







这一节我们把以前学过的logistics 和 kernel合在一起
在上一节中,我们讲了soft-margin,推出的结论如下图

图中的ζ其实就是一个点违反的距离,就是1-y(wz+b)
其实我们可以很容易想到,对于图中的点,如果违反了,那么ζ是1-y(wz+b),而对于没有违反的点,显然就是0,
所以其实可以写成这样子

其实这个形式是不是很熟悉?
没错

那我们为什么不一开始直接写成这个样子,而是写成最开始做二次规划的那个样子呢?
1.如果直接写成这个样子,没有条件,而且是把整个东西直接来做min,不是一个二次规划问题
2.对于里面的err hat,我们中间有max函数,对于它,有的地方是没有办法微分的。
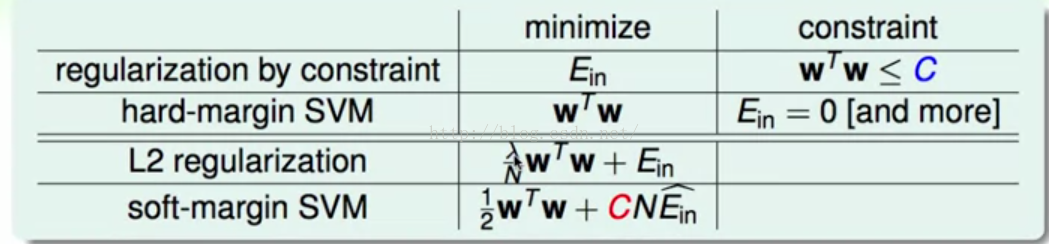
我们可以很直观的看一下比较,其实large margin就是更少的hyperplanes,就是L2 regularization的更短的w
而soft margin其实就是一个具体的err hat,把具体错误的衡量方式给了出来。
当然图中的C越大,说明regularization做得越小。 λ则相反
接着,我们再来说说这个error问题,
0/1 error,这个是上一门课提到的,而我们SVM的error hat显然是0/1error的一个上限
而在以前讲过,如果0/1error能够被一个上限给包住,那么我们找到一个替代的演算法(我已经忘了,看来还需要脑补一下=。=)

其实我们可以由图看出来,logistic的和svm的其实是很接近的。
又因为我们的svm加上了w的限制,是不是可以把SVM看做是一个logistic+L2呢?
w的限制对应L2,error hat对应logistic =。=也就是说如果我们今天解了一个regularization logistic 问题,是不是其实也相当于解了一个SVM问题呢?
那如果我们今天解了一个SVM问题,可以想成解决了一个regularization logistic 问题吗?大家记得我们logistic问题给出的概率哟,SVM能做到吗?
naive 方法1,解出SVM得到b和w,然后直接用这个b和w代替lr问题中的b和w,=。=这样感觉就没有lr的意义了,比如以前推导的似然函数等等都没有了
naive 方法2,解出SVM得到b和w,然后用这个作为lr问题中迭代的起始点,但是这和实际只跑lr的解没有太大区别
一个可行的方法,直接给公式吧

其实就是先用SVM做出来一个值,然后再调整A和B两个参数来match 最大似然函数。
其实也可以这样理解,就是把以前的x转换到SVM这个维度,多维到一维,然后再做一个一维的lr问题。
但是这并不是真正的做kernel lr=。=
我们前面已经接触到这样一个结论,在L2 lr中我们要求的w可以表示成资料Z的线性组合,

证明:假设最佳解w1不是属于space Z,
那么w1这个向量可以分解成w2∈space Z ,w3垂直于space Z,首先w1*z=(w2+w3)*z=w2z,因为w3*z=0,垂直嘛
ww=(w2+w3)(w2+w3)=w2w2+w3w3+2w2w3=w2w2+w3w3>w2w2
显然w2比起w1来说才是更优的解,矛盾
所以说我们的确是可以用资料的线性组合来表示w

显然这样就得到了我们的kernel
最后老师说这个模型可以理解成两种,一个把kernel本身当做一个整体,所以是β的线性组合,也可也理解成原始资料的线性组合
比如高斯SVM,可以理解为原始资料的线性组合,也可以理解为一堆高斯的线性组合。这里我没太理解清楚=。=
最后klr的β大多不为0,计算代价比较大。















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









