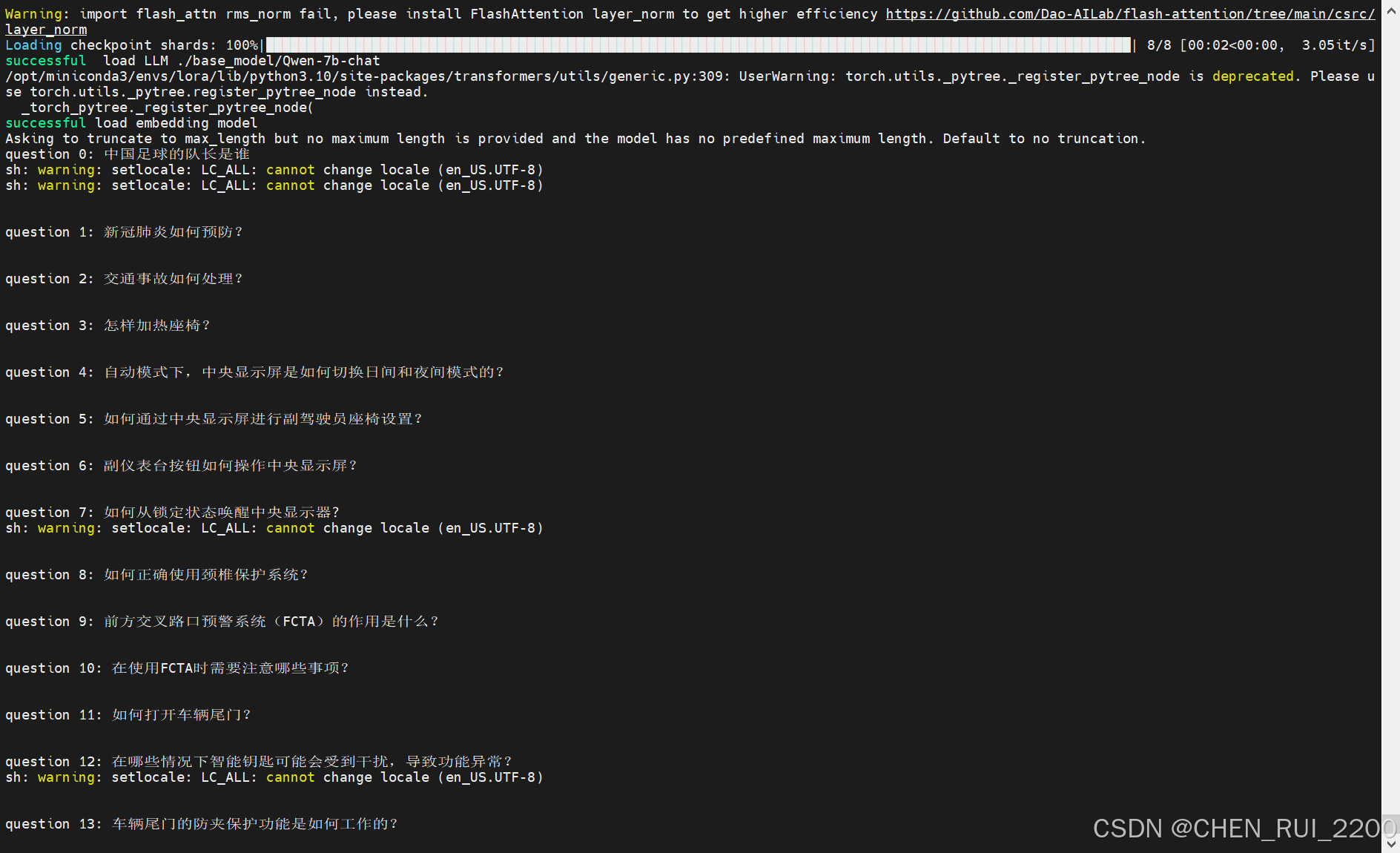
问答结束后查看下输出的submit.json
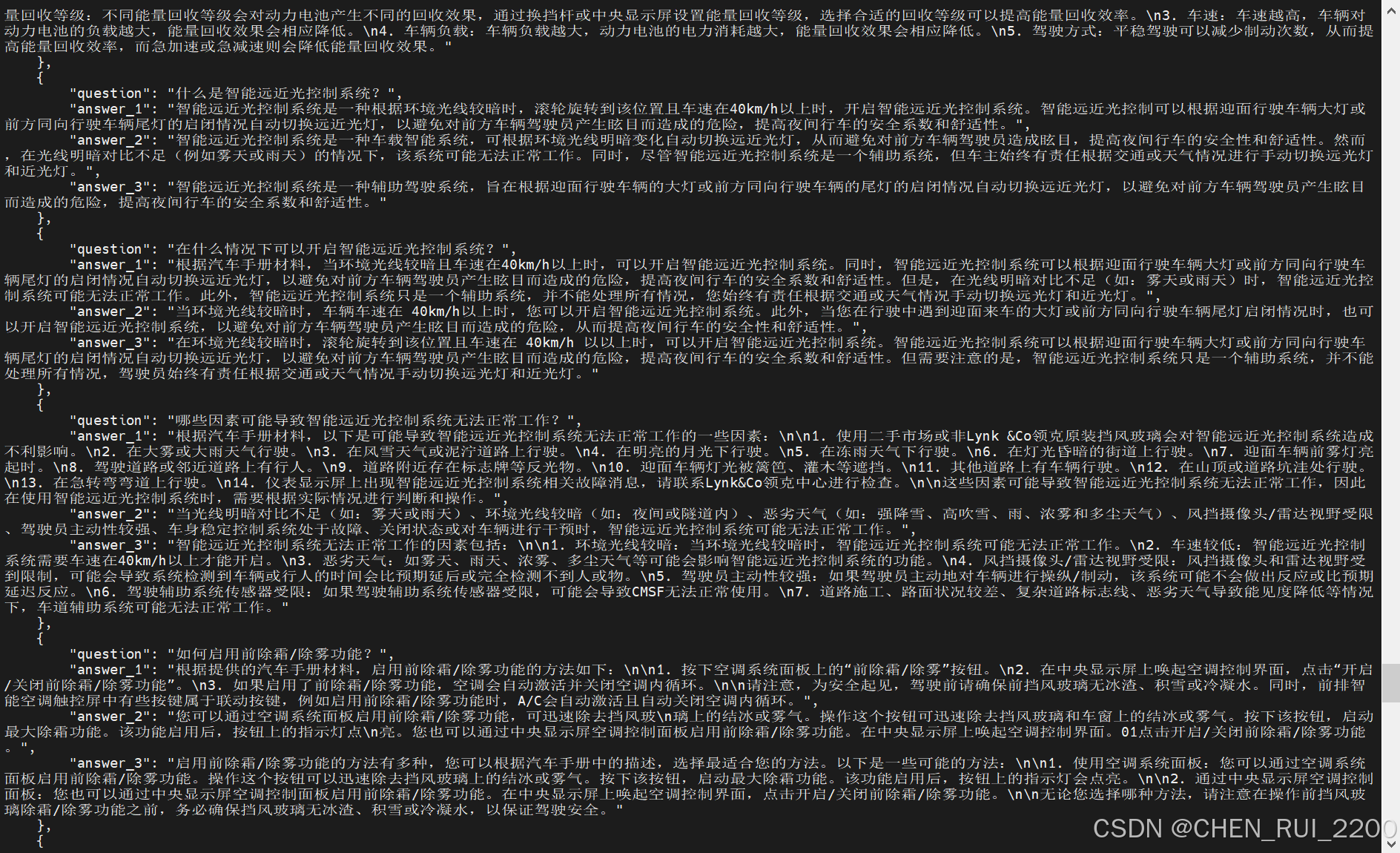
[
...
{
"question": "如何正确使用颈椎保护系统?",
"answer_1": "首先,颈椎保护系统应该作为安全带的补充装置使用。在使用安全带时,必须正确佩戴,确保其牢固贴身,无扭曲。如果发生追尾事故,即使座椅外观未受损,也必须由Lynk&Co领克中心检查前排靠背。如果前排座椅靠背与已折叠后排座椅靠背接触,可能会影响颈椎保护系统功能。后排座椅上安装了儿童安全座椅时,必须向前调节前排座椅,确保其不接触后排座椅。在使用颈椎保护系统时,头枕必须拉紧,但不得将安全带从肩部滑落。此外,请勿将安全带从后背绕过、从胳膊下面绕过或绕过颈部。最后,如果安全带无法正常使用,请联系Lynk&Co领克中心进行处理。",
"answer_2": "颈椎保护系统作为安全带的补充装置。在发生追尾事故时,如果未使用或未正确使用安全带,颈椎保护系统会降低作用。建议您在舒适的前提下尽量坐直,背部靠在靠背上。如果座椅靠背已折叠,必须固定后备厢内物品,防止追尾事故时,物品向前滑动抵住前排座椅靠背。如果座椅靠背已折叠或后排座椅上安装了儿童安全座椅,必须向前调节前排座椅,确保其不接触后排座椅。",
"answer_3": "正确使用颈椎保护系统的步骤如下:\n\n1. 首先,要确保安全带已正确系好,并确保它牢固贴身,无扭曲。安全带应远离您的面部和颈部,但不得从肩部滑落。\n\n2. 如果您乘坐的是后排座椅,请确保头枕已安装牢固。头枕调整不正确会增加碰撞时颈部受伤的风险。\n\n3. 在车辆行驶过程中,不要试图自行调整颈椎保护系统中的任何部件。如果遇到问题,请及时联系Lynk&Co领克中心进行检查和维修。\n\n4. 如果您在车辆发生追尾事故后,座椅外观并未受损,仍需由Lynk&Co领克中心检查前排靠背,以确保颈椎保护系统内部的某些部件是否需要更换。\n\n5. 在舒适的前提下,乘员应尽量坐直,背部靠在靠背上。如果座椅靠背已折叠,必须固定后备厢内物品,防止追尾事故时,物品向前滑动抵住前排座椅靠背。\n\n6. 请勿尝试自行维修颈椎保护系统中的任何部件。\n\n7. 如果您有人乘坐的后排座椅的头枕被拆除,请勿驾驶车辆。头枕调整不正确会增加碰撞时颈部受伤的风险。\n\n8. 如果您需要对颈椎保护系统进行调整,请参考车辆手册中的相关章节,并按照手册的指导进行操作。"
},
{
"question": "前方交叉路口预警系统(FCTA)的作用是什么?",
"answer_1": "前方交叉路口预警系统(FCTA)的作用是在车速处于4-15km/h范围内,车辆驶出停车位或经过交叉路口时,若前方交叉路口预警系统(FCTA)监测到存在前方侧向碰撞风险,将通过仪表提示信息和蜂鸣声提醒驾驶注意观察前方道路情况,从而降低发生前方侧向碰撞的风险。",
"answer_2": "FCTA的作用是在车速在4-15km/h范围内,车辆驶出停车位或经过交叉路口时,通过仪表提示信息和蜂鸣声提醒驾驶注意观察前方道路情况,从而降低发生前方侧向碰撞的风险。",
"answer_3": "前方交叉路口预警系统(FCTA)的作用是提醒驾驶员在驶出停车位或经过交叉路口时注意观察前方道路情况,降低发生前方侧向碰撞的风险。当车速处于4-15km/h范围内,FCTA会监测到存在前方侧向碰撞风险,并通过仪表提示信息和蜂鸣声提醒驾驶注意观察前方道路情况。"
},
{
"question": "在使用FCTA时需要注意哪些事项?",
"answer_1": "在使用FCTA时,需要注意以下几点:\n\n1. FCTA属于驾驶辅助系统,并不能确保在任何情况下均能正常工作,紧急情况时,驾驶员应及时接管车辆。\n2. 虽然车辆配备有FCTA,但为确保行驶安全,通过交叉路口或其他视线受阻的环境前应环顾四周,确认周围环境无危险。\n3. FCTA主要对横穿的轿车/SUV、客车/卡车等车辆类型作用,对三轮车、外表不规则的车辆、行人、骑行者、动物具有识别的局限性而不起作用。\n4. 对于系统识别的有效目标,根据车辆、场景、路况的不同,FCTA并非总能达到相同的性能水平。\n5. 当猛打方向盘或方向盘转角过大时,系统功能会被限制。\n\n此外,用户还需要了解FCTA和FCW是同一设置项,通过中央显示屏设置灵敏度时相当于同步设置了FCTA和FCW的灵敏度。FCW系统可对潜在碰撞发出预警,但是它不可能缩短您的反应时间。FCW绝不能替代驾驶员对交通状况的注意力或驾驶员对安全驾驶车辆的责任。",
"answer_2": "在使用FCTA时,需要注意以下几点:\n1. 请务必保持警惕,当系统无法正常工作时,驾驶员应及时接管车辆;\n2. 在通过交叉路口或其他视线受阻的环境前应环顾四周,确认周围环境无危险;\n3. FCTA主要对横穿的轿车/SUV、客车/卡车等车辆类型作用,对三轮车、外表不规则的车辆、行人、骑行者、动物具有识别的局限性而不起作用;\n4. 对于系统识别的有效目标,根据车辆、场景、路况的不同,FCTA并非总能达到相同的性能水平;\n5. 当猛打方向盘或方向盘转角过大时,系统功能会被限制。",
"answer_3": "在使用FCTA时,需要注意以下事项:\n\n1. FCTA属于驾驶辅助系统,并不能确保在任何情况下都能正常工作,紧急情况时,驾驶员应及时接管车辆。\n2. 通过交叉路口或其他视线受阻的环境前应环顾四周,确认周围环境无危险。\n3. FCTA主要对横穿的轿车/SUV、客车/卡车等车辆类型作用,对三轮车、外表不规则的车辆、行人、骑行者、动物具有识别的局限性而不起作用。\n4. 对于系统识别的有效目标,根据车辆、场景、路况的不同,FCTA并非总能达到相同的性能水平。\n5. 当猛打方向盘或方向盘转角过大时,系统功能会被限制。\n6. FCTA和FCW是同一设置项,通过中央显示屏设置灵敏度时相当于同步设置了FCTA和FCW的灵敏度。\n7. 如果驾驶辅助系统传感器受限,可能会导致FCTA无法正常使用,请参见驾驶辅助系统传感器章节。\n8. 设置FCTA灵敏度时,请注意前方交叉路口预警系统的局限性。\n9. FCW系统可对潜在碰撞发出预警,但是它不可能缩短您的反应时间,FCW系统绝不能替代驾驶员对交通状况的注意力或驾驶员对安全驾驶车辆的责任。"
},
...
]增加点写在后面的,上面使用FAISS语义召回还属于比较粗糙的方式
这里尝试一个例子rank_bm25 + rerank方式的召回
from rank_bm25 import BM25Okapi
from nltk.tokenize import word_tokenize
# 假设有一个文档集合
documents = [
"人工智能正在改变世界。",
"深度学习是机器学习的一个分支。",
"搜索引擎使用 BM25 进行文档检索。",
"大型语言模型可以用于自然语言处理任务。"
]
# 进行分词(BM25 需要基于单词计算权重)
tokenized_corpus = [word_tokenize(doc) for doc in documents]
# 构建 BM25 索引
bm25 = BM25Okapi(tokenized_corpus)
# 查询
query = "机器学习和人工智能"
tokenized_query = word_tokenize(query)
# 计算 BM25 相关性得分,返回 Top-K
scores = bm25.get_scores(tokenized_query)
top_k_indices = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:3]
# 输出召回的文档
bm25_retrieved_docs = [documents[i] for i in top_k_indices]
print("BM25 召回的文档:", bm25_retrieved_docs)
from sentence_transformers import CrossEncoder
# 加载一个 Rerank 模型(MS MARCO 预训练的 Cross-Encoder)
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
# 计算 Rerank 分数
query = "机器学习和人工智能"
rerank_inputs = [(query, doc) for doc in bm25_retrieved_docs]
rerank_scores = reranker.predict(rerank_inputs)
# 按 Rerank 得分排序
reranked_results = sorted(zip(bm25_retrieved_docs, rerank_scores), key=lambda x: x[1], reverse=True)
# 输出最终排序的文档
print("最终 Rerank 排序的文档:")
for doc, score in reranked_results:
print(f"Score: {score:.4f} - {doc}")
输出
最终 Rerank 排序的文档:
Score: 6.4217 - 深度学习是机器学习的一个分支。
Score: 5.9995 - 人工智能正在改变世界。
Score: 3.0660 - 搜索引擎使用 BM25 进行文档检索。



















 4299
4299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











