







2024年12月26日,中国AI初创公司杭州深度求索人工智能基础技术研究有限公司发布DeepSeek-V3大模型并开源了其模型代码及技术报告。整个Report有53页,这里对其技术报告中的关键技术进行简要解读。
一、总体介绍
首先给出Report的摘要部分:
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
我们提出了DeepSeek-V3,这是一个强大的混合专家(MoE)语言模型,模型总参数为671B,每个令牌激活37B。为了实现高效的推理和经济高效的训练,DeepSeek-V3采用了多头潜在注意力(MLA)和DeepSeekMoE架构,这些架构在DeepSeek-V2中得到了充分的验证。此外,DeepSeek-V3开创了一种用于负载平衡的辅助无损耗策略 (auxiliary-loss-free strategy for load balancing),并设定了**多令牌预测训练目标(multi-token prediction training objective)**以提高性能。我们对DeepSeek-V3进行了14.8万亿次多样化的预训练高质量的令牌,然后是监督微调和强化学习阶段,以充分利用其功能。综合评估显示,DeepSeek-V3的表现优于其他开源模型,其性能可与领先的闭源模型相媲美。尽管性能卓越,DeepSeek-V3只需要2.788M H800 GPU小时即可进行全面训练。此外,它的训练过程非常稳定。在整个训练过程中,我们没有遇到任何不可挽回的损失高峰或任何倒退。模型检查点位于 https://github.com/deepseek-ai/DeepSeek-V3。
下面给出DeepSeek V3相比于现有主流大模型的效果对比:
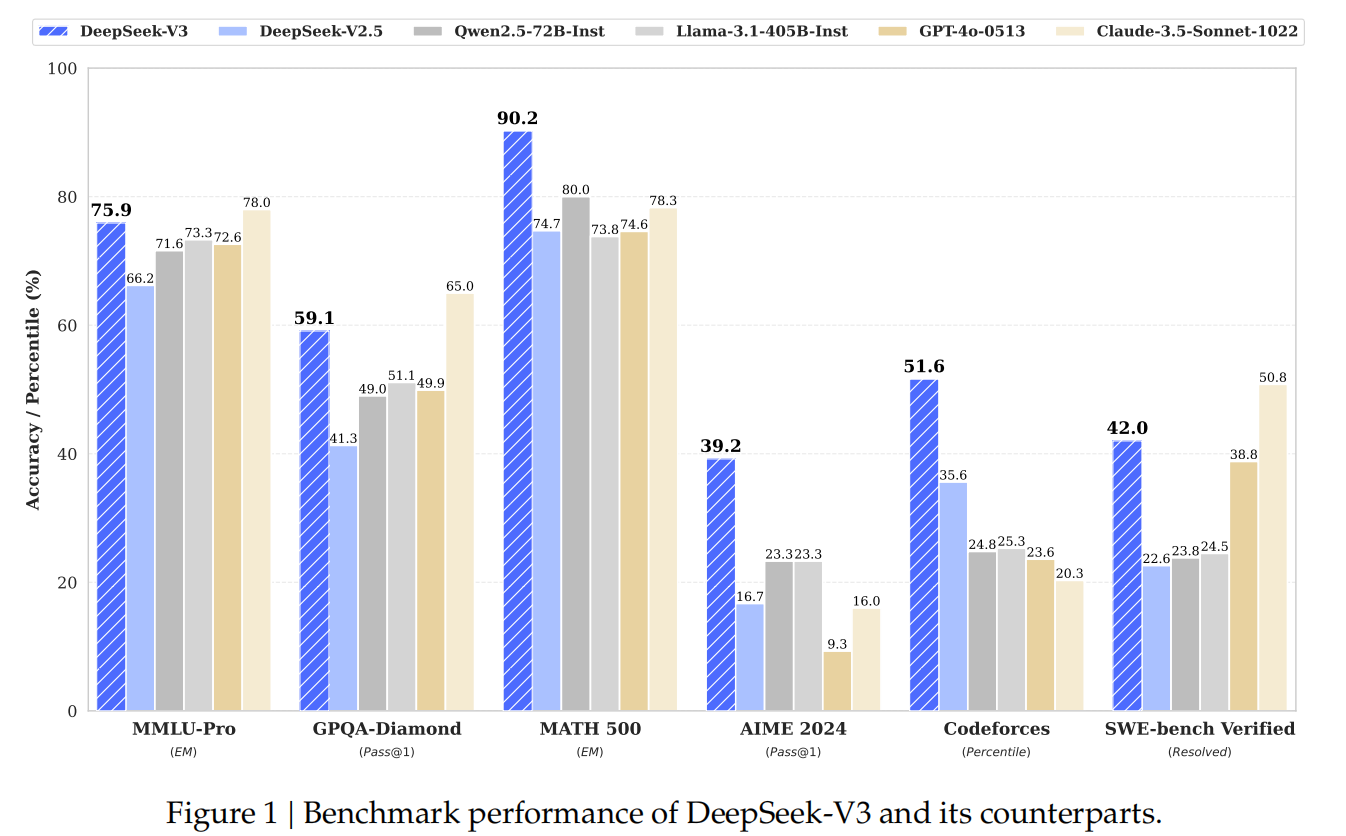
总体而言,DeepSeek-V3 是一个在2048 个 NVIDIA H800 GPU 的集群上进行训练得到的超大型MoE架构的大语言模型。它延续了Deepseek MoE、Deepseek V2等模型的一系列创新,进一步提出了MTP,并优化了训练的效率,取得比较好效果的同时,提高了训练的效率,节约了成本。
DeepSeek V3的核心贡献点包括以下几方面:
- Architecture(架构): Innovative Load Balancing Strategy and Training Objective
- Pre-Training(预训练): Towards Ultimate Training Efficiency
- Post-Training(后训练): Knowledge Distillation from DeepSeek-R1
二、Architecture(整体架构)
DeepSeek V2中就使用了 混合专家 (Mixture-of-Experts, MoE) 及 多头隐注意力 (Multi-head Latent Attention, MLA) 的架构,这种架构的有效性也在DeepSeek V2中得到了充分的验证。因此,作者在DeepSeek V3中继续沿用了基于 混合专家 (Mixture-of-Experts, MoE) 及 多头隐注意力 (Multi-head Latent Attention, MLA) 的基础架构,并增加了 辅助的无损耗负载平衡 (auxiliary-loss-free load balancing strategy) 策略以减轻因确保负载平衡而导致的性能下降。
DeepSeek V3的整体架构图如下所示:
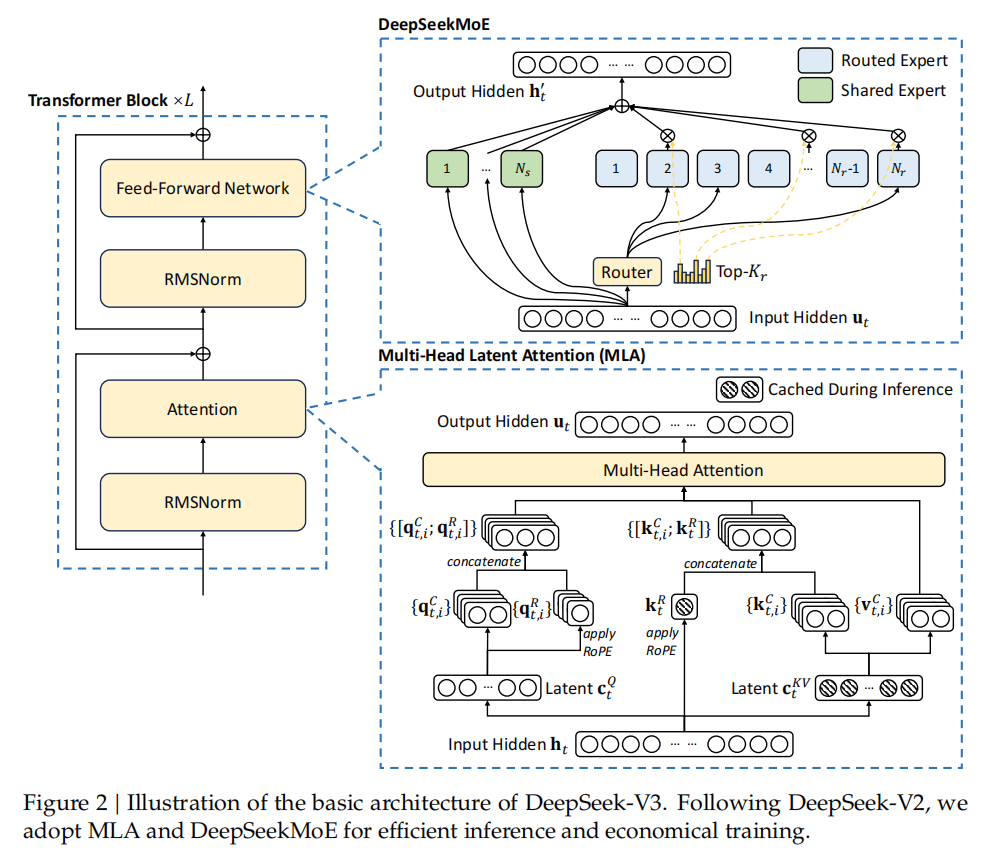
2.1 基本架构
2.1.1 Mixture-of-Experts, MOE(混合专家)
关于Mixture-of-Experts, MOE(混合专家)的更深入理解,可以参考博客:图解大模型训练系列之:DeepSpeed-Megatron MoE并行训练(原理篇)
DeepSeekMOE架构的细节可参考他们前期的论文:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models。
- 论文地址:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- Github地址:https://github.com/deepseek-ai/DeepSeek-MoE
(1)传统的MoE
首先简单介绍下传统的MoE的做法:在Transformer中按照指定的间隔,用MoE层替换FFN层。一个MoE层由多个专家组成,每个专家的结构与标准的FFN层相同。然后,每个token将被分配到一个或两个专家。
这种架构存在两个潜在问题:
- 知识混合:现有的MoE实践通常使用有限数量的专家(例如,8或16),因此分配给特定专家的token可能会涵盖多种知识。
- 知识冗余:分配给不同专家的token可能需要共同知识。
(2)DeepSeekMoE
DeepSeekMoE是一种创新的MoE架构,旨在实现最终的专家专业化。该架构涉及两个主要策略:
- 细粒度专家分割:在保持参数数量不变的情况下,通过分割Transformer中的前馈网络(FFN)中间隐藏维度将专家划分为更细的粒度。相应地,在保持恒定计算成本的同时,我们也激活更多细粒度的专家,以实现更灵活和适应性更强的激活专家组合。细粒度专家分割允许将多样化的知识更精细地分解,并更精确地学习到不同的专家中,每个专家将保持更高水平的专业化。此外,增加激活专家组合的灵活性也有助于更准确和有针对性的知识获取。
- 共享专家隔离:将某些专家隔离为始终激活的共享专家,旨在捕捉和整合跨不同上下文的共同知识。通过将共同知识压缩到这些共享专家中,可以减少其他路由专家之间的冗余。这可以提高参数效率,并确保每个路由专家通过专注于独特方面来保持专业化。这些架构创新为训练参数高效的MoE语言模型提供了机会,其中每个专家都高度专业化。
DeepSeekMoE的整体架构如下:
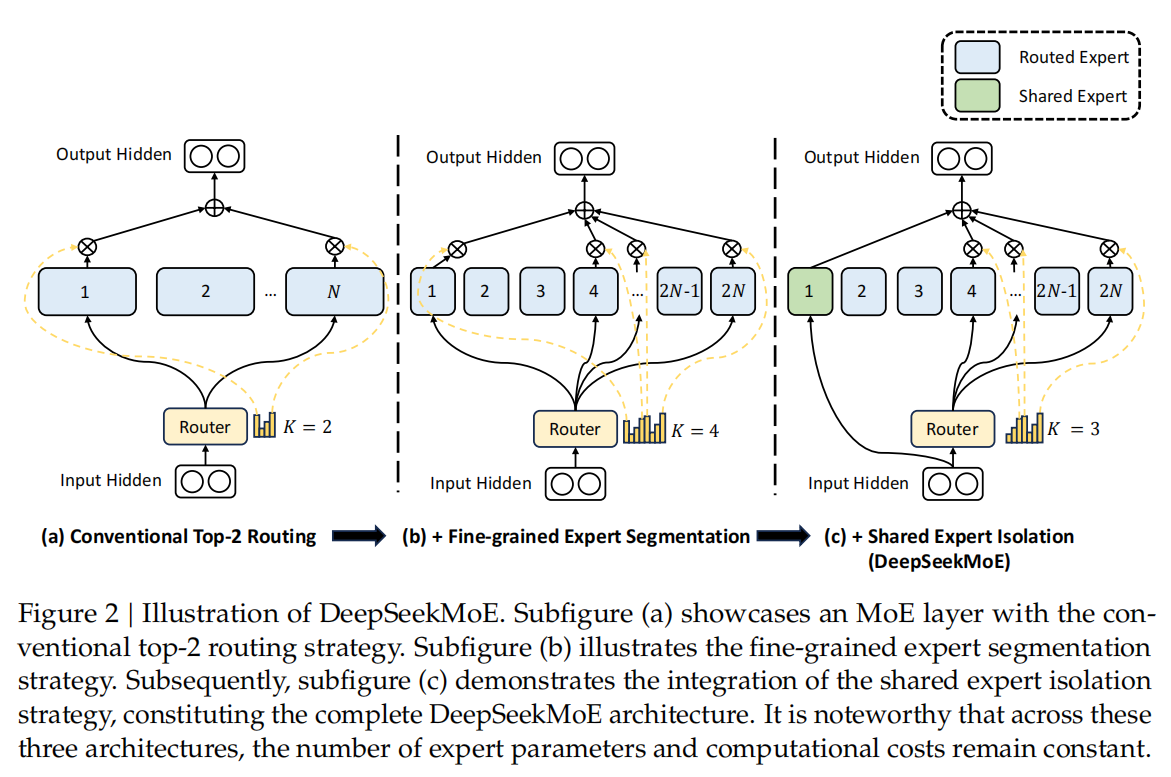
子图 (a) 展示了采用传统 top-2 路由策略的 MoE 层。子图(b)说明了细粒度的专家分割策略。随后,子图(c)演示了共享专家隔离策略的集成,构成了完整的DeepSeekMoE架构。
(3)DeepSeekV3中的DeepSeekMoE
DeepSeekV3中的DeepSeekMoE的主要的公式如下:
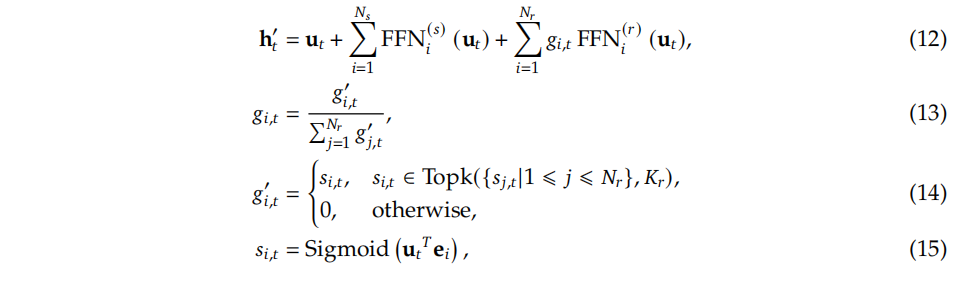
其中 :
- N s N_s Ns代表共享专家的数量, N r N_r Nr代表路由专家的数量;
- F F N i ( s ) ( . ) {FFN_{i}}^{(s)}(.) FFNi(s)(.) 代表第 i i i 个共享专家, F F N r ( s ) ( . ) {FFN_{r}}^{(s)}(.) FFNr(s)(.) 代表第 i i i 个路由专家;
- K r K_r Kr代表激活的路由专家的数量;
- g i , t g_{i, t} gi,t代表第i个专家的门控值(gating value);
- s i , t s_{i, t} si,t代表token到专家的映射关系(token-to-expert affinity);
- e i e_{i} ei 是第 i i i 位路由专家的质心向量(centroid vector);
- T o p K ( ) TopK() TopK()表示在为 第 t t t 个token和所有路由专家计算的亲和度得分中,包含最高 K K K个得分的集合。
DeepSeekV3中的DeepSeekMoE相比于DeepSeekV2的不同点: 使用sigmoid函数计算关联度得分,并且基于所有选择的关联度得分进行归一化,来得到最终的门控值。
2.1.1.4 Auxiliary-Loss-Free Load Balancing(辅助的无损耗负载平衡)
(1)Auxiliary-Loss-Free Load Balancing
对于MoE模型,不平衡的专家负载将导致路由崩溃等问题,并降低专家并行场景中的计算效率。为了在负载平衡和模型性能之间实现更好的权衡,DeepSeek提出了一种 辅助的无损耗负载平衡策略,以确保负载平衡。
具体做法: 为每个专家引入偏置项(bias) b i b_i bi,并且将其与对应的亲合度得分(affinity scores)相加,以计算 Top-K 个路由。
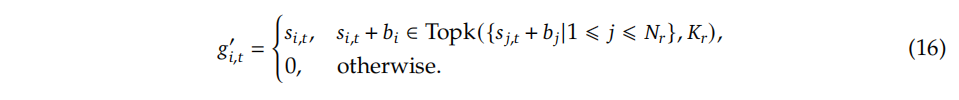
在每一步结束时,如果其对应的专家overloaded,则将bias减小,即
b
i
a
s
−
r
bias-r
bias−r;如果其对应的专家underloaded,则将bias增大,即
b
i
a
s
+
r
bias+r
bias+r,其中
r
r
r 是称为偏差bias更新速度的超参数。
(2)Complementary Sequence-Wise Auxiliary Loss
尽管DeepSeek-V3主要依赖于辅助无损耗策略来实现负载平衡,但为了防止任何单个序列内的极端不平衡,我们还采用了互补的顺序平衡损耗:
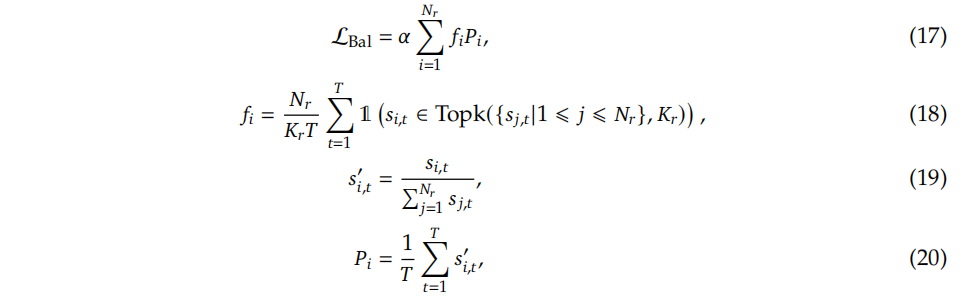
2.1.2 Multi-Head Latent Attention(多头潜在注意力)
关于MHA, MLA的更深入理解,可以参考博客:缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
多头潜在注意力(Multi-Head Latent Attention, MLA) 是 多头注意力(Multi-Head Attention, MHA) 的扩展,旨在通过引入潜在变量来捕捉更复杂的依赖关系。
在DeepSeek V3中,多头潜在注意力(Multi-Head Latent Attention, MLA) 的关键作用是:对注意力键 (key) 和 值 (value) 进行低秩联合压缩,以减少推理过程中的键值(KV)cache,从而降低了内存占用并提高了计算效率。
(1)多头注意力(Multi-Head Attention, MHA)
在传统的Transformer架构中,多头注意力(Multi-Head Attention, MHA)机制中的每个注意力头会计算一个加权的输入表示,然后再对多个头的输出进行拼接或加权合并,从而获得更丰富的特征表示。每个头在计算注意力时会关注输入中的不同部分,能够捕捉多种信息。
- 多个头:每个头都对应一个独立的线性变换,学习不同的特征表示。
- 并行计算:多个头的计算可以并行进行,提高效率。
- 合并输出:多个头的输出会在一起进行合并,通常是拼接后再通过线性变换进行处理。
然而,随着序列长度的增长,KV缓存的大小也会线性增加,这给模型带来了显著的内存负担。
(2)多头潜在注意力(Multi-Head Latent Attention, MLA)
为了解决上述问题,MLA引入了以下核心创新:
-
低秩联合压缩:MLA通过对多个注意力头的键和值进行联合压缩,将它们映射到一个共享的潜在空间。具体来说,对于每个注意力头的键和值,分别应用一个下投影矩阵将其压缩到低维潜在空间。这样,原本需要存储的大量KV对现在只需要存储较少数量的潜在向量,极大地减少了内存需求。
-
动态重构:在推理过程中,MLA能够从潜在空间中恢复原始的键和值,仅在需要时才进行重构,避免了全量存储的内存开销。这种方法不仅节省了内存,还提高了处理更长序列或更大批次的能力。
-
查询矩阵的低秩压缩:除了键和值之外,MLA还对查询矩阵进行了低秩压缩,以减少训练时的激活内存,这有助于降低训练成本。
-
旋转位置编码(RoPE):为了保留位置信息,MLA对键和查询矩阵应用了旋转位置编码,这使得模型能够在保持位置敏感性的同时实现高效的注意力计算。
这些技术共同作用,使得MLA可以在保持甚至提升模型性能的同时,显著降低内存使用和计算复杂度。
多头潜在注意力(MHA)的工作原理:
多头潜在注意力结合了多头注意力Multi-Head Attention, MHA)和潜在空间(Latent Space)两者的特点,通过将多个潜在空间的表示进行注意力计算,实现对不同信息维度的综合考虑。简单来说,MHA尝试在多个潜在空间中对输入数据进行自注意力计算,从而能够同时关注不同层次的特征,并捕捉多种潜在关系。工作原理为:
- 潜在空间表示:首先,将输入数据映射到不同的潜在空间中,这些潜在空间可能代表不同的抽象特征。
- 多头计算:然后,在每个潜在空间中应用多个独立的注意力头,每个头从不同的角度计算输入序列中各个元素之间的关系。
- 合并输出:最后,将多个头的输出结合起来,可能是拼接或加权求和,再通过线性变换进行处理。
2.2 Multi-Token Prediction(多token预测)
(1)原始 Multi-Token Prediction
传统的LLM一般采用Next Token Prediction ,即根据给定的序列预测下一个token;而MTP则是让模型在训练时一次性预测接下来的多个token。这种做法一方面提高了预测效率,另一方面也可以让模型具有更好的上下文理解能力,关注到更多的token。
Multi-Token Prediction预测的思想主要来源于论文:Better & faster large
language models via multi-token prediction
(2)DeepSeek V3中的 Multi-Token Prediction
DeepSeek V3中使用的MTP与Gloeckle等人提出的MTP略有不同: DeepSeek V3中使用独立的输出头并行预测额外令牌不同,顺序预测额外token,并在每个预测深度保持完整的因果链。
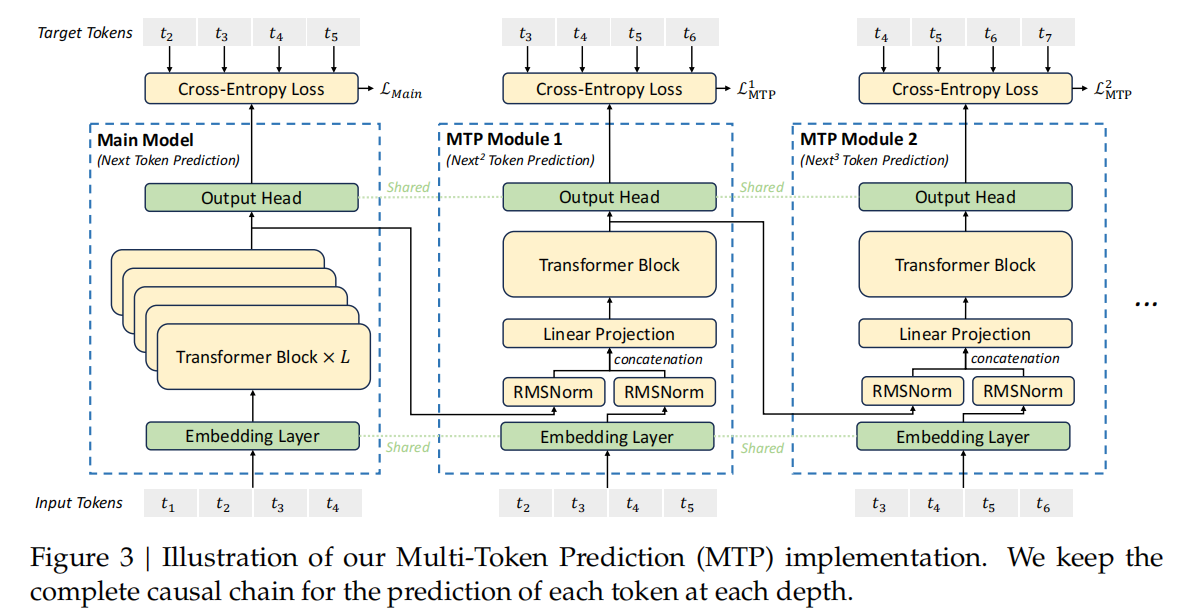
- MTP Modules(MTP模块):Deepseek v3的MTP结构利用 D D D个连续的模块预测 D D D个token。如上图所示,第 k k k个MTP模块由一个共享的embedding层 E m b ( . ) Emb(.) Emb(.),一个共享的输出head层 O u t H e a d ( . ) OutHead(.) OutHead(.),一个transformer块 T R M k ( . ) TRM_k(.) TRMk(.) 和一个投影矩阵 M k M_k Mk 组成。
- 对于第
k
k
k 个MTP层的第
i
i
i 个输入token
t
i
t_i
ti ,执行以下操作:将第
i
i
i 个token 在第
k
−
1
k-1
k−1 层的 输出
h
i
k
−
1
{h_{i}}^{k-1}
hik−1 和 第
(
i
+
k
)
(i+k)
(i+k) 个token 的embedding值
E
m
b
(
t
i
+
k
)
Emb(t_{i+k})
Emb(ti+k) 各自标准化后再进行拼接,并用投影矩阵
M
k
M_k
Mk进行线性投影。
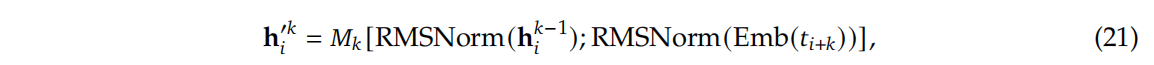
注意:对于所有的MTP模块,embeding layer在整个模型中共享。
-
公式(21)的输出结果 h i ′ k {h_{i}}^{'k} hi′k 后续作为第 k k k 层 Transformer block 的输入,用来计算当前层的输出 h i k {h_{i}}^{k} hik,如公式(22)所示:
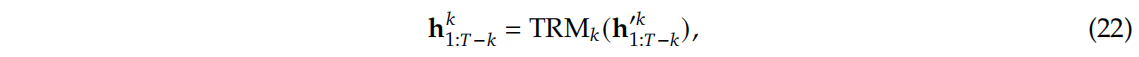
其中, T T T代表输入序列的长度, i : j i:j i:j 代表切片操作。 -
基于公式(22)得到的 h i k {h_{i}}^{k} hik输入到共享输出头OutHead中,输出头将会计算第 k k k 个额外预测token的概率分布,如公式(23)所示:
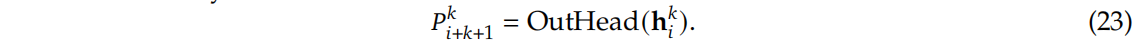
输出头OutHead(·)将表示线性映射到logits,随后应用Softmax(·)函数来计算第𝑘个附加令牌的预测概率。
- MTP Training Objective(MTP训练目标):训练时使用的MTP交叉熵损失。
-
首先基于交叉熵损失计算每个预测层的损失 L k M T P {L^{k}}_{MTP} LkMTP。对于第 k k k个MTP层,计算方式如下:
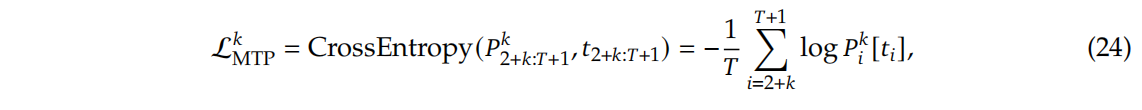
-
再在所有的MTP层上计算平均损失,这里使用了一个权重系数。
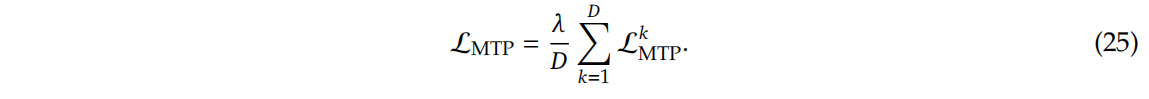
- MTP in Inference(推理):MTP策略主要是为了提高主模型的性能,因此在推理过程中,我们可以直接丢弃MTP模块。
三、Infrastructures(基础设施)
3.1 计算集群
DeepSeek-V3在配备2048个NVIDIA H800 GPU的集群上进行训练。H800集群中的每个节点都包含8个GPU,通过节点内的NVLink和NVSwitch连接。
3.2 训练框架
DeepSeek-V3的训练使用HAI-LLM框架,由DeepSeek的工程师从头开始精心打造的高效轻量级培训框架。
- 16路流水线并行(PP)
- 64路专家并行(EP)
- ZeRO-1数据并行(DP)
3.2.1 DualPipe算法
为了提升DeepSeek-V3的训练效率,作者们设计了 DualPipe 算法 来实现高效的流水线并行。
DualPipe 算法的核心思想:是在一对单独的正向和反向块内重叠计算和通信,有效减少了流水线中的起泡。如下图所示:
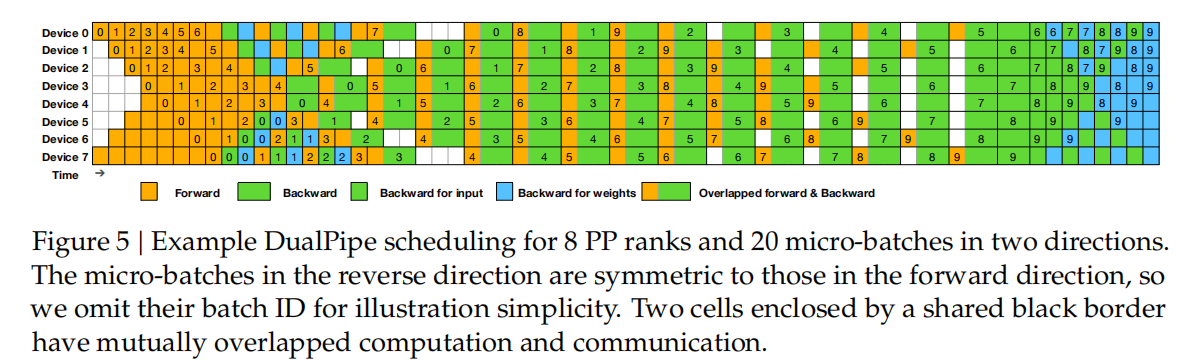
DualPipe 算法采用双向流水线调度,同时从流水线两端馈送微批,并且可以完全重叠大部分通信。这种重叠也确保了随着模型的进一步扩展,只要我们保持恒定的计算与通信比率,我们仍然可以在节点之间使用细粒度的专家,同时实现接近零的全对全通信开销。
3.3 FP8 Training(FP8训练)
根据以往的研究工作表明,低精度的训练往往受到激活、权重和梯度中异常值的限制。在此之前,几乎没有基于低精度训练大语言模型的成功案例。
DeepSeek-V3 模型使用了 FP8 训练,为了增强训练稳定性以及维持训练效果不至于下降太多,DeepSeek引入了细粒度的量化策略:
- tile-wise grouping:包含 1 × 𝑁𝑐 个元素
- block-wise grouping: 包含 𝑁𝑐 × 𝑁𝑐 个元素
3.3.1 Mixed Precision Framework(混合精度框架)
作者提出了支持FP8训练的混合精度框架,在这个框架中,大多数计算密集型操作都是在FP8中进行的,而一些关键操作则保持在其原始数据格式中,以平衡训练效率和数值稳定性。框架示意图如下所示:
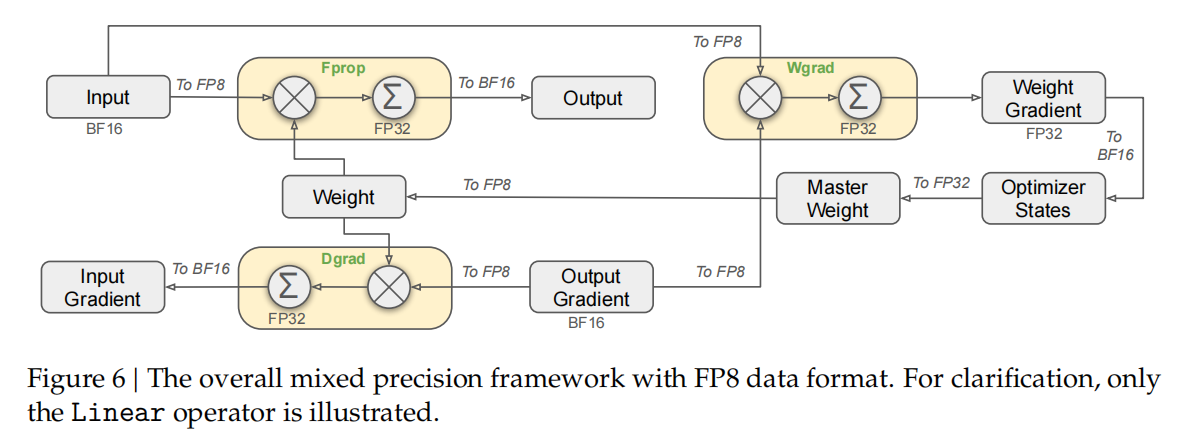
-
FP8 精度:为了加速模型训练,主要的 核心计算内核(如General Matrix Multiplication,GEMM操作) 在 FP8 精度下实现,这些操作接受 FP8 张量作为输入,并生成 BF16 或 FP32 格式的输出。所有与线性操作相关的三个 GEMM(前向传播、激活反向传播和权重反向传播)都在 FP8 中执行,这种设计理论上将计算速度提高了一倍。此外,FP8 权重反向传播 GEMM 允许激活值以 FP8 格式存储,以便在反向传播中使用,从而显著减少了内存消耗。
-
原始精度(如BF16或FP32):训练框架在 Embedding模块、输出头、MoE门控模块、归一化算子和注意力算子等组件中保持了原始精度(如BF16或FP32)。这些高精度的保留确保了DeepSeek-V3的稳定训练动态。为了进一步保证数值稳定性,作者将模型的主权重、权重梯度和优化器状态均存储在更高的精度中。
3.4 Inference and Deployment(推理及部署)
[待后续补充…]
四、Pre-Training(预训练)
4.1 Data Construction(数据集构建)
相比于DeepSeek V2,V3版本的数据提升了数学及编程数据的比例,此外将多语言覆盖范围扩大到英语和中文之外。
V3版本实现了数据完整性的文档打包方法。
- Fill-in-Middle (FIM) 策略: 借鉴DeepSeekCoder-V2的经验,引入FIM策略,使模型能够基于上下文线索准确预测中间文本,而不影响下一个token的预测能力。
- 语料库大小:DeepSeek-V3的训练语料库由 14.8T(万亿) 个高质量和多样化的token组成
- 分词器:Byte-level BPE,词汇表的大小为128K
4.2 Hyper-Parameters(超参数)
略
4.3. Long Context Extension(长上下文扩展)
4K 到 32K 到 128K
五、Post-Training(后训练)
[待更新…]

















 3256
3256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









