







深度学习是机器学习的一个子领域,深度学习通过神经网络模拟人脑神经元的连接来进行复杂数据的学习与预测。其中,卷积神经网络(CNN)主要用于计算机视觉任务;循环神经网络(RNN)则适用于处理序列数据。今天介绍CV和NLP领域一些重要模型。
后台回复abh获取文中视频和原版英文。
[RNN] 手书动画 ✍️
0. 初始化
输入序列X:[3,4,5,6]
参数矩阵:
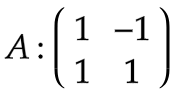
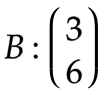
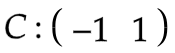
参数矩阵是通过训练得到的,图中虽然列了4个节点,但其实是同一个节点按照时间步展开的,这也是RNN经常被误解的地方。
RNN隐状态和输出的计算公式:
![]()
![]()
根据隐状态计算公式,当新的输入进来时,RNN不仅考虑当前的输入,还结合之前保存的隐状态来做出新的判断。隐状态在RNN中相当于记忆或上下文,它保存了从前面输入序列中学到的信息。
初始隐藏状态:
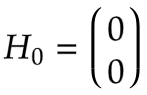
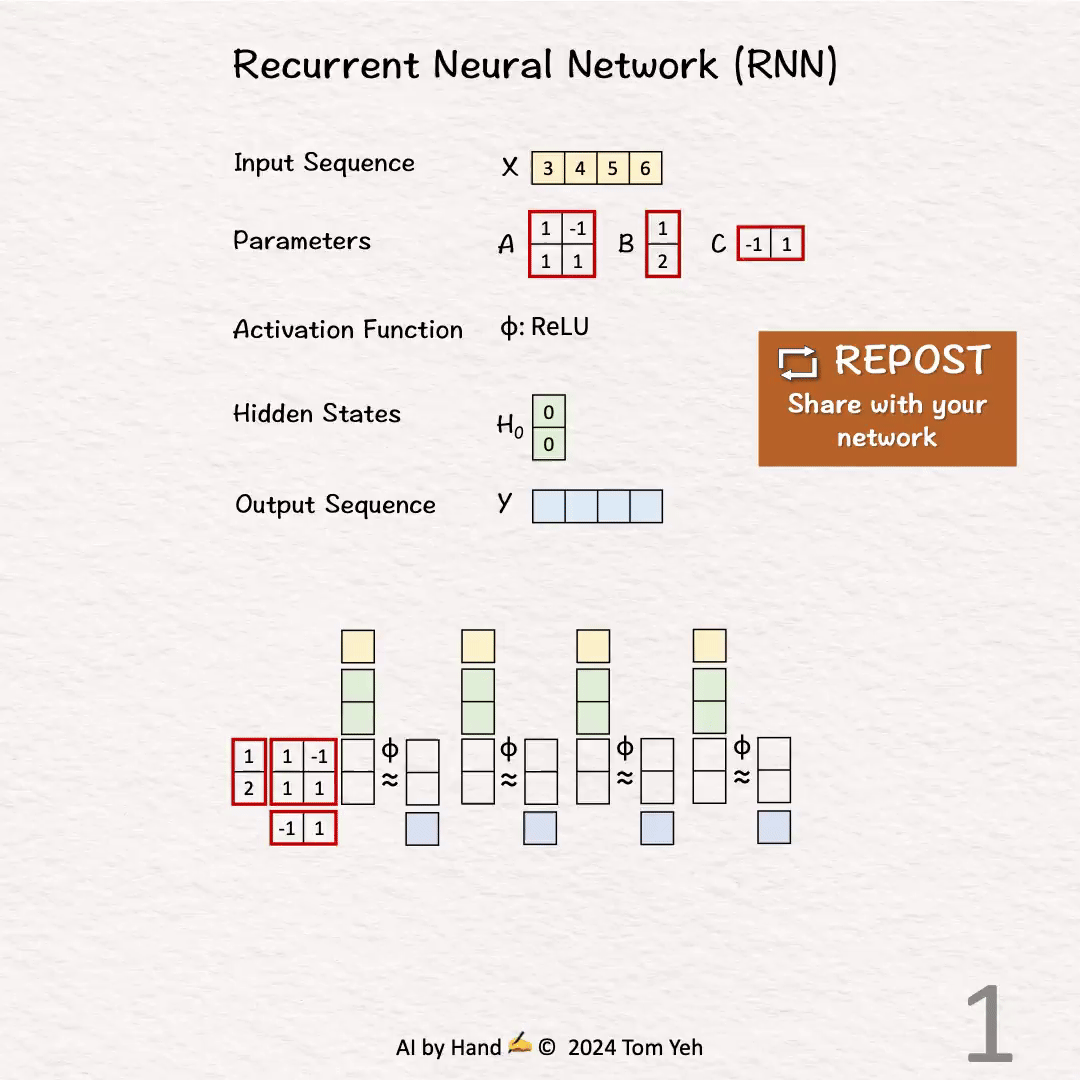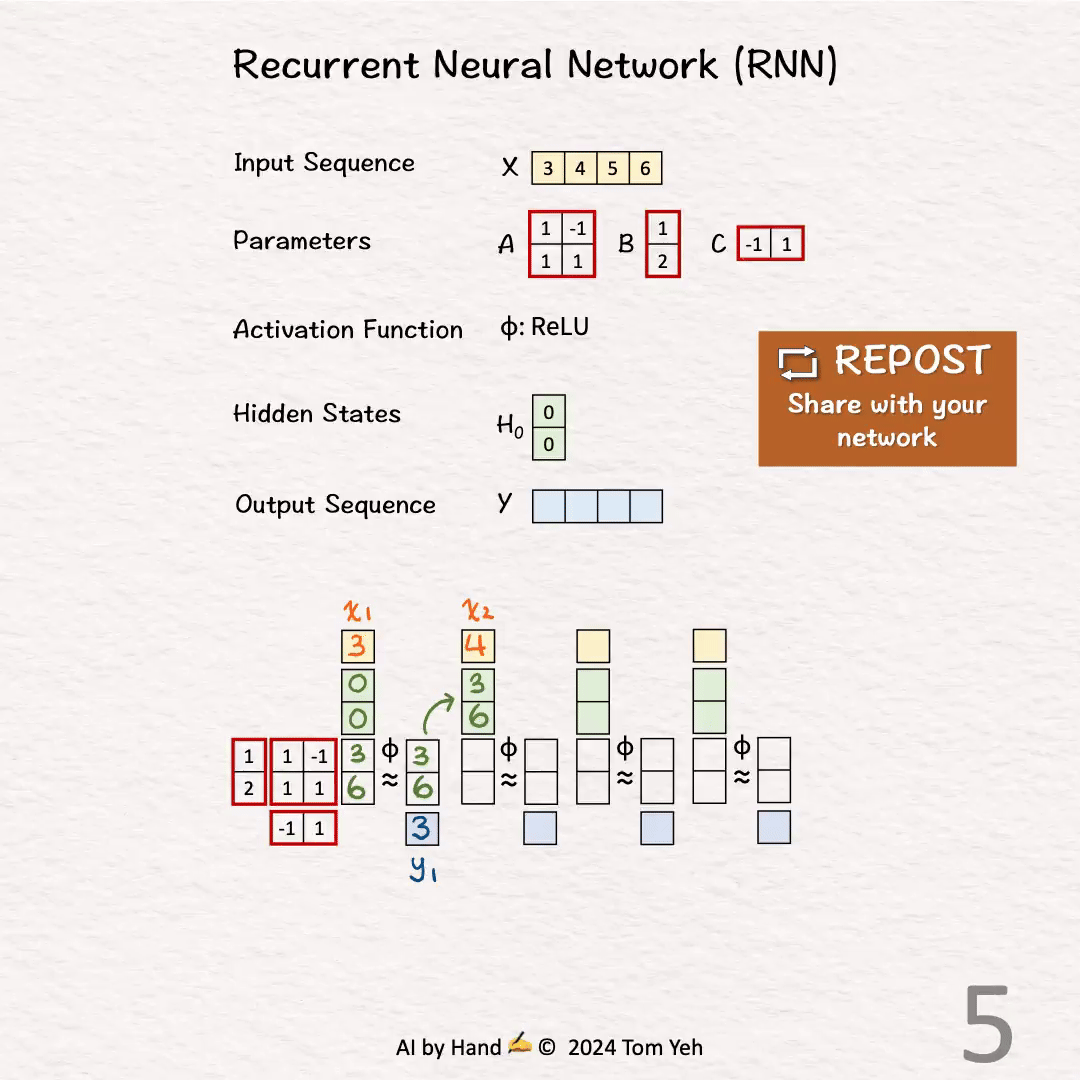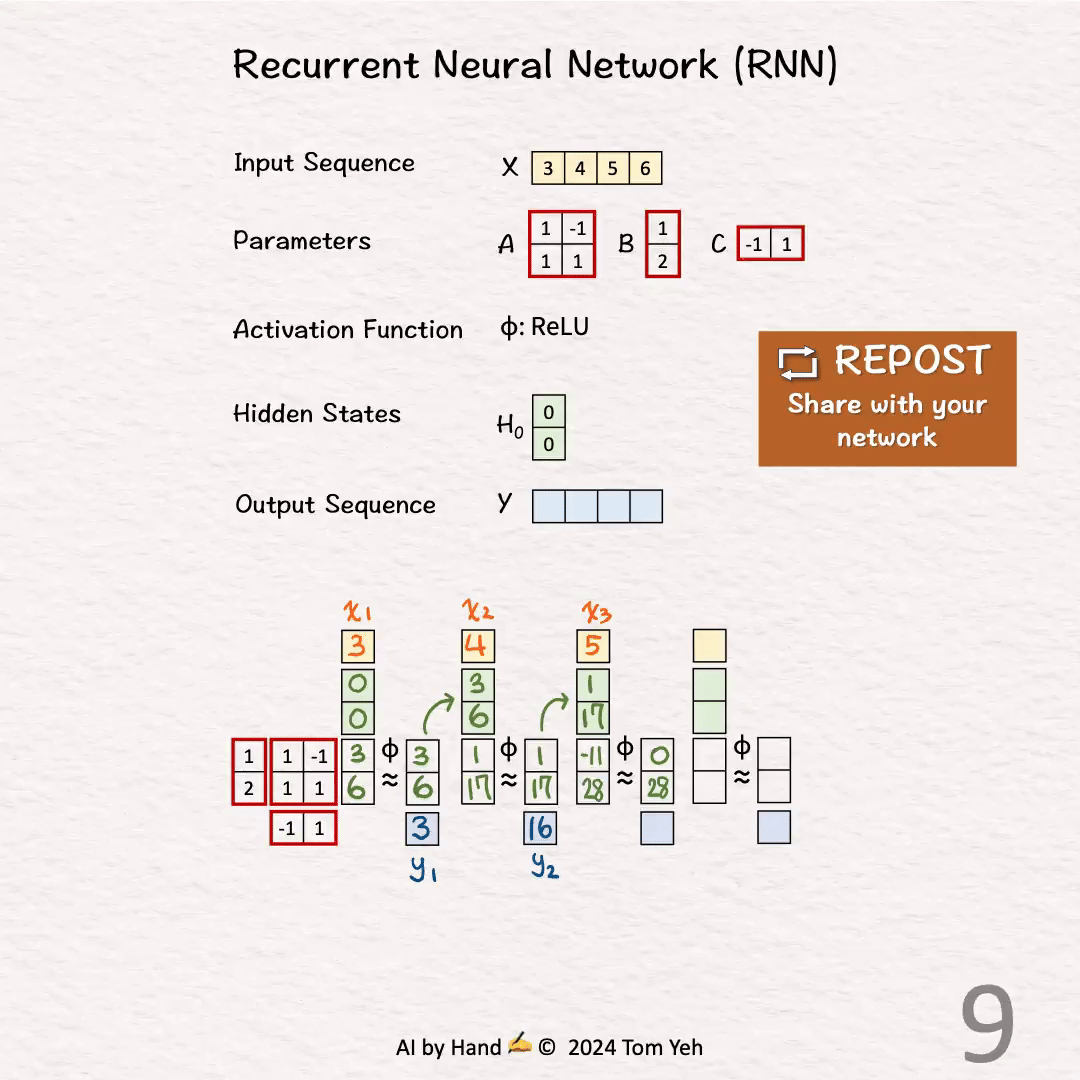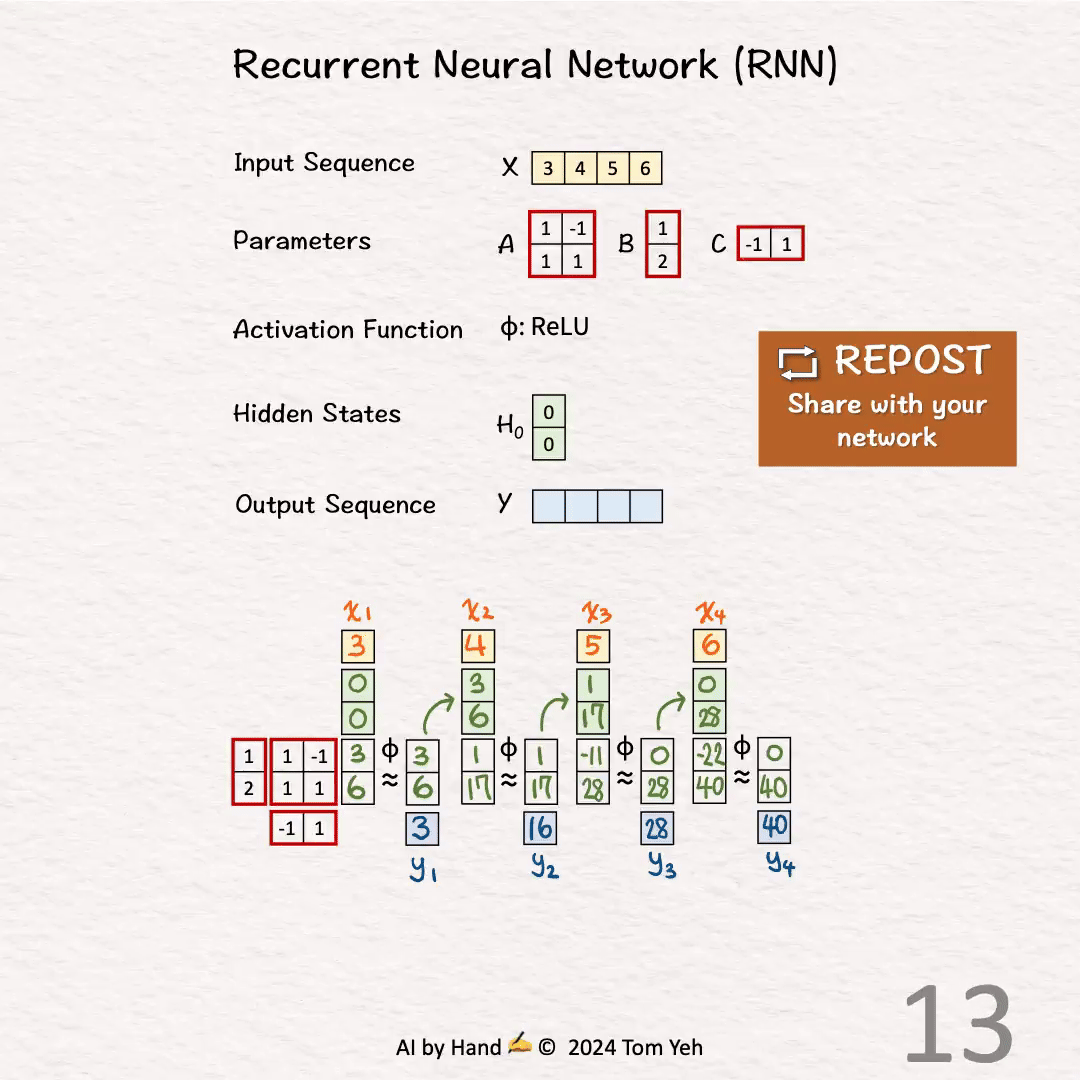
1.第一个时间步t=1
输入
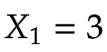
计算隐藏状态:
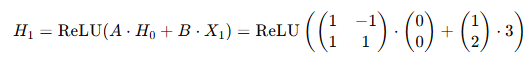
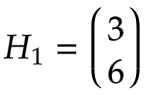
计算输出:

2.第一个时间步t=2
输入
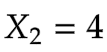
计算隐藏状态:
![]()
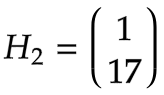
计算输出:
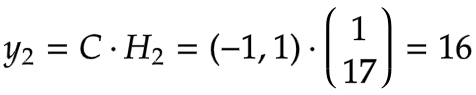
3.第一个时间步t=3
输入
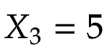
计算隐藏状态:
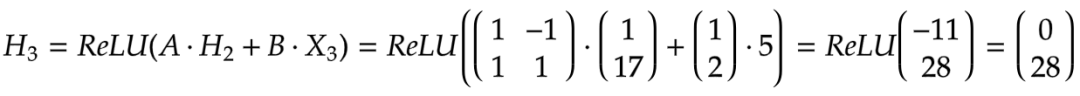
计算输出:
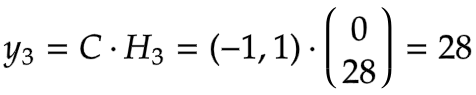
4.第一个时间步t=4
输入
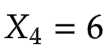
计算隐藏状态:
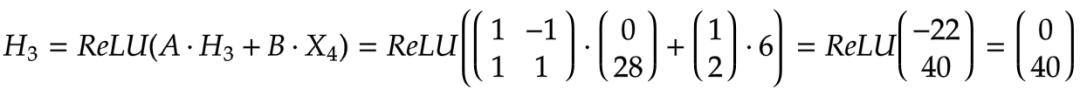
计算输出:
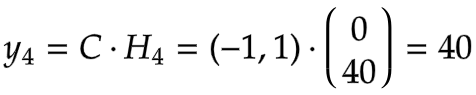
[Deep RNN] 手书动画 ✍️

Deep RNN 在普通 RNN 的基础上增加了更多的层,类似MLP的多个隐藏层,每一层可以提取更加复杂和抽象的特征,通过增加层数,Deep RNN 能够更好地捕捉序列中的复杂模式和长距离依赖关系,提升处理长序列的能力。
Deep RNN是如何工作的?
[1] 给定
一个包含四个输入X1,X2,X3, X4的序列

,以及通过训练得到隐藏层和输出层权重。
[2] 初始化隐藏状态
将a0, b0, c0初始化为零
— 处理X1 (t = 1)—
[3] 第一隐藏层 (a)

: a0 → a1
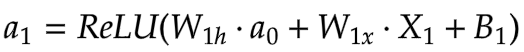
输入权重

:
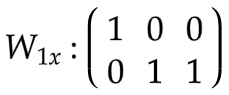
隐状态权重

:

偏置

:
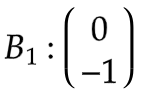
权重是通过训练过程得到的,图中四个节点其实是同一个节点按照时间展开的,所以共享同一套参数。
输入权重、隐藏状态权重和偏置的水平拼接成一个变换矩阵,视觉上表示为 [

|

|

] 。
状态矩阵是输入X1、之前的隐藏状态a0和一个额外的1的垂直拼接,视觉上表示为 [

;

; 1]。
将这两个矩阵相乘得到新的隐藏状态a1 = [0 ; 1]。
[4] 第二隐藏层 (b)

: b0 → b1
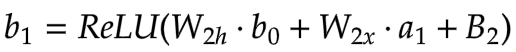
第一层的a1

成为输入。
变换矩阵视觉上表示为 [

|

|

]。
输入权重

:
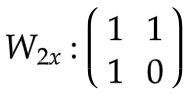
隐状态权重

:
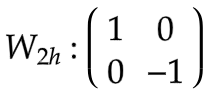
偏置

:
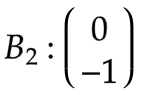
状态矩阵是a1, b0和1的组合,视觉上表示为 [

;

; 1]。
将这两个矩阵相乘得到新的隐藏状态b1 = [1; -1]。
[5] 第三隐藏层 (c)

: c0 → c1
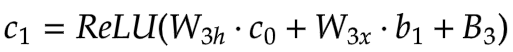
第二层的b

成为输入。
变换矩阵视觉上表示为 [

|

|

]。
输入权重

:
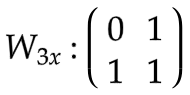
隐状态权重

:
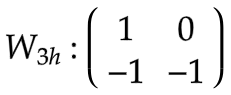
偏置

:
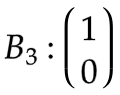
状态矩阵是b1, c0和1的组合,视觉上表示为 [

;

; 1]。
将这两个矩阵相乘得到新的隐藏状态b1 = [1; -1]。
[6] 输出层 (Y)

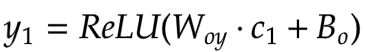
变换矩阵视觉上表示为 [

|

]。
状态矩阵是c1和1的组合,视觉上表示为 [

; 1]。
将这两个矩阵相乘得到输出Y1 = [3; 0; 3]。
— 处理X2 (t = 2)—
[7] 之前的隐藏状态
复制a1, b1, c1的值。
[8] 隐藏



+ 输出

重复步骤[3]-[6],得到输出Y2 = [5; 0; 4]
— 处理X3 (t = 3)—
[9] 之前的隐藏状态
复制a2, b2, c2的值。
[10] 隐藏



+ 输出

重复步骤[3]-[6],得到输出Y3 = [13; -1; 9]
— 处理X4 (t = 4)—
[11] 之前的隐藏状态
复制a3, b3, c3的值。
[12] 隐藏



+ 输出

重复步骤[3]-[6],得到输出Y4 = [15; 7; 2]
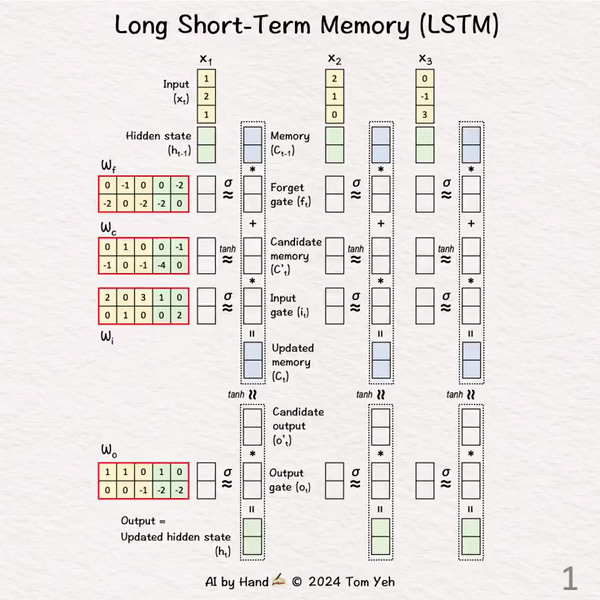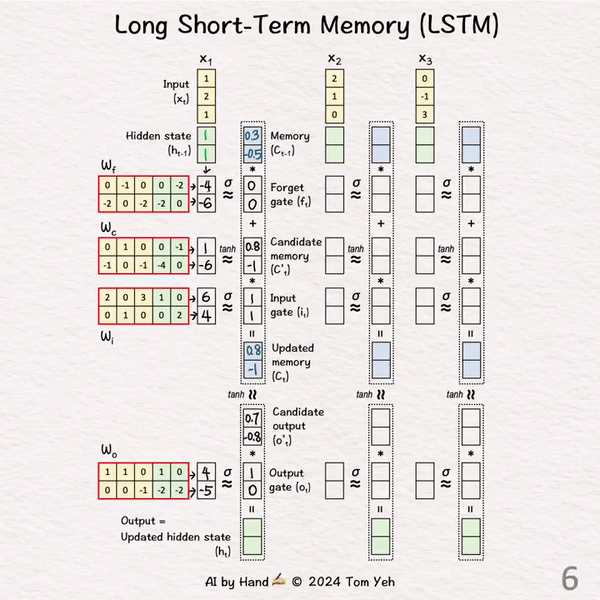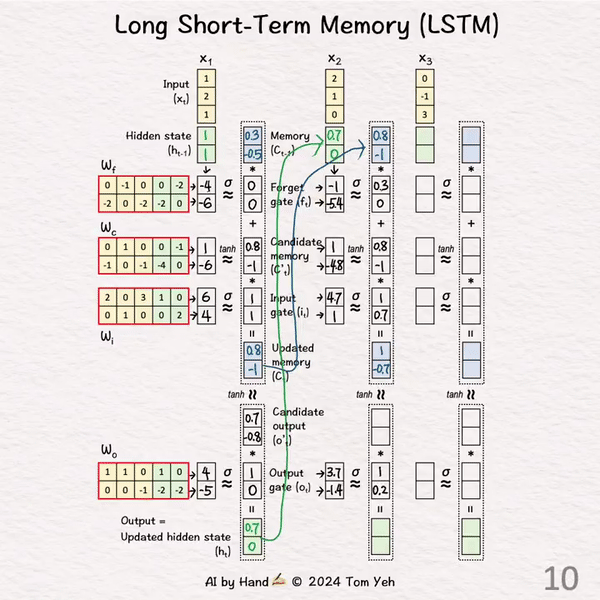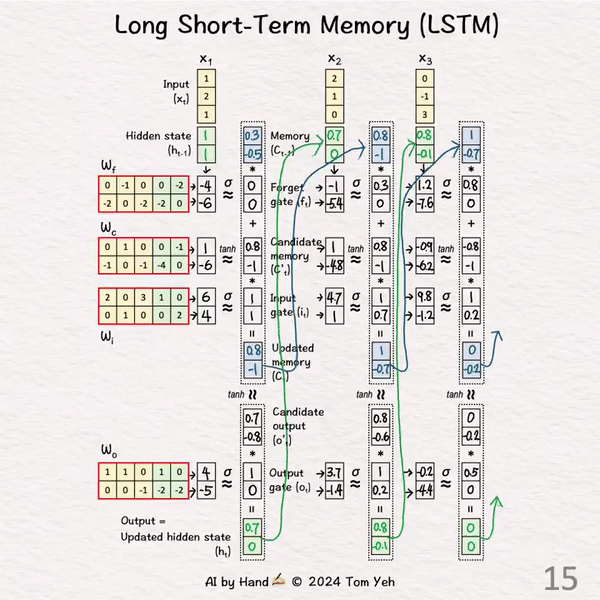
[LSTM] 手书动画 ✍️
LSTM曾经是处理长序列数据最有效的架构,直到Transformers的出现改变了这一切。
LSTM属于广义的循环神经网络(RNN)家族,以循环的方式顺序处理数据。
另一方面,Transformers放弃了循环,转而使用自注意力机制,以并行的方式同时处理数据。
最近,由于人们意识到自注意力在处理极长序列(如几十万的tokens)时并不具有可扩展性,因此对循环机制又重新产生了兴趣。Mamba就是一个将循环机制带回的好例子。
突然之间,研究LSTM又变得时髦了。
LSTM是如何工作的?
[1] 给定
↳ 🟨 输入序列 X1, X2, X3 (d = 3)
↳ 🟩 隐藏状态 h (d = 2)
↳ 🟦 记忆 C (d = 2)
↳ 权重矩阵 Wf, Wc, Wi, Wo
处理 t = 1
[2] 初始化
↳ 随机设置之前的隐藏状态h0为 [1, 1],记忆单元C0为 [0.3, -0.5]
[3] 线性变换
↳ 将四个权重矩阵与当前输入(X1)和之前的隐藏状态(h0)的拼接相乘。
↳ 结果是特征值,每个特征值都是当前输入和隐藏状态的线性组合。
[4] 非线性变换
↳ 应用sigmoid σ来获得门控值(在0到1之间)。
• 遗忘门 (f1): [-4, -6] → [0, 0]
• 输入门 (i1): [6, 4] → [1, 1]
• 输出门 (o1): [4, -5] → [1, 0]
↳ 应用tanh来获得候选记忆值(在-1到1之间)
• 候选记忆 (C’1): [1, -6] → [0.8, -1]
[5] 更新记忆
↳ 遗忘 (C0 .* f1): 逐元素地将当前记忆与遗忘门值相乘。
↳ 输入 (C’1 .* o1): 逐元素地将“候选”记忆与输入门值相乘。
↳ 通过将上述两项相加来更新记忆到C1:C0 .* f1 + C’1 .* o1 = C1
[6] 候选输出
↳ 对新的记忆C1应用tanh获得候选输出o’1。
[0.8, -1] → [0.7, -0.8]
[7] 更新隐藏状态
↳ 输出 (o’1 .* o1 → h1): 逐元素地将候选输出与输出门相乘。
↳ 结果是更新后的隐藏状态h1
↳ 同时,这也是第一次输出。
处理 t = 2
[8] 初始化
↳ 复制之前的隐藏状态h1和记忆C1
[9] 线性变换
↳ 重复步骤[3]
[10] 更新记忆 (C2)
↳ 重复步骤[4]和[5]
[11] 更新隐藏状态 (h2)
↳ 重复步骤[6]和[7]
处理 t = 3
[12] 初始化
↳ 复制之前的隐藏状态h2和记忆C2
[13] 线性变换
↳ 重复步骤[3]
[14] 更新记忆 (C3)
↳ 重复步骤[4]和[5]
[15] 更新隐藏状态 (h3)
↳ 重复步骤[6]和[7]
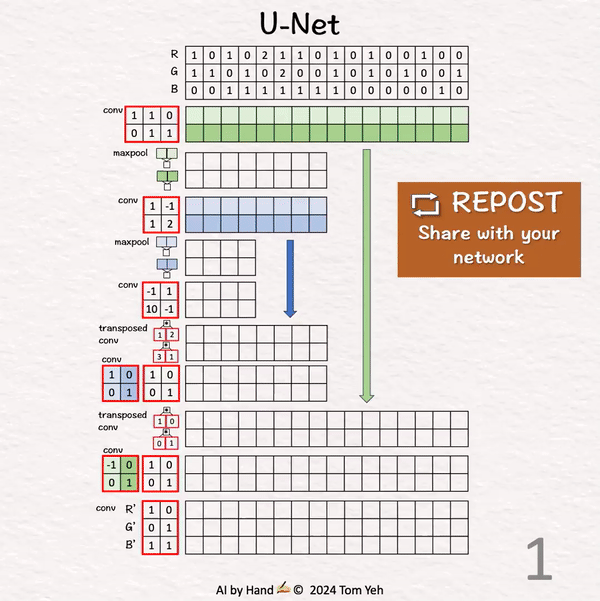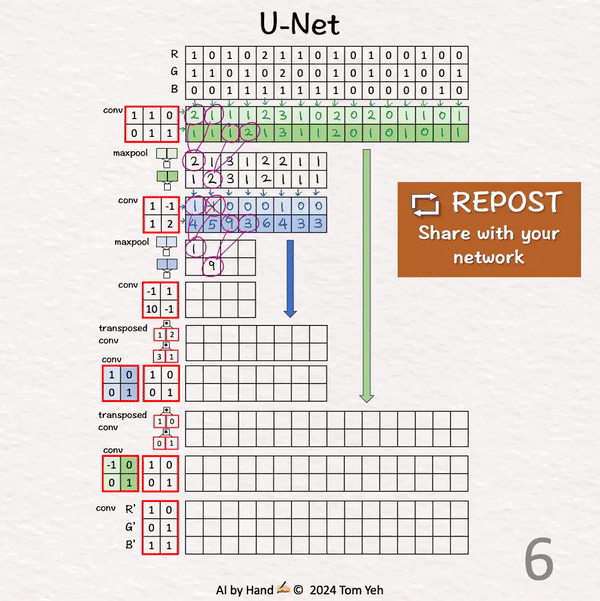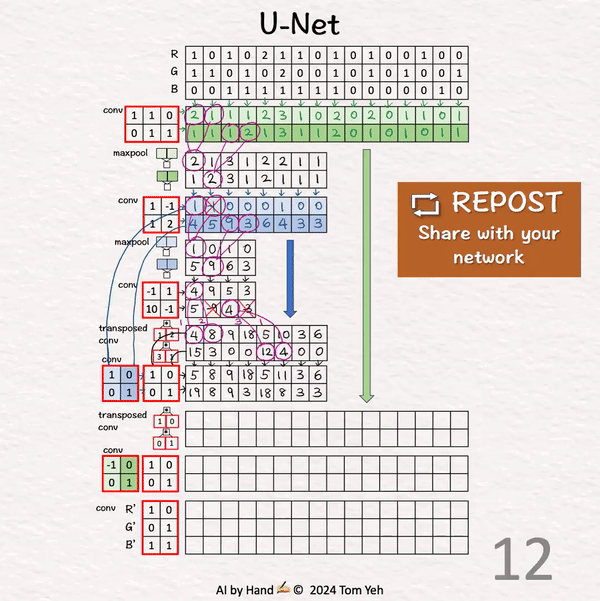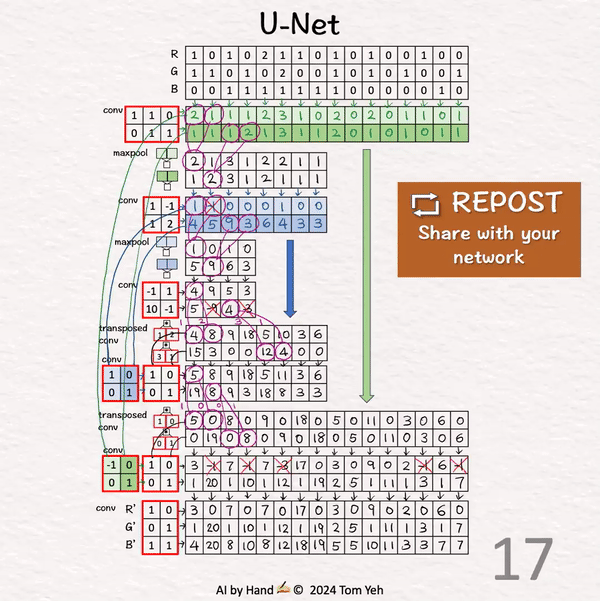
[U-Net] 手书动画 ✍️
[Graphic Convolutional Network] 手书动画✍️
-- 𝗚𝗼𝗮𝗹 目标 --
预测图中节点是否为 X。
[1] 给定
↳ 一个包含五个节点 A、B、C、D、E 的图
[2] 🟩 邻接矩阵:邻居
↳ 为每条边的邻居加 1
↳ 在两个方向上重复(例如,A->C,C->A)
↳ 对两个 GCN 层重复此操作
[3] 🟩 邻接矩阵:自环
↳ 为每个自环添加 1
↳ 等同于添加单位矩阵
↳ 对两个 GCN 层重复此操作
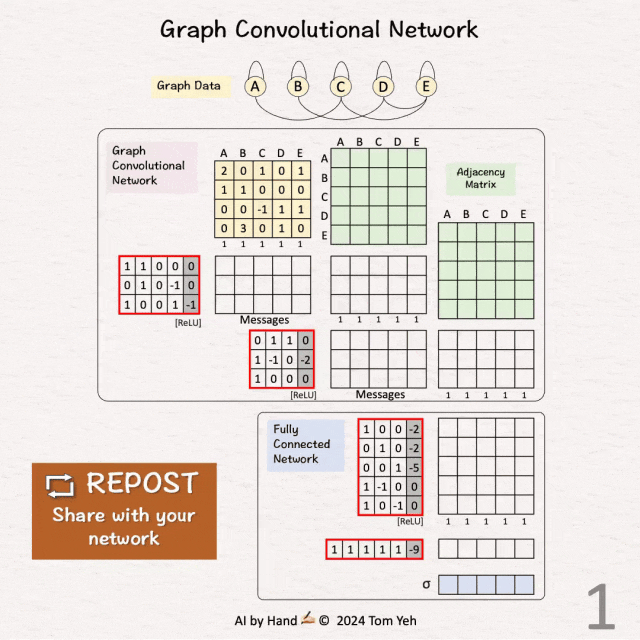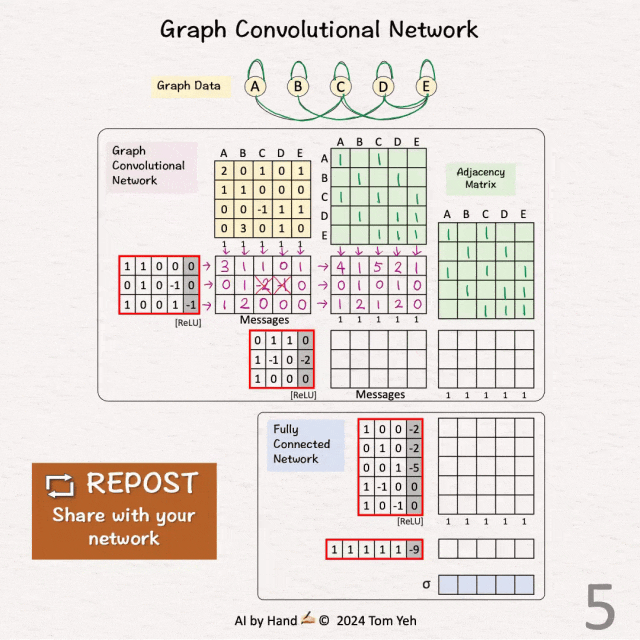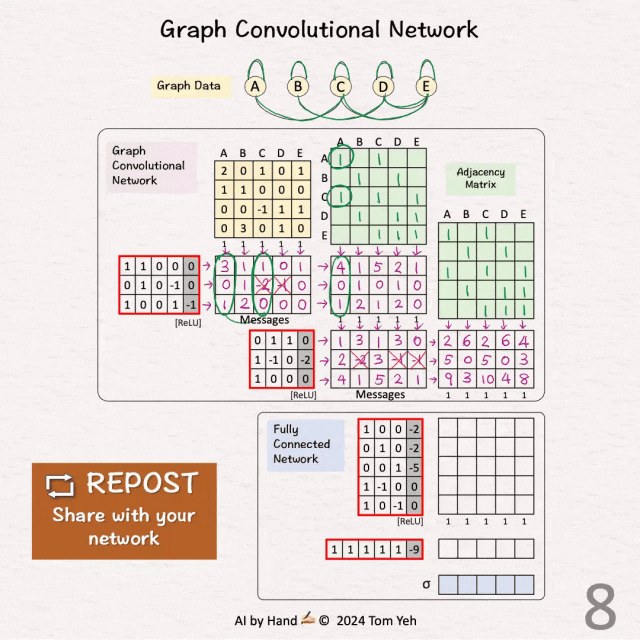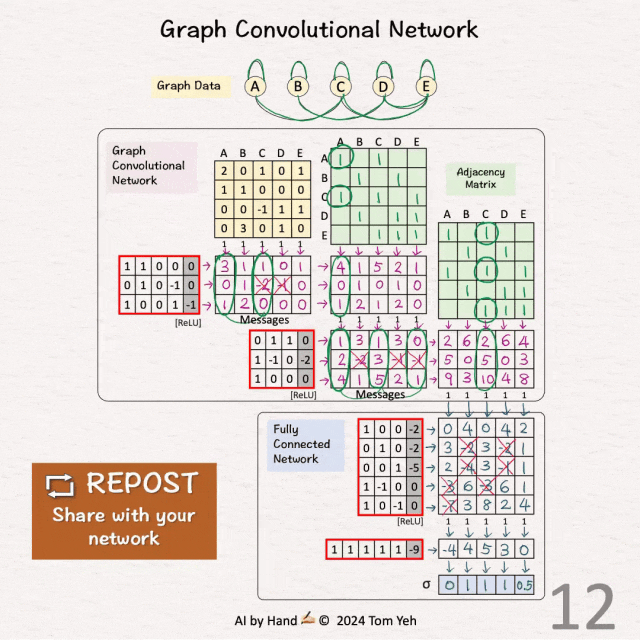
[4] 🟪 GCN1:信息传递
↳ 将节点嵌入 🟨 与权重和偏置相乘
↳ 应用 ReLU(负值 → 0)
↳ 结果是每个节点的一条信息
[5] 🟪 GCN1:池化
↳ 将信息与邻接矩阵相乘
↳ 目的是从每个节点的邻居以及节点本身汇集信息。
↳ 结果是每个节点的新特征
[6] 🟪 GCN1:可视化
↳ 对于节点 1,可视化如何汇集信息以获得新特征以便更好地理解
↳ [3,0,1] + [1,0,0] = [4,0,1]
[7] 🟪 GCN2:信息传递
↳ 将节点特征与权重和偏置相乘
↳ 应用 ReLU(负值 → 0)
↳ 结果是每个节点的一条信息
[8] 🟪 GCN2:池化
↳ 将信息与邻接矩阵相乘
↳ 结果是每个节点的新特征
[9] 🟪 GCN2:可视化
↳ 对于节点 3,可视化如何汇集信息以获得新特征以便更好地理解
↳ [1,2,4] + [1,3,5] + [0,0,1] = [2,5,10]
[10] 🟦 FCN:线性 1 + ReLU
↳ 将节点特征与权重和偏置相乘
↳ 应用 ReLU(负值 → 0)
↳ 结果是每个节点的新特征
↳ 与 GCN 层不同,不包含来自其他节点的信息。
[11] 🟦 FCN:线性 2
↳ 将节点特征与权重和偏置相乘
[12] 🟦 FCN:Sigmoid
↳ 应用 Sigmoid 激活函数
↳ 目的是为每个节点获得一个概率值
↳ 一种手动计算 Sigmoid ✍️ 的方法是使用以下近似值:
• >= 3 → 1
• 0 → 0.5
• <= -3 → 0
-- 𝗢𝘂𝘁𝗽𝘂𝘁𝘀 输出 --
A:0(非常不可能)
B:1(非常可能)
C:1(非常可能)
D:1(非常可能)
E:0.5(中立)
References
[1] https://x.com/ProfTomYeh
后台回复abh获取文中视频和原版英文。
[SVM]手书动画 ✍️
除了SVM,传统机器学习中还有很多其它分类、回归和聚类算法,例如逻辑回归,决策树,随机森林等集成学习方法;这里统称为模型,这些模型基本上可以通过明确的数学公式定义输入数据与输出结果之间的关系。
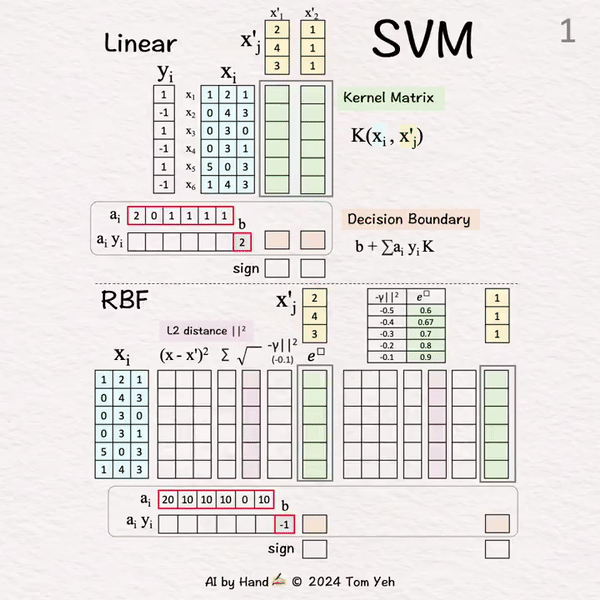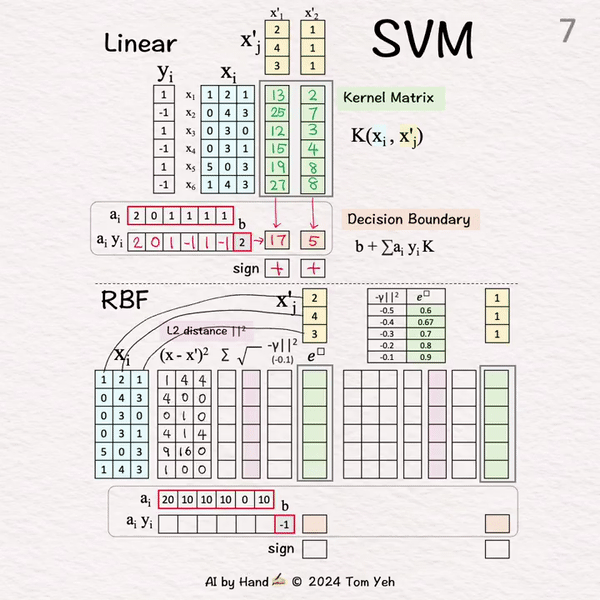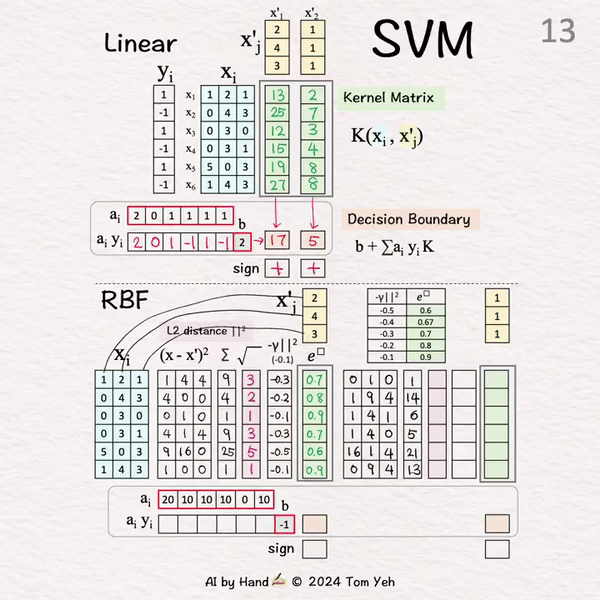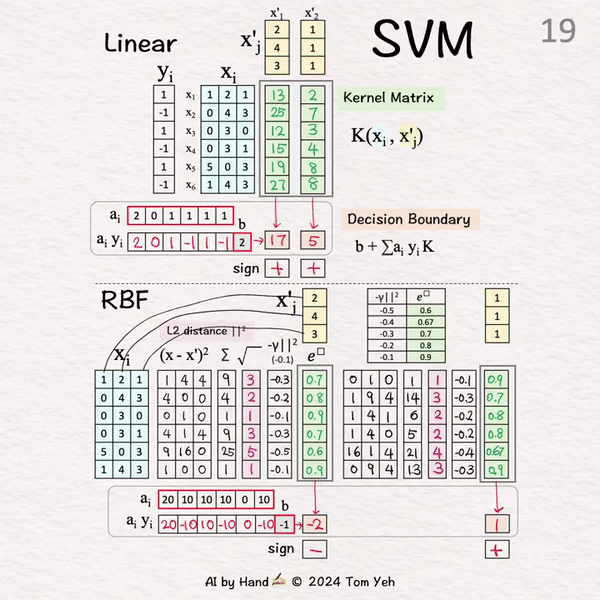
在深度学习兴起之前,支持向量机(SVM)在机器学习领域占据主导地位。
这个动画比较了线性SVM和RBF SVM。
[1] 给定:
xi: 六个训练向量(蓝色行 🟦)
yi: 标签
使用xi和yi,我们学习得到ai和b(红色边框):
ai: 每个训练向量i的系数。
• 非零: 支持向量,定义了决策边界
• 零: 距离决策边界太远,被忽略
b: 偏置(决策边界应该移动多少)
x'j: 两个测试向量(黄色列 🟨)
(为了简化手工计算,训练和测试向量没有进行归一化。)
~ 线性SVM ~
🟩 核矩阵 (K)[2]-[3]
[2] 测试向量1
计算测试向量 🟨 与每个训练向量 🟦 的点积
点积近似两个向量之间的"余弦相似度"
输出: K的第1列
[3] 测试向量2
类似于 [2]
输出: K的第2列
🟧 决策边界 [4]-[6]
[4] 无符号系数 → 有符号权重
将每个系数与相应的标签相乘
第2个训练向量不是支持向量,因为它的系数为0。
[5] 加权组合
将权重和偏置与K相乘
输出: 到决策边界的"有符号"距离
...
X'1: (2)*13+0+(1)*12+(-1)*15+(1)*19+(-1)*27+(2) = 17
X'2: (2)*2+0+(1)*3+(-1)*4+(1)*8+(-1)*8+(2) = 5
...
[6] 分类
取符号
...
X'1: 17 > 0 → 正 +
X'2: 5 > 0 → 正 +
...
~ RBF SVM ~
给定:
ai: 学习得到的系数
b: 学习得到的偏置
🟩 核矩阵 (K)
[7]-[15]
测试向量 (X'1) 🟨 L2距离 🟪 [7]-[9]
[7] 平方差
... i=1: (1-2)^2=1, (2-4)^2=4,(1-3)^2=4 ...
[8] 求和
[9] 平方根
[10] 负缩放
乘以-1: 注意L2是一个距离度量。取负将距离转换为相似度。
乘以gamma γ: 目的是控制每个训练样本的影响力。小的gamma意味着每个训练样本对决策边界的拉力较小,resulting in更平滑的决策边界。
结果是"负缩放的L2"
[11] 求指数
以e为底,"负缩放的L2"为指数
使用提供的表格查找e^的值
输出: K的第1列
测试向量2 (X'2) 🟨 L2距离 🟪 [12]-[14]
[12] 平方差
[13] 求和
[14] 平方根
[15] 负缩放
[16] 求指数
输出: K的第2列
🟧 决策边界 [17]-[19]
[17] 无符号系数 → 有符号权重
[18] 加权组合
...
X'1: (20)*0.7+(-10)*0.8+(10)*0.9+(-10)*0.7+0+(-10)*0.9+(-1) = -2
X'2: (20)*0.9+(-10)*0.7+(10)*0.8+(-10)*0.8+0+(-10)*0.9+(-1) = 1
...
[19] 分类
...
X'1: -2 < 0 → -
X'2: 1 > 0 → +
...
[反向传播] 手书动画✍️
有了模型,接下就需要通过优化算法求模型中的参数,也就是数学公式中的未知量。
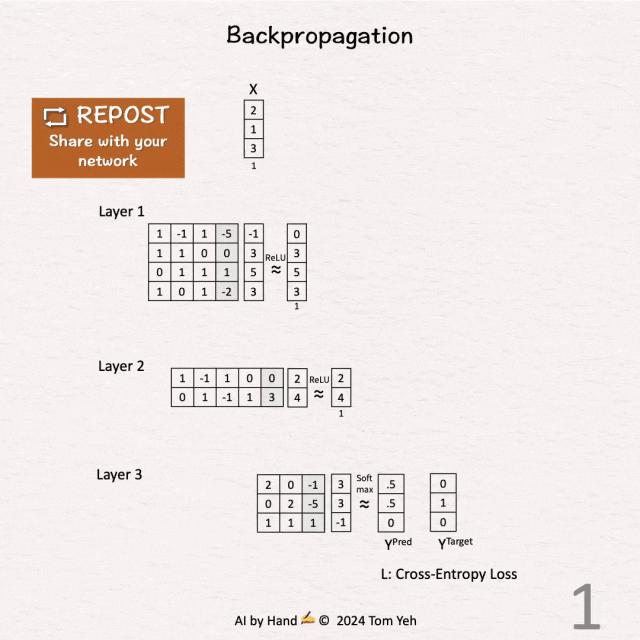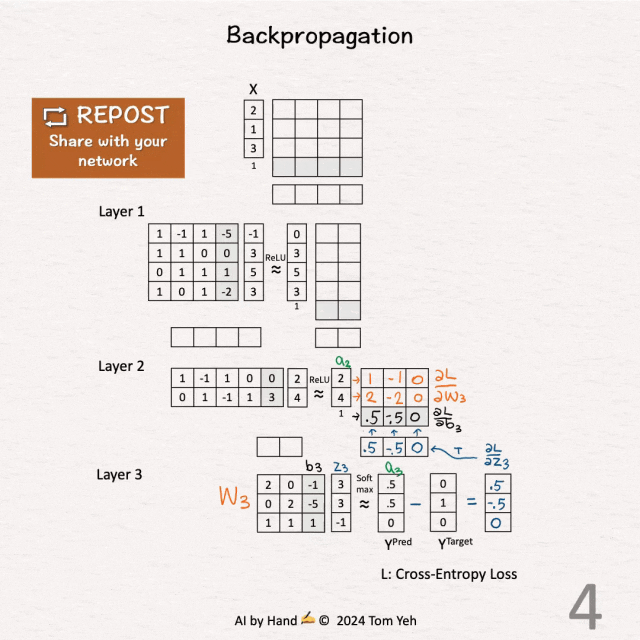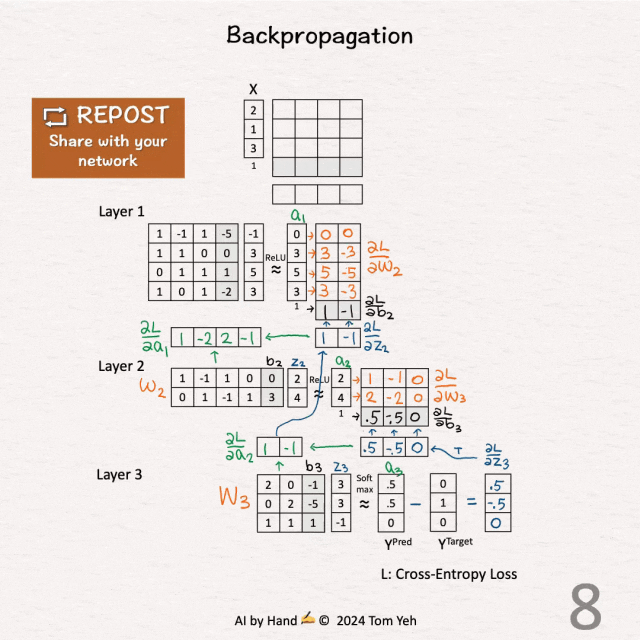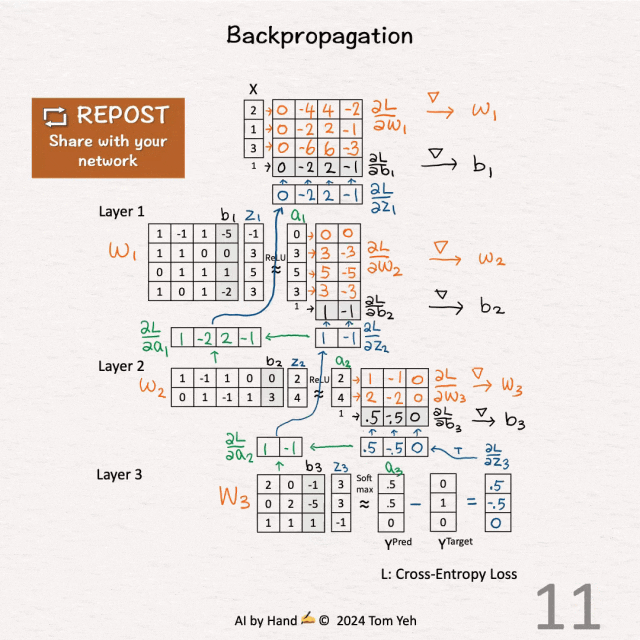
[1] 前向传播
↳ 给定一个三层的多层感知器,输入向量为X,预测结果为Y^{Pred} = [0.5, 0.5, 0],真实标签为Y^{Target} = [0, 1, 0]。
[2] 反向传播
↳ 添加单元格以存放我们的计算结果(梯度信息)。
[3] 第三层 - Softmax(蓝色)
↳ 使用化简后的公式直接计算 ∂L / ∂z3:Y^{Pred} - Y^{Target} = [0.5, -0.5, 0]。
↳ 这个化简后的公式得益于Softmax和交叉熵损失的联合使用。
[4] 第三层 - 权重(橙色)和偏置(黑色)
↳ 通过将 ∂L / ∂z3 和 [ a2 | 1 ] 相乘,计算 ∂L / ∂W3 和 ∂L / ∂b3。
[5] 第二层 - 激活(绿色)
↳ 通过将 ∂L / ∂z3 和 W3 相乘,计算 ∂L / ∂a2。
[6] 第二层 - ReLU(蓝色)
↳ 通过将 ∂L / ∂a2 乘以1(对正值)或0(对负值),计算 ∂L / ∂z2。
[7] 第二层 - 权重(橙色)和偏置(黑色)
↳ 通过将 ∂L / ∂z2 和 [ a1 | 1 ] 相乘,计算 ∂L / ∂W2 和 ∂L / ∂b2。
[8] 第一层 - 激活(绿色)
↳ 通过将 ∂L / ∂z2 和 W2 相乘,计算 ∂L / ∂a1。
[9] 第一层 - ReLU(蓝色)
↳ 通过将 ∂L / ∂a1 乘以1(对正值)或0(对负值),计算 ∂L / ∂z1。
[10] 第一层 - 权重(橙色)和偏置(黑色)
↳ 通过将 ∂L / ∂z1 和 [ x | 1 ] 相乘,计算 ∂L / ∂W1 和 ∂L / ∂b1。
[11] 梯度下降
↳ 更新权重和偏置(通常在这里应用学习率)。
💡 矩阵乘法是关键:正如在前向传播中一样,反向传播也主要是矩阵乘法。你完全可以像我在这个练习中演示的那样手动计算,尽管速度慢且不太完美。这就是为什么GPU高效矩阵乘法能力在深度学习中扮演重要角色的原因,这也是为什么NVIDIA的估值现在接近1万亿美元的原因。
💡 梯度爆炸:我们可以看到即使在这个简单的三层网络中,随着反向传播的进行,梯度正在变大。这促使我们使用诸如ResNet中跳跃连接(skip connections)的方法来处理梯度爆炸(或消失)问题。
[Multiple Layer Perceptron(MLP)]手书动画✍️
MLP更准确地说应该属于神经网络范畴,作为一种分类、回归模型,在很多地方都能看到它的身影,例如,目标检测,Transformer等。
通过隐藏层和激活函数的使用,它能够模拟任意复杂函数,与传统机器学习相比,它大大减小对经验的依赖。

步骤说明
给定一个代码模板(左侧),实现如图所示的多层感知器(右侧)。
第一个线性层。
输入特征大小为3。输出特征大小为4。我们可以看到权重矩阵的大小是4×3。此外,还有一个额外的列用于偏置(bias = T)。激活函数是ReLU。我们可以看到ReLU对第一个特征的影响(-1 -> 0)。
第二个线性层。
输入特征大小为4,与前一层的输出特征大小相同。输出特征大小为2。我们可以看到权重矩阵的大小是2×4。但是,没有额外的列用于偏置(bias = F)。激活函数是ReLU。
最后的线性层。
输入特征大小为2,与前一层的输出特征大小相同。输出特征大小为5。我们可以看到权重矩阵的大小是5×2。此外,有一个额外的列用于偏置(bias = T)。激活函数是Sigmoid。我们可以看到Sigmoid的效果,它是一个将原始分数(3, 0, -2, 5, -5)非线性映射到0到1之间的概率值的函数。
[MLP vs KAN]手书动画✍️
Transformer中MLP占据了很大一部分参数,为了提升Transformer计算效率,有人提出了KAN和MoE来作为MLP的一种替代。

机器学习所有图文110
机器学习所有图文 · 目录
上一篇AI界的力扣(LeetCode)来了下一篇终于有人将深度学习中重点做成了动画

















 33万+
33万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









