







- 摘要
- Issue1-模型部署
- Issue2-Build模型报错
- Issue3-模型训练过程中出现Allocation of ** exceeds 10% of system memory
- Issue-4 keras-h5py包版本问题
- Issue-5 使用keras转换后的ONNX模型推理报错
- Issue6-读取图像格式不对 Tensorflow2.4
- Issue7-torch quantization export onnx
- Issue8-数据标注的问题
- Issue9-Resource Exhaust
- Issue10-Pytorch2ONNX 问题
- Issue-11 Keras代码转换成Tensorflow2.X错误
- Issue-12 tensorflow2.x训练问题
- Issue-13 tensorflow2.x(keras)保存模型加载模型
- Issue14 单机多卡训练的问题
- Issue15 图像信息被翻转了
- Issue16 numpy的问题
- Issue17 训练问题
- Issue18 Batchnornalization问题
摘要
本博客记录在做深度学习的工作中遇到的坑。
Issue1-模型部署
问题描述
使用Flask部署tensorflow+keras的建筑物识别Api的时候,模型加载成功,但是使用模型预测的时候会报错,提示:Tensor Tensor(“softmax_1/truediv:0”, shape=(?, ?, 2), dtype=float32) is not an element of this graph。具体代码如下:
# 模型加载的代码:
buildingModel = Deeplabv3(classes=NCLASSES,input_shape=(HEIGHT,WIDTH,3))
buildingModel.load_weights("./models/tianheBuildings.h5")
# 预测代码:
pr = buildingModel.predict(img)[0]
原因分析
网上查了资料,众说纷纭。有人说根本原因产生两个计算图,一开始我也是认为是这样的,因为在我的FlaskAPI下面确实部署了其他的深度学习模型。但是我也不确定是不是这个原因。keras的github仓库上有相对应的issue,可以参考下:https://github.com/keras-team/keras/issues/2397。感觉这个问题比较玄学,也可以参考这个https://zhuanlan.zhihu.com/p/27101000。
解决方案
上面知乎专栏上是加载模型之后对一组随机生成的数据进行预测,后续对其他数据predict就没有问题。下面有两种方法:
-
buildingModel = Deeplabv3(classes=NCLASSES,input_shape=(HEIGHT,WIDTH,3)) buildingModel.load_weights("./models/tianheBuildings.h5") # 加载模型完成后进行预测: buildingModel._make_predict_function() -
第二种解决方案:
buildingModel = Deeplabv3(classes=NCLASSES,input_shape=(HEIGHT,WIDTH,3)) buildingModel.load_weights("./models/tianheBuildings.h5") graph_building = tf.get_default_graph() # buildingModel._make_predict_function() def buildingSeg(uploadPath, filename, save_dir): img = Image.open(uploadPath+filename) old_img = copy.deepcopy(img) orininal_h = np.array(img).shape[0] orininal_w = np.array(img).shape[1] img = img.resize((WIDTH,HEIGHT), Image.BICUBIC) img = np.array(img) / 255 img = img.reshape(-1, HEIGHT, WIDTH, 3) # 使用这个即可 with graph_building.as_default(): pr = buildingModel.predict(img)[0] pr = pr.reshape((int(HEIGHT), int(WIDTH), NCLASSES)).argmax(axis=-1) seg_img = np.zeros((int(HEIGHT), int(WIDTH),3)) for c in range(NCLASSES): seg_img[:, :, 0] += ((pr[:,: ] == c) * class_colors[c][0]).astype('uint8') seg_img[:, :, 1] += ((pr[:,: ] == c) * class_colors[c][1]).astype('uint8') seg_img[:, :, 2] += ((pr[:,: ] == c) * class_colors[c][2]).astype('uint8') seg_img = Image.fromarray(np.uint8(seg_img)).resize((orininal_w,orininal_h)) image = Image.blend(old_img,seg_img,0.3) save_image = filename.split('.')[0] save_blend_filename = save_dir+save_image+'_blend.jpg' save_predict_filename = save_dir+save_image+'_predict.jpg' image.save(save_blend_filename) seg_img.save(save_predict_filename) return save_blend_filename, save_predict_filename
Issue2-Build模型报错
问题描述
在tensorflow2上build模型的时候出现一下错误:

原因分析
按照英文的提示:‘You cannot build your model by calling build if your layers do not support float type inputs. Instead, in order to instantiate and build your model, call your model on real tensor data (of the correct dtype)’ 说我的网络层不支持浮点类型的输入? 我的输入是:
model.build(input_shape=(None, 512, 512, 3))
解决方案
重新编写了resnet的代码然后就可以了。
'''
Tensorflow 实现resNet
作者:chenjl
日期:20210609
'''
import tensorflow as tf
from tensorflow.keras import layers, models
NUM_CLASSES = 10
class BasicBlock(tf.keras.layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(filters=filter_num,
kernel_size=(3, 3),
strides=stride,
padding="same")
self.bn1 = tf.keras.layers.BatchNormalization()
self.conv2 = tf.keras.layers.Conv2D(filters=filter_num,
kernel_size=(3, 3),
strides=1,
padding="same")
self.bn2 = tf.keras.layers.BatchNormalization()
if stride != 1:
self.downsample = tf.keras.Sequential()
self.downsample.add(tf.keras.layers.Conv2D(filters=filter_num,
kernel_size=(1, 1),
strides=stride))
self.downsample.add(tf.keras.layers.BatchNormalization())
else:
self.downsample = lambda x: x
def call(self, inputs, training=None, **kwargs):
residual = self.downsample(inputs)
x = self.conv1(inputs)
x = self.bn1(x, training=training)
x = tf.nn.relu(x)
x = self.conv2(x)
x = self.bn2(x, training=training)
output = tf.nn.relu(tf.keras.layers.add([residual, x]))
return output
class BottleNeck(tf.keras.layers.Layer):
def __init__(self, filter_num, stride=1):
super(BottleNeck, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(filters=filter_num,
kernel_size=(1, 1),
strides=1,
padding='same')
self.bn1 = tf.keras.layers.BatchNormalization()
self.conv2 = tf.keras.layers.Conv2D(filters=filter_num,
kernel_size=(3, 3),
strides=stride,
padding='same')
self.bn2 = tf.keras.layers.BatchNormalization()
self.conv3 = tf.keras.layers.Conv2D(filters=filter_num * 4,
kernel_size=(1, 1),
strides=1,
padding='same')
self.bn3 = tf.keras.layers.BatchNormalization()
self.downsample = tf.keras.Sequential()
self.downsample.add(tf.keras.layers.Conv2D(filters=filter_num * 4,
kernel_size=(1, 1),
strides=stride))
self.downsample.add(tf.keras.layers.BatchNormalization())
def call(self, inputs, training=None, **kwargs):
residual = self.downsample(inputs)
x = self.conv1(inputs)
x = self.bn1(x, training=training)
x = tf.nn.relu(x)
x = self.conv2(x)
x = self.bn2(x, training=training)
x = tf.nn.relu(x)
x = self.conv3(x)
x = self.bn3(x, training=training)
output = tf.nn.relu(tf.keras.layers.add([residual, x]))
return output
def make_basic_block_layer(filter_num, blocks, stride=1):
res_block = tf.keras.Sequential()
res_block.add(BasicBlock(filter_num, stride=stride))
for _ in range(1, blocks):
res_block.add(BasicBlock(filter_num, stride=1))
return res_block
def make_bottleneck_layer(filter_num, blocks, stride=1):
res_block = tf.keras.Sequential()
res_block.add(BottleNeck(filter_num, stride=stride))
for _ in range(1, blocks):
res_block.add(BottleNeck(filter_num, stride=1))
return res_block
class ResNetTypeI(tf.keras.Model):
def __init__(self, layer_params):
super(ResNetTypeI, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(filters=64,
kernel_size=(7, 7),
strides=2,
padding="same")
self.bn1 = tf.keras.layers.BatchNormalization()
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=(3, 3),
strides=2,
padding="same")
self.layer1 = make_basic_block_layer(filter_num=64,
blocks=layer_params[0])
self.layer2 = make_basic_block_layer(filter_num=128,
blocks=layer_params[1],
stride=2)
self.layer3 = make_basic_block_layer(filter_num=256,
blocks=layer_params[2],
stride=2)
self.layer4 = make_basic_block_layer(filter_num=512,
blocks=layer_params[3],
stride=2)
self.avgpool = tf.keras.layers.GlobalAveragePooling2D()
self.fc = tf.keras.layers.Dense(units=NUM_CLASSES, activation=tf.keras.activations.softmax)
def call(self, inputs, training=None, mask=None):
x = self.conv1(inputs)
x = self.bn1(x, training=training)
x = tf.nn.relu(x)
x = self.pool1(x)
x = self.layer1(x, training=training)
x = self.layer2(x, training=training)
x = self.layer3(x, training=training)
x = self.layer4(x, training=training)
x = self.avgpool(x)
output = self.fc(x)
return output
class ResNetTypeII(tf.keras.Model):
def __init__(self, layer_params):
super(ResNetTypeII, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(filters=64,
kernel_size=(7, 7),
strides=2,
padding="same")
self.bn1 = tf.keras.layers.BatchNormalization()
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=(3, 3),
strides=2,
padding="same")
self.layer1 = make_bottleneck_layer(filter_num=64,
blocks=layer_params[0])
self.layer2 = make_bottleneck_layer(filter_num=128,
blocks=layer_params[1],
stride=2)
self.layer3 = make_bottleneck_layer(filter_num=256,
blocks=layer_params[2],
stride=2)
self.layer4 = make_bottleneck_layer(filter_num=512,
blocks=layer_params[3],
stride=2)
self.avgpool = tf.keras.layers.GlobalAveragePooling2D()
self.fc = tf.keras.layers.Dense(units=NUM_CLASSES, activation=tf.keras.activations.softmax)
def call(self, inputs, training=None, mask=None):
x = self.conv1(inputs)
x = self.bn1(x, training=training)
x = tf.nn.relu(x)
x = self.pool1(x)
x = self.layer1(x, training=training)
x = self.layer2(x, training=training)
x = self.layer3(x, training=training)
x = self.layer4(x, training=training)
x = self.avgpool(x)
output = self.fc(x)
return output
def resnet_18():
return ResNetTypeI(layer_params=[2, 2, 2, 2])
def resnet_34():
return ResNetTypeI(layer_params=[3, 4, 6, 3])
def resnet_50():
return ResNetTypeII(layer_params=[3, 4, 6, 3])
def resnet_101():
return ResNetTypeII(layer_params=[3, 4, 23, 3])
def resnet_152():
return ResNetTypeII(layer_params=[3, 8, 36, 3])
if __name__ == '__main__':
model = resnet_18()
model.build(input_shape=(1000, 512, 512, 3))
model.summary()
print('debug')
Issue3-模型训练过程中出现Allocation of ** exceeds 10% of system memory
问题描述
在使用unet模型训练语义分割的时候,在第一,第二步出现以下报错信息Allocation of ** exceeds 10% of system memory,后面训练就开始正常了。

原因分析
内存占用满了
解决方案
调小batch size。
https://blog.csdn.net/qq_34559890/article/details/89357279
Issue-4 keras-h5py包版本问题
问题描述
在使用keras——tensorflow的时候,出现AttributeError: ‘str’ object has no attribute ‘decode’

原因分析
h5py包的版本不正确,本版本的是3.3.0,改为2.10.0就可以了
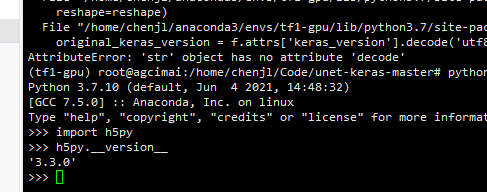
解决方案
pip install h5py==2.10.0
Issue-5 使用keras转换后的ONNX模型推理报错
问题描述
keras的模型用keras2onnx导出了ONNX的模型,使用ONNX模型报错:

原因分析
错误提示已经非常明显了,就是ONNX希望你输入的数据类型是tensor(float),但是实际输入了tensor(double),我在debug控制台上看待输出类型是float64,只需要将其转换成float32即可

解决方案
添加astype(np.float32)即可

Issue6-读取图像格式不对 Tensorflow2.4
问题描述
在使用tensorflow2.4训练的时候出现以下错误,提示已经很明白,图像格式不对,不是JPEG,PNG,GIF,BMP格式。但是训练图像的后缀是jpg。因此需要写一个图像格式检查脚本对图像的format进行检查。
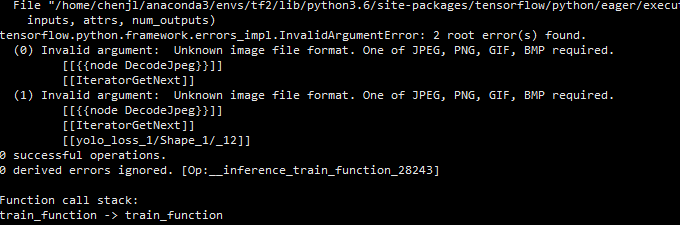
解决方案
用opencv转换一次
try:
img=cv2.imread(klass_path)
shape=img.shape
cv2.imwrite(klass_path, img)
except:
print('file ', klass_path, ' is not a valid image file')
bad_images.append(klass_path)
Issue7-torch quantization export onnx
问题描述
使用onnx导出torch quantization的时候报错:
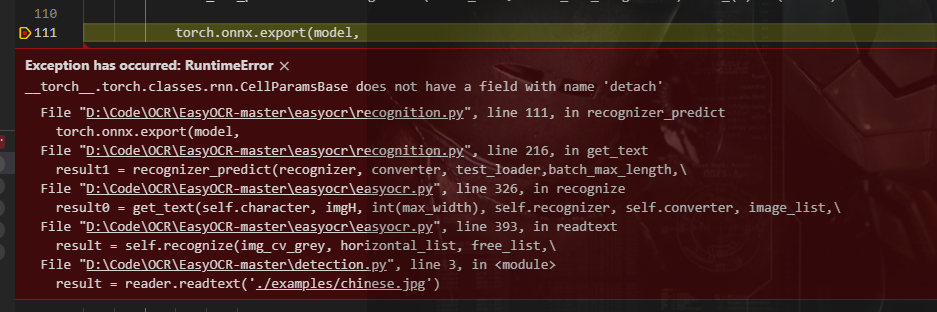
解决方案
在pytorch社区上看大,直到2020年4月份仍未支持onnx导出quantization。

但是在社区上看到有这个解决方案:https://discuss.pytorch.org/t/onnx-export-of-quantized-model/76884/8
Issue8-数据标注的问题
问题描述
今早前端同事找我反馈说使用目标检测模型推理时出现浮点数,而且位置出现负数的情况。我就纳闷,位置框怎么出现负数。于是我检查下标注数据,发现有个类别的数据使用labelme生成json文件然后转换成xml文件,不知道是转换过程中出现浮点数还是标注是浮点数。我觉得很大概率是标注的时候产生了浮点数。上图是labelme生成的标注,下图是labelimg生成的。

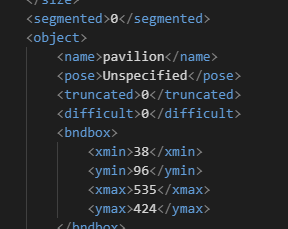
解决方案
后续使用labelimg标注目标检测数据集。
Issue9-Resource Exhaust
问题描述
在训练的时候出现Resouce Exhaust

原因分析
感觉主要有两方面的原因:1. 读取训练集的方式有误,可以优化成迭代器的方式读取数据。2. batchsize过大
解决方案
调小batch_size或者优化读取训练集的方式
Issue10-Pytorch2ONNX 问题
问题描述
将deeplabV3plus_resnet101的模型转换成onnx的时候报错

原因分析
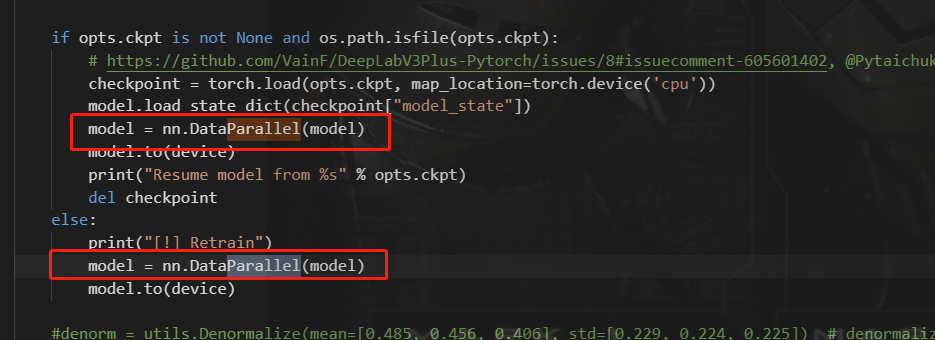
提示已经非常明确了:torch.nn.DataParallel is not supported by ONNX exporter
解决方案
please use ‘attribute’ module to unwrap model from torch.nn.DataParallel. Try torch.onnx.export(model.module, …)
但是用以上这种解决方案,转换出来的ONNX模型与原pytorch的模型推理结果并不一样。
ONNX推理结果:

pytorch推理结果:

Issue-11 Keras代码转换成Tensorflow2.X错误
问题描述
在做实例分割任务时使用matterport/Mask_RCNN转成tensorflow2的代码时,出现错误:

原因分析
错误信息已经提示很清晰并且已经Google过,是因为版本不对的原因:https://stackoverflow.com/questions/65383964/typeerror-could-not-build-a-typespec-with-type-kerastensor。但是我现在的任务就是要将其转化成tensorflow2的代码。我在参考别的Mask-Rcnn tensorflow2 repo也是这样改。
解决方案
参照https://github.com/akTwelve/Mask_RCNN 这个repo进行修改。我的Repo地址:https://github.com/RyanCCC/Mask_RCNN。在debug过程中发现我的错误代码的input_image是KerasTensor类型的,而应该是tf.Tensor类型。错误的见上图,正确的见下图。


只需要关闭tf2里面兼容tf1的eager模式就行了

Related topics:
https://github.com/matterport/Mask_RCNN/issues/1889#issuecomment-786683553

Issue-12 tensorflow2.x训练问题
问题描述
在使用tensorflow2.x训练unet的时候报以下截图的错误

原因分析
GPU显存不够导致报错

解决方案
- 扩充GPU或者等GPU空闲的时候使用
- tensorflow2.x显示GPU的使用。
Issue-13 tensorflow2.x(keras)保存模型加载模型
问题描述
在完成模型训练尝试将模型保存json的格式做加载处理,在复原的时候报了以下错误:

原因分析
见keras的issue:issues-8612:can not load_model() or load_from_json() if my model contains my own Layer
Handling custom layers (or other custom objects) in saved models
If the model you want to load includes custom layers or other custom classes or functions,
you can pass them to the loading mechanism via the custom_objects argument:
Assuming your model includes instance of an “AttentionLayer” classfrom keras.models import load_model model = load_model('my_model.h5', custom_objects={'AttentionLayer': AttentionLayer})Alternatively, you can use a custom object scope:
from keras.utils import CustomObjectScope with CustomObjectScope({'AttentionLayer': AttentionLayer}): model = load_model('my_model.h5')Custom objects handling works the same way for load_model, model_from_json, model_from_yaml:
from keras.models import model_from_json model = model_from_json(json_string, custom_objects={'AttentionLayer': AttentionLayer})
解决方案
Assuming your model includes instance of an “AttentionLayer” class
model_from_json(json_string, custom_objects={'AttentionLayer': AttentionLayer})
Issue14 单机多卡训练的问题
问题描述
使用keras的单级多卡训练的Api之后,报了以下错误:

相关代码如下:
定义单级多卡分布的配置:
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = get_train_model(config)
model.summary()
model.load_weights(COCO_MODEL_PATH,by_name=True,skip_mismatch=True)
原因分析
Additionally, if using less than two GPUs, then optimizer weights are only loaded if load_weights is called outside of strategy.scope(). This seems undesired, since the structure of the code needed to load identical model weights differs based on hardware configuration.
解决方案
将上面代码改成:
with strategy.scope():
model = get_train_model(config)
model.summary()
model.load_weights(COCO_MODEL_PATH,by_name=True,skip_mismatch=True)
Issue15 图像信息被翻转了
问题描述
今天在做tfrecord数据集的时候发现以下情况:在电脑上查看数据集好好地,但是送入到网络的时候数据集发生了翻转。

原因分析
这篇博客写的非常清楚了:计算机视觉模型效果不佳,你可能是被相机的Exif信息坑了。简单来说就是程序没有简析到图像的exif信息。
解决方案
- 用苹果或者平板拍摄的时候要锁定手机
- 用那篇博客的代码进行预处理。
import PIL.Image
import PIL.ImageOps
import numpy as np
def exif_transpose(img):
if not img:
return img
exif_orientation_tag = 274
# Check for EXIF data (only present on some files)
if hasattr(img, "_getexif") and isinstance(img._getexif(), dict) and exif_orientation_tag in img._getexif():
exif_data = img._getexif()
orientation = exif_data[exif_orientation_tag]
# Handle EXIF Orientation
if orientation == 1:
# Normal image - nothing to do!
pass
elif orientation == 2:
# Mirrored left to right
img = img.transpose(PIL.Image.FLIP_LEFT_RIGHT)
elif orientation == 3:
# Rotated 180 degrees
img = img.rotate(180)
elif orientation == 4:
# Mirrored top to bottom
img = img.rotate(180).transpose(PIL.Image.FLIP_LEFT_RIGHT)
elif orientation == 5:
# Mirrored along top-left diagonal
img = img.rotate(-90, expand=True).transpose(PIL.Image.FLIP_LEFT_RIGHT)
elif orientation == 6:
# Rotated 90 degrees
img = img.rotate(-90, expand=True)
elif orientation == 7:
# Mirrored along top-right diagonal
img = img.rotate(90, expand=True).transpose(PIL.Image.FLIP_LEFT_RIGHT)
elif orientation == 8:
# Rotated 270 degrees
img = img.rotate(90, expand=True)
return img
def load_image_file(file, mode='RGB'):
# Load the image with PIL
img = PIL.Image.open(file)
if hasattr(PIL.ImageOps, 'exif_transpose'):
# Very recent versions of PIL can do exit transpose internally
img = PIL.ImageOps.exif_transpose(img)
else:
# Otherwise, do the exif transpose ourselves
img = exif_transpose(img)
img = img.convert(mode)
return np.array(img)
Issue16 numpy的问题
问题描述
在训练加载数据的时候,我通过tf.data.Dataset。当我使用map函数的时候,尝试将tensor转换成numpy然后报错。具体代码如下:
train_dataset = train_dataset.map(lambda x, y:(
transform_dataset(x, input_shape),
preprocess_true_boxes(y, input_shape, anchors, num_classes)
))
preprocess_true_boxes
def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
assert (true_boxes[..., 4]<num_classes).numpy().all()
num_layers = len(anchors)//3
anchor_mask = config.ANCHOR_MASK
......
原因分析

解决方案
可以参考:https://stackoverflow.com/questions/52357542/attributeerror-tensor-object-has-no-attribute-numpy。切记:尽可能使用tensorflow的函数,避免出现这种错误。
Issue17 训练问题
问题描述
训练yolov4的模型,算法能够收敛,但是在推理部分,结果框不合理想。

原因分析
分析了这些异常的框,发现这些框的比例都是比较恒定的,约1:3左右。因此想到的问题是可能这类框样本不足,其他样本数量非常多,导致出现此错误。因此需要解决样本不均衡的问题。
解决方案
解决样本不均衡的问题,我主要从两个方面下手:
- 增加batchsize。
- 采用label smoothing
配置文件如下:

Issue18 Batchnornalization问题
问题描述
在实现SqueezeNet时候,在Fireblock上只定义一个bn层会报错,具体错误代码:
import tensorflow as tf
from tensorflow.keras import Input, Model, layers
class Mish(layers.Layer):
def __init__(self):
super(Mish, self).__init__()
def __call__(self, inputs):
return tf.multiply(inputs, tf.tanh(tf.nn.softplus(inputs)))
class FireBlock(layers.Layer):
def __init__(self, filter1, filter2, filter3):
super(FireBlock, self).__init__()
self.conv1 = layers.Conv2D(filters=filter1, kernel_size=1, padding='same', use_bias=False)
self.conv2 = layers.Conv2D(filters=filter2, kernel_size=1, padding='same', use_bias=False)
self.conv3 = layers.Conv2D(filters=filter3, kernel_size=3, padding='same', use_bias=False)
self.bn = layers.BatchNormalization()
# self.bn2 = layers.BatchNormalization()
# self.bn3 = layers.BatchNormalization()
def __call__(self, inputs):
squeeze_x = self.conv1(inputs)
squeeze_x = self.bn(squeeze_x)
squeeze_x = Mish()(squeeze_x)
expand_x1 = self.conv2(squeeze_x)
expand_x1 = self.bn(expand_x1)
expand_x1 = Mish()(expand_x1)
expand_x3 = self.conv3(squeeze_x)
expand_x3 = self.bn(expand_x3)
expand_x3 = Mish()(expand_x3)
merge_x = layers.Concatenate()([expand_x1, expand_x3])
return merge_x
class SqueezeNet(Model):
def __init__(self):
super(SqueezeNet, self).__init__()
self.conv1 = layers.Conv2D(filters=96, kernel_size=7, strides=2, padding='same', use_bias=False)
self.bn1 = layers.BatchNormalization()
self.act1 = Mish()
self.pool1 = layers.MaxPool2D(3, strides=2, padding='same')
self.fire_block2 = FireBlock(16, 64, 64)
self.fire_block3 = FireBlock(16, 64, 64)
self.fire_block4 = FireBlock(32, 128, 128)
self.pool4 = layers.MaxPool2D(3, strides=2, padding='same')
self.fire_block5 = FireBlock(32, 128, 128)
self.fire_block6 = FireBlock(48, 192, 192)
self.fire_block7 = FireBlock(48, 192, 192)
self.fire_block8 = FireBlock(64, 256, 256)
self.pool8 = layers.MaxPool2D(3, strides=2, padding='same')
self.fire_block9 = FireBlock(64, 256, 256)
def __call__(self, inputs = None):
if not inputs:
inputs = Input(shape=(224, 224, 3))
x = self.conv1(inputs)
x = self.bn1(x)
x = self.act1(x)
x = self.pool1(x)
x = self.fire_block2(x)
x = self.fire_block3(x)
x = self.fire_block4(x)
x = self.pool4(x)
x = self.fire_block5(x)
x = self.fire_block6(x)
x = self.fire_block7(x)
x = self.fire_block8(x)
x = self.pool8(x)
x = self.fire_block9(x)
squeeze = Model(inputs, x)
return squeeze
squeeze_net = SqueezeNet()
model = squeeze_net()
model.summary()
提示维度不对的问题:

原因分析
可以参考keras官方文档:https://keras.io/zh/layers/writing-your-own-keras-layers/ 或者https://www.cnblogs.com/yaos/p/12128153.html
解决方案
定义多个BN层:
import tensorflow as tf
from tensorflow.keras import Input, Model, layers
class Mish(layers.Layer):
def __init__(self):
super(Mish, self).__init__()
def __call__(self, inputs):
return tf.multiply(inputs, tf.tanh(tf.nn.softplus(inputs)))
class FireBlock(layers.Layer):
def __init__(self, filter1, filter2, filter3):
super(FireBlock, self).__init__()
self.conv1 = layers.Conv2D(filters=filter1, kernel_size=1, padding='same', use_bias=False)
self.conv2 = layers.Conv2D(filters=filter2, kernel_size=1, padding='same', use_bias=False)
self.conv3 = layers.Conv2D(filters=filter3, kernel_size=3, padding='same', use_bias=False)
self.bn1 = layers.BatchNormalization()
self.bn2 = layers.BatchNormalization()
self.bn3 = layers.BatchNormalization()
def __call__(self, inputs):
squeeze_x = self.conv1(inputs)
squeeze_x = self.bn1(squeeze_x)
squeeze_x = Mish()(squeeze_x)
expand_x1 = self.conv2(squeeze_x)
expand_x1 = self.bn2(expand_x1)
expand_x1 = Mish()(expand_x1)
expand_x3 = self.conv3(squeeze_x)
expand_x3 = self.bn3(expand_x3)
expand_x3 = Mish()(expand_x3)
merge_x = layers.Concatenate()([expand_x1, expand_x3])
return merge_x
class SqueezeNet(Model):
def __init__(self):
super(SqueezeNet, self).__init__()
self.conv1 = layers.Conv2D(filters=96, kernel_size=7, strides=2, padding='same', use_bias=False)
self.bn1 = layers.BatchNormalization()
self.act1 = Mish()
self.pool1 = layers.MaxPool2D(3, strides=2, padding='same')
self.fire_block2 = FireBlock(16, 64, 64)
self.fire_block3 = FireBlock(16, 64, 64)
self.fire_block4 = FireBlock(32, 128, 128)
self.pool4 = layers.MaxPool2D(3, strides=2, padding='same')
self.fire_block5 = FireBlock(32, 128, 128)
self.fire_block6 = FireBlock(48, 192, 192)
self.fire_block7 = FireBlock(48, 192, 192)
self.fire_block8 = FireBlock(64, 256, 256)
self.pool8 = layers.MaxPool2D(3, strides=2, padding='same')
self.fire_block9 = FireBlock(64, 256, 256)
def __call__(self, inputs = None):
if not inputs:
inputs = Input(shape=(224, 224, 3))
x = self.conv1(inputs)
x = self.bn1(x)
x = self.act1(x)
x = self.pool1(x)
x = self.fire_block2(x)
x = self.fire_block3(x)
x = self.fire_block4(x)
x = self.pool4(x)
x = self.fire_block5(x)
x = self.fire_block6(x)
x = self.fire_block7(x)
x = self.fire_block8(x)
x = self.pool8(x)
x = self.fire_block9(x)
squeeze = Model(inputs, x)
return squeeze
















 5261
5261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









