







文章目录
为什么需要KV Cache?
在自回归模型中(Autoregressive Models),模型会逐个生成文本的每个token,这个过程可能比较慢,因为模型一次只能生成一个token,而且每次新的预测都依赖于之前的上下文。这意味着,要预测第1000个token,你需要用到前999个token的信息,这通常涉及到对这些token的表示进行一系列矩阵乘法运算。而要预测第1001个token,你不仅需要前999个token的信息,还要加上第1000个token的信息。
KV Cache是在推理阶段 减少重复计算,优化推理效率的方法。在计算Attention的时候,KV Cache把所有的K和V缓存下来,然后生成next token时就可以复用这些KV。
一、Multi-Head Attention (MHA)
在进入KV Cache的正题前,我们需要对Multi-Head Attention (MHA)即标准的多头注意力机制有所了解。这里,我们首先回顾最标准的 Transformer 中的 Self-Attention 的计算及MHA部分的介绍:Transformer 模型详解
二、KV Cache
2.1 产生原因
参考博客: 用数学推导的方式理解KV Cache
对于Self-Attention 的计算有了一定了解后,下面我们一步一步用公式推导来说明KV Cache到底是如何产生的。

这里Q和K转置的矩阵乘实际上是在做向量点乘,把QKV都写成分块形式会比较清晰:

Q和K转置的矩阵乘可以写成如下形式:

注意这里小写的 k k k 和 q q q 都是长度为 d k d_k dk 的向量. 这里不需要赋予 Q Q Q 和 K K K 任何含义,把它们当成 T T T 个长度为 d k d_k dk 的向量即可。可以看出, Q K T QK^T QKT与 q i . k j q_i.k_j qi.kj 的点乘运算等价。

在序列的第t个位置,attention运算结果为:

可以看到,如果没有KV Cache的话,每次都得重新计算出所有的 k j ∗ v j k_j*v_j kj∗vj ,这就存在大量的重复计算。因此我们需要缓存所有的KV,这样每次新的token进来,只需要算最后一个 k t , j ∗ v t , j k_{t,j}*v_{t, j} kt,j∗vt,j ,而不需要算之前的KV,避免大量的重复计算,增加推理效率。
2.2 因果掩码(Causal Mask)
LLM的推理过程是自回归的,输入前 t个token,输出第 t+1个token. 然后输出的token接到输入序列最后,输入t+1个token,输出第t+2个token,如此反复。
在进行自回归推理的过程中,模型无法得到未来token的信息,也就无法知道整个序列所有位置的KV.。因此需要引入因果掩码(Causal Mask),把未来的信息掩盖掉。
具体来说,所谓的“未来”信息指的是所有的 q t ∗ k j ( j > t ) q_t * k_j (j>t) qt∗kj(j>t) 。

加入因果掩码后,序列第t个位置的attention结果正如我们所设想的变为:

2.3 推理流程
LLM的推理流程分为两部分,分别是prefill(预填充)和decode(解码)。
(1)prefill(预填充)
prefill过程是LLM解析整个prompt,并生成第一个token的过程。假设prompt的长度为T个token,对应T个query。接着进行attention运算:
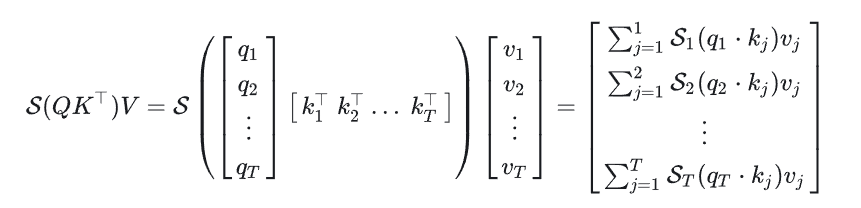
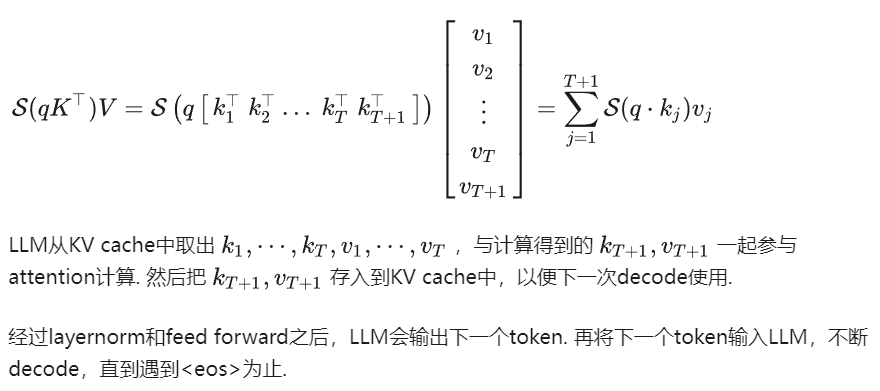
得到的attention结果经过layernorm和feed forward层,再经过一系列处理输出第一个token.
在prefill过程中,LLM会把计算得到的 k 1 , . . . , k t ; v 1 , . . . , v t {k_1, ...,k_t; v_1,...,v_t} k1,...,kt;v1,...,vt 存入KV cache中。
(2)decode
decode过程是LLM根据上一个token输出下一个token的过程。prefill结束后,LLM输出了一个token. 将这个token作为LLM的输入,对应1个query。进行attention运算时,Q退化为向量,得到的attention结果也是向量:
为什么没有Q Cache?
只要理解了decode阶段的计算过程,这个问题很好解释。
- 在推理解码阶段,输出token是一个一个生成的,transformer只需要计算出 O i O_i Oi 。
- Attention机制中的第 i i i 个输出 O i O_i Oi 只和第 i i i 个query有关,和其他query无关,所以query没有必要缓存。
- Attention的输出 O i O_i Oi 的计算和完整的K和V有关,而K、V的历史值只和历史的 O O O 有关,和当前的 O O O 无关。那么就可以通过缓存历史的K、V,避免重复计算。
三、缓解KV Cache
首先给出变量的含义:
- d d d 代表输入维度(input dim)
- n h n_h nh 代表头数(head数)
- d h d_h dh 代表每个头的维度
- h t h_t ht 代表输入的第 t 个向量
- l l l 代表 transformer 的层数
对于标准的MHA而言,对于每一个token,KV Cache占用的缓存的大小为 2 n h d h l 2n_hd_hl 2nhdhl。
由于层数 l l l 是固定的,所以KV Cache的缓解主要就在于如何减小 n h d h n_hd_h nhdh。因此,Grouped-Query Attention (GQA)、Multi-Query Attention (MQA) 、MLA (Multi-head Latent Attention) 等技术被提出,下面我们看看这几个工作是如何减少缓存占用的。
3.1 Multi-Query Attention (MQA) 、Grouped-Query Attention (GQA)
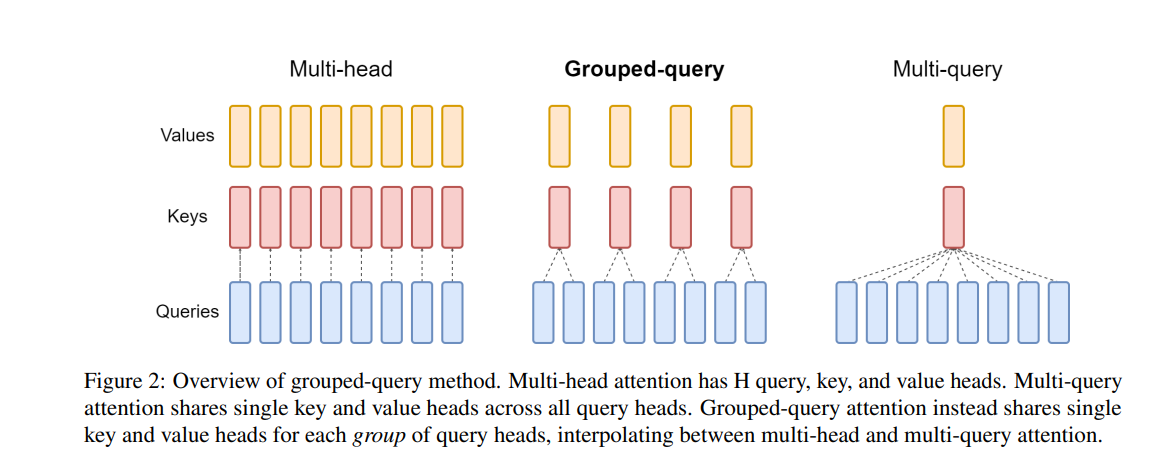
-
Multi-Query Attention(MQA):所有的查询头(Query Heads)共享相同的 Key 和 Value。即削减了 FLOPs,也降低了 Cache,并且压缩了频繁矩阵拼接的 I/O 耗时。
-
Grouped-Query Attention(GQA) :是 Multi-Query Attention(MQA) 的改进版,它通过在 多个查询头(Query Heads)之间共享 Key 和 Value,在 Multi-Head Attention(MHA) 和 MQA 之间找到了一种折中方案。GQA 旨在在 推理速度 和 模型质量 之间取得更好的平衡,减少 MQA 带来的模型质量下降问题,同时仍然保留比 MHA 更快的推理速度。DeepSeekV1 67B、LLaMa2 70B和LLaMa3全系列都用了GQA。
我们再来计算下对于MQA和GQA而言,每个token需要占用的缓存量:
- MQA:缓存大小为 2 d h l 2d_hl 2dhl ,相比于MHA的 2 n h d h l 2n_hd_hl 2nhdhl 而言大大减少,但是性能也会差一些。
- GQA: 缓存大小为 2 n g d h l 2n_gd_hl 2ngdhl,其中 n g n_g ng 代表head的分组数。
3.2 MLA (Multi-head Latent Attention)
MLA的提出也是为了解决在推理时KV Cache占据空间过大的问题,首先给出原论文中对于MLA的示意图:
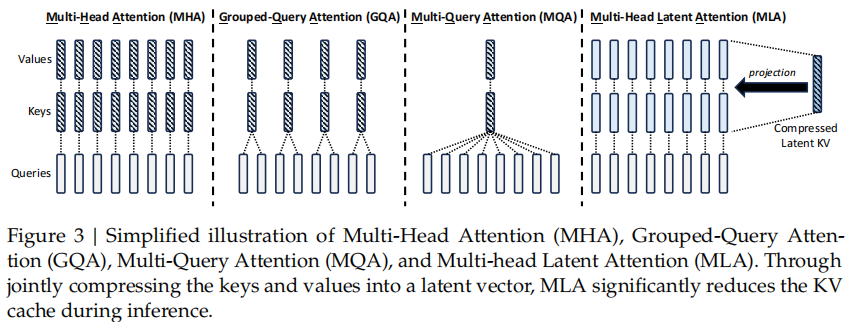
MLA的完整公式如下:

这里关于MLA的具体技术细节不再详细介绍了,可以参考博客:【大模型】DeepSeek核心技术之MLA (Multi-head Latent Attention)

















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









