







Get started with Gemma using KerasNLP
https://www.kaggle.com/code/nilaychauhan/get-started-with-gemma-using-kerasnlp
Step1: Gemma Setup
1.1.Gemma setup
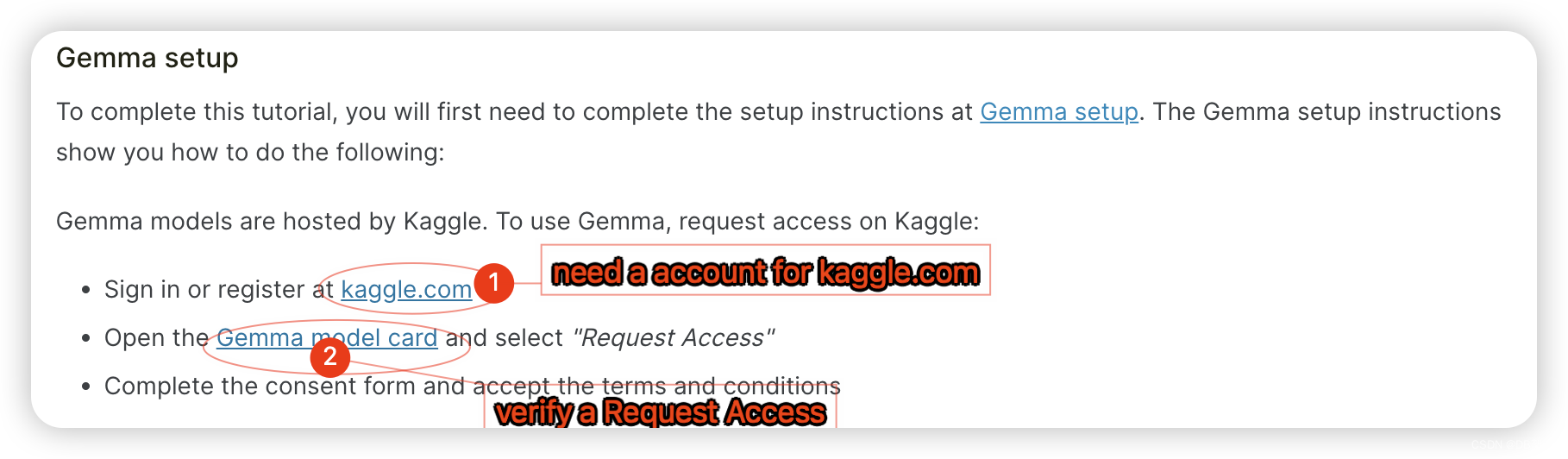
To complete this tutorial, you will first need to complete the setup instructions at Gemma setup. The Gemma setup instructions show you how to do the following:
Gemma models are hosted by Kaggle. To use Gemma, request access on Kaggle:
- Sign in or register at kaggle.com
- Open the Gemma model card and select "Request Access"
- Complete the consent form and accept the terms and conditions
1.2.Open the Gemma model card and select "Request Access"

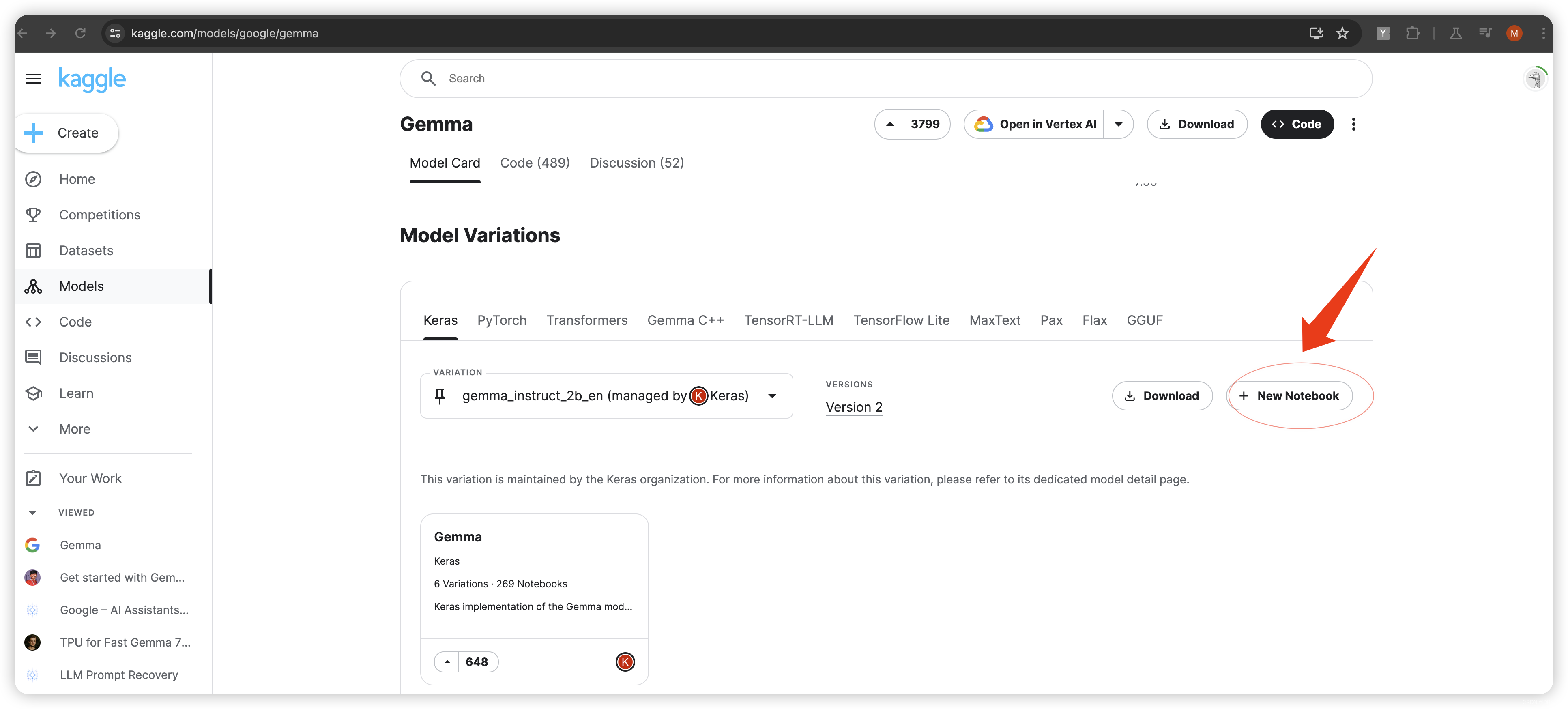
1.3 上面的页面(Gemma | Kaggle)往下滑到下面:选中New Notebook
1.4 更改notebook临时名称为Get started with Gemma using KerasNLP
1.5 运行本地环境。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session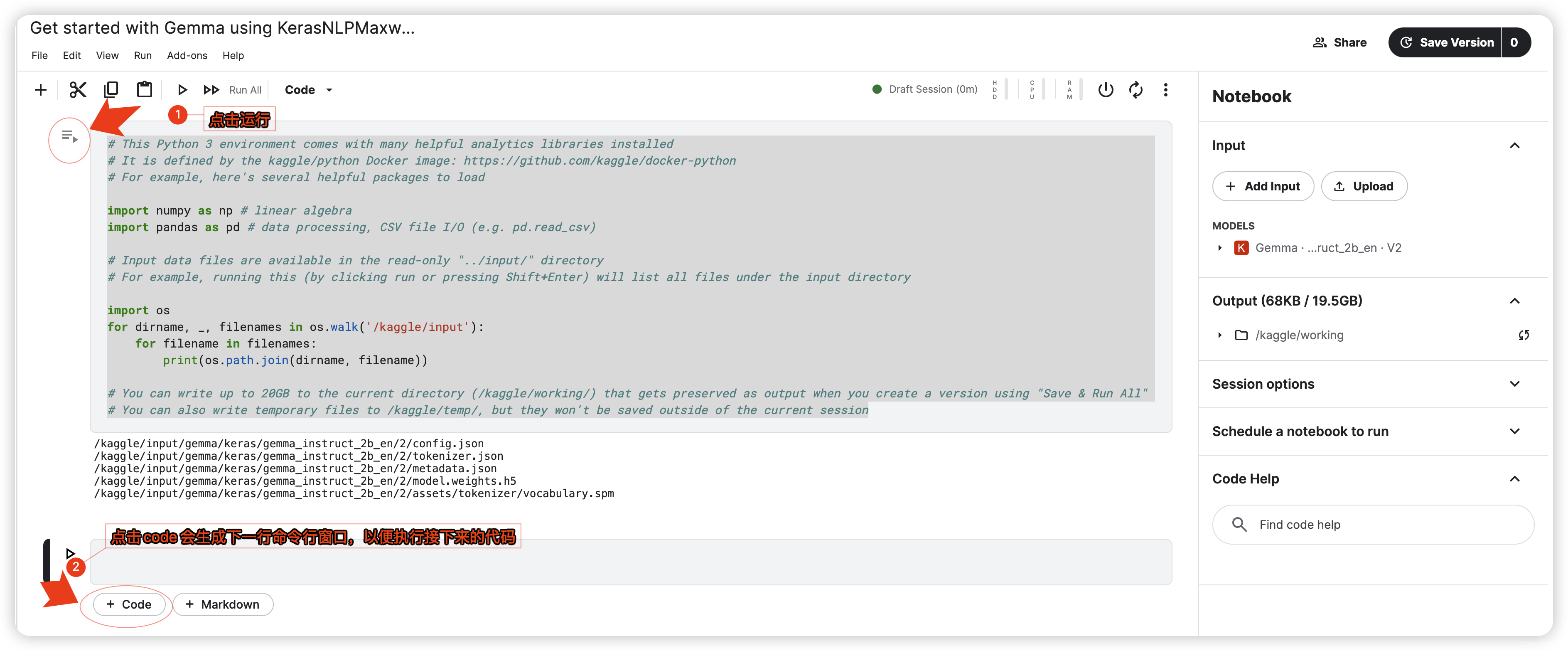
Step2 Install dependencies
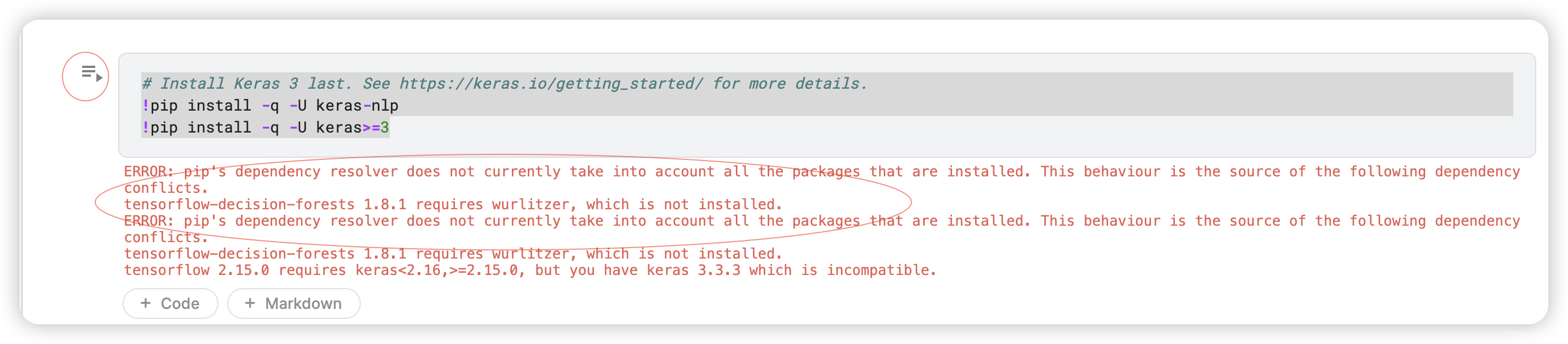
Install keras and KerasNLP
# Install Keras 3 last. See https://keras.io/getting_started/ for more details.
!pip install -q -U keras-nlp
!pip install -q -U keras>=3
pip install Wurlitzer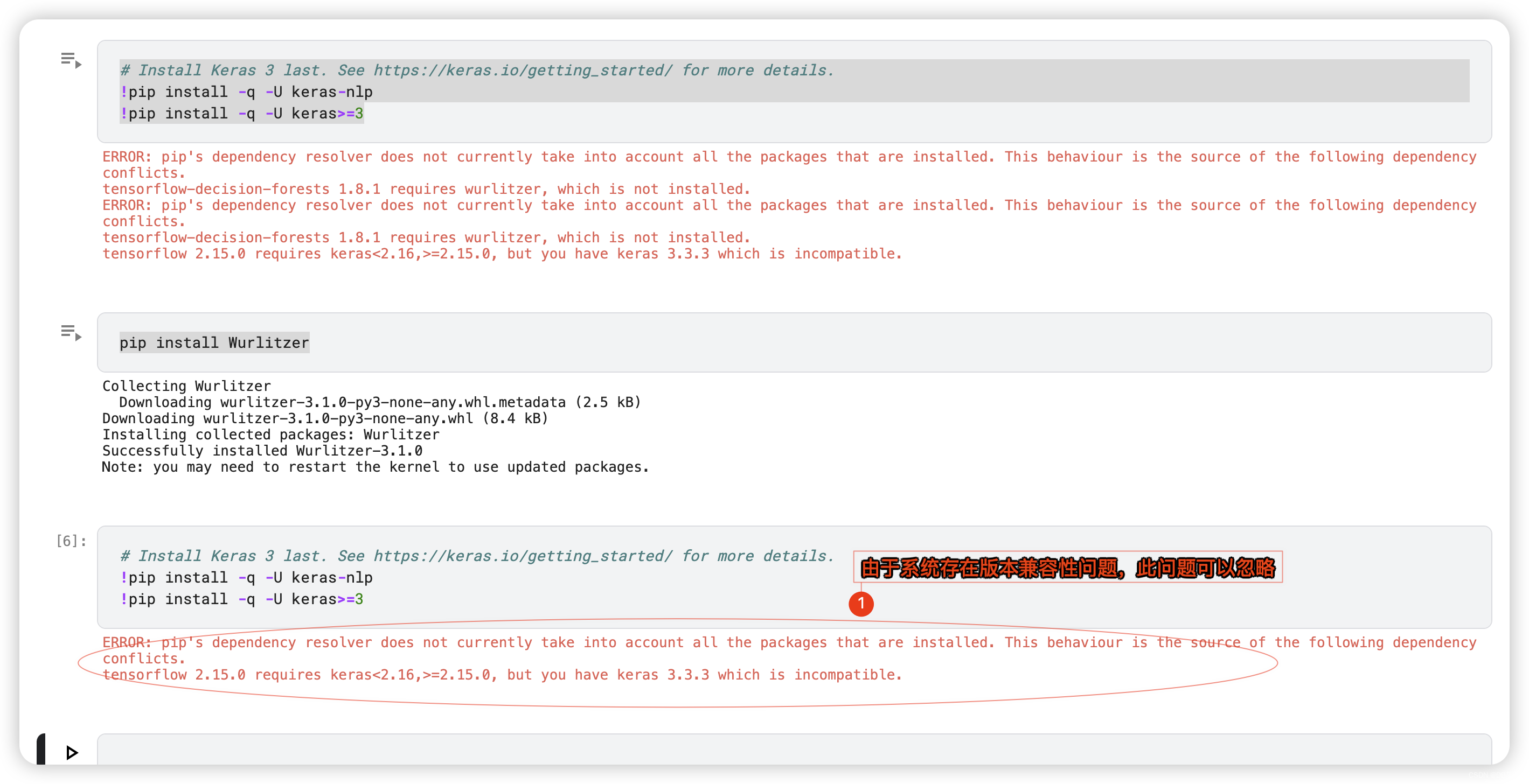
Step3 Import packages
Import Keras and KerasNLP
import keras
import keras_nlp
Step 4 Selected a backend
Keras is a high-level, multi-framework deep learning API designed for simplicity and ease of use. Keras 3 lets you choose the backend: TensorFlow, JAX, or PyTorch. All three will work for this tutorial.
import os
os.environ["KERAS_BACKEND"] = "jax" # Or "tensorflow" or "torch".
Step 5 Create a model
KerasNLP provides implementations of many popular model architectures. In this tutorial, you'll create a model using GemmaCausalLM, an end-to-end Gemma model for causal language modeling. A causal language model predicts the next token based on previous tokens.
Create the model using the from_preset method:
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")

from_preset instantiates the model from a preset architecture and weights. In the code above, the string "gemma_2b_en" specifies the preset architecture: a Gemma model with 2 billion parameters. (A Gemma model with 7 billion parameters is also available. To run the larger model in Colab, you need access to the premium GPUs available in paid plans. Alternatively, you can perform distributed tuning on a Gemma 7B model on Kaggle or Google Cloud.)
Use summary to get more info about the model:
gemma_lm.summary()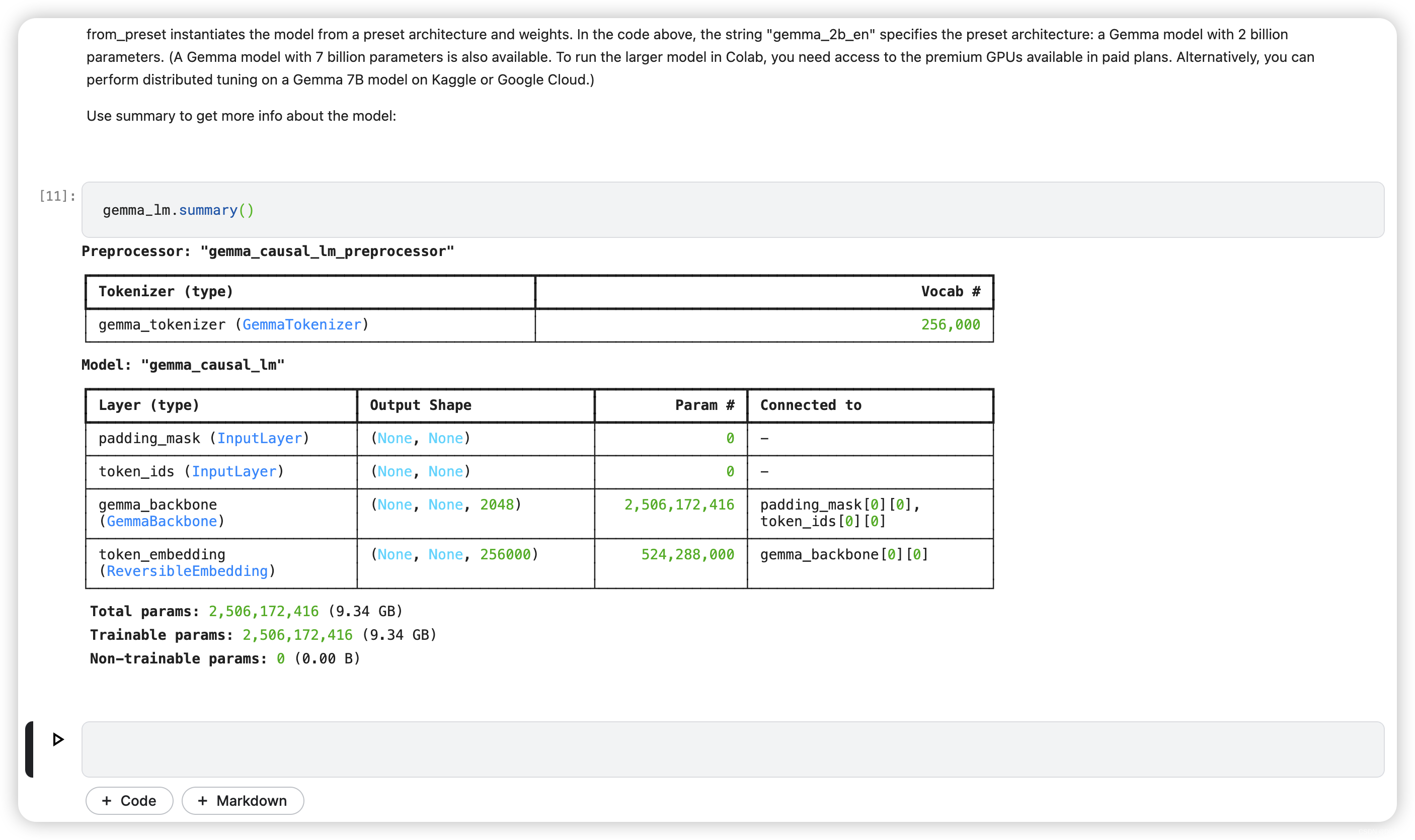
As you can see from the summary, the model has 2.5 billion trainable parameters.
Step 6 Generate text
Now it's time to generate some text! The model has a generate method that generates text based on a prompt. The optional max_length argument specifies the maximum length of the generated sequence.
Try it out with the prompt "What is the meaning of life?".
gemma_lm.generate("What is the meaning of life?", max_length=64)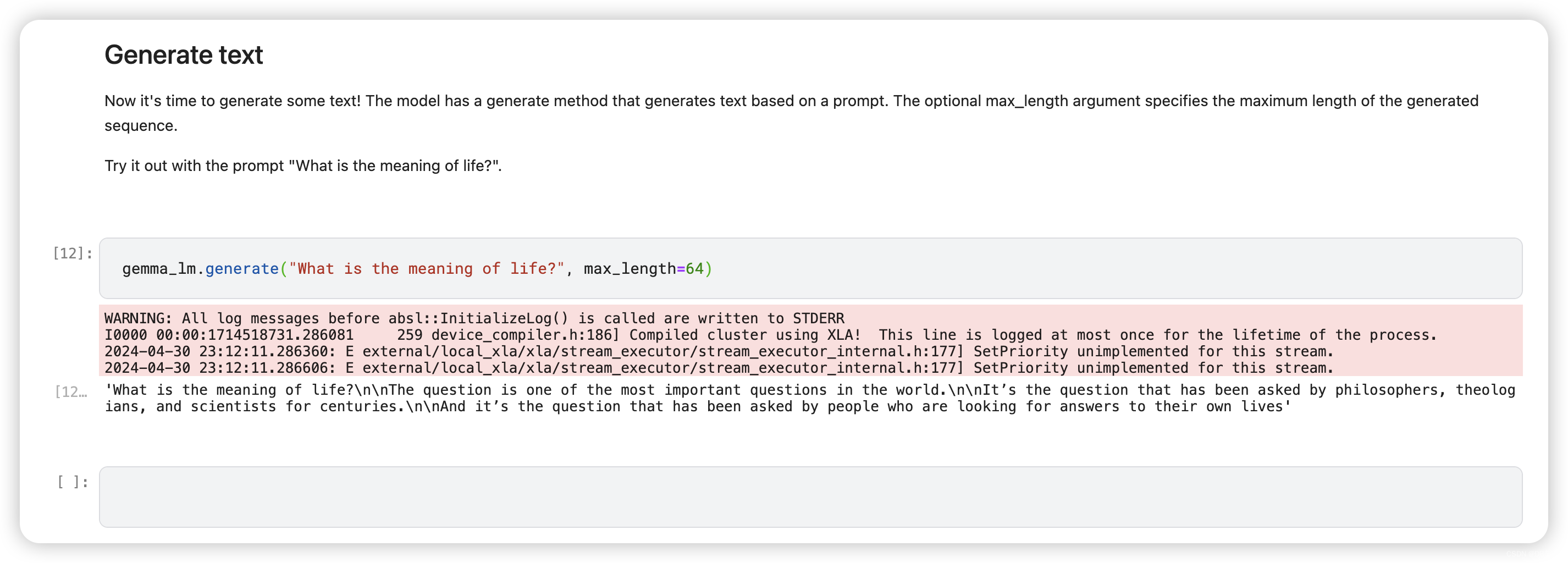
Try calling generate again with a different prompt.
gemma_lm.generate("How does the brain work?", max_length=64)
If you're running on JAX or TensorFlow backends, you'll notice that the second generate call returns nearly instantly. This is because each call to generate for a given batch size and max_length is compiled with XLA. The first run is expensive, but subsequent runs are much faster.
linkcode
You can also provide batched prompts using a list as input:
gemma_lm.generate(
["What is the meaning of life?",
"How does the brain work?"],
max_length=64)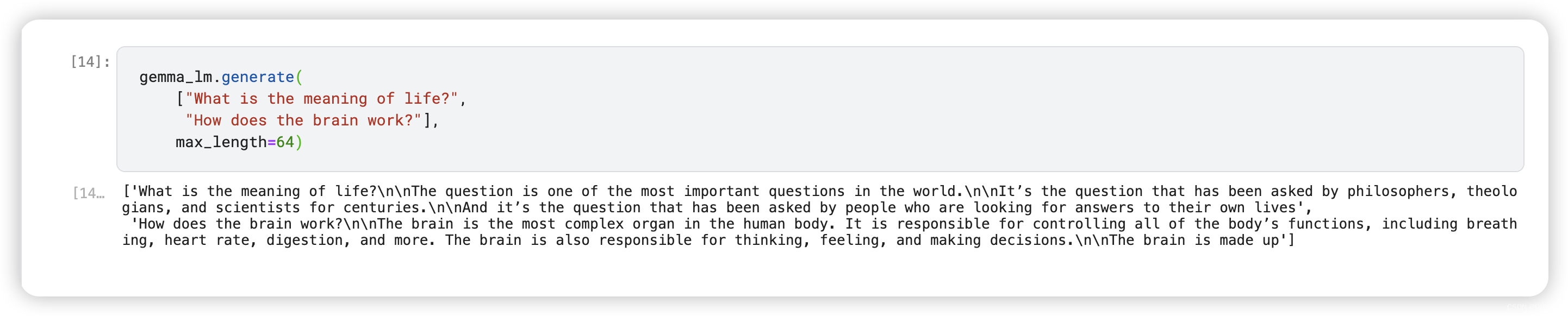
Step7 Optional: Try a different sampler
You can control the generation strategy for GemmaCausalLM by setting the sampler argument on compile(). By default, "greedy" sampling will be used.
As an experiment, try setting a "top_k" strategy:
gemma_lm.compile(sampler="top_k")
gemma_lm.generate("What is the meaning of life?", max_length=64)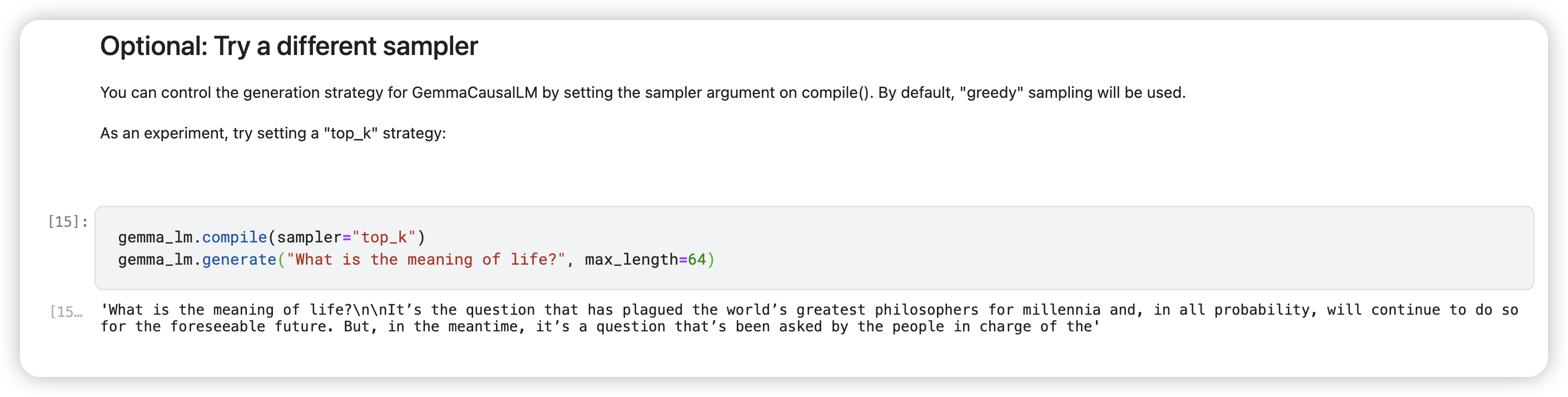
While the default greedy algorithm always picks the token with the largest probability, the top-K algorithm randomly picks the next token from the tokens of top K probability.
You don't have to specify a sampler, and you can ignore the last code snippet if it's not helpful to your use case. If you'd like learn more about the available samplers, see Samplers.
倘若您觉得我写的好,那么请您动动你的小手粉一下我,你的小小鼓励会带来更大的动力。Thanks.














 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









