







在我们学习机器学习的过程中,一定了解K-Means聚类算法,K-Means虽然简单但是其本身具有一定的局限性:
(1)当聚类的大小、密度、形状不同时,K-means 聚类的结果不理想
(2)数据集包含离群点时,K-means 聚类结果不理想
(3)两个类距离较近时,聚类结果不合理
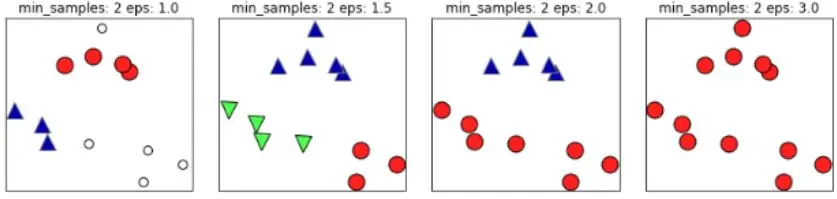
通过下面几幅图可以清晰的看到K-Means的局限性。
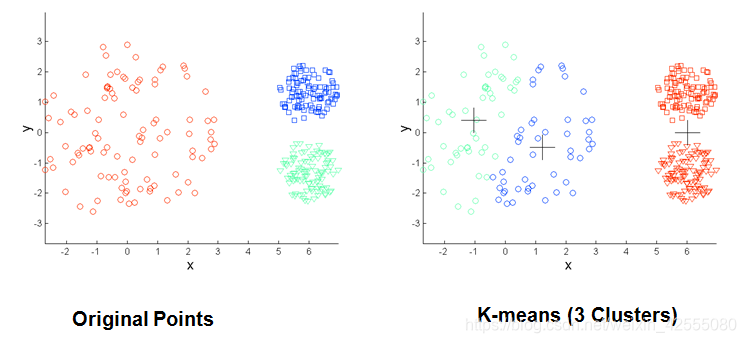
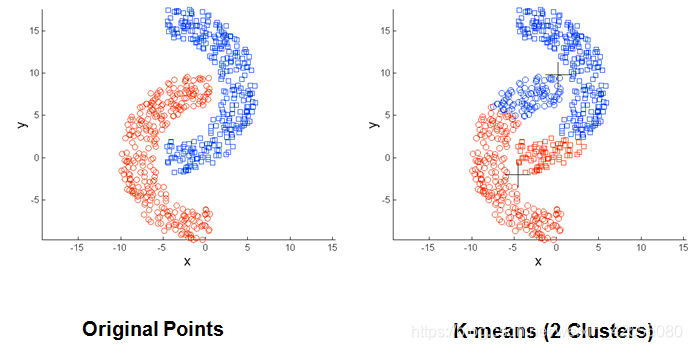
针对上面的问题,提出了DBSACN模型。DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将 簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。 因此,DBSCAN算法也能用于异常点检测。
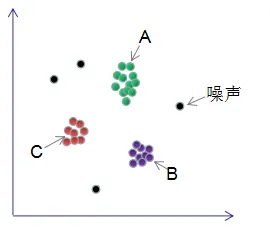
一、基本概念
DBSCAN是一种基于密度的聚类算法,可以根据样本分布的紧密程度决定,同一类别的样本之间是紧密相连的,不同类别样本联系是比较少的。
DBSCAN聚类完成后会产生三种类型的点:
- 核心点:若样本 xi 的 ε ε ε 邻域内至少包含了MinPts个点,则为核心点
- 边界点:若样本 xi 的 ε ε ε 邻域内包含的点数小于MinPts,但在其他核心点的ε邻域内,则为边界点
- 噪声点:既非核心点也非边界点则为噪声
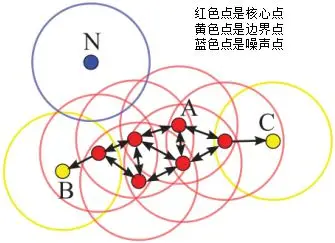
假设MinPts=4,如下图的核心点、非核心点与噪声的分布:
二、算法原理
2.1 基本定义
DBSCAN算法划分数据集D为核心点、边界点和噪声点,并按照一定的连接规则组成簇类。介绍连接规则前,先定义下面这几个概念:
- 密度直达(directly density-reachable):若q处于p的 ε ε ε 邻域内,且p为核心点,则称q由p密度直达;
- 密度可达(density-reachable):若q处于p的 ε ε ε 邻域内,且p,q均为核心点,则称q的邻域点由p密度可达;
- 密度相连(density-connected):若p,q均为非核心点,且p,q处于同一个簇类中,则称q与p密度相连。
下图给出了上述概念的直观显示(MinPts):
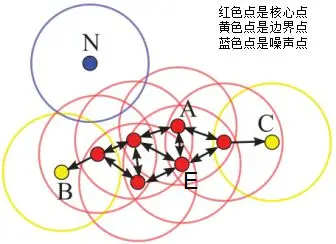
其中核心点E由核心点A密度直达,边界点B由核心点A密度可达,边界点B与边界点C密度相连,N为孤单的噪声点。
2.2 算法原理
DBSCAN是基于密度的聚类算法,原理为:只要任意两个样本点是密度直达或密度可达的关系,那么该两个样本点归为同一簇类。
上图的样本点ABCE为同一簇类。因此,DBSCAN算法从数据集D中随机选择一个核心点作为“种子”,由该种子出发确定相应的聚类簇,当遍历完所有核心点时,算法结束。
DBSCAN算法可以抽象为以下几步:
- 找到每个样本的 ε ε ε 邻域内的样本个数,若个数大于等于MinPts,则该样本为核心点;
- 找到每个核心样本密度直达和密度可达的样本,且该样本亦为核心样本,忽略所有的非核心样本;
- 若非核心样本在核心样本的 ε ε ε 邻域内,则非核心样本为边界样本,反之为噪声。
算法步骤如下:
输入: 包含n个对象的数据库,半径e,最少数目MinPts;
输出:所有生成的簇,达到密度要求。
(1)Repeat
(2)从数据库中抽出一个未处理的点;
(3)IF抽出的点是核心点 THEN 找出所有从该点密度可达的对象,形成一个簇;
(4)ELSE 抽出的点是边缘点(非核心对象),跳出本次循环,寻找下一个点;
(5)UNTIL 所有的点都被处理。
DBSCAN对用户定义的参数很敏感,细微的不同都可能导致差别很大的结果,而参数的选择无规律可循,只能靠经验确定。
三、算法参数估计
由上一节可知,DBSCAN主要包含两个参数:
- ε ε ε :两个样本的最小距离,它的含义为:如果两个样本的距离小于或等于值 ε ε ε ,那么这两个样本互为邻域。
- MinPts:形成簇类所需的最小样本个数,比如MinPts等于5,形成簇类的前提是至少有一个样本的 ε ε ε 邻域大于等于5。
【参数估计】 :
- MinPts参数
如下图,如果 ε ε ε 值取的太小,部分样本误认为是噪声点(白色); ε ε ε 值取的太大,大部分的样本会合并为同一簇类。
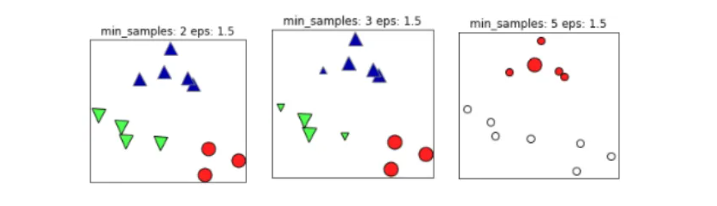
同样的,若MinPts值过小,则所有样本都可能为核心样本;MinPts值过大时,部分样本误认为是噪声点(白色),如下图:
根据经验,minPts的最小值可以从数据集的维数D得到,即
m
i
n
P
t
s
>
=
D
+
1
min Pts>=D+1
minPts>=D+1。若minPts=1,含义为所有的数据集样本都为核心样本,即每个样本都是一个簇类;若minPts≤2,结果和单连接的层次聚类相同;因此 minPts必须大于等于3,因此一般认为
m
i
n
P
t
s
=
2
∗
d
i
m
minPts=2*dim
minPts=2∗dim,若数据集越大,则minPts的值选择的亦越大。
-
ε
ε
ε 参数
ε ε ε 值常常用k-距离曲线(k-distance graph)得到,计算每个样本与所有样本的距离,选择第k个最近邻的距离并从大到小排序,得到k-距离曲线,曲线拐点对应的距离设置为 ε ε ε ,如下图:
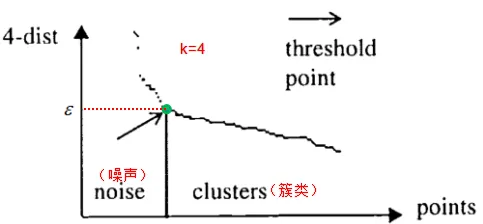
由图可知或者根据k-距离曲线的定义可知:样本点第k个近邻距离值小于
ε
ε
ε 归为簇类,大于
ε
ε
ε 的样本点归为噪声点。根据经验,一般选择
ε
ε
ε 值等于第(minPts-1)的距离,计算样本间的距离前需要对数据进行归一化,使所有特征值处于同一尺度范围,有利于
ε
ε
ε 参数的设置。
如果(k+1)-距离曲线和k-距离曲线没有明显差异,那么minPts设置为k值。例如k=4和k>4的距离曲线没有明显差异,而且k>4的算法计算量大于k=4的计算量,因此设置MinPts=4。
四、算法实战
k-means聚类算法假设簇类所有方向是同等重要的,若遇到一些奇怪的形状(如对角线)时,k-means的聚类效果很差,本节采用DBSCAN算法以及简单的介绍下如何去选择参数 ε ε ε 和MinPts。
随机生成五个簇类的二维数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
# 生成随机簇类数据
X, y =make_blobs(random_state=170,n_samples=600,centers=5)
rng = np.random.RandomState(74)
# 数据拉伸
transformation = rng.normal(size=(2,2))
X = np.dot(X,transformation)
# 绘制延伸图
plt.scatter(X[:,0],X[:,1])
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.show()
散点图为:
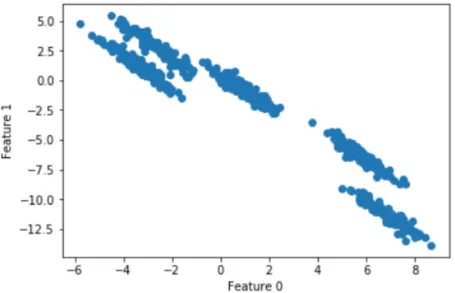
k-means聚类结果:
按照经验MinPts=2*ndims,因此我们设置MinPts=4。
为了方便参数 ε ε ε 的选择,我们首先对数据的特征进行归一化:
#特征归一化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
假设 ε ε ε =0.5:
# dbscan聚类算法
t0=time.time()
dbscan = DBSCAN(eps=0.12,min_samples = 4)
clusters = dbscan.fit_predict(X_scaled)
# 绘制dbscan聚类结果
plt.scatter(X[:,0],X[:,1],c=clusters,cmap="plasma")
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.title("eps=0.5,minPts=4")
plt.show()
t1=time.time()
print(t1-t0)
查看聚类结果:
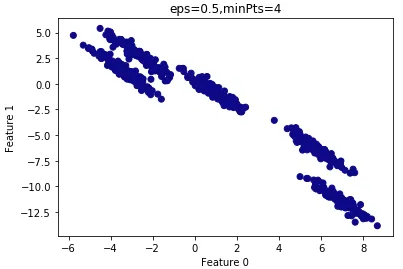
由上图可知,所有的样本都归为一类,因此
ε
ε
ε 设置的过大,需要减小
ε
ε
ε 。
设置
ε
ε
ε =0.2的结果:
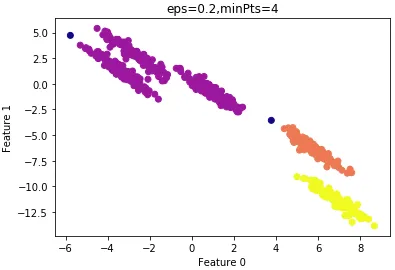
由上图可知,大部分样本还是归为一类,因此 ε ε ε 设置的过大,仍需要减小 ε ε ε 。
设置 ε ε ε =0.12的结果:
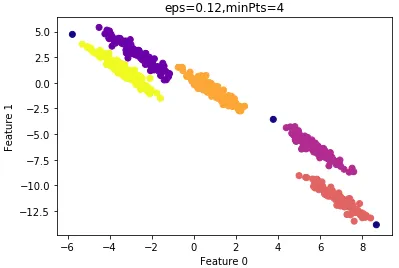
结果令人满意,看看聚类性能度量指数:
# 性能评价指标ARI
from sklearn.metrics.cluster import adjusted_rand_score
# ARI指数
print("ARI=",round(adjusted_rand_score(y,clusters),2))
#>
ARI= 0.99
由上节可知,为了较少算法的计算量,我们尝试减小MinPts的值。
设置MinPts=2的结果:
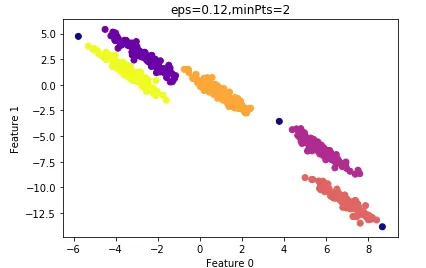
其ARI指数为:0.99
算法的运行时间较minPts=4时要短,因此我们最终选择的参数: ε ε ε =0.12,minPts=4。
这是一个根据经验的参数优化算法,实际项目中,我们首先根据先验经验去设置参数的值,确定参数的大致范围,然后根据性能度量去选择最优参数。
五、算法优缺点
【优点】:
1)DBSCAN不需要指定簇类的数量;
2)DBSCAN可以处理任意形状的簇类;
3)DBSCAN可以检测数据集的噪声,且对数据集中的异常点不敏感;
4)DBSCAN结果对数据集样本的随机抽样顺序不敏感(细心的读者会发现样本的顺序不一样,结果也可能不一样,如非核心点处于两个聚类的边界,若核心点抽样顺序不同,非核心点归于不同的簇类);
【缺点】:
1)DBSCAN最常用的距离度量为欧式距离,对于高维数据集,会带来维度灾难,导致选择合适的参数值很难;
2)若不同簇类的样本集密度相差很大,则DBSCAN的聚类效果很差,因为这类数据集导致选择合适的minPts和 ε ε ε 值非常难,很难适用于所有簇类。















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









