







基于自适应t分布的麻雀搜索算法
1.自适应t分布策略
t分布又称学生分布,含有参数自由度n,它的曲线形态与自由度n的大小有关,n的值越小,其曲线越平坦,曲线中间越低,曲线双侧尾部翘得越高。高斯分布,柯西分布与t分布的对比图如下:
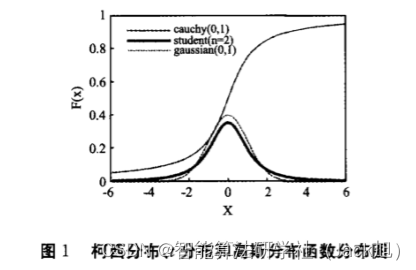
对麻雀位置利用自适应t分布进行更新如下式所示:
x
i
t
=
x
i
+
x
i
∗
t
(
i
t
e
r
)
(1)
x_i^t = x_i + x_i*t(iter)\tag{1}
xit=xi+xi∗t(iter)(1)
式中,
x
i
t
x_i^t
xit为变异后的麻雀位置;
x
i
x_i
xi为第i个麻雀个体的位置;
t
(
i
t
e
r
)
t(iter)
t(iter)为以算法的迭代次数为参数自由度的t分布。该式充分利用了当前种群信息,以迭代次数t作为自由度参数,前期t较小类似柯西变异具有较强的全局搜索能力,后期t较大类似高斯变异具有较强的局部搜索能力。从而提高算法的搜索能力。
2.基于自适应t分布策略的麻雀搜索算法
基础麻雀算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/108830958
该改进主要是麻雀更新后,利用自适应t分布对麻雀位置更新,麻雀的选择采用随机选择的方式,对比更新前后麻雀,如果更优则替代之前的麻雀。
算法流程
Step1: 初始化种群,迭代次数,初始化捕食者和加入者比列。
Step2:计算适应度值,并排序。
Step3:麻雀更新捕食者位置。
Step4:麻雀更新加入者位置。
Step5:麻雀更新警戒者位置。
Step6:计算适应度值并更新麻雀位置。
Step7: 如果rand<p,则根据式(1)进行自适应t分布变异。
Step8:计算适应度值并更新麻雀位置。
Step9:是否满足停止条件,满足则退出,输出结果,否则,重复执行Step2-8;
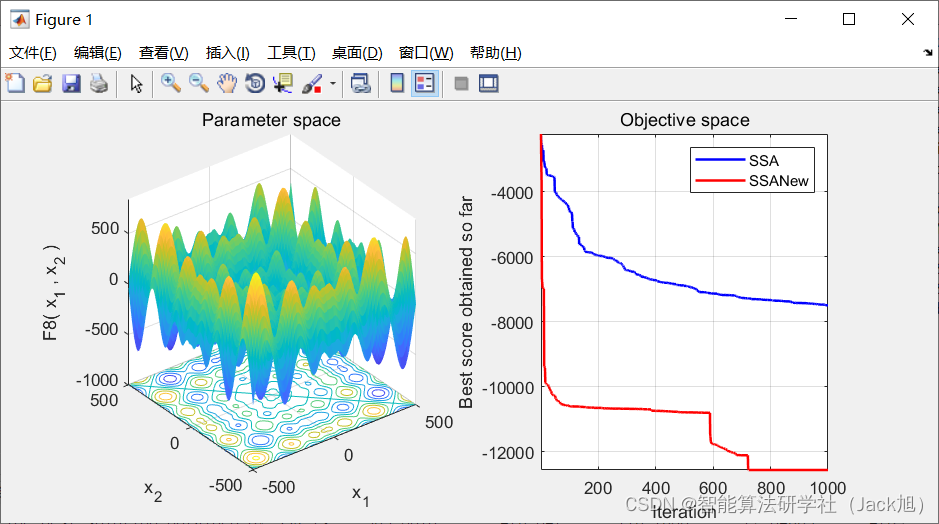
3.算法结果:



















 266
266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











