







1. 下载数据
其官网: Language-Independent Named Entity Recognition (II)
链接:https://pan.baidu.com/s/1AgpB3_3joR2uxUqR2RfdTg
提取码:ao2g
2. 数据介绍
2.1 标注方式
【NLP】序列标注BIO介绍(也叫IOB2)_mjiansun的专栏-CSDN博客
2.2 类别个数
总共四类:persons, locations, organizations ,miscellaneous entities
对应的简写:PER LOC ORG MISC
2.3 数据集样例

数据集第一例是单词;
第二列是词性;
第三列是语法块;
第四列是实体标签。
在NER任务中,只关心第一列和第四列。
3. 标注
3.1 标注工具doccano
工具的安装请参考https://github.com/doccano/doccano
3.2 doccano创建project
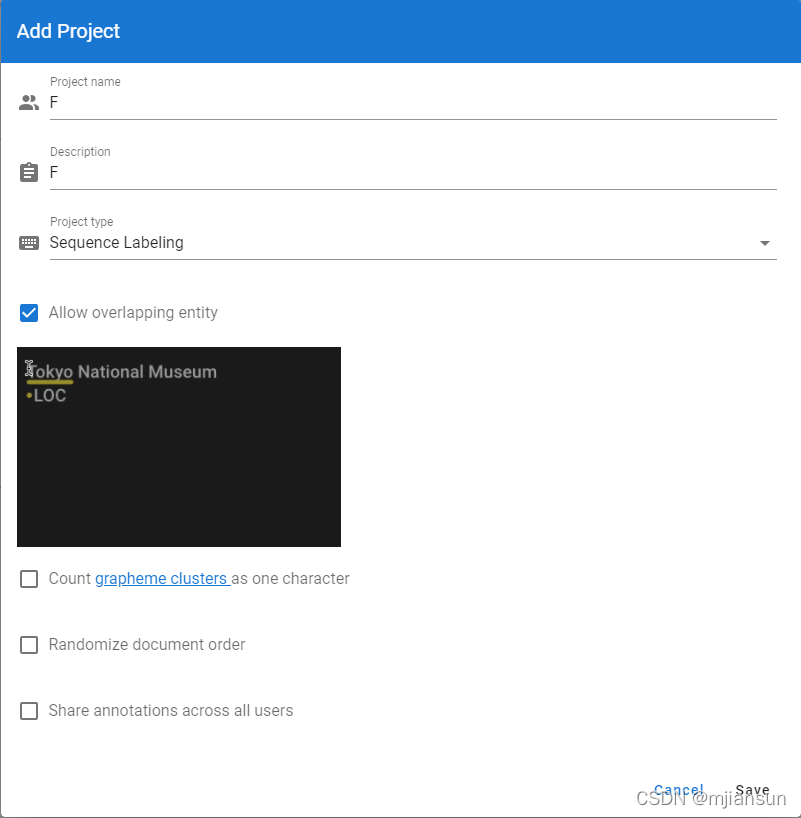
3.3 导入数据
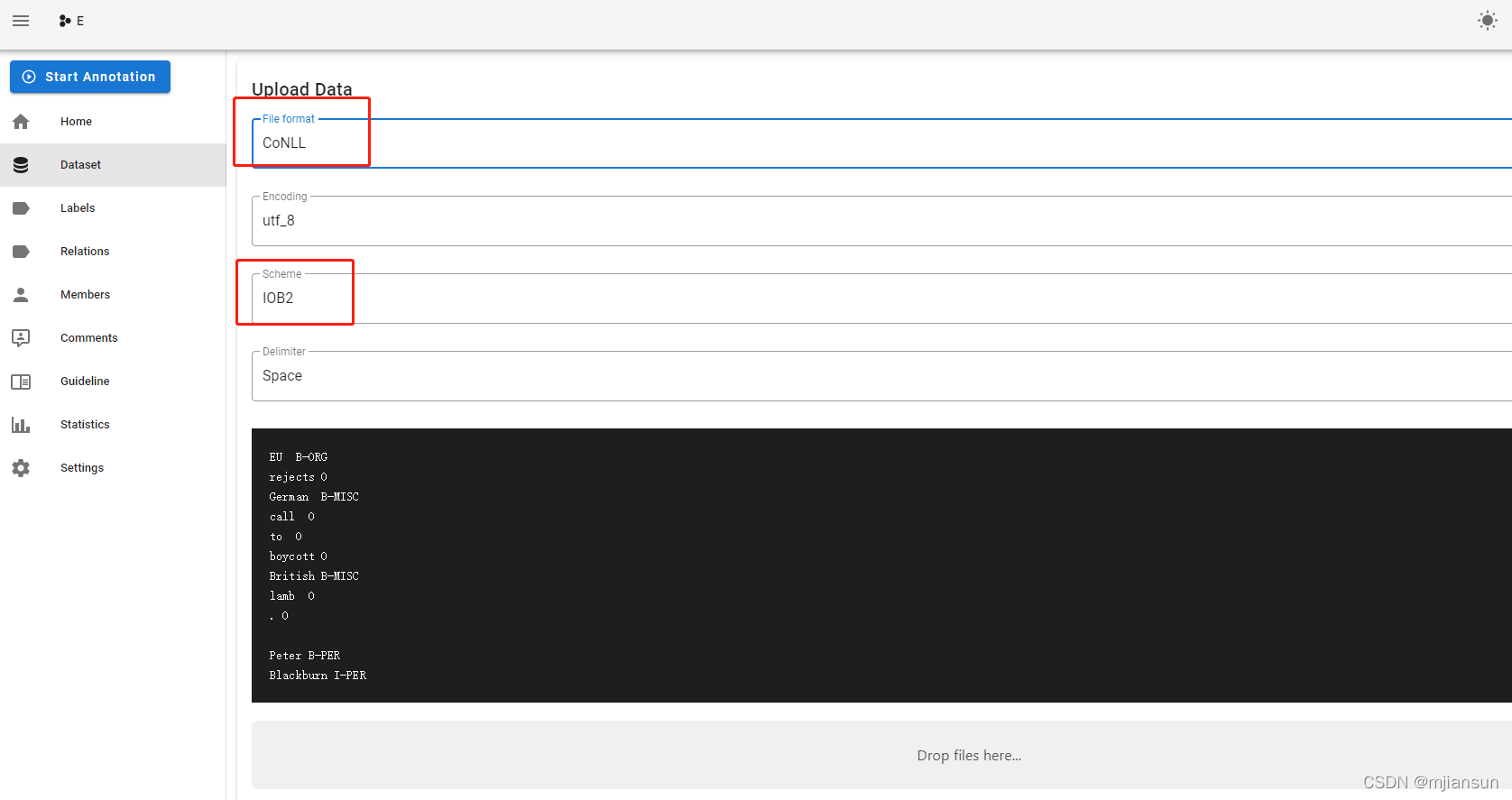
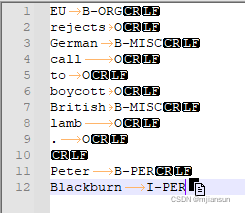
3.3.1 将CoNLL的数据转成上述格式
import os
if __name__ == "__main__":
rootPath = "/data2/PrivateExperiment/bert-master/CoNLL/train.txt"
savePath = "/data2/PrivateExperiment/bert-master/CoNLL/process/conll.txt"
collectData = []
with open(rootPath, "r") as f:
for line in f.readlines():
lineStrs = line.strip().split()
if len(lineStrs) > 0:
collectData.append([lineStrs[0], lineStrs[-1] + "\n"])
else:
collectData.append(["\n"])
with open(savePath, "w", encoding="utf-8") as f:
for lineData in collectData:
f.write("\t".join(lineData))生成结果为
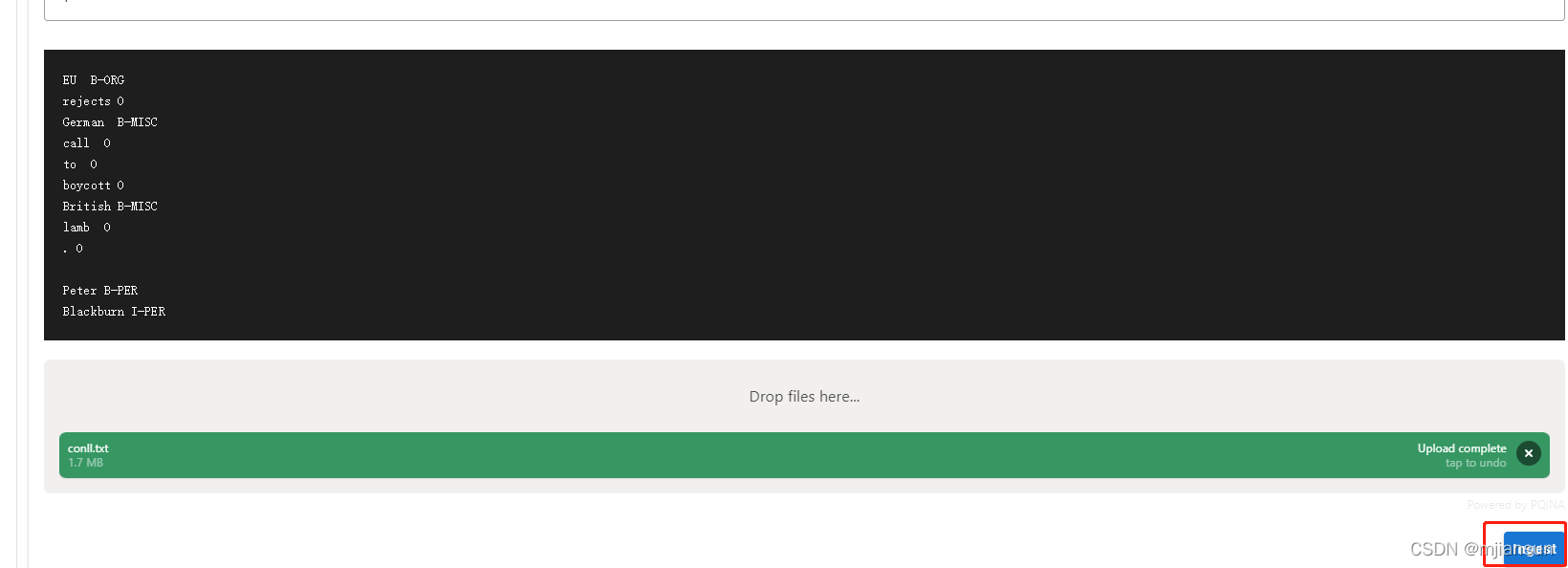
3.3.2 将输入拖拽导入
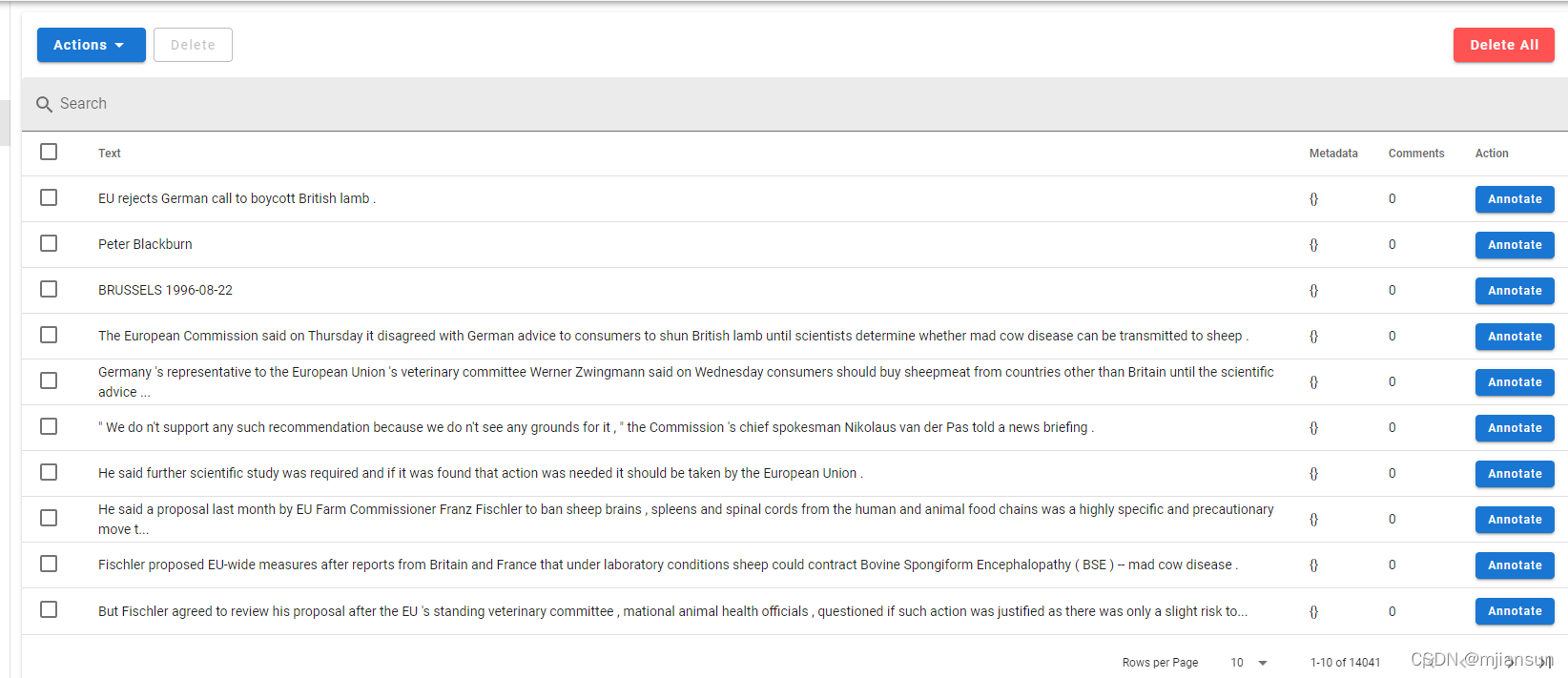

3.4导出数据

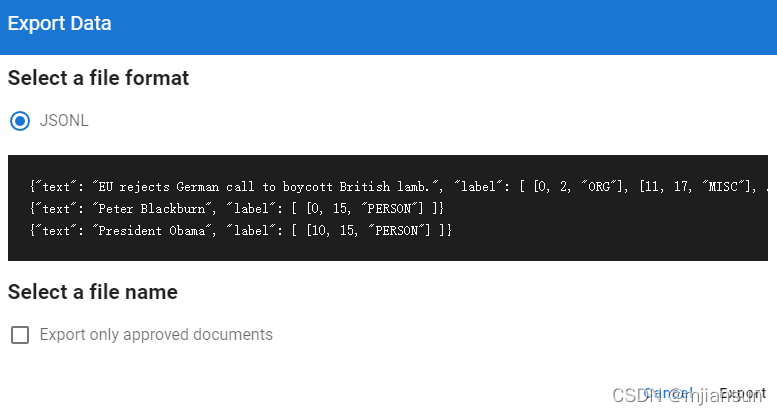
admin.jsonl为正常的数据,unknown.jsonl为不正常数据。
admin.jsonl

unknown.jsonl
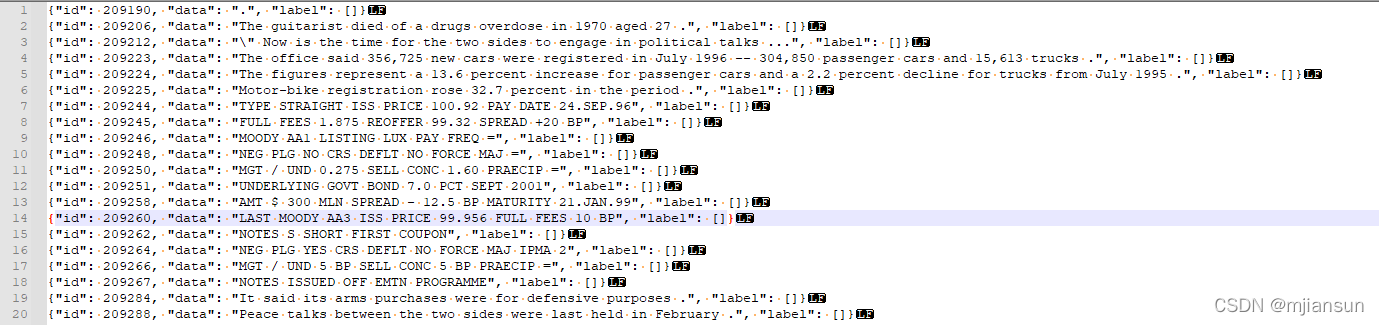

















 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









