







 本文介绍了因果效应的概念,通过辛普森悖论展示了因果关系的复杂性。接着,深入探讨了因果效应的估算,包括SUTVA、Ignorability、Consistency和Positivity假设。重点转向Uplift模型,它用于预测单个样本因干预而产生的增益,特别是在营销场景中如何利用Uplift模型进行用户细分以提高营销效果。文章还讨论了不同类型的Uplift模型建模方法,如T-Learner、S-Learner、X-Learner,并介绍了模型评估方法,如Uplift Curve和AUUC。最后,提到了Causal Forest和实际应用中的注意事项。
本文介绍了因果效应的概念,通过辛普森悖论展示了因果关系的复杂性。接着,深入探讨了因果效应的估算,包括SUTVA、Ignorability、Consistency和Positivity假设。重点转向Uplift模型,它用于预测单个样本因干预而产生的增益,特别是在营销场景中如何利用Uplift模型进行用户细分以提高营销效果。文章还讨论了不同类型的Uplift模型建模方法,如T-Learner、S-Learner、X-Learner,并介绍了模型评估方法,如Uplift Curve和AUUC。最后,提到了Causal Forest和实际应用中的注意事项。
最近工作中遇到了类似营销场景下找出对营销敏感用户的问题,用到了uplift model。所以想对uplift model做个简单的总结。
因果推断
这是一个非常大的研究领域,它是推断一个变量对另外一个变量的因果关系,以及影响大小。研究因果关系的是因果发现(causal discovery),估计影响大小的是因果效应(causal effect)。后面我们主要聚焦在因果效应上。
辛普森悖论
辛普森悖论是概率统计中的一种现象:在变量 Z 的每一个分层上,变量 X 和变量 Y 都表现出一致的相关性,但是在 Z 的整体上,X 和 Y 却呈现出与之相反的相关性。 这里我们用《Introduction to Causal Inference》这门课的例子来说明。
背景:假设你是一个医院的数据分析人员。 现在有一种疾病D,D的病情可以分为两种轻微(mild)和严重(severe)目前有两种治疗方式A和B,其中B比A需要的资源更稀缺。对于得了D的病人只有两种结局被治愈和死亡。
我们把上面的描述总总结成一个表格方便理解:

经过一段时间的实验,收集到的统计数据如下:

在分不同病情看方案A和B的治疗效果的时候,都是方案B好些(
15
%
>
10
%
15\%>10\%
15%>10% ;
30
%
>
20
%
30\%>20\%
30%>20%);但是如果看总体的情况时,方案A的效果好些(
16
%
<
19
%
16\%<19\%
16%<19%)。我们没办法说明哪个方案更好。这就是辛普森悖论。它是由于数据的不均衡加权造成的(选择方案A的病人大多是轻症,而选择方案B的大多是重症,重症患者更容易死亡)。辛普森悖论给我们带来的问题就是:到底是应该相信分组的数据还是总体的数据呢?
先给出结论:面对这样的问题,我们不能单从数据入手,而是要根据数据背后的原因(质量方案,病情等的关系)得出结论。下面我们就分情况讨论下:
情况1:病情是治疗的原因,且病情和治疗一起导致了结果(是否死亡)。也就是说因为方案B需要的资源更稀缺,医生会根据病人的病情选择治疗方案。如果是轻症,大多数会选择方案A,反之会用方案B。这里方案B被不公平对待了。所以此时看总体数据不能说明真正的情况,需要分病情的轻重看哪个方案有效。 因此无论在轻症还是重症,方案B的死亡率都低,所以方案B更好。
这时候,病情对治疗和结果都有影响(病情决定治疗方案,治疗方案决定死亡率,病情和治疗方案也会共同决定死亡率),病情就是一个混杂因子(confounder,混淆因子是Treatment和Outcome的共同的原因)。画出关系图如下:

情况2:治疗方案是引起病情不同的原因。 这时,医生会随机采取治疗方案。由于方案B需要的资源很稀缺,选择方案B的病人往往要等很长的时间才能呗治疗,这时候大部分病人已经发展成了重症。所以方案B的重症比例高;而方案A来说,病人在轻症的时候就可以得到治疗,所以方案A的轻症比例更高。此时因为病情是由治疗方案导致的,病情是个途径。此时如果分病情来看数据,不能得出有效的结论,因为途径被抹除了(此时分组方案A的死亡率高是因为方案A需要都是简单的资源,没有那么精细造成的)。这种情况应该看总体的数据情况。所以方案A的效果比方案B好。
这时候,病情是治疗到结果的中介(病情的变化是由于治疗方案导致的)此时病情是一个修饰效应(effect modification,修饰效应是Treatment到outcome的一个途径)。画出因果图如下:

到这里我们关于辛普森悖论就聊完了。接下来我们正式聊聊因果效应。
因果效应
一些概念:
- 干预(treeatment):对个体实施的策略,比如辛普森悖论里的治疗方案,记作 T T T。为了说明问题方便:这里 T ∈ 0 , 1 T\in0,1 T∈0,1, T = 1 T=1 T=1表示受到了干预; T = 0 T=0 T=0表示未受到干预。 T i T_{i} Ti表示第 i i i个样本受到的干预。
- 观测结果:一个个体是否受到干预,我们都能观察到他的一个结果,记作 Y o b s Y^{obs} Yobs。 Y i o b s Y^{obs}_{i} Yiobs表示的是第 i i i个样本的观测结果。
- 潜在结果:我们想知道一个个体在同等条件下不同treatment的结果,这个结果就是潜在结果,记作
Y
(
T
)
Y(T)
Y(T)。潜在结果有两个:
- Y i ( 1 ) Y_{i}(1) Yi(1) : 第 i i i个用户受到干预的潜在结果;
-
Y
i
(
0
)
Y_{i}(0)
Yi(0) : 第
i
i
i个用户未受到干预的潜在结果;
一个个体不可能同时受到treatment和不受treatment,所以潜在结果只有一个能被观测到。被观测到的是观测结果,另一个是反事实结果。
- ITE(Individual Treatment Effect):个体的因果效应。
I T E = Y i ( 1 ) − Y i ( 0 ) (1) ITE = Y_{i}(1)-Y_{i}(0) \tag{1} ITE=Yi(1)−Yi(0)(1)
因果效应
其实因果效应的核心问题是估计
I
T
E
ITE
ITE,但是很多时候一个人的因果效应没有太大意义,总体的才有意义,所以就有了平均因果效应
A
T
E
ATE
ATE(Average treatment effect)这个概念。它表示的是所有个体的平均因果效应。
A
T
E
=
E
[
Y
i
(
1
)
−
Y
i
(
0
)
]
(2)
ATE = E[Y_{i}(1)-Y_{i}(0)] \tag{2}
ATE=E[Yi(1)−Yi(0)](2)
如果我们能估计出
A
T
E
ATE
ATE,我们就能知道这个干预是否有效以及效果有多大了。但是由于反事实的存在(
Y
i
(
1
)
Y_{i}(1)
Yi(1) 和
Y
i
(
0
)
Y_{i}(0)
Yi(0)只有一个能得到。 ),所以没办法直接算。这时就需要一些假设把
A
T
E
ATE
ATE变成可估计的形式。下面就花些篇幅搞定这个事情。
ATE估算
Stable Unit Treatment Value Assumption (SUTVA)假设
SUTVA假设描述的是:个体之间相互独立,互不干扰。不考虑treatment和样本之间的交互。用公式表示就是:
Y
i
(
t
1
,
t
2
,
.
.
.
.
t
n
,
t
n
)
=
Y
i
(
t
i
)
(3)
Y_{i}(t_{1},t_{2},....t_{n},t_{n})=Y_{i}(t_{i}) \tag{3}
Yi(t1,t2,....tn,tn)=Yi(ti)(3)
t
1
,
t
2
,
.
.
.
.
t
n
,
t
n
t_{1},t_{2},....t_{n},t_{n}
t1,t2,....tn,tn是其他的treatment。
举一个不满足的例子:在淘宝发优惠券的时候,我们发不发生购买不仅取决于自己收到优惠券的面值大小,也可能会收到周围的人收到优惠券面值的大小。如果我收到的比别人的小,我可能就不买了。可以看到在社交性场景下,就不能得到满足。
有了SUTVA假设,
(
2
)
(2)
(2)可以进一步推导成:
A
T
E
=
E
[
Y
i
(
1
)
−
Y
i
(
0
)
]
=
E
[
Y
i
(
1
)
]
−
E
[
Y
i
(
0
)
]
(4)
ATE=E[Y_{i}(1) -Y_{i}(0)]=E[Y_{i}(1)]-E[Y_{i}(0)] \tag{4}
ATE=E[Yi(1)−Yi(0)]=E[Yi(1)]−E[Yi(0)](4)
到这我们已经前进了一步:观测结果的期望可以分开算,但是还没有解决反事实的问题。
Ignorability假设
Ignorability假设描述的是:在给定背景变量
X
X
X下,treatment(
T
T
T)与潜在结果(
Y
(
T
)
Y(T)
Y(T))是相互独立的。其实就是个体会被随机分配到两个组,一个组接受treatment另一个不接受)。用公式表示就是:
T
⊥
(
Y
(
1
)
,
Y
(
0
)
)
∣
X
(5)
T\perp(Y(1),Y(0)) | X \tag{5}
T⊥(Y(1),Y(0))∣X(5)
假设也可以说明:接受treatment的组合和不接受treatment的组之间可以交换,最后的
A
T
E
ATE
ATE不变。同时该假设也保证了没有混杂因子(混杂因子会影响treatment也会影响outcome。相当于treatment和outcome就不独立了。)这个也可以说是背景变量和treatment相互独立。
Ignorability假设保证了研究Treatment Effect时,接受treatment的组和不接受treatment的组的背景变量 X X X的分布是相同的。从而避免由于实验组和对照组 X X X的分布不同(即选择偏差selection bias),导致Treatment的分配有不同倾向性。
背景变量指的是个体的属性,如果是一个人的话,背景变量可以是年龄、性别、职业等等
因此有了Ignorability假设,我们可以再进一步:
A
T
E
=
E
[
Y
i
(
1
)
−
Y
i
(
0
)
]
=
E
[
Y
i
(
1
)
]
−
E
[
Y
i
(
0
)
]
=
E
[
Y
i
(
1
)
∣
T
i
=
1
]
−
E
[
Y
i
(
0
)
∣
T
i
=
0
]
(6)
\begin{aligned} ATE &= E[Y_{i}(1) -Y_{i}(0)] \\ &= E[Y_{i}(1)]-E[Y_{i}(0)] \\ &= E[Y_{i}(1)|T_{i}=1]-E[Y_{i}(0)|T_{i}=0] \end{aligned} \tag{6}
ATE=E[Yi(1)−Yi(0)]=E[Yi(1)]−E[Yi(0)]=E[Yi(1)∣Ti=1]−E[Yi(0)∣Ti=0](6)
这个假设还有个名字叫做CIA
Consistency假设
Consistency假设说的是潜在的结果和观察到的结果一致的。也就是说一旦treatment的值确定(
T
T
T是1还是0确定了),样本的结果就跟treatment没有关系,而是跟背景变量(用户特征)相关了。之前的
Y
i
o
b
s
Y_{i}^{obs}
Yiobs可以表示成:
Y
i
o
b
s
=
{
Y
i
(
1
)
T
i
=
1
Y
i
(
0
)
T
i
=
0
(7)
Y_{i}^{obs}=\left\{ \begin{aligned} Y_{i}(1) & & {T_{i}=1}\\ Y_{i}(0) & & {T_{i}=0}\\ \end{aligned} \right. \tag{7}
Yiobs={Yi(1)Yi(0)Ti=1Ti=0(7)
这个看起来有点费劲,
(
7
)
(7)
(7)可以转化为
Y
i
o
b
s
=
T
i
Y
i
(
1
)
+
(
1
−
T
i
)
Y
i
(
0
)
(8)
Y_{i}^{obs} = T_{i}Y_{i}(1)+(1-T_{i})Y_{i}(0) \tag{8}
Yiobs=TiYi(1)+(1−Ti)Yi(0)(8)
从
(
8
)
(8)
(8)更能理解这个假设了。
有了这个假设后 :
A
T
E
=
E
[
Y
i
(
1
)
−
Y
i
(
0
)
]
=
E
[
Y
i
(
1
)
]
−
E
[
Y
i
(
0
)
]
=
E
[
Y
i
(
1
)
∣
T
i
=
1
]
−
E
[
Y
i
(
0
)
∣
T
i
=
0
]
=
E
[
Y
i
o
b
s
∣
T
i
=
1
]
−
E
[
Y
i
o
b
s
∣
T
i
=
0
]
(9)
\begin{aligned} ATE &= E[Y_{i}(1) -Y_{i}(0)] \\ &= E[Y_{i}(1)]-E[Y_{i}(0)] \\ &= E[Y_{i}(1)|T_{i}=1]-E[Y_{i}(0)|T_{i}=0] \\ &= E[Y_{i}^{obs}|T_{i}=1]-E[Y_{i}^{obs}|T_{i}=0] \end{aligned} \tag{9}
ATE=E[Yi(1)−Yi(0)]=E[Yi(1)]−E[Yi(0)]=E[Yi(1)∣Ti=1]−E[Yi(0)∣Ti=0]=E[Yiobs∣Ti=1]−E[Yiobs∣Ti=0](9)
到了这里 A T E ATE ATE就可以估算了。只需要在估算的过程中保证上面三个假设成立就行了(最重要的就是保证Ignorability假设,SUTVA是数据层面和设计干预要保证的。Consistency一般认为一直成立)。最直接的方法就是对全体变量做随机实验。随机实验就是用户被随机的分配到实验组和对照组中,这保证了Ignorability假设的成立。
你一定还有疑问,为什么随机实验可以估算。 因为随机实验时,实验组和对照组的样本的背景变量基本一致,也就是说实验组的样本一定可以在对照组中找到一个跟他非常非常相似的样本。这样如果一个样本受了干预,那么实验组的结果就是观察的结果,对照组里的相似样本的结果就是反事实结果。反之也成立,再加上需要计算期望可以抹平误差, A T E ATE ATE可以用随机实验的数据估算。
如果我们能做随机实验,我们的任务就完成了。
CATE的估算
但是很多情况是做不了随机实验的,比如在互联网公司不能拿全体用户做随机实验。
这时候怎么办呢?我们能不能从总体中抽取部分样本,估计他们的平均因果效应当做
A
T
E
ATE
ATE呢?答案是能的。这个就是条件平均因果效应
C
A
T
E
CATE
CATE(Conditional Average treatment effect)
C
A
T
E
=
E
[
Y
i
(
1
)
−
Y
i
(
0
)
∣
X
i
]
(10)
CATE=E[Y_{i}(1)-Y_{i}(0)|X_{i}] \tag{10}
CATE=E[Yi(1)−Yi(0)∣Xi](10)
X
i
X_{i}
Xi仍然是背景特征,对于人来说就是用户特征。只不过是抽样的关系,这里是指取值域内的一部分值。
根据
(
8
)
(8)
(8)和
(
2
)
(2)
(2) 有:
A
T
E
=
E
[
Y
i
(
1
)
−
Y
i
(
0
)
]
=
E
X
i
[
Y
i
(
1
)
−
Y
i
(
0
)
∣
X
i
]
=
E
(
C
A
T
E
)
(11)
ATE = E[Y_{i}(1) -Y_{i}(0)] = E_{X_{i}}[Y_{i}(1)-Y_{i}(0)|X_{i}] = E(CATE) \tag{11}
ATE=E[Yi(1)−Yi(0)]=EXi[Yi(1)−Yi(0)∣Xi]=E(CATE)(11)
所以拿CATE代表因果效应也是没问题的(这里是一个不严谨的证明,实际的证明比较复杂的)。
接下来我们就要估算下
C
A
T
E
CATE
CATE了。
除了需要满足SUTVA、 Ignorability和Consistency假设外,还需要满足Positivity假设。
Positivity假设
Positivity假设通俗解释;对于背景变量 X X X取任何值,都有: P ( T = 1 ∣ X ) > 0 P(T=1|X)>0 P(T=1∣X)>0 和 P ( T = 0 ∣ X ) > 0 P(T=0|X)>0 P(T=0∣X)>0 成立(T取多值也成立)。这就保证了任何样本都有反事实可以估计。
有了上面四个假设
C
A
T
E
CATE
CATE也可以变成
(
9
)
(9)
(9)的样子:
C
A
T
E
=
E
[
Y
i
(
1
)
−
Y
i
(
0
)
∣
X
i
]
=
E
[
Y
i
(
1
)
∣
X
i
]
−
E
[
Y
i
(
0
)
∣
X
i
]
=
E
[
Y
i
(
1
)
∣
T
i
=
1
,
X
i
]
−
E
[
Y
i
(
0
)
∣
T
i
=
0
,
X
i
]
=
E
[
Y
i
o
b
s
∣
T
i
=
1
,
X
i
]
−
E
[
Y
i
o
b
s
∣
T
i
=
0
,
X
i
]
(12)
\begin{aligned} CATE &= E[Y_{i}(1) -Y_{i}(0)|X_{i}] \\ &= E[Y_{i}(1)|X_{i}]-E[Y_{i}(0)|X_{i}] \\ &= E[Y_{i}(1)|T_{i}=1,X_{i}]-E[Y_{i}(0)|T_{i}=0,X_{i}] \\ &= E[Y_{i}^{obs}|T_{i}=1,X_{i}]-E[Y_{i}^{obs}|T_{i}=0,X_{i}] \end{aligned} \tag{12}
CATE=E[Yi(1)−Yi(0)∣Xi]=E[Yi(1)∣Xi]−E[Yi(0)∣Xi]=E[Yi(1)∣Ti=1,Xi]−E[Yi(0)∣Ti=0,Xi]=E[Yiobs∣Ti=1,Xi]−E[Yiobs∣Ti=0,Xi](12)
其中P(T=1|X)叫做倾向性评分(propensity score)
A T E ATE ATE可以用随机实验的数据估算,那么 C A T E CATE CATE就可以用ab测试的数据估算,而且ab测试可以保证Positivity假设(小声BB,如果不能保证我们也可以去掉一些样本。)
为什么说用ab测试可以保证Positivity假设呢?我们在使用ab测试的时候,实验组和对照组是随机分配的,而且要保证两组用户的背景变量(用户特征)分布基本一致。其实就是实验组中的用户大概率可以在对照组中找到跟他背景变量相似的用户。
C A T E CATE CATE可以用ab测试估算的原因跟 A T E ATE ATE能用随机实验估算的原因一样。
我们现在有三个因果效应的表示了: A T E ATE ATE、 C A T E CATE CATE和 I T E ITE ITE。这三个其实没啥区别,彼此之间是期望的关系。
Uplift model
终于到了正题了,通过上面对因果推断的介绍,理解下面的内容就易如反掌了。
uplift model是一个预测treatment给单个样本带来的增益的模型(比如一个用户给优惠券下一个200元的订单,如果不给他优惠券,他就啥也不买。这个优惠券带来的增益效果就是200元)。 实际上这个增益就是 I T E ITE ITE。
举个例子更细致的描述下uplift model是干什么的。
想象我们是个电商,马上要周年庆了。我们想采用发放优惠券的方式提升订单量。但是我们的预算有限(因为优惠券相当于我们出钱补贴商家,我们不能无限制的补贴。),问题就是我们应该给哪些用户发卷才能实现利益最大化呢?(利益最大化就是指,预算有限的情况下,提升的订单量最大)。
最直接的思路是做一个二分类问题。预测给用户发券后,产生订单的概率,即 P ( Y = 1 ∣ X ) P(Y=1|X) P(Y=1∣X)。但这样走是否合适呢?想象下我们的用户发优惠券的反应。
- persuadables:不发券就不购买、发券才会购买的人群;
- sure thing:无论是否发券,都会购买;
- lost causes:无论是否发券都不会购买;
- sleeping dogs:不发券会购买,但发券后不会再购买。
这就是营销场景下对用户的分类。其实我们在预算有限的情况下,最好的情况就是把优惠券发给persuadables这一类人,还应该避免发给sleeping dogs。但是之前二分类的思路(我们管这样的模型叫做 response model,比如ctr预测都是这样的模型)是没办法区分不同用户的。这个场景uplift model就排上了用场。
uplift model是预测
I
T
E
ITE
ITE的,那么我们可以把uplift model的预测增量(
τ
\tau
τ)表示成,(这里我们管
τ
\tau
τ叫做uplift):
τ
i
=
I
T
E
i
=
Y
i
(
1
)
−
Y
i
(
0
)
=
P
(
Y
i
∣
X
i
,
T
i
=
1
)
−
P
(
Y
i
∣
X
i
,
T
i
=
0
)
=
P
(
Y
i
=
1
∣
X
i
,
T
i
=
1
)
−
P
(
Y
i
=
1
∣
X
i
,
T
i
=
0
)
这
是
发
券
下
单
的
概
率
减
去
不
发
券
下
单
的
概
率
(13)
\begin{aligned} \tau_{i} &= ITE_{i} \\ &= Y_{i}(1)-Y_{i}(0) \\ &=P(Y_{i}|X_{i},T_{i}=1) - P(Y_{i}|X_{i},T_{i}=0)\\ &=P(Y_{i}=1|X_{i},T_{i}=1) - P(Y_{i}=1|X_{i},T_{i}=0) 这是发券下单的概率减去不发券下单的概率 \end{aligned} \tag{13}
τi=ITEi=Yi(1)−Yi(0)=P(Yi∣Xi,Ti=1)−P(Yi∣Xi,Ti=0)=P(Yi=1∣Xi,Ti=1)−P(Yi=1∣Xi,Ti=0)这是发券下单的概率减去不发券下单的概率(13)
其中
- Y i Y_{i} Yi:潜在的结果,在这个例子里就是是否下单,我们一般是看下单的概率也就是 Y i = 1 Y_{i}=1 Yi=1的概率( P ( Y i = 1 ∣ X i , T i = 1 ) P(Y_{i}=1|X_{i},T_{i}=1) P(Yi=1∣Xi,Ti=1)和 P ( Y i = 1 ∣ X i , T i = 0 ) P(Y_{i}=1|X_{i},T_{i}=0) P(Yi=1∣Xi,Ti=0));
- X i X_{i} Xi:是用户 i i i的特征(也就是上面说的背景变量);
- T i T_{i} Ti: 用户受到的干预,这个例子里就是是否发券(发券: T i = 1 T_{i}=1 Ti=1;不发券: T i = 0 T_{i}=0 Ti=0)。
因为确定了干预后(一个人发不发券)后,是否下单跟玩家的特征有关,不是一个确定的值是概率,所以 ( 13 ) (13) (13)写成了发券下单的概率减去不发券下单的概率的形式。
到这里uplift model的基本形式咱们就了解了。 下一步你肯定想知道这两个概率怎么预测。这就是要用到机器学习的方式了。可以拿一个模型(或者两个模型)预测这两个概率。具体的建模方式我们下面会详细讨论。还一个问题需要关心:训练数据哪里来?答案是:AB测试。
原因是: I T E ITE ITE是单个样本的因果效应,一个样本只能是受干预和不受干预之一,不能同时出现。这就导致我们没有办法估算 I T E ITE ITE。但是 I T E ITE ITE和 C A T E CATE CATE、 A T E ATE ATE是等价的。我们可以拿 C A T E CATE CATE的估算近似代替 I T E ITE ITE的估算,其原因是 C A T E CATE CATE可以用ab测试估算,另外假设实验组和对照组各有一个样本,这俩样本的用户特征相似(可以相互代替其反事实)。 C A T E CATE CATE在这种情况下就是 I T E ITE ITE。而ab测试中两组都是这样的样本对。所以我们可以用ab测试的数据让模型学习到一个样本的观察结果和反事实结果。
OK,训练数据是什么我们也知道了。接下来就详细讨论下建模方式。
Uplift model的建模方法
建模的方式可以分为3类,two/one model approach(differential response)、Class Transformation Method和Modeling Uplift Directly。 如果你看过文献或者其他的一些博客,你会看到还有一类方法叫做Meta-Learning Method。Meta-Learning Method跟上面的三个方法有些重合:T-learner是two model approach的实现;S-learner是differential response的另一种形式,它只用了一个模型;X-learner也是个双模型,可以看做是T-leaner的进化版本,Class Transformation Method也可以看做是S-leaner的进化版本。 所以我们会介绍三类方法:Meta-Learning Method、Class Transformation Method和Tree Based Model(Modeling Uplift Directly)。
Meta-Learning Method
这个方法可以说是一类算法的组合,它是由一些base-learner各种组合而成的。base-learner可以是现在任何既有的预测方法(如果目标 y y y是离散值就是分类的算法,目标 y y y是连续值就是回归的算法)。根据这些base-learner组合的不同将这类方法分为:S-Learner、T-Learner、X-Learner、R-Learner。我们介绍S-Learner、T-Learner、X-Learner三种,R-learner以后可以补充下吧(因为我没用过)。
T-Learner(two model approach,differential response)
T-Learner是指用两个模型来估计Uplift,即用两个模型分别建模干预、不干预的情况,取差值作为Uplift。也就是说用实验组和对照组数据分别建模,用差值作为uplift。此时建模的算法可以是各种既有算法。
具体的步骤如下:
- 对实验组数据和对照组数据分别训练预测模型,预测的目标依然是目标
y
=
1
y=1
y=1的概率;
p T ( y i = 1 ∣ X i ) = f T ( X i ) (14) p^{T}(y_{i}=1|X_{i}) =f^{T}(X_{i}) \tag{14} pT(yi=1∣Xi)=fT(Xi)(14)
p C ( y i = 1 ∣ X i ) = f C ( X i ) (15) p^{C}(y_{i}=1|X_{i}) =f^{C}(X_{i}) \tag{15} pC(yi=1∣Xi)=fC(Xi)(15)
其中: f T ( ) f^{T}() fT()和 f C ( ) f^{C}() fC()分别是对实验组和对照组的建模的模型; X i X_{i} Xi是第 i i i个用户的特征 - 用两个模型预测的概率的差值做为uplift(
τ
\tau
τ);
τ i = p T ( y i = 1 ∣ X i ) − p C ( y i = 1 ∣ X i ) (16) \tau_{i} = p^{T}(y_{i}=1|X_{i})-p^{C}(y_{i}=1|X_{i}) \tag{16} τi=pT(yi=1∣Xi)−pC(yi=1∣Xi)(16)
预测新样本时,两个模型分别对该样本做预测,得到两个概率。这两个概率的差值为这个样本的uplift( τ \tau τ)
优点:
- 该方法原理简单,实现也简单,好理解;
- 可以用现成的分类或者或回归的模型做base-learner;
- 模型训练也比较快(这个是我自己测的,T和S learner比X快不少)
缺点:
- 两个模型预测,容易累计误差,这个误差主要是两个模型的bias方向不一致造成的,所以使用时需要针对两个模型打分分布做一定校准;
- 当数据差异很大的时候,准确性会受影响;
- 不是对uplift直接建模,没有办法利用与uplift直接相关的信号,并且不好优化。
S-Learner(one model approach,differential response)
S-Learner用一个模型来估计Uplift,将实验组和对照组数据合并,并把treatment的分组标号也作为特征和用户其他的特征放在一起建模。
具体建模过程跟response模型一样。只是预测的时候,一个样本要预测两次,分别
T
=
1
T=1
T=1和
T
=
0
T=0
T=0各预测一次。然后两次结果作差就是uplift (
τ
\tau
τ)即:
τ
i
=
p
(
y
i
=
1
∣
X
i
,
T
i
=
1
)
−
p
(
y
i
=
1
∣
X
i
,
T
i
=
0
)
(17)
\tau_{i} = p(y_{i}=1|X_{i},T_{i}=1)-p(y_{i}=1|X_{i},T_{i}=0) \tag{17}
τi=p(yi=1∣Xi,Ti=1)−p(yi=1∣Xi,Ti=0)(17)
优点:
- 该方法原理简单,实现也简单,好理解;
- 可以用现成的分类或者或回归的模型做base-learner;
- 用一个模型,不会累计误差;
- 充分利用数据;
- 可以支持treatment多值的情况
缺点:
- 模型依然不是直接对uplift直接建模,
- 用户特征不能太多,不然会把treamtment的信息淹没;
X-Learner
X-leaner可以看做是T-leaner的进化版本,用来改进因为实验组和对照组数据差异较大造成T-leaner误差较大的算法。具体的步骤如下:
- 和T-learner一样,对实验组数据和对照组数据分别训练预测模型:
p T ( y i = 1 ∣ X i ) = f T ( X i ) (18) p^{T}(y_{i}=1|X_{i}) =f^{T}(X_{i}) \tag{18} pT(yi=1∣Xi)=fT(Xi)(18)
p C ( y i = 1 ∣ X i ) = f C ( X i ) (19) p^{C}(y_{i}=1|X_{i}) =f^{C}(X_{i}) \tag{19} pC(yi=1∣Xi)=fC(Xi)(19) - 对实验组和对照组的样本做ITE的估计(就是用上一步的预测结果和原来的y作差)
D i T = y i − p C ( y i = 1 ∣ X i ) (20) D^{T}_{i} = y_{i} - p^{C}(y_{i}=1|X_{i}) \tag{20} DiT=yi−pC(yi=1∣Xi)(20)
注意: 这里是拿实验组的数据建模
D i C = y i − p T ( y i = 1 ∣ X i ) (21) D^{C}_{i} = y_{i} - p^{T}(y_{i}=1|X_{i}) \tag{21} DiC=yi−pT(yi=1∣Xi)(21)
注意: 这里是拿对照组的数据建模 - 分别在实验组和对照组以上一步的差值为目标(分别以
D
i
T
D^{T}_{i}
DiT和
D
i
C
D^{C}_{i}
DiC为目标)训练模型,得到各自的uplift的预估
τ i T = l T ( X i ) (22) \tau^{T}_{i} = l^{T}(X_{i}) \tag{22} τiT=lT(Xi)(22)
τ i C = l C ( X i ) (23) \tau^{C}_{i} = l^{C}(X_{i}) \tag{23} τiC=lC(Xi)(23) - 对上一步的uplift预估值做加权求和得到最终的uplift
τ i = g ( X i ) τ i C + ( 1 − g ( X i ) ) τ i T (24) \tau_{i} = g(X_{i})\tau^{C}_{i}+(1-g(X_{i}))\tau^{T}_{i} \tag{24} τi=g(Xi)τiC+(1−g(Xi))τiT(24)
这里的 g ( X i ) g(X_{i}) g(Xi)可以是1和0,或者 g ( X i ) = p ( T = 1 ∣ X ) g(X_{i})=p(T=1|X) g(Xi)=p(T=1∣X)其实就是propensity score的估计。它表示了最终的 τ \tau τ更像实验组还是更像对照组。这个是论文中推荐的方法。
优点:
- 适合实验组和对照组样本数量差异较大的场景(但是差异多大可以表现的比其他方法好没有定论。)
- 弥补T-learner的缺点。
缺点:
- 因为是多个模型建模,非常费时费力;
- 多模型建模容易累计误差;
到此meta-learning的方法就介绍的差不多了。还有R-learner,但是它太老了而且非常的晦涩,再有我没用过,这里就不介绍了。当然还有很多基于上面方法的改进算法,有兴趣的同学可以自己看看论文。我如果用到了也会在这个文章里补充。
Class Transformation Method
这个方法是用过对Y的转换,可以用response model直接对uplift建模。但是目前只适用于treatment和outcome都是二值的情况,并且实验组和对照组的样本要尽量平衡(这个条件可以忽略,因为有改进的方法)。
咱们先看看实验组和对照组的样本相等,也就是随机实验的情况。
首先定义新的目标变量:我们想让这个新的目标变量:在实验组
y
=
1
y=1
y=1的以及在对照组
y
=
0
y=0
y=0的样本等于1,反之为0。 因为受到干预买,没有受到干预就不买,应该是我们目标。
Z
i
=
Y
i
o
b
s
T
i
+
(
1
−
Y
i
o
b
s
)
(
1
−
T
i
)
(25)
Z_{i} = Y_{i}^{obs}T_{i} +(1-Y_{i}^{obs})(1-T_{i}) \tag{25}
Zi=YiobsTi+(1−Yiobs)(1−Ti)(25)
此时:
Z
i
=
{
1
Y
i
o
b
s
=
1
,
T
1
=
1
o
r
Y
i
o
b
s
=
0
,
T
1
=
0
0
o
t
h
e
r
w
i
s
e
Z_{i}=\left \{ \begin{aligned} 1 & & {Y_{i}^{obs}=1,T_{1}=1 or Y_{i}^{obs}=0,T_{1}=0}\\ 0 & & {otherwise}\\ \end{aligned} \right.
Zi={10Yiobs=1,T1=1orYiobs=0,T1=0otherwise
其中,
Y
i
o
b
s
Y_{i}^{obs}
Yiobs是用户
i
i
i观察到的结果,
Y
i
o
b
s
∈
0
,
1
Y_{i}^{obs}\in0,1
Yiobs∈0,1。
T
i
T_{i}
Ti表示是否受到干预,
T
i
∈
1
,
0
T_{i}\in1,0
Ti∈1,0。
X
i
X_{i}
Xi是用户
i
i
i的特征。这个表达式满足了我们的想法。
接下来就需要用目标表示uplift了。这里先给出结果,再推导过程。用户
i
i
i的uplift表示如下:
τ
i
=
2
P
(
Z
i
=
1
∣
X
i
)
−
1
(26)
\tau_{i} = 2P(Z_{i}=1|X_{i})-1 \tag{26}
τi=2P(Zi=1∣Xi)−1(26)
有了这个表达,我们就可以先对
Z
i
Z_{i}
Zi做一个response model,然后再根据
(
26
)
(26)
(26)计算每个样本的uplift值(
τ
i
\tau_{i}
τi)。
下面是推导过程:
由
(
25
)
(25)
(25)有:
P
(
Z
i
∣
X
i
)
=
P
(
Y
1
=
1
,
T
i
=
1
∣
X
i
)
+
P
(
Y
1
=
0
,
T
i
=
0
∣
X
i
)
(27)
P(Z_{i}|X_{i})=P(Y_{1}=1,T_{i}=1|X_{i})+P(Y_{1}=0,T_{i}=0|X_{i}) \tag{27}
P(Zi∣Xi)=P(Y1=1,Ti=1∣Xi)+P(Y1=0,Ti=0∣Xi)(27)
因为是随机实验,一个样本被分到实验组和对照组的概率是一样的,就有:
P
(
T
i
=
1
∣
X
i
)
=
P
(
T
i
=
0
∣
X
i
)
=
1
2
(28)
P(T_{i}=1|X_{i}) = P(T_{i}=0|X_{i}) = \frac{1}{2} \tag{28}
P(Ti=1∣Xi)=P(Ti=0∣Xi)=21(28)
P
(
T
i
=
1
∣
X
i
)
=
P
(
Y
i
=
1
,
T
i
=
1
∣
X
1
)
+
P
(
Y
i
=
0
,
T
i
=
1
∣
X
1
)
(29)
P(T_{i}=1|X_{i}) = P(Y_{i}=1,T_{i}=1|X_{1})+P(Y_{i}=0,T_{i}=1|X_{1}) \tag{29}
P(Ti=1∣Xi)=P(Yi=1,Ti=1∣X1)+P(Yi=0,Ti=1∣X1)(29)
P
(
T
i
=
0
∣
X
i
)
=
P
(
Y
i
=
1
,
T
i
=
0
∣
X
1
)
+
P
(
Y
i
=
0
,
T
i
=
0
∣
X
1
)
(30)
P(T_{i}=0|X_{i}) = P(Y_{i}=1,T_{i}=0|X_{1})+P(Y_{i}=0,T_{i}=0|X_{1}) \tag{30}
P(Ti=0∣Xi)=P(Yi=1,Ti=0∣X1)+P(Yi=0,Ti=0∣X1)(30)
τ
i
=
P
(
Y
i
=
1
∣
X
i
,
T
i
=
1
)
−
P
(
Y
i
=
1
∣
X
i
,
T
i
=
0
)
这
是
发
券
下
单
的
概
率
减
去
不
发
券
下
单
的
概
率
(
最
原
始
定
义
)
=
P
(
Y
i
=
1
,
T
i
=
1
∣
X
1
)
P
(
T
i
=
1
∣
X
i
)
−
P
(
Y
i
=
1
,
T
i
=
0
∣
X
1
)
P
(
T
i
=
0
∣
X
i
)
贝
叶
斯
公
式
=
P
(
Y
i
=
1
,
T
i
=
1
∣
X
1
)
1
/
2
−
P
(
Y
i
=
1
,
T
i
=
0
∣
X
1
)
1
/
2
由
(
28
)
得
=
2
[
P
(
Y
i
=
1
,
T
i
=
1
∣
X
1
)
−
P
(
Y
i
=
1
,
T
i
=
0
∣
X
1
)
]
=
[
P
(
Y
i
=
1
,
T
i
=
1
∣
X
1
)
−
P
(
Y
i
=
1
,
T
i
=
0
∣
X
1
)
]
+
[
1
2
−
P
(
Y
i
=
0
,
T
i
=
1
∣
X
1
)
−
1
2
+
P
(
Y
i
=
0
,
T
i
=
0
∣
X
1
)
]
由
(
29
)
(
30
)
得
=
P
(
Y
i
=
1
,
T
i
=
1
∣
X
1
)
+
P
(
Y
i
=
0
,
T
i
=
0
∣
X
1
)
−
P
(
Y
i
=
0
,
T
i
=
1
∣
X
1
)
−
P
(
Y
i
=
1
,
T
i
=
0
∣
X
1
)
=
P
(
Z
i
=
1
∣
X
i
)
−
P
(
Z
i
=
0
∣
X
i
)
=
P
(
Z
i
=
1
∣
X
i
)
−
(
1
−
P
(
Z
i
=
1
∣
X
i
)
)
=
2
P
(
Z
i
=
1
∣
X
i
)
−
1
\begin{aligned} \tau_{i} &=P(Y_{i}=1|X_{i},T_{i}=1) - P(Y_{i}=1|X_{i},T_{i}=0) &&这是发券下单的概率减去不发券下单的概率(最原始定义) \\ &=\frac{P(Y_{i}=1,T_{i}=1|X_{1})}{P(T_{i}=1|X_{i})}-\frac{P(Y_{i}=1,T_{i}=0|X_{1})}{P(T_{i}=0|X_{i})} &&贝叶斯公式 \\ &=\frac{P(Y_{i}=1,T_{i}=1|X_{1})}{1/2}-\frac{P(Y_{i}=1,T_{i}=0|X_{1})}{1/2} &&由(28)得 \\ &=2[P(Y_{i}=1,T_{i}=1|X_{1})-P(Y_{i}=1,T_{i}=0|X_{1})] \\ &=[P(Y_{i}=1,T_{i}=1|X_{1})-P(Y_{i}=1,T_{i}=0|X_{1})] \\ &+[\frac{1}{2}-P(Y_{i}=0,T_{i}=1|X_{1})-\frac{1}{2}+P(Y_{i}=0,T_{i}=0|X_{1})] && 由(29)(30)得 \\ &=P(Y_{i}=1,T_{i}=1|X_{1}) +P(Y_{i}=0,T_{i}=0|X_{1})\\ &-P(Y_{i}=0,T_{i}=1|X_{1})-P(Y_{i}=1,T_{i}=0|X_{1}) \\ &=P(Z_{i}=1|X_{i}) -P(Z_{i}=0|X_{i}) \\ &=P(Z_{i}=1|X_{i}) -(1-P(Z_{i}=1|X_{i}) ) \\ &= 2P(Z_{i}=1|X_{i}) -1 \end{aligned}
τi=P(Yi=1∣Xi,Ti=1)−P(Yi=1∣Xi,Ti=0)=P(Ti=1∣Xi)P(Yi=1,Ti=1∣X1)−P(Ti=0∣Xi)P(Yi=1,Ti=0∣X1)=1/2P(Yi=1,Ti=1∣X1)−1/2P(Yi=1,Ti=0∣X1)=2[P(Yi=1,Ti=1∣X1)−P(Yi=1,Ti=0∣X1)]=[P(Yi=1,Ti=1∣X1)−P(Yi=1,Ti=0∣X1)]+[21−P(Yi=0,Ti=1∣X1)−21+P(Yi=0,Ti=0∣X1)]=P(Yi=1,Ti=1∣X1)+P(Yi=0,Ti=0∣X1)−P(Yi=0,Ti=1∣X1)−P(Yi=1,Ti=0∣X1)=P(Zi=1∣Xi)−P(Zi=0∣Xi)=P(Zi=1∣Xi)−(1−P(Zi=1∣Xi))=2P(Zi=1∣Xi)−1这是发券下单的概率减去不发券下单的概率(最原始定义)贝叶斯公式由(28)得由(29)(30)得
接下来我们考虑一般的情况,也就是实验组和对照组样本数量不等的情况。
我们依然要构造一个目标变量
Y
i
⋆
=
Y
i
(
1
)
T
1
e
(
X
i
)
−
Y
i
(
0
)
(
1
−
T
i
)
(
1
−
e
(
X
i
)
)
=
Y
i
o
b
s
T
i
−
e
(
X
i
)
e
(
X
i
)
(
1
−
e
(
X
i
)
)
(31)
\begin{aligned} Y_{i}^{\star} &= Y_{i}(1)\frac{T_{1}}{e(X_{i})}-Y_{i}(0)\frac{(1-T_{i})}{(1-e(X_{i}))} \\ &=Y_{i}^{obs}\frac{T_{i}-e(X_{i})}{e(X_{i})(1-e(X_{i}))} \tag{31} \end{aligned}
Yi⋆=Yi(1)e(Xi)T1−Yi(0)(1−e(Xi))(1−Ti)=Yiobse(Xi)(1−e(Xi))Ti−e(Xi)(31)
其中
Y
i
(
1
)
Y_{i}(1)
Yi(1) : 第
i
i
i个用户受到干预的潜在结果;
Y
i
(
0
)
Y_{i}(0)
Yi(0) : 第
i
i
i个用户未受到干预的潜在结果。
e
(
X
i
)
e(X_{i})
e(Xi):是倾向性评分
P
(
T
i
=
1
∣
X
i
)
P(T_{i}=1|X_{i})
P(Ti=1∣Xi) 这里也可以直接用
P
(
T
i
=
1
)
P(T_{i}=1)
P(Ti=1)估计。
在《Machine Learning Methods for Estimating Heterogeneous Causal Effects》中证明了
E
[
Y
i
⋆
]
=
τ
i
E[Y_{i}^{\star}]=\tau_{i}
E[Yi⋆]=τi。所以我们可以直接用response model对
Y
i
⋆
Y_{i}^{\star}
Yi⋆建模。
我们的ab测试一般会满足 ( 28 ) (28) (28)的假设,但是如果不满足,建模后结果也不错,也是可以用的。
Tree Based Model(Modeling Uplift Directly)
meta-learning的方法都是间接的对uplift建模,下面介绍的方法是对uplift直接的建模。Tree Based Model是一类的算法,他们都是跟传统的决策树(都是跟CART树的思想一样)模型是一样的(所以都Tree Based Model)。 跟传统的树模型主要的不同点是分裂节点的依据不同,传统的树模型是利用信息增益(信息增益率,gini)作为分裂依据,而Tree Based Model是依据uplift的差异作为分裂依据的。这里主要介绍3个方法:Uplift-Tree,CTS和CausalForest。这些模型都是决策树的思想,所以我们着重介绍跟决策树不一样的地方。
Uplift-Tree
Uplift-tree使用实验组和对照组的分布散度的差作为分裂依据。分布散度是两个概率分布之间的差异,因此我们可以将实验组和对照组理解为两个(关于Y的)概率分布,以此为分裂依据,若分裂后差异变大,则说明这次分裂有区分能力且能描述实验组和对照组的uplift差异。
论文中的给了三种分布散度:KL散度、欧式距离和卡方散度:
- KL Divergence: K L ( P T ( Y ) : P C ( Y ) ) = ∑ y P T ( y ) l o g P T ( y ) P C ( y ) KL(P^T(Y):P^C(Y))=\sum_{y}P^T(y)log\frac{P^T(y)}{P^C(y)} KL(PT(Y):PC(Y))=∑yPT(y)logPC(y)PT(y)
- 欧式距离: E ( P T ( Y ) : P C ( Y ) ) = ∑ y ( P T ( y ) − P C ( y ) ) 2 E(P^T(Y):P^C(Y))=\sum_{y}(P^T(y)-P^C(y))^{2} E(PT(Y):PC(Y))=∑y(PT(y)−PC(y))2
- 卡方散度(Chi-squared Divergence): χ 2 ( P T ( Y ) : P C ( Y ) ) = ∑ y ( P T ( y ) − P C ( y ) ) 2 P C ( y ) \chi^{2}(P^T(Y):P^C(Y))=\sum_{y}\frac{(P^T(y)-P^C(y))^{2}}{P^C(y)} χ2(PT(Y):PC(Y))=∑yPC(y)(PT(y)−PC(y))2
其中, P T ( Y ) P^T(Y) PT(Y):实验组中样本数据类别 Y Y Y的概率分布, P T ( y ) P^T(y) PT(y):实验组中样本, Y = y Y=y Y=y时的概率; P C ( Y ) P^C(Y) PC(Y):对照组中样本数据类别 Y Y Y的概率分布, P C ( y ) P^C(y) PC(y):对照组中样本, Y = y Y=y Y=y时的概率。
这三个分布都可以在两个概率分布相同时,值为0;两个分布差异越大,值越大。虽然KL散度用的比较多,但是作者指出欧氏距离却比较有优势:1. 它是对称的,这个保证在只有对照组的时候,仍然是可以学到东西的;2. 它更稳定(当 P C ( y ) P^C(y) PC(y)为0,但是 P T ( y ) P^T(y) PT(y)不为0时,它是一个值,而KL散度和卡方散度会趋近无穷)保证模型稳定。
当结点中对照组数据为空时,KL散度会退化为信息增益;欧式距离和卡方散度将会退化为基尼指数。而当结点中实验组数据为空时,欧式距离将会化为基尼指数。这也是为什么分布散度可以作为分裂标准原因。
接下来以特征
A
A
A来分裂节点时的增益(这个增益类似决策树里的信息增益):
D
g
a
i
n
(
A
)
=
D
a
f
t
e
r
(
P
T
(
Y
)
:
P
C
(
Y
)
)
−
D
b
e
f
o
r
e
(
P
T
(
Y
)
:
P
C
(
Y
)
)
=
D
(
P
T
(
Y
)
:
P
C
(
Y
)
∣
A
)
−
D
(
P
T
(
Y
)
:
P
C
(
Y
)
)
(32)
\begin{aligned} D_{gain}(A) &= D_{after}(P^T(Y):P^C(Y)) - D_{before}(P^T(Y):P^C(Y)) \\ &= D(P^T(Y):P^C(Y)|A) - D(P^T(Y):P^C(Y)) \end{aligned} \tag{32}
Dgain(A)=Dafter(PT(Y):PC(Y))−Dbefore(PT(Y):PC(Y))=D(PT(Y):PC(Y)∣A)−D(PT(Y):PC(Y))(32)
其中,
D
(
∙
)
D(\bullet)
D(∙):分布散度,可以KL散度、欧式距离、卡方散度等;
D
(
∙
∣
A
)
D(\bullet|A)
D(∙∣A):利用特征
A
A
A做分裂后的分布散度。
D
(
P
T
(
Y
)
:
P
C
(
Y
)
∣
A
)
=
∑
a
N
(
a
)
N
D
(
P
T
(
Y
∣
a
)
:
P
C
(
Y
∣
a
)
)
(33)
D(P^T(Y):P^C(Y)|A) = \sum_{a} \frac{N(a)}{N}D(P^T(Y|a):P^C(Y|a)) \tag{33}
D(PT(Y):PC(Y)∣A)=a∑NN(a)D(PT(Y∣a):PC(Y∣a))(33)
其中,
a
a
a: 是特征A可以取的值;
N
(
a
)
N(a)
N(a):特征
A
=
a
A=a
A=a的样本数;
N
N
N:总的样本数;
D
(
P
T
(
Y
∣
a
)
:
P
C
(
Y
∣
a
)
D(P^T(Y|a):P^C(Y|a)
D(PT(Y∣a):PC(Y∣a)):当
A
=
a
A=a
A=a时的分布散度。
上面就是uplift tree是如何计算分裂依据的。每次分裂,模型会遍历所有特征,计算每个特征下所有值的分布散度,取最大的那个作为分裂特征和分裂点。如此反复直到满足要求(无分裂点,叶节点样本数,树的深度达到标准),算法停止。
我们引用一个例子来看下增益的计算过程:
如下图所示,T代表实验组,C代表对照组。 红色的求表示
y
=
1
y=1
y=1的样本,绿色的求表示
y
=
0
y=0
y=0的样本。
D
(
∙
)
D(\bullet)
D(∙)用欧式距离

D
(
P
T
(
Y
)
:
P
C
(
Y
)
)
=
∑
y
∈
1
,
0
(
P
T
(
y
)
−
P
C
(
y
)
)
2
=
(
3
4
−
1
4
)
2
+
(
1
2
−
1
2
)
2
=
0.125
D(P^T(Y):P^C(Y)) = \sum_{y \in1,0}(P^T(y)-P^C(y))^{2} = (\frac{3}{4}-\frac{1}{4})^2 + (\frac{1}{2}-\frac{1}{2})^2 = 0.125 \\
D(PT(Y):PC(Y))=y∈1,0∑(PT(y)−PC(y))2=(43−41)2+(21−21)2=0.125
D
(
P
T
(
Y
)
:
P
C
(
Y
)
∣
A
)
=
∑
a
∈
l
e
f
t
,
r
i
g
h
t
N
(
a
)
N
D
(
P
T
(
Y
∣
a
)
:
P
C
(
Y
∣
a
)
)
=
∑
a
∈
l
e
f
t
,
r
i
g
h
t
N
(
a
)
N
(
∑
y
∈
1
,
0
(
P
T
(
y
∣
a
)
−
P
C
(
y
∣
a
)
)
2
)
=
5
8
(
(
3
3
−
0
)
2
+
(
0
−
2
2
)
2
)
+
3
8
(
(
0
−
1
1
)
2
+
(
2
2
−
0
)
2
)
=
2
\begin{aligned} D(P^T(Y):P^C(Y)|A) &=\sum_{a \in left,right} \frac{N(a)}{N}D(P^T(Y|a):P^C(Y|a)) \\ &= \sum_{a \in left,right} \frac{N(a)}{N}( \sum_{y \in1,0}(P^T(y|a)-P^C(y|a))^{2} ) \\ & =\frac{5}{8}((\frac{3}{3}-0)^2+(0-\frac{2}{2})^2)+\frac{3}{8}((0-\frac{1}{1})^2+(\frac{2}{2}-0)^2) \\ &= 2 \end{aligned}
D(PT(Y):PC(Y)∣A)=a∈left,right∑NN(a)D(PT(Y∣a):PC(Y∣a))=a∈left,right∑NN(a)(y∈1,0∑(PT(y∣a)−PC(y∣a))2)=85((33−0)2+(0−22)2)+83((0−11)2+(22−0)2)=2
D
g
a
i
n
(
A
)
=
D
a
f
t
e
r
(
P
T
(
Y
)
:
P
C
(
Y
)
)
−
D
b
e
f
o
r
e
(
P
T
(
Y
)
:
P
C
(
Y
)
)
=
D
(
P
T
(
Y
)
:
P
C
(
Y
)
∣
A
)
−
D
(
P
T
(
Y
)
:
P
C
(
Y
)
)
=
2
−
0.125
=
1.875
\begin{aligned} D_{gain}(A) &= D_{after}(P^T(Y):P^C(Y)) - D_{before}(P^T(Y):P^C(Y)) \\ &= D(P^T(Y):P^C(Y)|A) - D(P^T(Y):P^C(Y))\\ &= 2-0.125 \\ &=1.875 \end{aligned}
Dgain(A)=Dafter(PT(Y):PC(Y))−Dbefore(PT(Y):PC(Y))=D(PT(Y):PC(Y)∣A)−D(PT(Y):PC(Y))=2−0.125=1.875
跟普通的决策树一样,uplfit-tree也会有模型会挑选更多值的特征分裂的问题。而且uplift-tree还会选择将实验组和对照组分裂后在叶节点比例差别很大的特征(这个会破坏CIA,也会在计算概率的时候有问题)。为了解决这两个问题,uplift-tree也会对分布散度做标准化,具体标准化的形式如下:
K
L
g
a
i
n
(
A
)
I
(
A
)
E
g
a
i
n
(
A
)
J
(
A
)
χ
g
a
i
n
2
(
A
)
J
(
A
)
\frac{KL_{gain}(A)}{I(A)} \qquad \frac{E_{gain}(A)}{J(A)} \qquad \frac{\chi^2_{gain}(A)}{J(A)}
I(A)KLgain(A)J(A)Egain(A)J(A)χgain2(A)
其中,
I
(
A
)
=
H
(
N
T
N
,
N
C
N
)
K
L
(
P
T
(
A
)
:
P
C
(
A
)
)
+
N
T
N
H
(
P
T
(
A
)
)
+
N
C
N
H
(
P
C
(
A
)
)
+
1
2
J
(
A
)
=
G
i
n
i
(
N
T
N
,
N
C
N
)
D
(
P
T
(
A
)
:
P
C
(
A
)
)
+
N
T
N
G
i
n
i
(
P
T
(
A
)
)
+
N
C
N
G
i
n
i
(
P
C
(
A
)
)
+
1
2
(34)
\begin{aligned} I(A) = H(\frac{N^T}{N},\frac{N^C}{N})KL(P^T(A):P^C(A)) + \frac{N^T}{N}H(P^T(A))+\frac{N^C}{N}H(P^C(A))+\frac{1}{2} \\ J(A) = Gini(\frac{N^T}{N},\frac{N^C}{N})D(P^T(A):P^C(A)) + \frac{N^T}{N}Gini(P^T(A))+\frac{N^C}{N}Gini(P^C(A))+\frac{1}{2} \\ \end{aligned} \tag{34}
I(A)=H(NNT,NNC)KL(PT(A):PC(A))+NNTH(PT(A))+NNCH(PC(A))+21J(A)=Gini(NNT,NNC)D(PT(A):PC(A))+NNTGini(PT(A))+NNCGini(PC(A))+21(34)
其中
H
(
⋅
)
H(\cdot)
H(⋅):交叉熵;
P
T
(
A
)
P^T(A)
PT(A):选特征
A
A
A分裂时,样本被分进实验组的概率;
P
C
(
A
)
P^C(A)
PC(A):选特征
A
A
A分裂时,样本被分进对照组的概率。
第一项是解决决策树通病的了;第二项是解决分裂后实验组和对照组比例过大的问题;第三项是防止前面两项值过小的情况。
下一个问题是:用什么值代表叶节点的uplift。
τ
l
=
−
c
+
∑
y
v
y
(
P
T
(
y
∣
l
)
−
P
C
(
y
∣
l
)
)
(35)
\tau_{l} = -c+\sum_{y}v_{y}(P^T(y|l)-P^C(y|l)) \tag{35}
τl=−c+y∑vy(PT(y∣l)−PC(y∣l))(35)
其中
l
l
l:叶节点;
P
T
(
y
∣
l
)
P^T(y|l)
PT(y∣l):对于实验组的样本在叶节点
l
l
l上
Y
=
y
Y=y
Y=y的概率;
P
C
(
y
∣
l
)
P^C(y|l)
PC(y∣l):对于对照组的样本在叶节点
l
l
l上
Y
=
y
Y=y
Y=y的概率;
v
y
v_y
vy:y的收益;
c
c
c:加干预的成本。我觉得也未必这么算,甚至可以用对应组
Y
=
y
Y=y
Y=y的概率的均值也可以,后面的cts等都是这样算的。
其实uplift-tree还涉及到剪枝的问题,这里就不介绍了。如果有兴趣可以参考下论文。其次论文中还介绍了multi-treatment的情况。
CTS
CTS(Contextual Treatment Selection)也是一种Tree-Based的uplift modeling方法。他跟uplift-tree的区别主要在于分裂的依据。CTS的分裂目标是最大化各个实验组(包括对照组)中最大的 Y Y Y的期望。其实就是在这一次分裂尽可能的让一个实验组被区分出来。
下面简述下如何计算分裂点的:
- 计算分裂前各个实验组(包含对照组)的
Y
Y
Y的期望的最大值,把这个值当做分裂前的uplift得分:
μ b e f o r e = max t = 0 , 1 , ⋯ , k E [ Y ∣ X ∈ ϕ , T = t ] (36) \mu_{before} = \max_{t=0,1,\cdots,k}E[Y|X\in\phi,T=t] \tag{36} μbefore=t=0,1,⋯,kmaxE[Y∣X∈ϕ,T=t](36)
其中 ϕ \phi ϕ是当前要分裂的节点,也就是父节点; T T T是干预,可以认为 T = 0 T=0 T=0是对照组,其他 T = 1 , 2 , . . . k T=1,2,...k T=1,2,...k都是实验组。 - 根据选定的特征,以及分割点将数据分为左右两支,计算左分支的各个实验组(包含对照组)的
Y
Y
Y的期望的最大值:,同理计算右分支的各个实验组(包含对照组)的
Y
Y
Y的期望的最大值。然后对左右分支的最大值做加权求和,把这个值当做分裂后的uplift得分。
μ a f t e r = P ( X ∈ ϕ l ∣ X ∈ ϕ ) max t l = 0 , 1 , ⋯ , k E [ Y ∣ X ∈ ϕ l , T = t l ] + P ( X ∈ ϕ r ∣ X ∈ ϕ ) max t r = 0 , 1 , ⋯ , k E [ Y ∣ X ∈ ϕ r , T = t r ] (37) \mu_{after} = P(X\in\phi_{l}|X\in\phi)\max_{t_{l}=0,1,\cdots,k}E[Y|X\in\phi_{l},T=t_{l}] \\+P(X\in\phi_{r}|X\in\phi)\max_{t_{r}=0,1,\cdots,k}E[Y|X\in\phi_{r},T=t_{r}] \tag{37} μafter=P(X∈ϕl∣X∈ϕ)tl=0,1,⋯,kmaxE[Y∣X∈ϕl,T=tl]+P(X∈ϕr∣X∈ϕ)tr=0,1,⋯,kmaxE[Y∣X∈ϕr,T=tr](37)
其中 ϕ l \phi_{l} ϕl是左分支的子节点; ϕ r \phi_{r} ϕr是右分支的子节点。 - 计算这个特征的这个分裂值的增益
Δ
μ
\Delta\mu
Δμ。
Δ μ = μ a f t e r − μ b e f o r e (38) \Delta\mu = \mu_{after}-\mu_{before} \tag{38} Δμ=μafter−μbefore(38) - 按照第二、三步,遍历计算所有特征以及对应的特征值的 Δ μ \Delta\mu Δμ。取最大的 Δ μ \Delta\mu Δμ对应的特征和特征值作为分裂的节点。
- 重复对左右值分裂的步骤,直到满足停止的条件。最后就能构建一颗uplift树(过程跟CART树一样)。
关于上面的 P ( X ∈ ϕ l ∣ X ∈ ϕ ) P(X\in\phi_{l}|X\in\phi) P(X∈ϕl∣X∈ϕ)、 P ( X ∈ ϕ r ∣ X ∈ ϕ ) P(X\in\phi_{r}|X\in\phi) P(X∈ϕr∣X∈ϕ)和 E [ Y ∣ X ∈ ϕ l , T = t ] E[Y|X\in\phi_{l},T=t ] E[Y∣X∈ϕl,T=t]、 E [ Y ∣ X ∈ ϕ l , T = t ] E[Y|X\in\phi_{l},T=t] E[Y∣X∈ϕl,T=t]怎么算:以左子节点为例计算。
P
(
X
∈
ϕ
l
∣
X
∈
ϕ
)
P(X\in\phi_{l}|X\in\phi)
P(X∈ϕl∣X∈ϕ)就是左子节点样本数占父节点样本数的比例:
P
(
X
∈
ϕ
l
∣
X
∈
ϕ
)
=
∑
i
=
1
N
I
{
x
i
∈
ϕ
l
}
∑
i
=
1
N
I
{
x
i
∈
ϕ
}
(39)
P(X\in\phi_{l}|X\in\phi) = \frac{\sum_{i=1}^{N}I\{x^{i}\in\phi_{l}\}}{\sum_{i=1}^{N}I\{x^{i}\in\phi\}} \tag{39}
P(X∈ϕl∣X∈ϕ)=∑i=1NI{xi∈ϕ}∑i=1NI{xi∈ϕl}(39)
其中
I
(
⋅
)
I(\cdot)
I(⋅)表示计数
E
[
Y
∣
X
∈
ϕ
l
,
T
=
t
]
=
{
E
[
Y
∣
X
∈
ϕ
,
T
=
t
]
n
l
(
t
)
<
m
i
n
_
s
p
l
i
t
∑
i
=
1
N
y
i
I
{
x
i
∈
ϕ
l
}
I
{
t
i
=
t
}
+
E
[
Y
∣
X
∈
ϕ
,
T
=
t
]
n
_
r
e
g
∑
i
=
1
N
I
{
x
i
∈
ϕ
l
}
I
{
t
i
=
t
}
+
n
_
r
e
g
o
t
h
e
r
w
i
s
e
(40)
E[Y|X\in\phi_{l},T=t] =\left\{ \begin{aligned} E[Y|X\in\phi,T=t] & & {n_{l}(t)<min\_split}\\ \frac{\sum_{i=1}^{N}y^{i}I\{x^{i}\in\phi_{l}\}I\{t^{i}=t\}+E[Y|X\in\phi,T=t]n\_reg}{\sum_{i=1}^{N}I\{x^{i}\in\phi_{l}\}I\{t^{i}=t\}+n\_reg} & & {otherwise}\\ \end{aligned} \right. \tag{40}
E[Y∣X∈ϕl,T=t]=⎩⎪⎪⎨⎪⎪⎧E[Y∣X∈ϕ,T=t]∑i=1NI{xi∈ϕl}I{ti=t}+n_reg∑i=1NyiI{xi∈ϕl}I{ti=t}+E[Y∣X∈ϕ,T=t]n_regnl(t)<min_splitotherwise(40)
其中
n
l
(
t
)
n_{l}(t)
nl(t)是左子节点中第t个策略组的人数;
m
i
n
_
s
p
l
i
t
min\_split
min_split是树模型的参数,节点最小样本数。
n
_
r
e
g
n\_reg
n_reg是一个非常小的正数,是正则项,防止单个节点中Treatment比例过少导致条件期望难以估计的问题。
显而易见,CTS也支持multi-treatment的情况。
CTS其他的部分跟uplift-tree就差不多了。OK下面就介绍CausalForest。
CausalForest
这个算法其实是一类集成模型的框架。他们的思想是把建立好的uplift tree(论文里叫causal tree)做ensemble,然后集成模型的结果就是单个uplift tree的平均。这里的uplift tree可以是任何的tree based的方法(上面两个都可以的)。
这篇论文里讲拟合一个uplift tree时说,如果一个叶子节点所含的样本足够的少,那么混杂因子就会忽略不计了(treatment与outcome(Y)相互独立了)。再这样的情况下,在这个叶节点
L
L
L的uplift(
τ
(
x
)
\tau(x)
τ(x))可以表示成:
τ
(
x
)
=
1
∣
{
i
:
T
i
=
1
,
X
i
∈
L
}
∣
∑
i
:
T
i
=
1
,
X
i
∈
L
Y
i
−
1
∣
{
i
:
T
i
=
0
,
X
i
∈
L
}
∣
∑
i
:
T
i
=
0
,
X
i
∈
L
Y
i
(41)
\tau(x) = \frac{1}{|\{ i:T_{i}=1, X_{i} \in L \}|}\sum_{ i:T_{i}=1, X_{i} \in L}Y_{i} - \frac{1}{|\{ i:T_{i}=0, X_{i} \in L \}|}\sum_{ i:T_{i}=0, X_{i} \in L}Y_{i} \tag{41}
τ(x)=∣{i:Ti=1,Xi∈L}∣1i:Ti=1,Xi∈L∑Yi−∣{i:Ti=0,Xi∈L}∣1i:Ti=0,Xi∈L∑Yi(41)
(
33
)
(33)
(33)中uplift就是实验组的
Y
Y
Y的期望和对照组的
Y
Y
Y的期望的差。这个是非常直接的想法。
如果一个causal forest产生了
B
B
B棵树,其中任意一个树
b
b
b的uplift是
τ
b
(
x
)
\tau_{b}(x)
τb(x),整个树的输出的uplift就是:
τ
(
x
)
=
B
−
1
∑
b
=
1
B
τ
b
(
x
)
(42)
\tau(x) = B^{-1}\sum_{b=1}^{B}\tau_b(x) \tag{42}
τ(x)=B−1b=1∑Bτb(x)(42)
以上的Tree Based Model:
这些方法的思想都来自于决策树以及森林,只是分裂的依据不一样。这些算法的treatment可以是二值也可以是多值,并且outcome可以是二值,多值甚至连续。但是由于一些包实现的时候只实现了一部分,所以具体问题要看要用的包是不是实现了。
这个方法其实就是再说:CTS,uplift-tree都可以组装成森林来用,最后的结果就是各棵树结果的平均。
模型评价方法
uplift model跟response model不一样,没有真实的uplift标签,所以就没有类似mse、precision、recall这样的评估指标。为了能够评价uplift model的效果,我们将评价指标(方式)分为线上评估和线下评估。 线上评价其实就是做ab测试来看经过uplift model圈人之后(什么人合适实验组,什么人合适对照组),业务指标是不是有提升。 线下评估就是想一个指标或者一个图来对比不同模型的好坏,或者评价这个模型是不是可以用。下面就着重介绍线下评估的方法。
传统模型(response model)是要求准确性,但是uplift model不仅仅需要准确,还要最大化效应人群(尽可能找全策略能对其起作用的样本。)所以指标大致分为两类准确指标和效应指标。效应指标是衡量模型圈人的能力,这个对于大多数我面临的问题就够了。如果你的问题涉及到策略的成本,那么就需要有准确性的指标。目前咱们就先介绍效应指标,如果后续我用到了准确性指标在补充吧。
Uplift decile charts
首先将所有样本按照模型给出的uplift score(就是前面说的uplift,
τ
\tau
τ)降序排列,按照等比例分为K个组,算每个组内实验组和对照组的y的均值的差(mean diff),作为评价指标,在图中按组画出mean diff。如下图:
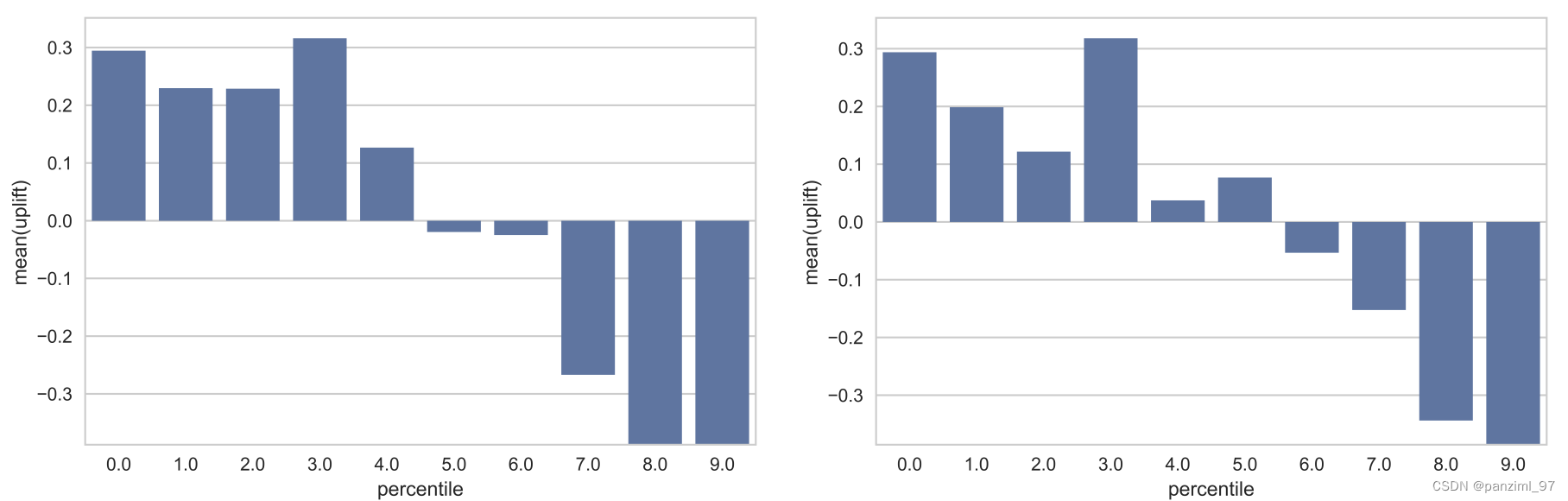
这个图虽然很直观的看出你的模型是不是有效果,但是没有办法比较多个模型的好坏。 这个方法不是我们常用的。
Uplift Curve & AUUC
首先将所有样本按照模型给出的uplift score(就是前面说的uplift, τ \tau τ)降序排列,将每个样本的累计增益(排在它前面的样本的累计增益, f ( t ) f(t) f(t))画在图上就是uplift curve,其中x轴是样本的位序,y轴是累计增益。
先说下累计增益(
f
(
t
)
f(t)
f(t))的计算方式:
f
(
t
)
=
(
Y
t
T
N
t
T
−
Y
t
C
N
t
C
)
(
N
t
T
+
N
t
C
)
(43)
f(t)=(\frac{Y_{t}^{T}}{N_{t}^{T}}-\frac{Y_{t}^{C}}{N_{t}^{C}})(N_{t}^{T}+N_{t}^{C}) \tag{43}
f(t)=(NtTYtT−NtCYtC)(NtT+NtC)(43)
(
43
)
(43)
(43)代表的是第i个样本的累计增益。其中,
Y
t
T
Y_{t}^{T}
YtT代表排在样本
t
t
t之前的所有样本中,实验组中
y
=
1
y=1
y=1的样本数;
N
t
T
N_{t}^{T}
NtT代表排在样本
t
t
t之前的所有样本中,实验组的样本数。同样,
Y
t
C
Y_{t}^{C}
YtC代表排在样本
t
t
t之前的所有样本中,对照组中
y
=
1
y=1
y=1的样本数;
N
t
C
N_{t}^{C}
NtC代表排在样本
t
t
t之前的所有样本中,对照组的样本数。
稍微理解下这个意义:实验组中 y = 1 y=1 y=1的样本应该是uplift score高的样本,对照组中 y = 1 y=1 y=1的样本应该是uplift score低的样本。因为样本已经按照uplift score由大到小排列了,所以图像左边,如果有实验组的样本,应该是 y = 1 y=1 y=1的样本尽可能多;如果有对照组的样本,应该是 y = 1 y=1 y=1的样本少。 f ( t ) f(t) f(t)描述的就是这个意思。
接下来我们看看图像:
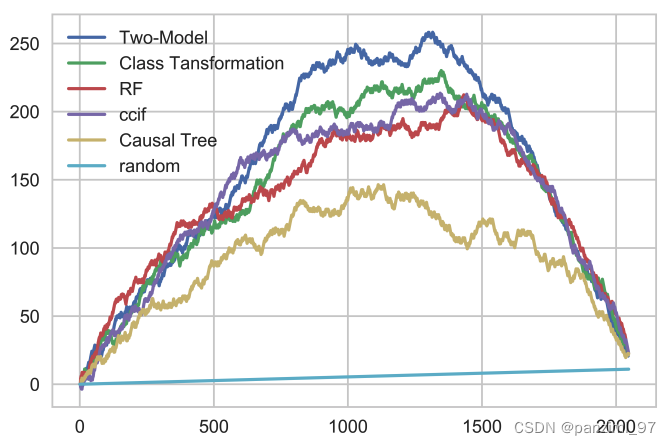
uplift curve就是这样子了。上面各种各样的曲线就是各个算法的uplift curve。 random代表的是将样本随机排列画的累计增益曲线。根据
(
43
)
(43)
(43), 图像越“向上鼓”,模型效果越好。算法uplift curve向上升的部分,就是累计增益在累加的的样本,这些是如果受到treatment,会有正向效果的样本,越靠右正向效果越明显。这些样本应该放到实验组中。 反之uplift curve下降的部分,就是treatment起负作用的部分,这里的样本如果受到treatment会有负向效果,越靠右负作用越大。这些样本应该放在对照组中。
还有一个点是: 模型和随机的uplift curve最后会相交于一点,这个表现的就是整理的因果效应大小了( C A T E CATE CATE),图中最后的累计增益是大于0的,说明实验组好于对照组。 也会遇到最后的累计增益是小于0的,这就是说实验组不如对照组。
跟ROC曲线相似,我们也可以取模型uplift curve和随机的uplift curve之间的面积代表模型的好坏,这个指标叫做AUUC(Area Under Uplift Curve),其值是说在0-1之间的 越大越好。但是在casual ml的实现中这个值也有可能大于1的。
Qini Curve & Qini Coefficient
uplift curve有个问题,当实验组和对照组的样本数不一致时,uplfit curve的评价会偏向样本多的组。qini curve就解决了这个问题,它会把对照组的样本数量做个缩放与实验组的样本量保持一致。qini curve的累计增益(
g
(
t
)
g(t)
g(t))就是:
g
(
t
)
=
(
Y
t
T
−
N
t
T
N
t
C
Y
t
C
)
N
t
T
+
N
t
C
N
t
T
(44)
g(t) = (Y_{t}^{T} - \frac{N_{t}^{T}}{N_{t}^{C}}Y_{t}^{C})\frac{N_{t}^{T}+N_{t}^{C}}{N_{t}^{T}} \tag{44}
g(t)=(YtT−NtCNtTYtC)NtTNtT+NtC(44)
(
44
)
(44)
(44)是跟
(
43
)
(43)
(43)的意义是一样的只不过要把对照组的
y
y
y的样本数做一个缩放,让实验组和对照组的数量保持一致。接下来我们看下图像。
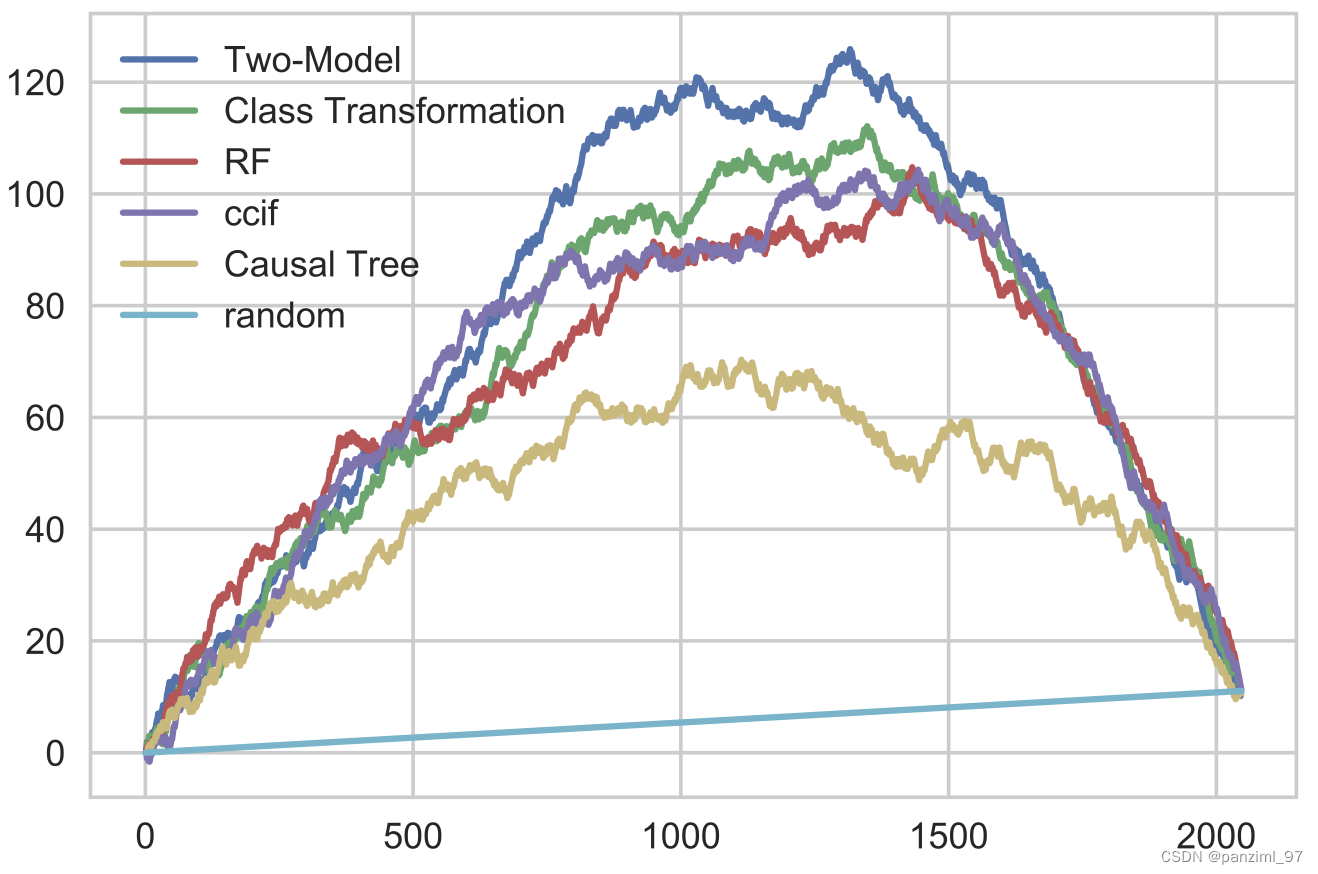
qini curve和uplift curve其实很像,图像的意义也基本一样。与AUUC相似,模型的qini curve和random curve之间的面积叫做 Qini Coefficient也是衡量模型好坏的指标,依然是越大越好。
像上面介绍的评价方式都是rank based的,他们衡量是否把人排的比较好,不太考虑准确性。但是在我的业务中,目前这样的情况也就够了。有没有既考虑排序又考虑准确性的指标或者评价方式呢? 是有的,比如moment of uplift。因为我还没有涉及到这方面的东西,如果后面接触到了再补充吧。
实现Uplift model的包
好了,终于把理论的部分说完了。接下来说一些实践的问题了。常用的包有pylift、Dowhy、Causal ML等。我是用过Causal ML,所以咱们就简单聊聊这个包的使用情况。
这个包的的github,文档。这个文档用处就是看下有哪些方法,输入输出是什么。想看怎么使用就去看github里的example文件夹,还有比如如何保存模型等就去看issue。
下面也是总结下自己用的时候的一些问题吧。
首先是哪些模型处理的范围(这里只列出了我用过的):
| 算法 | Treatment数量 | y是离散or连续 |
|---|---|---|
| UpliftTreeClassifier | 2或者多余2 | 离散 |
| UpliftRandomForestClassifier | 2或者多余2 | 离散 |
| CausalTreeRegressor | 2 | 连续 |
| CausalRandomForestRegressor | 2 | 连续 |
| BaseSClassifier | 2或者多余2 | 离散 |
| BaseSRegressor | 2或者多余2 | 连续 |
| BaseTClassifier | 2或者多余2 | 离散 |
| BaseTRegressor | 2或者多余2 | 连续 |
| BaseXClassifier | 2或者多余2 | 离散 |
| BaseXRegressor | 2或者多余2 | 连续 |
uplfitmodel的使用可以看: uplifttree例子、T,S和X的分类二值例子、T,S和X的分类多值例子和回归例子
多Treatment的模型评价:当Treatment是多值的时候,在评价模型的时候也是看应用Treatment和不用Treatment的差异,而不是具体到每一个,可以详见例子。
BaseXClassifier与其他的算法的使用会有差异,详情看这个。
uplift model应用场景
uplift model最早被应用是在营销的场景下,选出只有给优惠券才会下单的用户。套用这个场景,我们可以想一下在自己的场景中,哪些地方可以用。我这里就先抛砖引玉,也希望和大家讨论。
- 对于ab测试,特别是策略不显著有提升的或者策略可能引起其他负向的情况的时候,可以圈出适合策略的用户使用策略。这个要做的慎重,如果每个ab测试都做,那么用户分组分的特别细,可能影响后面的用户分组(分组用户不均匀)。
- 上一个想法可以不使用策略,而是做一个数据分析。分析出被圈出的用户和其他人的不同之处。这可能会给策划或者产品同学一些启示。
- 为用户选择合适的策略(多组)。这里的策略可以是广告策略,游戏难度策略等。这个需要先做一个ab测试来获得训练数据。其实能做这个事情方法很多,比如普通的机器学习(CTR预估)甚至强化学习。普通的机器学习简单,但是需要对没有经历的策略做负采样,这个如果在策略很多的时候就很难了。强化学习训练比较难。而uplift model可以不用负采样,而且建模简单。但是uplift model一般都是圈人用的,准确率可能不太高,如果你是需要考虑策略成本的情景,那么就需要对平行评价的指标进行改进了。
目前我就想到了这些,也在做一些尝试,如果有了新的想法也会补充。
Reference
uplift模型评估指标及分析
因果推断–uplift model 评估
因果推断笔记——uplift建模、meta元学习、Class Transformation Method(八)
因果推断学习笔记三——Uplift模型
因果推断综述及基础方法介绍
因果推断综述及基础方法介绍(二)
一文读懂uplift model进阶
【Uplift】因果推断基础篇
Causal Inference and Uplift Modeling A review of the literature
Uplift Modeling with Multiple Treatments and General Response Types
Estimation and Inference of Heterogeneous Treatment Effects using Random Forests
Decision trees for uplift modeling with single and multiple treatments
Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning
阿里文娱智能营销增益模型 ( Uplift Model ) 技术实践
增益模型(Uplift Model)的基础介绍 —— 估算ITE
Uplift-Model 在贝壳业务场景中的实践
[因果推断] 增益模型(Uplift Model)介绍(三)
智能营销增益模型(Uplift Modeling)的原理与实践
数据科学:因果推断(一)—— 辛普森悖论
因果推理入门(1)-辛普森悖论
因果推断学习笔记一
因果推断中的Ignorability假设

















 8865
8865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









