







文章目录
1. 前言
近年来,混合专家模型(Mixture-of-Experts, MoE) 因其在扩展大模型参数量时的高效性备受关注。MoE 通过动态路由机制将输入分配给不同的专家网络,从而在保持计算成本可控的前提下提升模型性能。然而,MoE 训练中一个关键挑战是负载均衡——某些专家可能被过度使用,而其他专家则被冷落。这不仅会导致计算资源的浪费(如部分设备闲置),还可能引发路由崩溃(Routing Collapse),即模型仅依赖少数专家,无法充分利用所有专家能力。
传统解决方案通过引入辅助损失(Auxiliary Loss) 强制均衡专家负载,但这种方法存在明显缺陷:辅助损失会向模型注入干扰梯度,与主任务(如语言建模)的优化目标冲突,导致模型性能下降。为此,本文提出了一种全新的无辅助损失负载均衡策略(Loss-Free Balancing),通过动态调整路由得分偏置(Bias)实现负载均衡,同时避免引入额外梯度干扰。实验表明,该方法在1B和3B参数规模的MoE模型上均取得了更优的负载均衡效果和模型性能。
原文:https://arxiv.org/html/2408.15664v1
2. MoE架构与负载均衡的挑战
2.1 MoE的基本原理
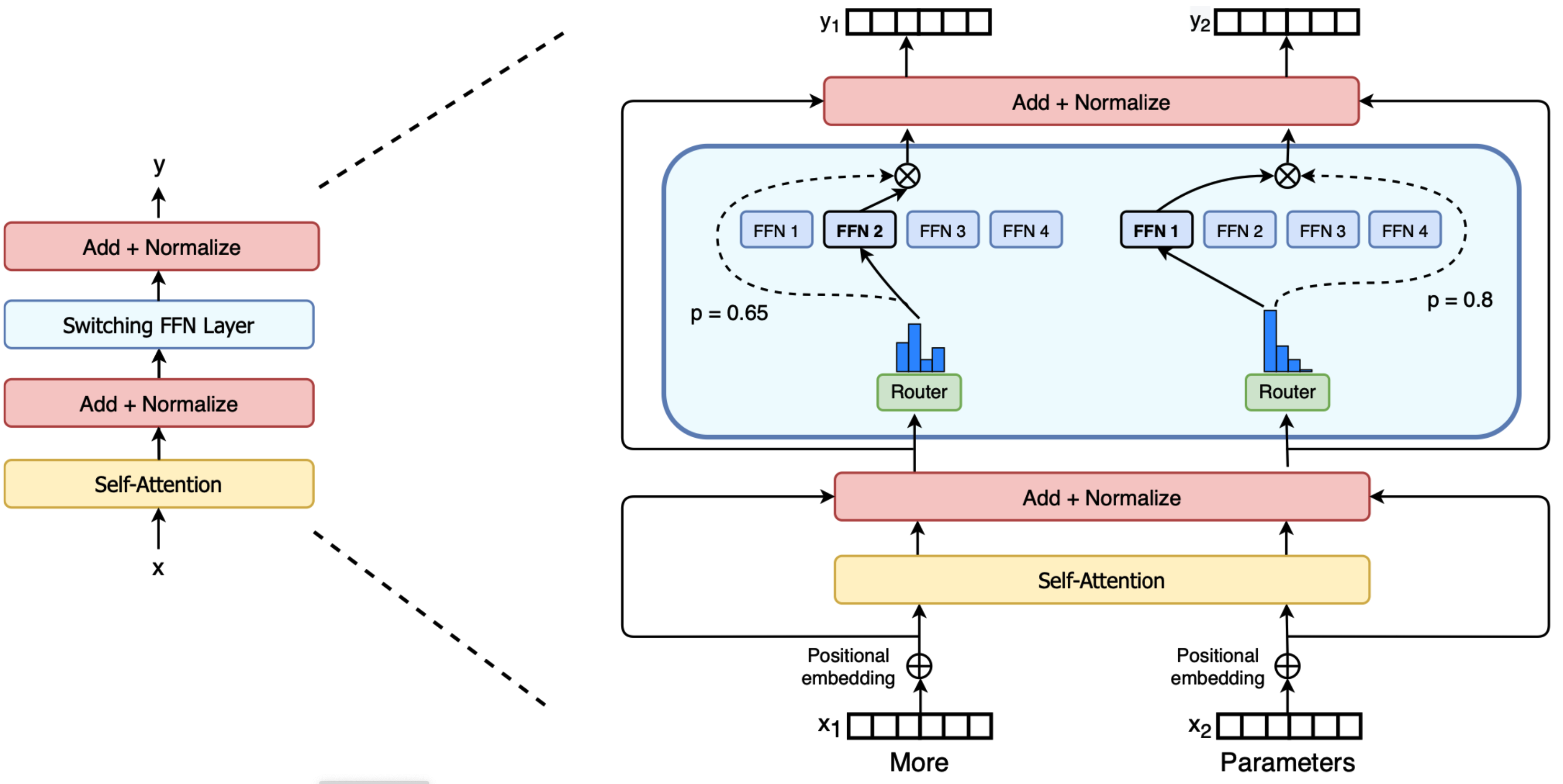
在 Transformer 架构中,MoE 层通常替换标准的 MLP 层。每个 MoE 层包含多个专家网络(如64个 FFN),输入 Token 通过 Top-K 路由机制选择 K 个专家(如K=2)。具体计算流程如下:
- 路由得分计算:输入 Token 的隐状态通过门控函数(如 Sigmoid 或 Softmax )生成各专家的路由得分 s i , t s_{i,t} si,t。
- Top-K 选择:选取得分最高的 K 个专家,将其输出加权求和得到最终结果。
2.2 传统方法的局限性
传统方法通过辅助损失控制负载均衡。例如,定义损失项:
L Balance = α ∑ i = 1 N f i P i \mathcal{L}_{\text{Balance}} = \alpha \sum_{i=1}^N f_i P_i LBalance=αi=1∑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 39
39

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











