









代码:mllm
1. 整体流程
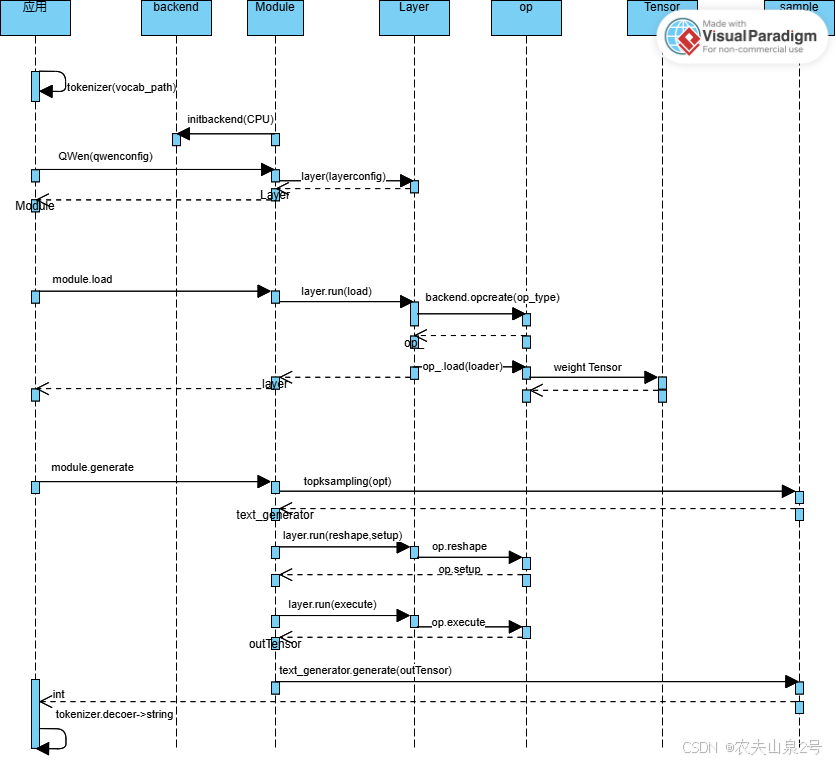
2. 模型结构组织
// TODO:
/*
* ┌───────┬──────┬───────┬────────┬───────────┬─────────┬─────────┬──────┬──────────────────────┬─────────────────────────┐
* │ │ │ │ │ │ │ │ │ │ │
* │ │ │ │ │ │ │ │ │ │ │
* │ │ │ │ │ │ │ │ │ │ │
* │ │ │ │ │ │ │ │ │ │ │
* │ │Index │ │ │ │ │ │ │ │ │
* │ │ Len │ │ │ │ │ │ │ │ │
* │ Magic │ INT │ Name │Name │ Weights │ Offset │ DataType│.... │ Weights Contents │ Weights Contents │
* │ │ │ Length│String │ Length │ INT │ INT │ │ │ │
* │ │ │ INT │ │ INT │ │ │ │ │ │
* │ │ │ │ │ │ │ │ │ │ │
* │ │ │ │ │ │ │ │ │ │ │
* │ │ │ │ │ │ │ │ │ │ │
* │ │ │ │ │ │ │ │ │ │ │
* └───────┴──────┴───────┴────────┴───────────┴─────────┴─────────┴──────┴──────────────────────┴─────────────────────────┘
* Weights File Structure
*/
int(20012)+u64(info)+[4+len(name)+8+8+4]*n + [weight]*n
import argparse
import json
import struct
from functools import reduce
from io import BufferedWriter
import os
import torch
MAGIC_NUMBER = 20012
file_map = {}
class Tensor:
name: str
offset: int
size: int
dtype: int
def __init__(self, name: str, dtype: int):
self.name = name
self.dtype = dtype
# One Tensor Index Item Contains: Name_Len(Int)+Name(str)+Weights_Len(UInt64)+Offset(UInt64)+DataType(Int)
def calc_tensors_index_table_size(name: str):
return 4 + len(name) + 8 + 8 + 4
class Writer:
writer: BufferedWriter
tensors_map: [str, Tensor]
tensors_name: [str]
def __init__(self, path: str):
self.tensors_map = {}
self.tensors_name = []
self.writer = open(path, "wb+")
self.writer.seek(0)
self.write_int(MAGIC_NUMBER)
def __torch_dtype_to_int(self, dtype: torch.dtype) -> int:
if dtype == torch.float32 or dtype == torch.bfloat16:
return 0
elif dtype == torch.float16:
return 1
elif dtype == torch.int8 or dtype == torch.bool:
return 16
elif dtype == torch.int32:
return 18
else:
raise Exception(f"Unknown dtype: {dtype}")
def write_int(self, val: int):
self.writer.write(struct.pack("<i", val))
def write_float(self, val: float):
self.writer.write(struct.pack("<f", val))
def write_u64(self, val: int):
self.writer.write(struct.pack("<Q", val))
def write_str(self, val: str):
self.writer.write(struct.pack("<i", len(val)))
self.writer.write(val.encode("utf-8"))
def write_tensor(self, tensor: torch.Tensor, name: str) -> [int, int]:
tensor_idx = Tensor(name=name, dtype=self.__torch_dtype_to_int(tensor.dtype))
self.tensors_map[name] = tensor_idx
offset = self.writer.tell()
if tensor.dtype == torch.bfloat16: # to float 16
tensor_numpy = tensor.detach().to(torch.float32).numpy()
elif tensor.dtype == torch.bool or tensor.dtype == torch.int8: # exported model for QNN int8
tensor_numpy = tensor.detach().to(torch.int8).numpy()
else:
tensor_numpy = tensor.numpy()
tensor_numpy.tofile(self.writer)
size = self.writer.tell() - offset
tensor_idx.size = size
tensor_idx.offset = offset
return offset, size
def write_tensor_index(
self,
):
self.writer.seek(4 + 8)
for tensor_name in self.tensors_name:
tensor = self.tensors_map[tensor_name]
# self.write_int(len(tensor.name))
tensor.name = tensor.name.replace("_weight", ".weight")
tensor.name = tensor.name.replace("_bias", ".bias")
# todo: nort used in GTEST
# tensor.name = key_map(tensor.name, args.type)
self.write_str(tensor.name)
self.write_u64(tensor.size)
self.write_u64(tensor.offset)
self.write_int(tensor.dtype)
print(f"Write tensor {tensor.name} to {tensor.offset} with size {tensor.size}")
def write_tensor_index_padding(self, tensors_name: [str]):
if len(tensors_name) > 0:
self.tensors_name = tensors_name
padding_size = reduce(
lambda x, y: x + y, map(calc_tensors_index_table_size, tensors_name)
)
self.writer.seek(4) # magic number的4字节
self.write_u64(padding_size) # tensor信息字节
print(f"Padding size: {padding_size}")
self.writer.write(b"\x00" * padding_size)
self.writer.flush()
return
else:
raise Exception("No tensors to write")
def close(self):
self.writer.close()
def get_tensor(model: dict, key: str, index_: dict):
if index_ is not None and isinstance(index_, dict) and "weight_map" in index_.keys():
if key in index_["weight_map"].keys():
model_ = file_map[index_["weight_map"][key]]
if args.type == "torch":
return model_[key]
if args.type == "safetensor":
return model_.get_tensor(key)
else:
raise Exception(f"Tensor {key} not found in index")
if key in model.keys():
if args.type == "torch":
return model[key]
if args.type == "safetensor":
return model.get_tensor(key)
else:
raise Exception(f"Tensor {key} not found in model")
def all_keys(model: dict, index_: dict):
global file_map
all_keys_name = []
if index_ is not None and isinstance(index_, dict) and "weight_map" in index_.keys():
json_pwd = os.path.dirname(args.input_model.name)
for (key, val) in index_["weight_map"].items():
all_keys_name.append(key)
if val is not None and val not in file_map.keys():
# JOIN PATH
val_path = os.path.join(json_pwd, val)
print(val_path)
if args.type == "torch":
file_map[val] = torch.load(val_path, weights_only=True)
else:
file_map[val] = safe_open(val_path, framework="pt")
else:
for key in model.keys():
if not key.startswith("_"):
if args.type == "torch":
val = model[key]
if args.type == "safetensor":
val = model.get_tensor(key)
if isinstance(val, torch.Tensor):
all_keys_name.append(key)
elif isinstance(val, dict):
all_keys_name.extend(all_keys(val))
else:
pass
return all_keys_name
def process_str(name: str, type: str='dense'):
if type == 'dense' or ('down_proj.weight' not in name):
return name
return name.replace('weight', 'weight_T')
def process(name: str, ten: torch.Tensor, type: str='dense'):
if type == 'dense' or ('down_proj.weight' not in name):
return name, ten
new_name = name.replace('weight', 'weight_T')
transposed_tensor = ten.transpose(-2, -1).contiguous()
return new_name, transposed_tensor
if __name__ == "__main__":
global args
parser = argparse.ArgumentParser()
parser.add_argument(
"--input_model", type=argparse.FileType("r"), default="/home/hub/Qwen1.5-0.5B/model.safetensors"
)
parser.add_argument("--output_model", type=str, default="output/qwen1.5-0.5b-fp32.mllm")
parser.add_argument(
"--type",
choices=["torch", "safetensor"],
default="safetensor",
)
parser.add_argument(
"--model_type",
choices=["dense", "sparse"],
default="dense",
)
model = None
index_ = None
args = parser.parse_args()
if args.type == "torch":
if args.input_model.name.endswith(".json"):
if os.path.basename(args.input_model.name) != "pytorch_model.bin.index.json":
raise Exception("Only support pytorch_model.bin.index.json")
index_ = json.load(args.input_model)
else:
model = torch.load(args.input_model.name)
if isinstance(model, dict) and "model" in model.keys():
model = model["model"]
elif args.type == "safetensor":
from safetensors import safe_open
if args.input_model.name.endswith(".json"):
index_ = json.load(args.input_model)
else:
tensors = {}
args.input_model.close()
model = safe_open(args.input_model.name, framework="pt")
for key in model.keys():
tensors[key] = model.get_tensor(key)
else:
raise Exception("Unknown type")
writer = Writer(args.output_model)
model_keys = all_keys(model, index_)
writer.write_tensor_index_padding([process_str(name, args.model_type) for name in model_keys])
for key in model_keys:
tensor = get_tensor(model, key, index_)
key, tensor = process(key, tensor, args.model_type)
if tensor.dtype != torch.bool or tensor.dtype != torch.int8:
tensor = tensor.float()
offset, size = writer.write_tensor(tensor, key)
print(f"Get tensor {key} to {offset} with size {size}")
writer.write_tensor_index()
1 模型导出
● 模型格式定义
● 模型参数写入到 bin 文件
2 推理框架中模型定义
● 用自己写的 module+layer 类来实现 graph 的构建,因为模型文件中是没有计算图的,所以需要在推理框架中再定义一遍计算图(手动)
class QWenForCausalLM final : public Module {
public:
QWenForCausalLM(QWenConfig &config) {
auto names = config.names_config;
hidden_size = config.hidden_size;
tie_embedding_words = config.tie_embedding_words;
embedding = Embedding(config.vocab_size, config.hidden_size, names.token_embd_name);
model = QWenModel(config, names, names.blk_name);
// Qwen-0.5 use tied embedding
// Others use nn.Linear()
if (tie_embedding_words) {
lm_head = Parameter(1, config.vocab_size, 1, config.hidden_size,
names.token_embd_name + ".weight");
} else {
lm_head_layer =
Linear(config.hidden_size, config.vocab_size, false, names.lm_head_name);
}
}
std::vector<Tensor> Forward(std::vector<Tensor> inputs, std::vector<std::any> args) override {
auto x = embedding(inputs[0]);
// go through model
auto outputs = model({x})[0];
if (tie_embedding_words) {
outputs = Tensor::mm(outputs, lm_head().transpose(Chl::SEQUENCE, Chl::DIMENSION));
} else {
outputs = lm_head_layer(outputs);
}
return {outputs};
}
void clear_kvcache() override {
model.clear_kvcache();
}
private:
int hidden_size;
bool tie_embedding_words;
Layer embedding;
Parameter lm_head;
Layer lm_head_layer;
QWenModel model;
};
其核心有 3 个类
● module:类似于 torch 中的 module
● layer+op:torch.layer, layer 的结构参数,创建 op,加载 layer 权重参数
● tensor:torch.tensor,做了很多重载,使用方式类似于 torch
3 op load
● 根据每个 layer 初始化时的名字,找到模型 bin 文件中对应的权重,再载入。
● 所有 layer 读取权重文件
ErrorCode CPUEmbedding::load(AbstructLoader &loader) {
weight_.setName(name() + ".weight");
weight_.reshape(1, 1, vocabSize_, hiddenSize_);
if (loader.getDataType(weight_.name()) != MLLM_TYPE_COUNT) {
weight_.setDtype(loader.getDataType(weight_.name()));
weight_.alloc();
loader.load(&weight_);
} else {
weight_.setDtype(MLLM_TYPE_F32);
weight_.alloc();
}
return Op::load(loader);
}
4 op reshape
● prefill/decoder 两个阶段,输入 seq 的长度是不定的。所以在推理之前需要做一个 reshape,就是根据输入 tensor 的 shape,将每一层输出 tensor 的 shape 计算出来。
ErrorCode CPUEmbedding::reshape(vector<shared_ptr<Tensor>> inputs, vector<shared_ptr<Tensor>> outputs) {
assert(inputs.size() == 1);
assert(outputs.size() == 1);
auto input = inputs[0];
auto output = outputs[0];
// Input: [batch, 1, sequence, 1]
output->reshape(input->batch(), 1, input->sequence(), hiddenSize_);
// outputs[0]->setDtype(activationDtype());
return Op::reshape(inputs, outputs);
}
5 op 执行
op 执行,将结果写入到每层的 outtensor
ErrorCode CPUEmbedding::execute(vector<shared_ptr<Tensor>> inputs, vector<shared_ptr<Tensor>> outputs) {
assert(inputs.size() == 1);
assert(outputs.size() == 1);
auto &input = inputs[0];
auto &output = outputs[0];
switch (weight_.dtype()) {
case MLLM_TYPE_F32: {
for (int batch = 0; batch < input->batch(); ++batch) {
for (int head = 0; head < input->head(); ++head) { // NOLINT(*-use-default-none)
#pragma omp parallel for num_threads(thread_count)
for (int seq = 0; seq < input->sequence(); ++seq) {
#ifdef USE_QNN
if ((int)input->dataAt<float>(batch, head, seq, 0) == vocabSize_) {
memset(output->hostPtr<float>() + output->offset(batch, head, seq, 0), 0, output->dimension() * sizeof(float));
continue;
}
#endif
auto seq__ = input->dataAt<float>(batch, head, seq, 0);
if (seq__ >= 0) {
memcpy(output->hostPtr<float>() + output->offset(batch, head, seq, 0),
weight_.hostPtr<float>() + weight_.offset(0, 0, (int)seq__, 0),
weight_.dtypeSize() * hiddenSize_);
}
}
}
}
break;
}
case MLLM_TYPE_Q4_0: {
for (int batch = 0; batch < input->batch(); ++batch) {
for (int head = 0; head < input->head(); ++head) {
#pragma omp parallel for num_threads(thread_count)
for (int seq = 0; seq < input->sequence(); ++seq) {
auto seq__ = input->dataAt<float>(batch, head, seq, 0);
if (seq__ >= 0) {
dequantize_row_q4_0(weight_.hostPtr<block_q4_0>() + weight_.offset(0, 0, (int)seq__, 0) / (QK4_0),
output->hostPtr<float>() + output->offset(batch, head, seq, 0),
hiddenSize_);
}
}
}
}
break;
}
6 sample 采样
● 将最后一个 seq 的输出,取出来按 topk,topp,greadysearch 进行采样
unsigned int _LlmTextGenerateTopkSamplingMethod::generate(Tensor &t) {
auto argmax = [](const std::vector<float> &vec) -> unsigned int {
return std::distance(vec.begin(), std::max_element(vec.begin(), vec.end()));
};
if (m_k == 0 || m_k == 1) {
std::vector<float> scores;
this->_tensor_to_vec(t, scores);
return argmax(scores);
}
std::vector<std::pair<float, unsigned int>> scores;
this->_tensor_to_vec_with_idx(t, scores);
// find top k
std::partial_sort(scores.begin(), scores.begin() + m_k, scores.end(),
[](std::pair<float, unsigned int> a, std::pair<float, unsigned int> b) { return a.first > b.first; });
std::vector<float> top_k_elements(m_k, 0.f);
std::vector<unsigned int> top_k_elements_idx(m_k, 0);
for (int i = 0; i < m_k; ++i) {
top_k_elements[i] = scores[i].first;
top_k_elements_idx[i] = scores[i].second;
}
// softmax with temperature
std::vector<float> softmax(top_k_elements.size(), 0.f);
double max_logit = top_k_elements[argmax(top_k_elements)];
double sum_exp = 0.f;
for (size_t i = 0; i < top_k_elements.size(); ++i) {
softmax[i] = exp((top_k_elements[i] - max_logit) / m_temperature);
sum_exp += softmax[i];
}
for (float &value : softmax) {
value /= sum_exp;
}
// sampling
float _sum = std::accumulate(softmax.begin(), softmax.end(), 0.0);
for (float &value : softmax) {
value /= _sum;
}
auto idx = _sample_element(top_k_elements_idx, softmax);
return idx;
}


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









